快速超轻量城市交通场景语义分割
2022-10-16石敏沈佳林易清明骆爱文
石敏,沈佳林,易清明,骆爱文
暨南大学 信息科学技术学院,广州510632
语义分割技术在面向自动驾驶的城市交通场景中有着非常重要的作用。目前分割效果较好的语义分割网络,如DeepLabV3+、PSPNet等都有比较高的准确率,但是这类神经网络算法具有庞大的模型参数量和计算量,因而需要在车载系统上配备强大的计算力,计算资源消耗高、成本高、能效低。为了使得车载系统在城市交通场景下达到实时处理图像信息的效果,轻量化和实时性成为了语义分割任务中除了分割精度以外的最重要考量因素,也是将语义分割实现真正落地应用的客观要求。
目前轻量化语义分割网络大部分采用现有的网络 如VGG16、ResNet、Xception等骨干网络作为语义分割的特征提取网络。如SegNet使用VGG16作为特征提取的骨干网络,拥有一定的特征提取能力;ICNet以ResNet为骨干网络构造多支路结构,提高分割精度;GUN(guided upsampling network)使用不同深度的ResNet 构建深浅骨干网络,提高网络多尺度特征提取能力。这一类网络通常具有不错的特征提取能力,但由于现有的比较流行的骨干网络ResNet、Xception 等本身都具有一定的参数量,直接采用它们作为语义分割的特征提取的骨干网络,会导致整个语义分割网络参数冗余。另一种方式是为语义分割任务有针对性地设计特征提取模块,利用这些特征提取模块构建一个特征提取骨干网络,如ENet采用ENet 瓶颈模块构建轻量化骨干网络;CGNet提出CG 块(context guided block),融合局部特征以及上下文特征,构建提取全局上下文的骨干网络;ERFNet设计Non-bottle-1D 模块堆叠成骨干网络。这些网络在参数量方面通常较小,但是通常存在特征表达能力不足的问题,从而导致分割准确率较低。针对以上问题,本文提出了通道注意力瓶颈(channel attention bottleneck,CABt)模块,采用通道分离策略降低模块参数量,并在通道合并时引入通道注意力机制提取多尺度上下文特征信息。本文由CABt 模块进一步构建出一个新的骨干网络,经实验证明该骨干网络具有参数超轻量且分割精度高的优点。
此外,语义分割在恢复图像尺寸阶段通常依赖于解码器,一些流行的语义分割网络为了提升分割精度设计了结构复杂的解码器。SegNet 通过引入多个标准卷积成倍数关系地恢复图像尺寸;ERFNet 则通过堆叠多个Non-bt-1D 构建解码器;ESNet串联若干个PFCU(parallel factorized convolution unit)模块进行图像尺寸的恢复。这些解码器均引入大量卷积运算,导致解码器参数量较大。另一部分语义分割网络如CGNet、EDANet等则使用一个双线性插值算法直接将特征图恢复至原图大小。这种方法通常能够大幅度降低整体网络的参数量,但容易产生锯齿状分割效果,降低分割精度。因此,本文提出了一种空间注意力机制解码器(spatial attention decoder,SAD),在解码阶段仅使用1×1 卷积模块,避免了大量使用3×3 卷积造成的参数冗余的问题,具有超轻量且快速的特点。SAD 引入级联的空间注意力机制到双线性插值算法中进行上采样,完成图像空间细节的恢复,提高分割精度。
1 双注意力轻量化网络
1.1 总体结构图
DALNet 的整体网络结构如图1 所示,主要由两大部分组成:编码器和解码器。编码器主要包含标准卷积模块、特征融合模块、下采样模块以及CABt模块。标准卷积模块用于对原始图像特征信息的提取,常放置于网络的首端。特征融合模块通过Concat操作融合不同倍率下采样的图像以及特征图。下采样模块的作用是降低特征图分辨率,降低运算量,同时扩大网络感受野,常放置于若干个特征提取模块的末端。CABt 模块作为DALNet 的主要特征提取模块,作用是提取多尺度特征以及上下文信息。DALNet的解码器为SAD 模块,SAD 模块的作用是通过引入空间注意力机制级联地恢复图像空间细节信息,实现对分割结果进行精度补偿。

图1 DALNet网络结构Fig.1 Structure of DALNet
1.2 CABt模块
ResNet 作为最常用的特征提取骨干网络,其中,深层ResNet 通过堆叠多个如图2(a)所示的瓶颈结构而组成。ResNet 瓶颈模块使用1×1 卷积将特征通道压缩至原来的1/4 再进行下一步的特征提取,其参数量较小且推理速度快,却难以有较好的特征表达能力。图2(b)为ERFNet 的Non-bottleneck-1D(Non-bt-1D),其使用1×3 和3×1 卷积模块代替一个标准3×3的卷积模块,两个非对称卷积的堆叠在网络深度上比一个3×3 卷积更深,具有更大的感受野以及更强特征提取能力。但由于Non-bottleneck-1D 没有采用通道压缩策略,构建的ERFNet 骨干网络整体参数量比较大。因此,为了克服ResNet 和ERFNet 的缺陷,使得网络架构以较小的参数代价获得较好的特征提取能力,以获得更高的目标分割精度和更快的推理速度,本文提出一个新的通道注意力瓶颈(CABt)结构。主要从以下两方面提高特征提取能力:一方面是确保该结构可在不增加参数量的情况下提取更多的尺度特征信息,提高模块对多尺度目标的捕捉能力;另一方面是为多尺度特征补充上下文特征信息,提升上下文理解能力。

图2 不同瓶颈模块的对比Fig.2 Comparison of different bottleneck modules
ResNet 以及ERFNet 仅采用单分支模块进行特征提取,难以捕捉到多尺度特征信息。因此,本文将CABt 设计成双分支并行处理融合的结构,以在特征提取过程中获取多尺度特征信息。如图2(c)所示,在模块输入端采用Split 策略,在不增加任何卷积参数的情况下将输入特征通道分离处理,设计两个不同感受野的卷积分别对输入特征并行处理,输出不同尺度的特征图。通道合并时,CABt 采用Concat 操作融合双分支的输出,得到多尺度特征图。
此外,由于大量实验表明通道细节信息对图像特征的表达能力有着显著的影响,本文为了对多尺度特征图有针对性地补充通道细节信息,设计了通道注意力机制对通道细节信息进行注意力加权筛选。多尺度特征图输入到全局池化层以及两层1×1卷积进行通道注意力权重学习,通过Sigmoid 计算通道注意力权重大小,与原始输入特征图进行乘积运算筛选出重要的上下文特征,最后与主干支路输出的多尺度特征图进行像素级融合,在提取多尺度信息时补充了原始输入图像的上下文信息,提高模块特征提取能力。
1.3 SAD 模块
解码器通常用于语义分割任务中特征图尺寸的恢复,其在进行上采样过程中通常会使用反卷积、反池化、双线性插值法等方法。但是反卷积和反池化计算量较大,引入到模型中会导致前向推理速度过慢问题,因此,需要重新设计解码器的结构以快速高效地实现特征信息的恢复。


图3 SAD 模块Fig.3 SAD module



图4 DALNet特征热度激活图Fig.4 DALNet feature heat activation map

其中,表示1×1 卷积操作,代表Sigmoid 激活函数。中层空间注意力图与特征图进行像素级乘操作得到特征图。表达式子如下:

其中,表示双线性插值上采样,⊗表示两个矩阵对应位置的像素乘积。
同理,特征图经过上采样操作得到特征图,特征图与浅层空间注意力图进行像素级乘操作得到特征图,最终经过一次2 倍上采样得到最终分割结果。SAD 模块的最终输出可以用以下式子表示:

2 实验分析
2.1 数据集与实验细节
本次实验主要在公开数据集Cityscapes和CamVid上进行实验。Cityscapes 数据集是一个大型的城市交通数据集,图像分辨率为1 024×2 048,包含19 个类别。语义分割部分数据集包含2 975 张图像训练集、500 张图像验证集以及1 525 张图像测试集。CamVid 数据集是一个交通场景数据集,图像分辨率为720×960,包含11 个类别。其中,训练集、验证集、测试集分别包含367、101、233 张图像。
所有的训练实验都基于RTX 2080 Ti 下CUDA 11.2 的PyTorch 1.7 平台上进行,所有的前向推理速度测试实验都在GTX 1080 Ti 显卡上进行。训练时采用的优化策略为基于动量的批随机梯度下降,设置动量momentum 为0.9,权重衰减为1.0×10。训练过程中采用的是学习率衰减的方式,衰减方式为多项式衰减,其中,初始学习率设置为4.5×10,power系数为0.9。训练过程中,设置训练的轮数为1 000,数据增强策略采用的是随机缩放0.75、1.00、1.25、1.50、1.75、2.00 倍的图像转换至不同的尺度输入到网络中训练。此外,由于Cityscapes 数据集存在正负样本不平衡的情况,采用OHEM(online hard example mining)损失函数进行优化,应用于语义分割的像素交叉熵损失函数式子如下:

其中,x表示×大小的图像第,个像素值,^ 表示模型在输入为x时的预测值。
OHEM 在以上损失函数的基础上设置一个阈值thresh,在一个batch 的样本计算其损失以后,对每一个像素进行损失计算并进行降序排序,将损失大于thresh 的像素作为难负样本加入到学习中,这样便能让网络更加关注到难以学习的样本,提高这些样本的分割精度。
对于CamVid 数据集,采用的是类别加权策略去缓解类别不平衡问题:

其中,代表某个类别的权重,为类别样本的分布情况。为超参数,设置为1.10。
2.2 消融实验
为了证明DALNet 的CABt 模块和SAD 模块的有效性,针对CABt模块和SAD 模块做了消融实验。
表1 为单独对CABt 基于512×1 024 尺寸的图像进行功能验证的实验结果,分别使用ResNet 瓶颈模块、ERFNet 的Non-bt-1D 模块以及CABt 模块构建编码器的骨干网络,编码器的输出通过一个8 倍双线性插值上采样将特征图恢复至原始输入图像大小。记录由这几个不同模块构成的骨干网络的mIoU、参数量以及前向推理速度(frame/s)。从表中可以看出,由ResNet 模块构成的骨干网络的前向推理速度最高且参数量为最小的,但是mIoU 仅有52.5%,难以满足真实道路分割的场景。使用Non-bt-1D 模块构成的骨干网mIoU 高达71.2%,而由CABt模块构成的骨干网络仅仅比Non-bt-1D 模块构成的骨干网络的mIoU低0.2 个百分点,却拥有更快的前向推理速度,并且参数量仅为它的1/4。以上的消融实验表明,对比由ResNet 模块和Non-bt-1D 模块构成的骨干网络,由CABt模块构成的骨干网络具有超轻量以及较强特征提取能力的特点,更适用于实时语义分割场景。
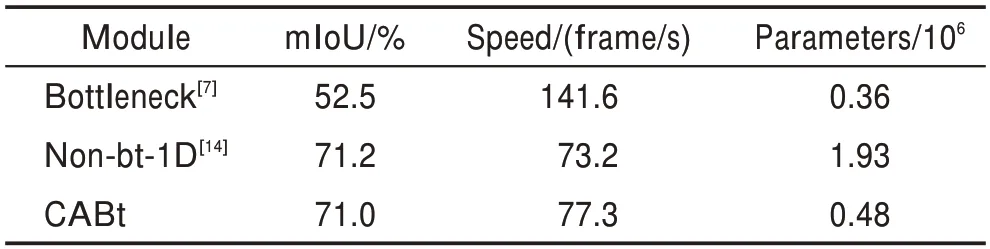
表1 不同瓶颈模块在Cityscapes验证集的实验结果Table 1 Experimental results of different bottleneck modules in Cityscapes validation set
为了验证SAD 模块的图像恢复能力,分别记录ResNet和DALNet在添加SAD 模块前后在Cityscapes验证集上的mIoU 情况。如表2 所示,分别在ResNet和DALNet 骨干网络添加SAD 模块作为解码器后,在参数量基本保持不变的情况下,mIoU 有0.5~1.0 个百分点的提升,而推理速度仅仅下降了5~10 frame/s左右。另外,由于ERFNet 的解码器ERFD 参数冗余,将ERFNet 的解码器ERFD 模块替换成SAD 模块,从表2 中可以看出,以SAD 为解码器的ERFNet 比以ERFD 为解码器的ERFNet 的mIoU 高1.8 个百分点,推理速度高30 frame/s 左右,参数量也从210 万降低至188万。以上实验表明,SAD 模块更加轻量,并具有较好的空间信息恢复能力,更适用于实时语义分割场景。

表2 SAD 模块在Cityscapes验证集的实验结果Table 2 Experimental results of SAD module in Cityscapes validation set
为了验证DALNet 整体的效果,对比近几年来实时性语义分割网络中性能较优秀的网络。表3 为各网络在Cityscapes数据集上的表现。

表3 不同模型在Cityscapes数据集上的实验结果Table 3 Experimental results of different models on Cityscapes dataset
可以观察到,当输入图像分辨率为512×1 024时,DALNet 在Cityscapes 验证集和测试集上的mIoU 均达到71%以上,而当图像输入分辨率为1 024×1 024时,DALNet 在测试集的mIoU 高达74.1%,比Dong 等人所提算法高0.5个百分点,而参数量仅为它的1/13,说明DALNet 能在准确率与参数量之间实现更好的权衡。表3 中参数量最小的网络为ENet 和ESPNet,仅有36 万的参数量,比DALNet 低12 万,但它们的mIoU 却比DALNet降低了10 个百分点以上。这说明DALNet 在mIoU 和参数量上做了一个很好的权衡。在前向推理实验中,输入分辨率为512×1 024 的情况下,DALNet 的推理速度能达到74 frame/s,远超实时网络的要求。
表4 为各网络在CamVid 数据集上的性能对比,在输入分辨率为360×480 时,DALNet 的mIoU 比表现最好的LEDNet 低0.5 个百分点,但其参数量仅为LEDNet 的1/2。DALNet 比表中参数量最小的ENet和ESPNet的mIoU 高10 个百分点以上,而参数量仅比两者增加了11万。在图像输入分辨率为360×480的情况下,DALNet 的推理速度高达103 frame/s,非常适宜应用于实时图像处理场景。当输入图像的分辨率为720×960 时,DALNet 的mIoU 高达70.1%,比Dong 等人提出的网络高出2.1 个百分点,且参数量也仅为其方法的1/13。表4 表明,DALNet 在CamVid数据集上也有比较优秀的表现,能够在mIoU、参数量以及推理速度三者中达到较好的权衡。

表4 不同模型在CamVid 测试集的实验结果Table 4 Experimental results of different models on CamVid test set
除了对Cityscapes 整体mIoU 的计算,表5 列出了各个网络在Cityscapes 测试集中每个类别的mIoU,其中,DALNet-512 和DALNet-1024 分别表示输入至DALNet 中的图像分辨率为512×1 024 或1 024×1 024。从表中可以看出,对比其他网络,DALNet 对于人行道、栅栏、柱子、交通灯等相对较小的物体均达到最高的mIoU,这表明DALNet 中的SAD 模块利用注意力机制能够对小物体进行一定程度的关注,从而实现对小目标空间细节的恢复。

表5 不同模型在Cityscapes测试集上的预分类结果Table 5 Pre-class results of different models on Cityscapes test set 单位:%
图5 为DALNet 和其他网络在Cityscapes 数据集上的分割效果对比图。其中,图5(a)蓝色椭圆圈出部分在原图的分割为应该忽略的类别,其他网络均将其误分割为人,DALNet 正确地将此类别忽略,这依赖于CABt 模块的通道注意力机制,在对类别通道权重计算时,对这个场景下应忽略的类别做了比较低的关注。从图5(d)圈出部分可以看出,墙体类别以及栅栏类别交界处容易使模型造成误判而产生边界不清晰问题,而DALNet 使用SAD 模块能够准确地确定墙体以及栅栏各自的边界,达到较好的分割效果。

图5 不同模型的分割结果Fig.5 Segmentation results of different models
3 结束语
本文针对城市交通实时应用场景,提出了一种基于双注意力机制的快速、超轻量语义分割网络DALNet。对于编码器,由通道注意力瓶颈模块CABt组成的CABb 网络作为语义分割的特征提取网络,实现图像特征的高效提取。对于解码器,提出了空间注意力模块SAD,结合空间注意力以及双线性插值法实现图像空间信息的高效恢复。通过实验数据表明,DALNet 在Cityscapes 数据集和CamVid 数据集的mIoU 最高可达74.1%和70.1%,而模型参数量仅有48 万,输入分辨率为512×1 024 时,在GTX 1080 Ti显卡上的推理速度达到74 frame/s。对比现在流行的实时语义分割网络,本文提出的DALNet 以更小参数量获得更高的分割准确率以及更高的推理速度,非常适用于道路分割场景。
