基于空间配准模型的Mask R-CNN位姿估计网络
2022-10-12刘一开王建王涵悦韩阳
刘一开,王建,王涵悦,韩阳
(1.华北理工大学 唐山市工程计算重点实验室,河北 唐山 063210;2. 华北理工大学 学科建设处,河北 唐山 063210 3. 华北理工大学 理学院,河北 唐山 063210
随着科学技术的不断发展,工业机器人在推动制造装备升级与换代的进程中扮演着极其重要的角色,制造专业细分和更加复杂的制造流程要求工业机器人作业更加智能化、精细化。在现代机器生产中,机器装配自动化已成为提高整个制造系统生产效率、降低成本和稳定产品质量的关键环节。汽车制造作为机器人应用和机器生产的典型代表,最能体现一个国家的制造业水平,在国民经济发展中具有战略性地位,其生产管理理念和方式不断辐射其它制造行业,且正朝向精密化、柔性化、智能化、自动化和清洁化方向发展。
其中视觉机器人的自动装配问题是发展的一个重点,视觉机器人的自动装配重点在于如何确定装配工件的位姿,位姿估计是视觉机器人自动装配的关键一环,位姿估计的准确性直接决定了视觉机器人的装配正确性Qiao M等人提出并设计实现了一种基于端到端学习的位姿估计模型[1],该模型的输入是连续图像帧,这为深度学习在位姿估计方面的应用提供了一种探索方法。Wang H等人提出通过使用双阈融合Canny边缘检测方法和深度学习方法来提取边缘,然后采用非参数统计方法来拟合边缘像素残差形成误差函数,从而得到目标物体的位姿估计[2]。Li S等人通过采用ASIS方法对三维点云进行分割预处理,并将三维点云映射到二维平面上,从而生成了深度特征图并提取位姿特征[3],大幅度提高了位姿估计准确率。
Hu Y等人通过在纯视觉的SLAM系统中增加构建稠密点云模块,构建出稠密点云图[4],展现出对周围环境更有利的一些信息,为解决稀疏点云图位姿估计问题提供了一种解决思路。Lv Q等人通过尺度不变特征变换(Scale Invariant Feature Transform,SIFT)算法或归一化对齐径向特征(Normal Aligned Radial Feature,NARF)来提取所需的点云特征,然后为了剔除错误的特征点对,采用了随机一致性采样算法(Random Sample Consensus RANSAC),得到了一个初始变换矩阵,随后采用ICP算法完成对最终变换矩阵的估计[5]。
该研究在量测传感器设备的视觉定位与引导中建立空间配准模型并引入深度学习算法,然后将误差参数补偿传感器系统,同时结合Mask RCNN框架和VGG-16网络,实现视觉目标位姿估计网络模型。
1 多传感器空间配准模型
根据多传感器的测量空间配准模型方程,假设在已经具有一组多传感器测量结果的条件下,利用建立的模型方程求解时,对系统误差解常用的方法有最小二乘法、广义最小二乘法等。
(1)最小二乘法
最小二乘法是在没有先验传感器设备测量数据概率的情况下,最简单的一种参数估计的计算方式。这里使用矩阵的形式表示测量数据,传感器设备的个数决定未知的待求解参数的维数,下面给出最小二乘法估计的理论模型。
假设传感器设备的测量数据表达方式如式(1)。
z(t)=h(t,x)+w(t)t=1,2,3...n
(1)
其中h(t,x)表示t时刻测量的传感器设备参数数据,w(t)表示t时刻测量的误差值。t时刻的参数x的最小二乘法估计数学意义是指该t时刻误差平方和收敛到最小时对应的x参数值,表达公式如式(2)。
(2)
(3)
化简可得x(t)参数估计表达式(4)。
x(t)=(A'A)-1A'Mi(t)
(4)
(2)广义最小二乘法
从最小二乘法的表达式可知,表达式中包含的系统误差如果在传感器设备工作了一段时间后发生了改变,使用最小二乘法的估计值会变得不准确。考虑到最小二乘法的缺点,把传感器设备测量到的随机误差添加到表达式中,得到广义最小二乘法的参数估计模型表达式:
公式中参数:
(5)
2 基于Mask R-CNN框架的位姿估计模型
2.1 目标检测网络
目标检测是指在给定的输入图像中寻找出可能是物体的位置并通过模型分类或预测给出该物体所属的类别。传统的计算机视觉方法中,需要从每张输入图像中抽取和选择图像特征,再放入模型中进行训练得到特征向量,再经过分类器即可得到对应物体类别的概率。常用的流程和步骤包括区域选择、特征提取和分类识别等[6]。深度学习的出现,扩展了数字图像处理的边界,提供了一种新的思路和方法并广泛应用于图像分类、语义分割和目标检测等领域。深度学习以神经网络作为理论基础,在此基础之上迭代发展,诞生了许多经典的算法和框架,传统计算机视觉工作流程和深度学习工作流程见图1所示。

图1 传统计算机视觉和深度学习工作流程
Mask R-CNN是在2017年提出的一种目标检测算法,而且是在Faster R-CNN基础上进行的扩展。它采用的分类器主要有Softmax分类器、LDA(Latent Dirichlet Allocation)和SVM ( Support Vector Machine)分类器[7-9]。它通过在bounding box recognition上并行增加一个预测分割的分支,可以输出图像的掩模,通过损失函数来训练参数,达到更好的图像检测分割效果,其网络架构如图2所示。

图2 Mask R-CNN网络架构
Mask R-CNN在其他领域也实现了比较好的检测效果,比如人体关键点识别检测。Mask R-CNN的算法流程分为2个阶段,在第一阶段中,主要通过区域建议网络(RNP网络)来得到包括目标物体的所有可能边框。在第二阶段中,通过对每个物体的检测识别,从而得到物体在图像中的边框信息和预测的类别这2个输出[10]。在这基础上为了对输出对象进行掩码,添加了第3个输出分支。
在进行特征提取时,Mask R-CNN选择采用了ResNet50残差网络和特征金字塔网络(FPN)。训练FPN和ResNet50网络后,会得到一个包含强语义信息和强空间信息的特征图。根据特征图,区域候选网络(RPN)可以通过非极大值抑制来得到候选区域[11]。同时,为了解决特征图和原始图像之间不对准的问题,Mask R-CNN采用了RolAlign方法进行改进,RolAlign是一个池化层,通过把特征图和原始图像像素对应,保留大致的空间位置,从而把结果映射到原图中,提高了算法的检测精度。最后,全连接层和卷积层通过接受ROL来进行位置回归、掩膜预测和类别预测等工作[12]。
2.2 位姿估计模型
VGG-16是一种泛化能力强和具有深度结构的卷积神经网络模型,其作为基础网络架构在特征提取能力方面非常强。在堆叠式网络层的各种组合方式中,VGG-16网络表现效果较佳,都是在下一层处理上一层提供的数据,两层之间不存在共享特征信息。其有16个隐藏层,由13个卷积层和3个全连接构成。其提取图像的显著特征主要是通过在卷积计算中使用3×3的卷积核和2×2的池化核来实现的。因此,VGG-16网络有着较好的目标物体检测效果,能够很好地提取到目标物体的特征,并能够最大限度地进行姿态估计网络的研究,其网络架构如图3所示。

图3 位姿估计网络原理示意图
预测出的平移矩阵的表达形式为T=(x1,x2,x3),分别表示了平移矩阵T的3个输出,而对应平移矩阵的真值表达式为(6):
(6)
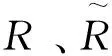
(7)
然而在实际情况中,简单的使用MAE作为网络训练的损失函数,往往无法得到预期效果。考虑到目标物体在三维空间中的变化与二维图像引起的变化并不是保持一致的,具体来说,在三维空间中,目标物体朝着远离相机的光轴方向和沿着平行于像素平面移动时,在二维图像中,目标物体引起的变化更加剧烈。考虑到这种情况,也为了能直接从网络中估计出目标物体的位姿,这里提出了一种加权的损失函数:
(8)
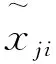
(9)
(10)
其中M表示样本个数,k为样本的第k个值。
该位姿估计网络的评估采用计算平均距离的方法,平均距离的计算是将目标物体中心点的真实旋转矩阵R和平移量T投射到空间上的点,与位姿估计算法预测的旋转矩阵R和平移量T映射到空间上的点进行计算得出平均距离,具体计算公式如下:
(11)
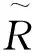
本研究结合深度学习的方法和常见的目标检测框架进行尝试和探索,实现给定彩色图像输入时,估计待测物体从目标坐标系变换到传感器设备指定坐标系的转换关系式,其中包含系统误差和随机误差。卷积神经网络在图像特征提取方面的应用十分广泛,图像特征提取的效果显著,选择卷积神经网络结合位姿估计建立预测网络模型。
3 实验结果分析
3.1 运动模型参数估计算法结果
假设传感器设备A和传感器设备B架设在坐标系的(0,0)和(400,0)处,在此假设系统中,假设传感器设备的观测偏差为1 m,方位角度的偏差为0.008 5,被测物体沿着传感器设备连线的平行线方向移动,移动距离为100m,如图4所示。

图4 传感器模拟系统示意图
在不同的随机误差情况下,重复抽样150次,通过计算机计算得到三维空间配准系统的近似估计,结果如表1和表2所示。

表1 最小二乘法系统误差参数估计值

表2 广义最小二乘法系统误差参数估计值
其中σn代表噪声协方差,ΔrA代表设备A距离估计值跟真实值的差值,ΔθA代表设备A方位估计值跟真实值的差值,ΔrB代表设备B距离估计值跟真实值的差值,ΔθB代表设备B方位估计值跟真实值的差值。
分别使用最小二乘法和广义最小二乘法进行120次仿真计算,根据求得的系统误差结果,求出在距离和方位角上的方差图,如(图5~图8所示)。

图5 传感器设备A的距离偏差估计 图6 传感器设备B的距离偏差估计
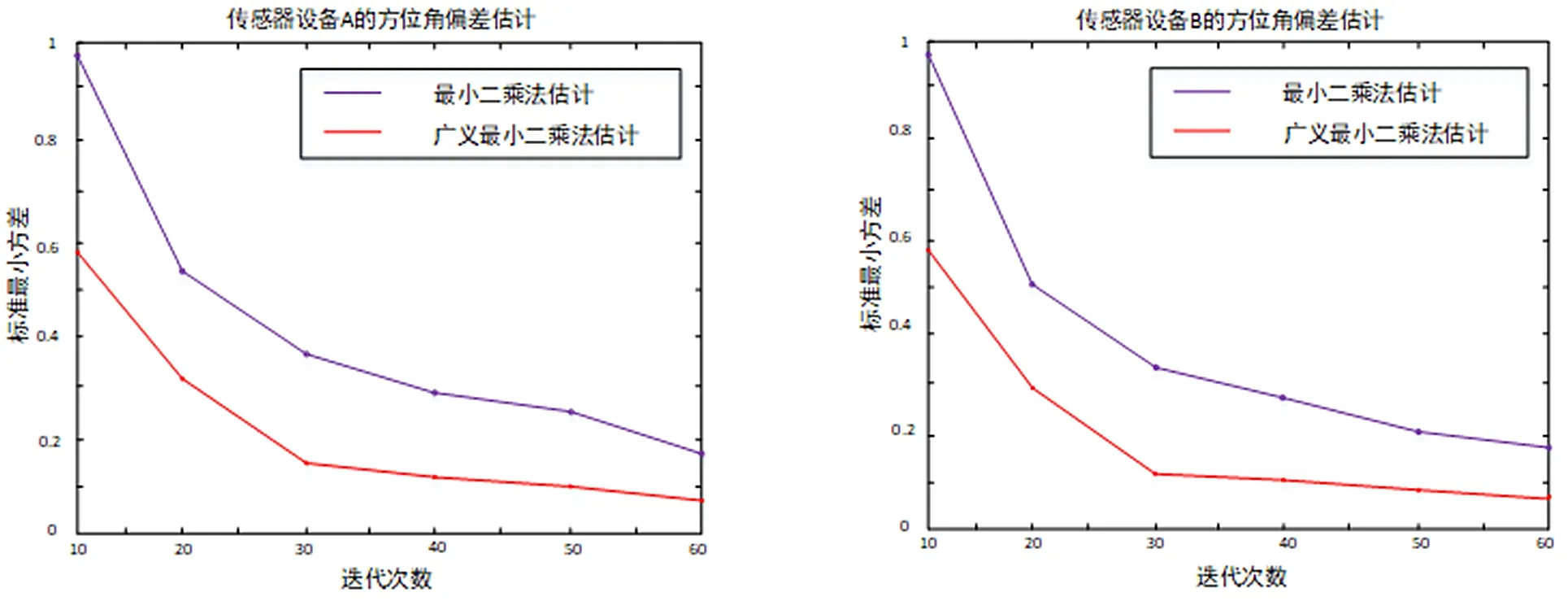
图7 传感器设备A的方位角偏差估计 图8 传感器设备B的方位角偏差估计
由实验结果可知,当被测物体距离传感器设备测量距离越近时系统误差的估计的结果就越准确,精度越高,随着物体移动的距离变远系统误差估计的偏移越来越大。同时随机噪声误差变大时,系统误差估计和实际值偏移量变大。
3.2 运动模型参数估计算法结果
本位姿估计模型实验框架选择python、Keras和tensorflow来实现目标位姿估计网络的搭建。为了提高网络的精确度,在训练网络时,先将样本进行有放回的随机抽样处理,每批样本大小设置为20组,学习率设置为0.002,迭代次数设置为5,网络中前13个卷积层的初始参数采用了在ImageNet上训练的VGG-16网络训练得到权值参数。
为了验证本文设计的网络效果与物体位姿估计网络Pose CNN进行了实验对比。在进行实验时,将Mask R-CNN目标检测物体的可信度设置为0.6,将平均距离 的阈值设置为8 cm并实验汇总11种物体估计的位姿误差在8厘米之内的占比情况。

表3 对比结果汇总
从统计的实验结果中可以看出,在使用CamVid数据集训练结束的结果中,本网络识别的结果和位姿估计的误差优于PoseCNN网络,因为引入了更优的目标识别和物体分割的掩膜,使得本文提出的位姿估计网络获得了更优的结果,网络具有比PoseCNN网络效果更好的泛化能力。但也存在一些不足之处,即出现预测效果较差的情况。由于数据集中存在一些体积较小或被其他物体严重遮挡的待预测物体,导致提取的特征十分少。表面光滑形状单一的物体也有同样的问题,所以位姿估计网络的预测效果较差。
4 结论
本文建立多传感器空间配准模型,推导坐标系之间的变换关系以及系统误差和随机误差的估计求解,并对误差影响做了分析。如果系统误差在较小范围内,对空间配准模型的影响不大,随着误差范围增大,坐标变换得到的位置结果偏离真实值较远,模型效果变得很差,所以坐标变化过程引入的误差也要重视。位姿估计模型是由目标检测和姿态估计两个模块组成,目标检测选择Mask-RCNN框架,姿态估计部分则通过改进损失函数和调整参数,能让该模型实现从待测图像中预测出目标物体的位姿。经实验对比,本文的网络模型的预测效果优于物体位姿估计网络Pose CNN。根据实验结论可知本文建立多传感器空间配准模型具有一定程度的应用价值,并且在准确度方面,未来会进行进一步研究。
