中国相对贫困的特征分析与指标比较
——基于货币方法和多维方法
2022-10-10刘宇洋陈玉萍
刘宇洋,陈玉萍
一、学界关于相对贫困的研究
(一)关于相对贫困的识别和测度
(二)关于相对贫困标准的研究
二、分析框架与方法比较
(一)分析框架
(二)研究方法
1.货币方法。采用强相对贫困线,以人均收入中位数的一定比例作为相对贫困线,对相对贫困进行识别与测度,理由如下:一是经过脱贫攻坚战,贫困人口的收入和福利水平大幅提高,教育、医疗、住房、饮水等条件明显改善,考虑绝对贫困的弱相对贫困线已经不适用中国;二是微观数据中收入虽然不如消费平滑,但易获取且数据可靠性较高;三是均值和中位数是测度相对贫困时通常使用的统计指标,虽然孰优孰劣仍有争论,但中位数能够避免过高收入造成的均值“被增长”效应。具体计算公式如下:

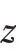
假设样本总数为n,对于每个样本均有总计为d 的福利指标,以x表示个体i 在指标j 上的取值,则可以构建权重矩阵g,其元素取值为:
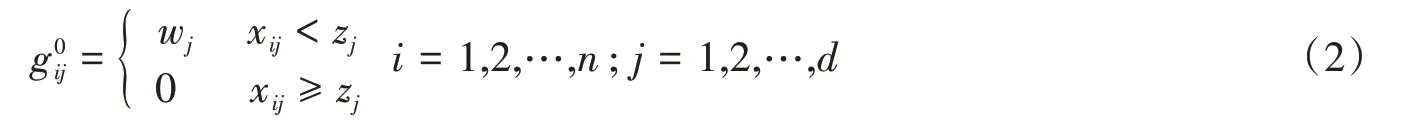
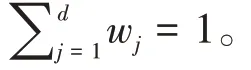
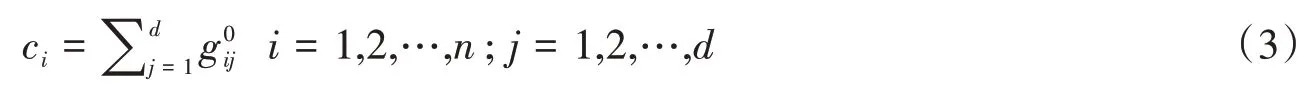
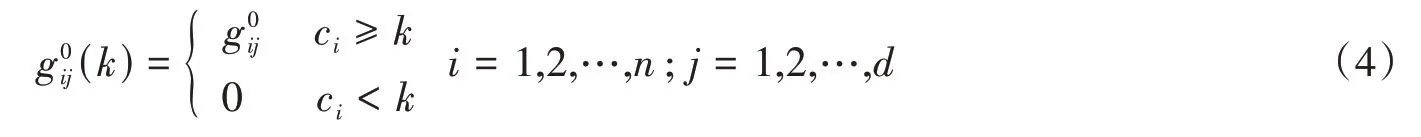
基于审查剥夺矩阵g(k),可以构建新的剥夺得分列向量c(k),以ρ表示当临界值为k 时个体的相对贫困状态,则有:

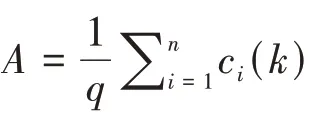

3.二值选择模型。如果被解释变量y 离散,称为离散选择模型,其中二值选择模型是离散选择模型的特殊形式,也是最常见的离散选择模型。在二值选择模型中,因变量y的取值非0即1,如果使用最小二乘法对线性概率模型进行估计,可能会产生预测值ŷ大于1 或者小于0 的情形,为使y 的预测值介于[0,1]之间,在给定解释变量x的情况下,考虑y的两点分布概率:

其中,P(·)表示概率,向量x 表示一系列解释变量,β 为参数,函数F(x,β)称为连接函数,因为其将x与y连接起来,y的取值要么为0,要么为1,故y服从两点分布。
连接函数的选择具有一定灵活性,如果F(x,β)为标准正态的累积分布函数,则有:
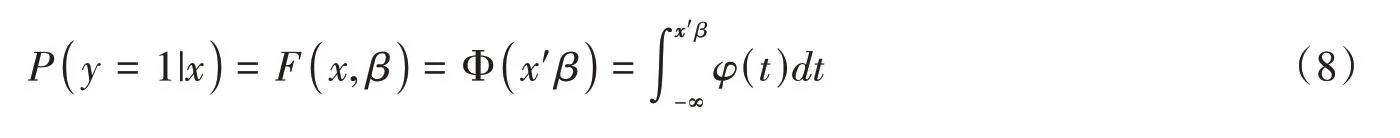
其中,φ(·)与Φ(·)分别为标准正态的密度与累积分布函数,此模型称为Probit模型。
如果F(x,β)为“逻辑分布”的累积分布函数,则有:
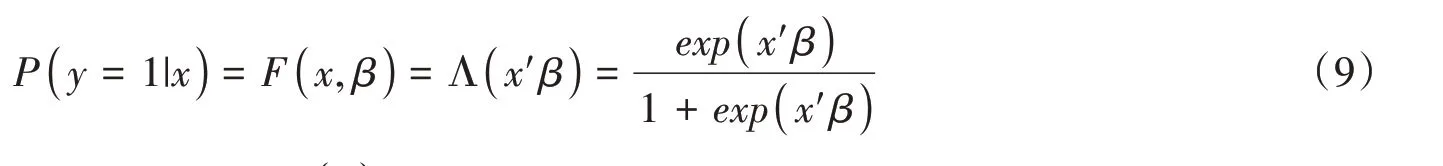
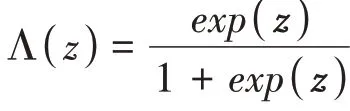
Probit 与Logit 模型本质上都是非线性模型,因此需要使用最大似然估计法(maximum likelihood estimation)进行估计。

三、基于货币方法和多维方法的中国相对贫困测算
(一)数据描述与指标选取
数据来源于中国家庭追踪调查(CFPS),调查内容涵盖了中国居民的经济活动、教育成果以及家庭关系等,调查样本覆盖了中国25 个省(自治区、直辖市),采用多阶段、内隐分层的抽样方法,具有一般代表性。取2014年、2016年和2018年3期数据,经过匹配、删除缺失值后,得到调查的样本8661个,共计25983个观测值。
以家庭为单位进行分析,货币贫困方法使用家庭经济库中的人均家庭纯收入作为测算指标,多维贫困方法指标的选取以牛津大学贫困与人类发展中心(OPHI)提出的多维贫困指标(MPI)为基础框架,结合国内学者关于多维相对贫困指标体系构建的研究。

表1 多维相对贫困的指标与剥夺临界值

(续表)
(二)货币方法:收入相对贫困发生率
基于收入数据,可以使用货币方法测度中国收入相对贫困发生率,选择2018年作为基准,采用收入中位数的一定阈值分省份、分城乡对相对贫困发生率进行测算。表2左半部分给出了不同阈值下以2018年收入数据测算的相对贫困发生率,可以看到将收入中位数40%作为相对贫困线时,总体相对贫困发生率为14.70%,其中城镇为13.40%,农村为15.85%最为合适,因此选择该阈值对收入相对贫困进行测算,得到表2 右半部分的数据。2014—2018年,中国收入相对贫困发生率有一个先下降后平稳的过程,由2014年的19.24%到2016年的14.26%再到2018年的14.70%,期间有4.54%的降幅。在此期间,农村的收入相对贫困发生率均高于城镇,但总体上农村的下降幅度更大,4年间共下降6.12%,城镇则下降了2.77%。

表2 中国收入相对贫困发生率的测算
(三)多维方法:多维相对贫困发生率

表3 中国多维相对贫困发生率的测算
此外,分指标可以得出2018年总体与分城乡样本家庭在12 个指标上的相对贫困发生率(图2)。总体而言,人均教育、养老保险、信息获取与文教娱乐的贫困发生率较高,分别为45.31%、44.02%、56.04%和36.1%,儿童入学与失业两个指标上几乎不存在发生相对贫困的家庭,分别为0.52%和1.81%,其余指标的贫困发生率均处于15%~30%的区间内。分城乡来看,在大部分指标上,农村家庭相对贫困发生率均高于城镇家庭,特别是在人均教育和信息获取指标上,农村比起城镇存在较大的差距,相对贫困发生率差值分别达到了30.14%和20.62%。

图2 中国多维相对贫困分指标发生率(2018年)
四、收入相对贫困与多维相对贫困的比较分析
(一)静态比较:分离与重合特征分析
为了深入分析收入相对贫困和多维相对贫困之间的区别与联系,本文从总体、分城乡、家庭生命周期、多维相对贫困驱动等统计分析了两种方法识别的相对贫困人口分离与重合特征,考虑到篇幅有限和现实参考意义,仅报告了2018年的测算结果(表4)。
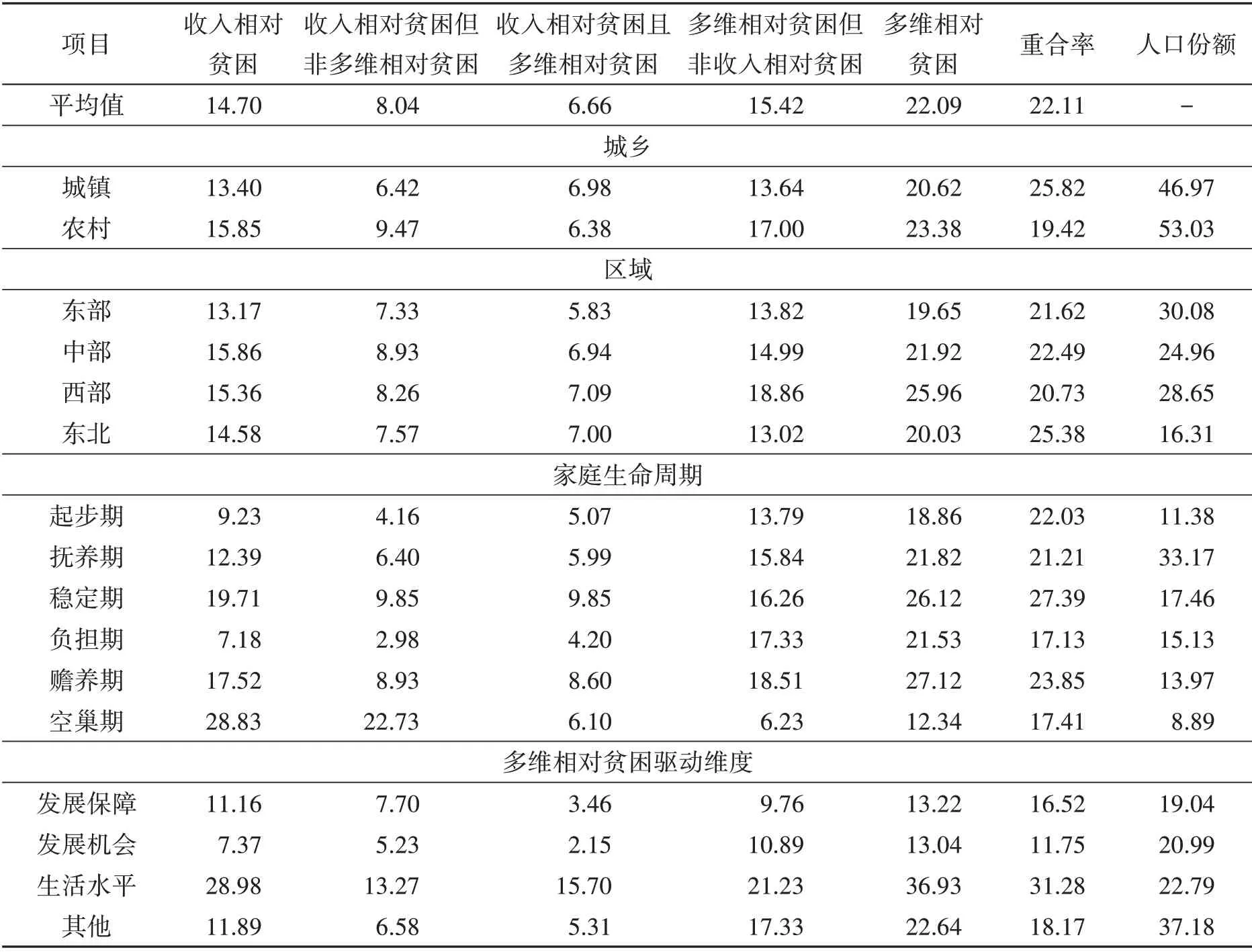
表4 收入相对贫困与多维相对贫困的分离重合特征(2018年) (单位:%)
其次,分城乡与分区域的数据能够进一步展示宏观层面的分离与重合特征。就城乡而言,不论是考虑收入相对贫困还是多维相对贫困,城镇的相对贫困发生率均低于农村,然而城镇识别重合率为25.82%,显著高于农村的19.42%,这意味着城镇陷入收入相对贫困的家庭存在更大几率同时陷入多维相对贫困,也说明农村的收入相对贫困遗漏了更多的多维相对贫困,因此多维相对贫困这一指标对于农村具有更重要的参考意义。对于分区域而言,收入相对贫困发生率最高的是中部,为15.86%,而多维相对贫困发生率最高的是西部,为25.96%,两种方法识别出来的相对贫困发生率最低的区域均为东部。此外,从重合率来看,由高到低依次为东北、中部、东部、西部,最高的东北重合率达到了25.38%。
再次,通过分家庭生命周期样本的数据可得出微观层面的分离与重合特征。处于空巢期、稳定期、赡养期的家庭更容易陷入收入相对贫困状态,其中空巢期的家庭由于缺乏劳动力,收入相对贫困发生率高达28.83%,是唯一一类收入相对贫困发生率高于多维相对贫困发生率的家庭。与此同时,处于赡养期、稳定期的家庭发生多维相对贫困要明显高于处于其他生命周期的家庭,分别为27.12%和26.12%。根据重合率可知,六种类型的家庭大致分为三个档次,识别重合率最低的为负担期的家庭与空巢期的家庭,这两种家庭的共同特征为既有老人又有儿童;处于中间位置的是起步期和抚养期的家庭,这两种家庭的共同特征为家中没有老人且劳动力数量较为充足;处于最高档次的为稳定期与赡养期的家庭,这两类家庭的共同特征为家中没有儿童(表5)。
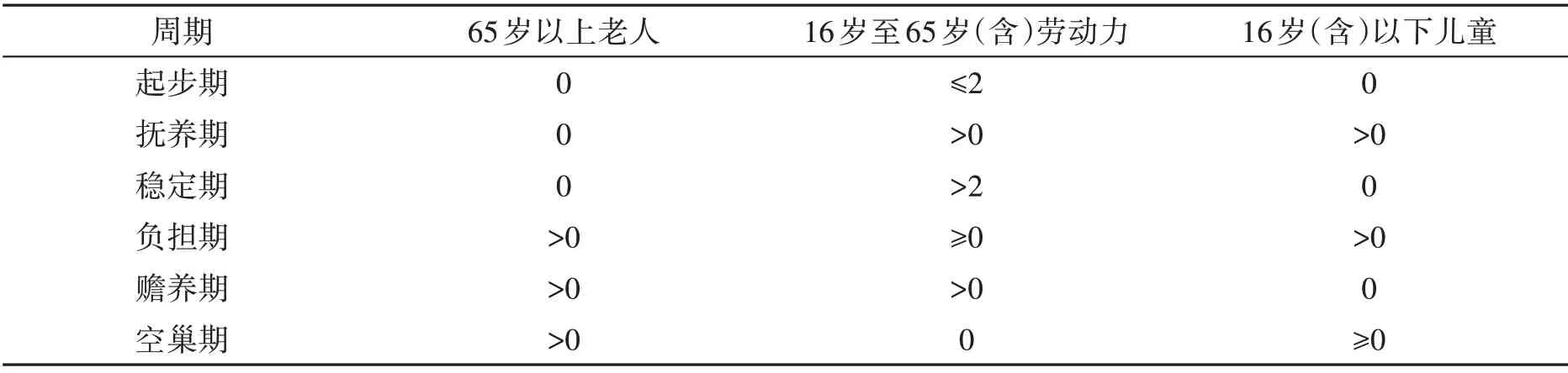
表5 根据人口特征的家庭生命周期划分
最后,分多维相对贫困驱动维度样本分析可进一步揭示收入相对贫困与多维相对贫困分离与重合的原因。按照多维相对贫困维度贡献份额将多维相对贫困群体分为四类,其在两种方法下识别出来的相对贫困群体由高到低分别是生活水平、其他、发展保障与发展机会。其中,发展机会和发展保障的识别重合率分别仅为11.75%和16.52%,这意味着收入相对贫困几乎无法识别在发展机会维度和发展保障陷入“困境”的家庭。与之相反,对于由生活水平作为主要多维相对贫困维度构成的家庭中,识别重合率高达31.28%,分离与重合的原因十分明显,即收入相对贫困识别出的贫困群体与多维相对贫困中生活水平维度作为主要贡献因素的家庭具有较高的重合率,但收入相对贫困无法识别在发展机会和发展保障维度陷入低福利状态的家庭。
综上分析,不论是从总体样本还是从分类样本来看,收入相对贫困与多维相对贫困的识别重合率均存在较大偏差,总体重合率为22.11%。从宏观层面上看重合率,城镇高于农村,东北高于其他区域;从微观层面上看重合率,稳定期和赡养期的家庭高于其他家庭,然而这两类家庭在两种方法测算下相对贫困发生率均较高。分多维相对贫困驱动维度的样本揭示了识别分离与重合的原因,即收入相对贫困主要能够反映多维相对贫困中的生活水平维度,因此以生活水平维度为主要贡献份额的多维相对贫困家庭与收入相对贫困有较高的重合率,反之则低。
(二)动态比较:跨期偏离分析
收入相对贫困与多维相对贫困的静态比较说明了两者识别重合率较低,那么伴随着家庭的收入相对贫困变动(脱贫或入贫),其多维相对贫困有多大概率同向或反向变动呢?表6 给出了2014—2016年和2016—2018年两个时期收入相对贫困转换过程中所伴随的多维相对贫困转换情况。
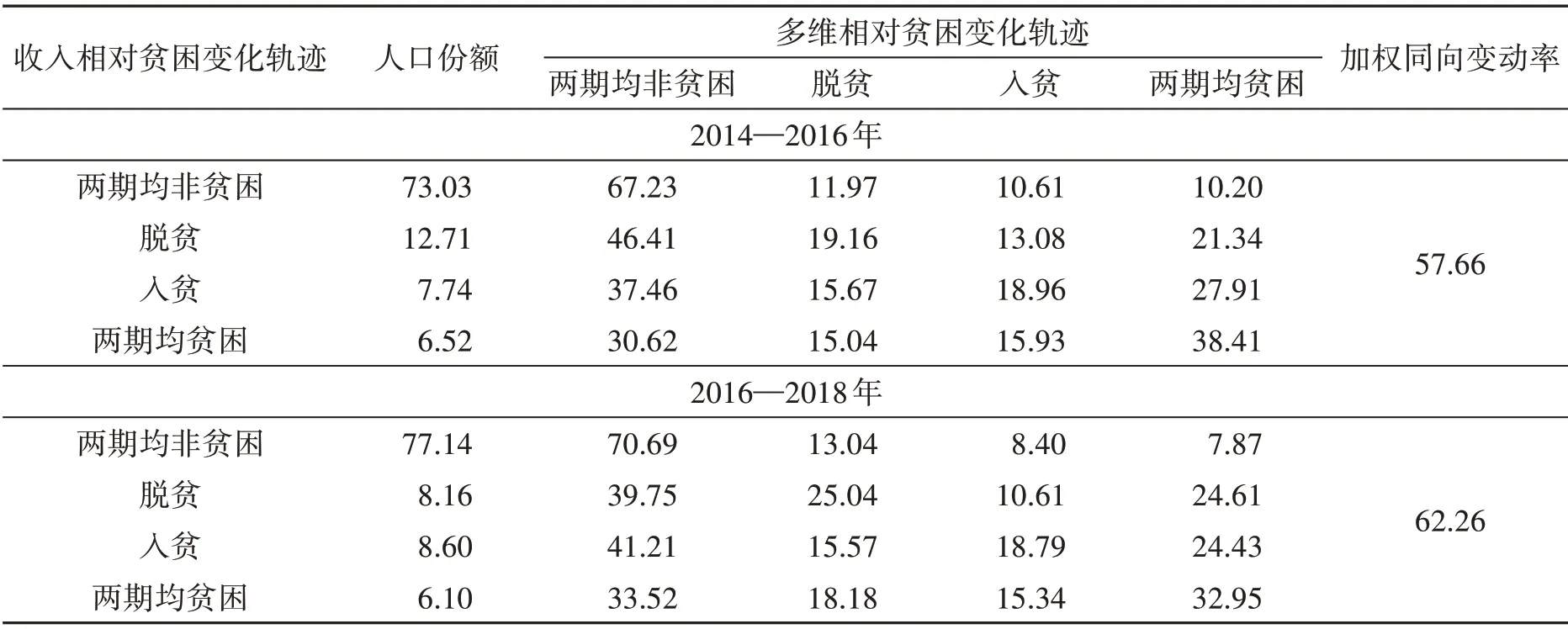
表6 收入相对贫困与多维相对贫困的跨期偏离分析 (单位:%)
以2016—2018年为例进行分析,2016年收入相对贫困发生率为14.26%,其中,8.16%的人脱离了收入相对贫困,但又有8.60%的人口进入收入相对贫困,其余6.10%无变化(仍处于收入相对贫困),因此2016—2018年收入相对贫困发生率略微提高了0.44%。在这一过程中,脱离收入相对贫困的8.16%家庭中有25.04%同时脱离了多维相对贫困,但也有10.61%的家庭虽然脱离了收入相对贫困,但陷入了多维相对贫困。与此同时,进入收入相对贫困的8.60%家庭中有18.79%的家庭同时也成为了多维相对贫困家庭,但其中15.57%的家庭进入了收入相对贫困的同时脱离了多维相对贫困。综合来看,伴随着收入相对贫困的变动,2014—2016年、2016—2018年的数据均显示,多维相对贫困同向变动的比例均大于反向变动的比例。采用集合的运算,根据式(11)可以计算2016—2018年加权同向变动率为62.26%,2014—2016年约为57.66%。从动态上分析说明,从收入相对贫困角度衡量的脱贫与入贫与从多维相对贫困角度衡量的脱贫与入贫仍有较大的差距。

(三)解释力比较
静态分析表明,两种方法识别出来的相对贫困群体有较大差别,而动态分析表明,两者之间的变动虽然同向比例高于反向比例,但仍有较大差距。因此,单独使用收入相对贫困与单独使用多维相对贫困均无法完整描述相对贫困群体,需要从解释力上对两种方法进行比较,探讨哪种方法对于相对贫困的本质更具有解释力。
1.模型构建。相对贫困的“本质”在于反映个体由于机会不均等而陷入了低收入或者低福利的不平等状态。为此,需要选取机会均等前提下的个体差异作为解释变量,讨论其对于两种方法测算结果的解释力。选取努力程度作为核心解释变量,并使用家庭工作时间(Work)作为努力程度的代理变量,理由如下:一是研究需要选择反映机会均等前提下的家庭特征差异作为核心变量,工作时间能够反映家庭为了摆脱贫困状态而进行的努力;二是教育水平、能力等指标具有较强的内生性问题,且与被解释变量多维相对贫困的指标体系中的部分内容有所交叉;三是中国家庭追踪调查数据中统计了个人的工作时间,易于加总到家庭中。构建计量模型如下:

其中,Poverty表示相对贫困状态,包括收入相对贫困和多维相对贫困,均为二值变量。Work为家庭工作时间,是模型的核心解释变量。向量Controls表示影响家庭贫困状态的一系列控制变量,u为残差。
2.变量选取与样本数据。被解释变量分别为收入相对贫困和多维相对贫困,核心解释变量为工作时间,定义为家庭劳动力人均每周工作时间。选取包括家庭规模与家庭结构的家庭特征变量、基于可持续生计框架,包括自然资本、金融资本、物质资本、社会资本、人力资本的家庭经济特征变量,以及包括区域属性、城乡属性和省经济的宏观层面变量作为控制变量。表7给出了模型中被解释变量、解释变量和控制变量所用指标、定义及其描述性统计分析。数据来源于中国家庭追踪调查,在删除了缺失值后得到由5931个家庭构成、共计3期(2014年、2016年和2018年)的均衡面板数据。由于新数据改变了样本分布,因此需要重新测算了收入相对贫困和多维相对贫困。

表7 变量的指标、定义及描述性统计分析
3.回归结果分析。鉴于被解释变量均为二值变量,可采用面板logit和面板probit模型,因为加入不随时间变化的宏观属性变量,因此使用随机效应和混合效应分别进行回归,所有回归模型均使用了因子工具变量(FIV)作为内生解释变量的工具变量(表8)。
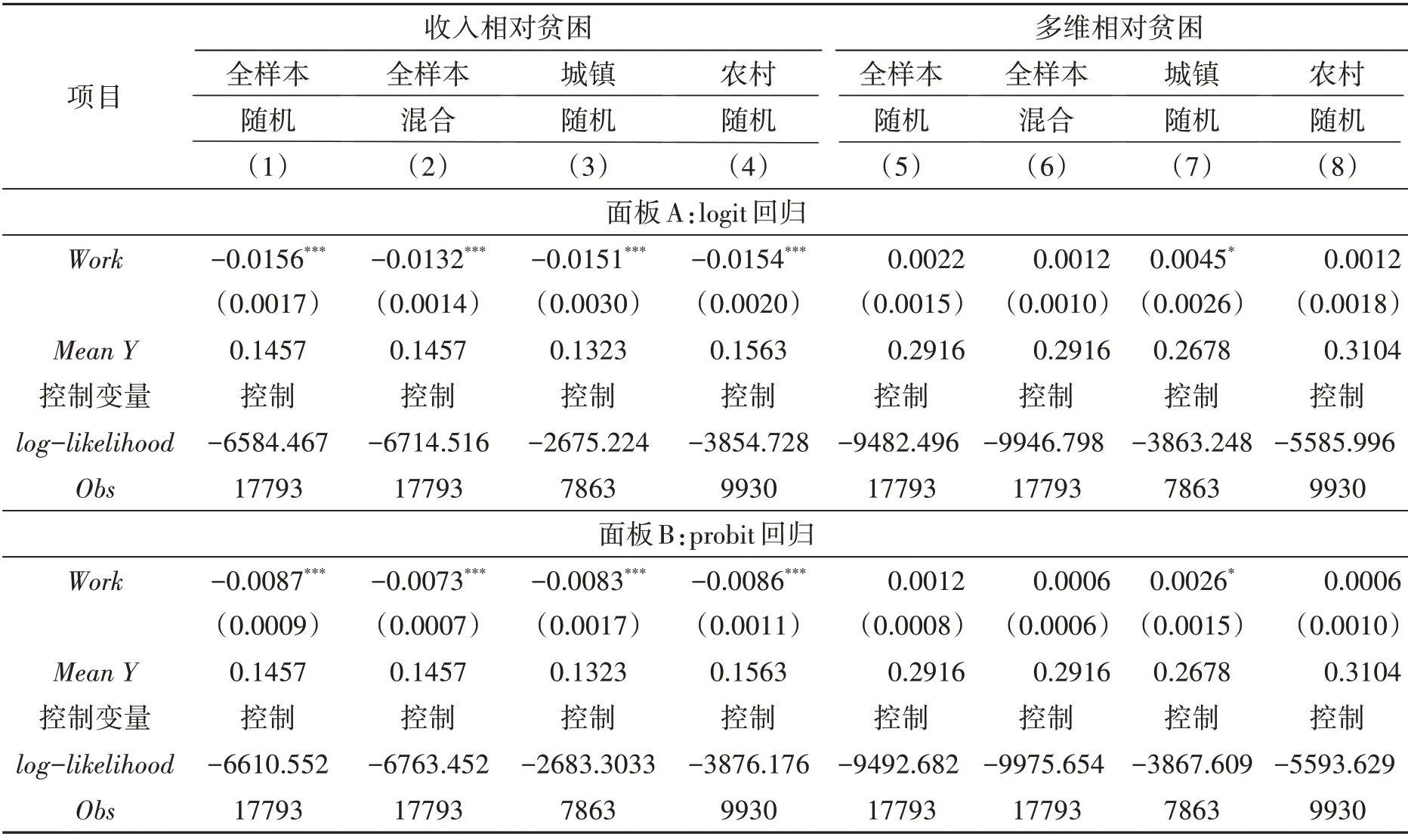
表8 回归结果
面板A 与面板B 的第(1)至(4)模型回归结果显示,以工作时间作为努力程度的代理变量,对于收入相对贫困具有非常好的解释力,所有模型的解释变量均通过了1%的显著性检验。家庭劳动力人均每周工作时间每提高1 个小时,可以降低陷入收入相对贫困状态的可能性约1.55 个百分点(由面板A第(1)列模型的几率比计算得出,限于篇幅未报告),这意味着家庭可以通过自身的努力,有效缓解收入相对贫困。收入相对贫困更多反映了机会均等的家庭差异造成的不平等,而这部分不平等属于良性的不平等,一定范围内的收入不平等有利于激发社会活力。
面板A 与面板B 的第(5)至(8)模型回归结果显示,工作时间的变化对多维相对贫困的影响效应并不明显,具体表现为:一是在统计上没有通过显著性检验,仅城镇样本的回归模型通过了10%的显著性检验;二是在经济学上不具有意义,系数为正且数值非常小,这意味着以工作时间作为代理变量的努力程度无法改变多维相对贫困,家庭很难通过自身努力改变多维相对贫困状态。换言之,多维相对贫困更多反映了由机会不均等产生的不平等,这违背了分配正义原则,损害了社会制度的内在公正性,是中国逐步实现共同富裕过程中需要着力避免的问题。
综上所述,收入相对贫困主要反映了机会均等造成的不平等,而多维相对贫困主要体现了机会不均等造成的不平等,后者的出现对社会公平正义建设,对实现共同富裕无疑是更为严重的损害。虽然收入相对贫困的测度更为方便,对社会公共资源的使用较小,但多维相对贫困能够更为全面和准确地反映测度对象是否处于低福利状态,且这一状态难以通过自身努力得到缓解。因此,未来在相对贫困治理阶段开展相对贫困人口识别工作,不能单独关注收入相对贫困,多维相对贫困是一个更能反映相对贫困本质的指标。
五、相关政策建议
“水之积也不厚,则其负大舟也无力”,中国现阶段的当务之急是研究制定符合国情的相对贫困标准、构建相对贫困治理的四梁八柱,这对于今后相对贫困人口的识别、贫困治理措施的执行以及长效机制的实现,都具有重大的现实意义。
(一)未来中国应当同时使用货币方法和多维方法两套方案对相对贫困进行衡量
从必要性来看,货币方法与多维方法所识别的人群差异较大,同时使用两套方案进行衡量能够更为全面地覆盖相对贫困群体,进而针对陷入相对贫困的类型实施缓解对策。从可行性来看,中国在脱贫攻坚阶段虽然使用的是货币贫困单一监测标准,但已经制定了“两不愁三保障”的多维度贫困退出标准,具备采用两套方案的实践基础。
(二)未来中国应当分城乡、分省份设定相对贫困标准
当前中国城乡发展、区域发展差距仍然较大,较之于绝对贫困所体现的“生存性”需要具有普遍统一的认知,相对贫困所凸显的“发展性”需要在城乡、区域之间的认知仍有较大的差异。基于这一判断,未来中国在制定相对贫困标准时,不能囿于旧有的思维框架,需要针对相对贫困的相对性、复合性作出相应的调整,也即是分城乡、分省份设定相对贫困标准。
(三)选择适合中国国情的相对贫困标准
新标准下的收入相对贫困标准使用收入中位数的40%为佳,多维相对贫困标准则考虑以发展保障、发展机会和生活水平为三个主要维度。一方面,新标准下收入相对贫困发生率应当控制在15%左右,本文通过数据测算表明使用收入中位数的40%作为收入相对贫困线较为合适,这一阈值也符合学界对于相对贫困治理起步阶段收入标准的认知;另一方面,多维相对贫困需要体现由“生存性”需要过渡到“发展性”需要的特点,本文设置的多维相对贫困标准包含了发展保障、发展机会和生活水平三个主要维度,分别对应着“生存性”需要的提高、“发展性”需要的可行能力以及“发展性”需要的标准,可以作为参考。
(四)根据相对贫困治理阶段的发展动态调整相对贫困的标准
上述三点建议主要适用于相对贫困治理的起步阶段,然而相对贫困具有长期性、顽固性的特点,其将一直存在于人类社会当中,因此随着相对贫困治理的推进需要对两套方案进行调整。一个总的思路是,阈值标准方面逐步上调,以体现中国在治理相对贫困方面的成效;识别测度上由两套方案并行逐步转为多维相对贫困为主的识别体系,以反映多维方法在揭示相对贫困“本质”方面的参考价值。
