拟合函数—神经网络协同的页岩气井产能预测模型
2022-10-10胡晓东涂志勇罗英浩周福建李宇娇刘健易普康
胡晓东,涂志勇,罗英浩,周福建,李宇娇,刘健,易普康
中国石油大学(北京)人工智能学院,北京 102249
0 前言
页岩气压裂后产能预测对于水平井压裂效果评价和生产参数优化具有重要意义。传统的压后产能预测方法包含解析法[1-3]、半解析法[4-6]、数值模拟法[7-8]和递减曲线拟合法[9-10]等。传统解析和数值模拟方法存在计算复杂、多物理场耦合困难等问题。而基于递减曲线等传统经验模型只能粗略描述地递减特征,难以准确而全面地表征复杂条件下的生产动态。
20世纪以来,许多学者尝试将基于数据驱动的机器学习算法应用到油气领域[11-13]。而针对气井产能预测的数据驱动算法是其中一种重要应用场景[14]。数据驱动方法能够避免物理机理分析方法构建的复杂性和多解性[15]。具体而言,单井产能预测问题的输入和预测对象均具有时间序列维度上连续性和自相关性。然而,地质和生产参数与产能随时间的变化具有强非线性关系[16]。针对这一问题,一些学者应用支持向量机[16-17]、粒子群[18]、BP神经网络[19-20](Back Propagation Neural Network)、循环神经网络[21]和LSTM神经网络[22-23](Long-Short Term Memory Neural Network)等算法的变形或耦合模型构建产能预测模型,以更好地捕获地质和生产两方面中多个控制参数(如井斜、垂深、孔隙度、排量、射孔簇数、支撑剂等)对生产曲线的非线性关系,从而提高产能预测的准确率。这些机器学习算法能够简化产能预测模型的构建和动态求解速度,但在产能预测模型优选、小样本训练、非结构化数据处理和主控因素分析等方面仍存在挑战。首先,产能预测的关键预测对象是气井正式投产后的未来产量动态变化,其影响因素不仅包括地质和生产过程中与时间无关的静态参数,还包括气井前期生产的产能时序数据。如何在时序序列预测模型中考虑静态参数是产能预测神经网络模型构建的关键。此外,气井产能预测模型的现场数据样本较少,且一些样本中存在异常产能趋势,这会造成模型训练的过拟合和泛化能力差等问题。针对以上问题,如何对神经网络模型结构和预测流程进行适应性修正是目前亟需解决的问题。
本文基于LSTM和DNN(Deep Neural Network)神经网络,建立了拟合函数—神经网络协同的页岩气井动态产能预测模型。首先,针对非结构化数据,本文利用维度扩展的方法表征了静态数据的时间不变性,并将前期日产气量、平均套管压力共同组成的二维时序数据与用液强度、加砂强度、总含气量、脆性矿物含量等静态产能控制参数混合构建数据集,以实现时序—非时序混合数据的时间序列预测。其次,本文将传统产能递减模型作为LSTM神经网络输入层的“弱物理约束”,即在特征工程阶段通过产能递减模型的拟合函数对所有准备训练的井样本数据进行预筛选。其中,Arps产能递减微分方程是Arps[9,24]提出的基于概率统计的产能预测模型,陈元千和郝明强[25]在此基础上推导出Arps的指数递减、双曲递减和调和递减等3种不同递减系数下的产能模型。本文基于Arps的3类递减拟合函数,通过谢军等人[26]提出的筛选法,以最小均方误差(mean squared error,MSE)为标准自动优选递减模型,对我国某页岩区块中的各单井产能数据进行递减曲线拟合,去除不符合产能递减规律的无效样本。同时,将实际工况下单日生产时间与产量的比例关系作为DNN神经网络输出层的“强物理约束”,即在神经网络的最后一个全连接层后对输出结果按实际单日生产时间进行缩放,以避免实际工况下由于临时停泵等人为因素造成的产能曲线异常点对模型反向优化过程的影响。基于以上两类“物理约束”, 本文模型既能捕获产能递减的共性规律,也能避免人为因素造成的特征干扰,解决了模型的无物理规律、过拟合的问题,从而保证了预测结果的稳定性。
最后,对筛选后的页岩气井的动态产能预测进行k折(k-fold)交叉验证,并分别讨论了神经网络模型参数、产能控制参数和时间步长等对于本文模型误差的影响。结果显示,LSTM+DNN神经网络可以通过用液强度、加砂强度、总含气量、脆性矿物含量等静态产能控制参数,前期生产、压力曲线和单日实际生产时间序列较快速准确地捕捉的后期生产特征。此外,通过拟合函数和神经网络的协同,在不增加样本规模的条件下模型能较准确和稳定地预测后期产能递减趋势。本文模型对于页岩气动态产能预测具有更好的预测能力,对老井压裂效果评价和新井生产参数优化具有一定指导意义。
1 方法与模型
1.1 LSTM神经网络原理
长短期记忆神经网络(LSTM)主体结构类似于RNN(Recurrent Neural Network)的链状重复网络结构,主要区别在于将RNN模型中隐藏层中的神经元替换为LSTM特有的结构单元。其典型的结构单元(见图1)包括“遗忘门”(forget gate)、“输入门”(input gate)、“输出门”(output gate)[27]。

图1 LSTM网络结构单元[28]Fig.1 LSTM network structure unit[28]
基于以上3个组成部分,LSTM网络结构单元典型的前向计算流程如下[27-29]:

式中,ft为“遗忘门”的输出值(0~1间的数字),决定了上一步处理器状态(cell state)应被继续传递的部分;it为“输入门”的输出值,决定了tanh类激活函数计算结果中应被保留的部分;ct为tanh类激活函数的计算结果,表征处理器状态的值;ot为“输出门”的输出值;ht为整个隐藏层的输出值;W表示各单元之间的权重系数矩阵;b表示各单元对应的偏置项;σ表示Sigmoid激活函数。
1.2 基于LSTM+DNN的动态产能预测模型
动态产能预测模型基于地质及工程等静态参数,产能、平均套管压力等时序参数和单日实际生产时间等强约束控制参数共同构建。现场数据包括50口页岩气井。其中,实测递减阶段的产能数据满足模型构建所需最小时间序列的井样本共24口。整理出供优选的地质参数8个(杨氏模量、总有机碳含量、最大水平主应力、最小水平主应力、总含气量、孔隙度、泊松比和脆性矿物含量)、工程参数6个(用液强度、加砂强度、平均泵压、平均排量、段长和簇间距)。结合灰色关联法和熵权法,确定各地质、工程参数与产能的相关度[30]。为确保模型预测的稳定性,从地质、工程参数中各选取与产能相关度最高的前2个参数作为静态产能控制参数,即用液强度、加砂强度、总含气量、脆性矿物含量。
由于静态产能控制参数无法直接和生产数据共同构建时间序列数据集,因此需要进行维度扩展处理。具体而言,模型训练包括多口井的数据,其中每口井具有与时间相关的产能、平均套管压力数据和特定且唯一的一组时间无关的静态产能控制参数。为了同时训练并提取产能控制参数和前期产能、平均套管压力数据对于后期产能数据的非线性规律,将每个时间无关的产能控制参数视为在该井后期产能曲线范围内与时间相关,并重复该范围内的静态控制参数,扩展到后期产能曲线的同一时间维度。当后期产能曲线在时间维度上的每个时间点具有对应的一组产能控制参数值,则可将所有井前期产能、平均套管压力数据和后期产能控制参数(包括单日实际生产时间)作为输入特征向量,后期产能数据作为输出特征向量,从而生成非结构化的高维时间序列数据集。最后,基于LSTM和DNN神经网络,设计了多变量动态产能预测模型(如图2)。模型训练和迭代过程包括:(1)对产能样本进行特征筛选,并构建非结构化的多变量时间序列数据集;(2)标准化数据集,划分训练集和测试集;(3)基于LSTM和DNN神经网络前向计算方法计算模型输出值;(4)基于网络层级和时间反向传播,计算模型输出值和实际值的误差项;(5)计算各对应权重的梯度;(6)基于梯度的优化算法更新权重;(7)重复迭代,确定最优的产能预测结果,并将结果反标准化。

图2 LSTM产能预测模型结构Fig.2 LSTM productivity prediction model structure
产能模型包含6个产能控制参数(平均套管压力、用液强度、加砂强度、总含气量、脆性矿物含量和单日实际生产时间),预实现通过某井前n个步长的产能数据预测后m个步长的产能数据。其中,模型主要设计为2个LSTM层和3层全连接层,分别通过3个输入接口传入所有产能控制参数和前期产能时序数据。模型对数据本身量级非常敏感,因此输入前需利用min-max标准化将所有数据映射到0~1之间,以消除参数之间的量纲影响。具体而言,首先,针对模型中前2个LSTM层,主要用于捕获产能递减趋势特征,需于第1个LSTM层输入由前期产能时序数据和对应平均套管压力时序数据组成的二维特征向量,即

其中Qn为第n时刻(步)的产能数据,x1,n为第n时刻(步)的平均套管压力,X1表示第一组输入特征向量。
前2个LSTM层将输出一组一维的中间变量,其长度与预测生产曲线的时间序列步长(m)一致。同时,将用液强度、加砂强度、总含气量、脆性矿物含量维度扩展为预测生产曲线的时间序列步长(m),并与LSTM层输出的中间变量共同组成一组新的五维特征向量,即

其中,x2,n m+为LSTM层输出的中间变量,x3,n m+~x6,n m+分别为维度扩展后的用液强度、加砂强度、总含气量、脆性矿物含量数据,X2表示第二组输入特征向量。
通过3个全连接层后将输出得到第n时刻至第n+m时刻间的产能数据。然后,输入同时间段内各个时刻的单日实际生产时间,作为第三组输入特征向量,即
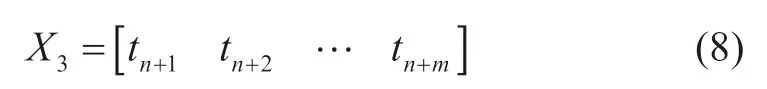
基于单日实际生产时间与对应单日产能数据的等比例关系,修正3个全连接层输出的产能,修正公式如下

其中,Qn m+和Qn m′+分别为修正前后的无因次产能预测值,需要通过反标准化确定最终的预测产量。
根据单井产能预测的实际条件,在训练过程中需要以井为单位分批构建时间序列进行模型训练,每口井重组10个样本(当单井实测时间序列不足划分10个样本时,取其能够划分的最多样本数)。其中,从各井产能递减阶段的起始位置开始,向后取点作为样本时间序列的初始时刻T,并取T~T n+时刻的生产曲线作为已知时间序列,T n++1~T n m++时刻的生产曲线作为预测目标。
2 结果与讨论
2.1 基于Arps产能递减模型的特征筛选
对于动态产能预测模型,当训练集的大量井样本中出现过多异常的无效样本,会造成神经网络特征提取过程中计算出错误的权重,反而会降低模型预测的精度。因此,在LSTM动态产能预测模型训练前需要进行一定预处理。除了对数据标准化,还需要筛选去除产量曲线明显异常的样本,以提高动态产能预测模型的特征提取的准确率。针对我国某页岩区块的单井产能曲线预测进行特征筛选。筛选对象共包含24口同区块页岩气井的真实产能数据。本文以Arps产能递减模型的拟合曲线作为评判标准筛选出12口符合产能递减规律的井样本(图3)。其中,Arps产能递减模型的一般微分方程表示为[25]

图3 基于Arps产能递减模型的训练及测试井样本筛选Fig.3 Training and test well sample selection based on Arps productivity model

其中,q为产量(104m3/天),t为时间(天),n为递减指数,Di为初始产量(104m3/天)。
根据递减指数n的不同,Arps微分方程可进一步表示为

分别利用3种模型拟合递减曲线,并比较不同拟合曲线的MSE,以最小MSE为标准自动优选递减模型拟合曲线。
基于特征筛选后的井样本,以天为单位对各井日产气量数据进行时间序列化,并通过k-fold交叉验证评价模型精度。具体而言,轮流将每口井作为测试集、其他11口井作为训练集进行模型训练和产能预测,并计算对应的MSE,最后将12次测试得到的均方误差取平均,获得最终用于评价模型精度的误差值。当误差值越大,表明模型预测精度越低。
以k-fold交叉验证所得的平均误差值为基础,通过对神经网络模型参数的优选确定最优的动态产能预测模型设计方案,最后讨论了静态产能控制参数和时间步长对模型精度的影响。
2.2 神经网络模型参数的影响规律
神经网络模型参数包括激活函数和梯度优化函数等。激活函数决定了神经网络前向计算时各层神经元向下一层传递的输出。除了linear激活函数,其他激活函数均为非线性函数,能够强化网络的非线性学习能力。梯度优化函数是神经网络在反向传播计算误差项时引导损失函数梯度下降的优化函数,即令损失函数的参数沿某一方向更新,使损失函数值逼近全局最小。梯度优化函数决定了损失函数的优化方向和步长。因此,针对本文模型优选激活函数和梯度优化函数能够提高模型的收敛速度和预测精度。
对于模型中LSTM层的2层输出的激活函数,分别取ELU、SELU、tanh、Sigmoid和linear激活函数进行交叉验证实验,确定各激活函数及其组合下的模型精度如表1所示。结果显示,ELU、tanh和Sigmoid函数的模型预测效果相对较好。综合考虑各函数条件下的模型对于各井的预测误差和平均误差,优选Sigmoid函数作为模型的激活函数。其中Sigmoid函数表示为

表1 不同激活函数下的模型预测精度Table 1 Prediction accuracy of models with different activation functions

对于模型的梯度优化函数。令LSTM层的激活函数为ELU和tanh函数,分别取梯度优化函数为SGD[31]、RMSprop[32]、Adagrad[33]、Adadelta、Adam、Adamax和Nadam[34]进行交叉验证实验,确定各梯度优化函数下的模型误差如表2所示。结果显示,Nadam函数的模型预测效果最好。其梯度计算公式如下[34]

表2 不同梯度优化函数下的模型的误差对比Table 2 Error comparison of models with different gradient optimization functions

式中,gt为平均梯度,θt为目标更新参数,nt为梯度的二阶矩估计值,mt为梯度一阶矩,∈为初始常数,α为动量系数。
最后,以Sigmoid作为激活函数,Nadam作为梯度优化函数训练动态产能预测模型,预测结果见图4。交叉验证结果显示,基于Sigmoid激活函数和Nadam梯度优化函数的动态产能预测模型的平均误差为2.0001,其中大部分井具有较好的预测效果。对于实际对于同一区块的具有相似产能递减规律的气井,通过对多个老井的训练,得到的模型能够基于新井前期部分产能曲线和用液强度、加砂强度、总含气量、脆性矿物含量等产能控制参数共同预测未来产能递减曲线。神经网络模型结构包含单日实际生产时间的强约束,有效降低了实际工况下大量异常产能数据点对产能趋势的影响。
2.3 静态产能控制参数的影响规律
本小节主要分析了静态产能控制参数对产能预测模型的影响。首先,保持神经网络模型结构不变,去除所有静态参数的输入接口,即第二组输入特征向量X2变为前2个LSTM层输出的一维中间变量。以2.2中确定的神经网络超参数重新训练模型,并与考虑静态控制参数的原模型预测结果进行对比(图5)。
结果显示,不含静态产能控制参数(用液强度、加砂强度、总含气量和脆性矿物含量)的模型预测结果整体偏高。对于同一口井,其静态产能控制参数不变。当通过2层LSTM神经网络确定后期产能趋势预测结果后,静态产能控制参数主要通过DNN神经网络对后期各天的产能预测值进行校正,并修正对应模型权重。极端条件下,当产能控制参数数值变化对产能影响较大,其校正后的产能预测值将偏离LSTM确定的整体产能趋势。例如单日实际生产时间与单日产能具有强烈的正比例关系,图5中第90~100天内单日实际生产时间由24小时骤减为9小时,其产能预测值同样远小于趋势预测结果。固定其他产能参数不变,将10井的加砂强度分别设置为1.415、1.978和2.542(所有样本的加砂强度范围为1.415~2.542 t/m),设置三组实验(图6)。结果显示,随着加砂强度的增加,后期的平均日产气量同样增加。

图5 考虑与不考虑静态产能控制参数的10井产能预测结果Fig.5 Productivity prediction results for well-10 with and without static productivity control parameters

图6 不同加砂强度条件下的10井平均产能预测结果Fig.6 Average productivity prediction results of well-10 with different sand addition strength conditions
2.4 输入时间步长和预测时间步长的影响规律
本小节分别分析了输入时间步长和预测时间步长对动态产能预测模型预测精度的影响。其中预测模型参数设置由2.2小节的激活函数和优化函数优选结果确定。首先固定预测时间步长为90天,分别设置输入时间步长为40,50,60和70天,对12口井进行k-fold交叉验证,各输入时间步长条件下的各井预测的平均误差结果如表3所示,其中2井的预测结果如图7所示。

图7 输入时间步长分别为40,50,60和70天的2井产能预测结果Fig.7 well-2 productivity prediction results for input time steps of 40, 50, 60 and 70 days, respectively

表3 输入时间步长为40,50,60和70天的5井产能预测模型的误差对比Table 3 Error comparison of productivity prediction models with input time steps of 40,50,60和70 days
固定输入时间步长为50天,分别设置预测时间步长为30、50、70和90天,对12口井进行k-fold交叉验证,各预测时间步长条件下的各井预测的平均误差结果如表4所示,其中4井的预测结果如图8所示。输入时间步长为50天,设置预测时间输出步长为200天,其中2井的预测结果如图9所示。

图8 预测时间步长分别为30、50、70和90天的4井产能预测结果Fig.8 Well-4 productivity prediction results for forecast time steps of 30, 50, 70 and 90 days, respectively

图9 预测时间步长200的2井产能预测结果Fig.9 Well-2 productivity prediction results for forecast time steps of 200

表4 预测时间步长为30、50、70和90天的产能模型的误差对比Table 4 Error comparison of productivity prediction models with forecast time steps of 30, 50, 70 and 90 days
结果显示,在40~70天范围内,输入时间步长对产能预测精度具有较大影响。当已知的时间序列数据越多,模型精度反而越低。其中,前期异常衰减的产能数据点对预测结果影响较大。模型中单日实际生产时间主要约束未来产能递减趋势中的异常衰减点。随着输入时间步长的增加,各井前期存在的衰减点变多,且避开了单日实际生产时间的强约束,削弱了产能趋势特征。其次,预测时间步长的增加并没有明显降低模型预测的精度。由于数据预处理过程对产能曲线样本进行了特征筛选,各样本的产能曲线均满足一般递减规律。基于序列到序列的LSTM神经网络,能够有效建立前期产能、平均套管压力曲线时间序列和后期递减曲线时间序列的特征关系。同时,通过多个静态产能控制参数的权重校正和单日时间生产时间的强约束,进一步提高了后期产能曲线的局部预测精度。最后,通过2井的200天产能预测结果,进一步说明动态产能预测模型对于更长期产能曲线预测具有较好的适用性。
3 结论
基于LSTM和DNN神经网络,本文建立了拟合函数—神经网络协同的动态产能预测模型。模型能够有效捕捉产能曲线在时间维度和地质及工程维度上的非线性规律。针对某页岩区块的筛选后的12口井,基于k折交叉验证分析了神经网络模型参数、静态产能控制参数、输入时间步长和预测时间步长对模型预测精度的影响。结论如下:1)通过LSTM和DNN神经网络的耦合,可实现多个时序—非时序产能控制参数对后期产能曲线的联合约束;2)在数据预处理过程中通过拟合函数对现场数据的规律性判断,预筛选符合产能递减趋势的样本作为模型训练集,以间接加入含产能递减规律的弱物理约束,可在不增加样本规模的条件下能够有效提高模型训练的精度;3)基于实际工况下单日生产时间与产量的强相关性,于神经网络模型内部加入产能等比例缩放的强物理约束,能够有效提高模型的预测精度和局部稳定性;4)激活函数、梯度优化函数分别为Sigmoid函数和Nadam函数时模型预测误差值为2.0001,预测效果最好;5)预测时间步长的增加并没有明显降低模型预测的精度,LSTM神经网络能够有效捕捉长期的时间序列信息。综上,本文模型考虑了拟合模型的特征筛选,结合单日生产时间的强物理约束,并针对现场产能数据进行训练和预测,能够较好适应不同特征的产能曲线样本,并获取对应的产能递减规律,可以一定程度上辅助页岩气井未来产能曲线预测。
