中国地基GNSS/MET 水汽产品质量控制及与再分析产品的对比评估
2022-10-09远芳廖捷周自江
远芳 廖捷 周自江
国家气象信息中心, 北京 100081
1 引言
水汽是大气中重要的变量,它既在地球气候系统的能量和水循环中扮演关键的角色,也是灾害性天气形成和演变中的重要因子。地基全球卫星导航系统气象(GNSS/MET)水汽资料利用放置在地面上的接收机测量GNSS 卫星信号穿过大气层到达地面时所引起的时间延迟量并进一步反演出天顶方向整层大气或信号斜路径上的水汽累积量。地基GNSS/MET 水汽探测可以获取高时效、高时空分辨率的大气水汽场,有助于更准确地分析天气系统的演变特征。随着地基GNSS/MET 水汽观测站网不断加密和资料传输业务化程度不断提高,该资料已广泛用于天气、气候特征分析(梁宏等, 2006;Fujita et al., 2012)以及与卫星反演水汽、探空、再分析等资料的对比评估(Liu et al., 2006; Wang et al., 2007; Zhang et al., 2018; 梁宏等, 2012)。有研究表明,大气可降水量PWV(Perceptible Water Vapor)资料在短时间内的快速增加与降水有密切关 系(Seco et al., 2012; Shoji, 2013; Yao et al.,2017),另外随着地基水汽资料的积累,已有研究人员开始利用该资料开展气候变化研究(van Malderen et al., 2014; Wang et al., 2016)。资 料 同化与数值预报是地基GNSS/MET 水汽资料重要业务应用方向,同化地基GNSS/MET 资料能够提高模式对水汽相关要素的预报效果。在美国,NOAA 自1998 年开始评估该资料在天气预报同化/模式系统的效果,测试表明同化PWV 资料对湿度的预报有一定的正效果(Gutman et al., 2004)。英国气象局自2007 年开始在其北大西洋和欧洲数值预报模式中同化了天顶总延迟(Zenith Total Delay,简称ZTD)要素,改进了相对湿度和云的预报(Bennitt and Jupp, 2012)。法国气象局2006 年6月起在业务系统Arpege 中同化ZTD 资料,试验表明同化ZTD 能够改进天气尺度环流和降水评分(Poli et al. 2007)。仲跻芹等(2017)的研究也表明,同化ZTD 可以有效提升预报系统的降水预报效果,特别是在无探空资料参加同化的预报时次,同时也发现同化ZTD 的效果优于同化PWV 的效果。英国气象局统计了单位观测数据量在同化中的影响力,结果发现GNSS/MET 资料排名第二(Jones et al., 2020)。
有诸多原因会影响地基GNSS 水汽产品的质量,卫星相关误差(如轨道误差、卫星钟差、卫星仰角过低等),信号传播相关误差(如电离层误差、多路径效应等),接收机相关误差(如接收机钟差、设备故障等)以及观测过程相关误差(如观测环境噪声、障碍物对天线的遮挡等)都可能造成资料出现各种错误(Wang et al., 2007; Bock et al., 2016)。另外在原始资料解算过程中需要用到投影函数和地面气压、气温等变量,若数据传输过程中出现要素不全或数据文件打包压缩过程出现失误或数据上传不及时等问题也会影响数据质量。因此在进行应用之前对资料进行质量控制是必不可少的步骤。Wang et al.(2007)利用PWV 与探空和微波辐射计资料对比之前采用了离群值检查,选取4 倍标准差作为阈值,剔除了不到0.1%的数据。英国气象局的资料进入同化前剔除了接收机高度与背景场模式地形相差300 m 以上或与模式背景场相差超过55 mm 的ZTD 资料(Bennitt and Jupp, 2012)。法国气象局同化ZTD 资料时采用了初猜场质量控制检查,剔除了大约不到3%的数据(Poli et al.,2007)。李昊睿等(2014)在同化前对PWV 进行了界限值检查并剔除了与背景场相差较大的数据(绝对差值超过6 mm)。仲跻芹等(2017)也基于模式背景差设计了由多个检查步骤组成的质控算法,各月份未通过质控的数据比例约为2%~8%。
总体而言,现有的研究在开展天气与气候分析之前以基本的离群值检查(即剔除偏离均值3 或4倍标准差的粗大误差)为主,较少进行严格的质量控制。同化前的质量控制算法更细致,但是被剔除的数据与模式密切相关,例如剔除与模式地形相差较大的台站数据(Bennitt and Jupp, 2012)等。此外相对于数据本身的质量而言,同化前的质量控制主要关注与背景场的偏差。Bock et al.(2016)建立了一套独立于模式的质量控制方案,但是其中多个检查步骤用到了GІSP 软件(Zumberge et al.,1997)相关的参数,对其他软件(例如GAMІT;Herring et al., 2010)并不完全适用。
气象资料的质量控制算法基本都带有统计特征,比较常用的方法是将观测值与某个参考值进行比较,超出特定的阈值范围则认为该观测值是疑误数据(WMO, 1993),参考值可以是邻近站或相邻时间点上的值或另一个观测平台或数值模式结果(Bennitt and Jupp, 2012)。阈值的选取方法一般包括统计信度、偏离平均值的程度或预设标记比例等(Durre et al., 2008)。作为统计结果,几乎所有算法都面临第一类错误(弃真)和第二类错误(存伪)的风险,所以需要充分评估两类错误后综合确定阈值。本文参考了Graybeal et al.(2004)提出的预设标记比例的思路,即每一个检查都对预设比例的数据进行标记(例如5%或1%)。考虑到这种方法必然会导致弃真的问题(Durre et al., 2008),本文引入综合决策算法,定位被多项检查反复标记的数据,并最终判断这些数据是否正确、可疑或错误,以达到降低误判、提高判断准确率的效果。
本文第2 部分介绍本研究用的观测和再分析数据,第3 部分介绍质量控制方法及评估结果,第4部分利用质量控制后的数据开展几套再分析资料的对比评估,最后是结论与讨论部分。
2 数据
2.1 地基GNSS/MET 水汽资料
本文采用全国1254 站2016~2019 年的小时观测数据作为样本来统计质量控制所用参数以及评估质量控制方案效果。Liang et al.(2015)介绍了原始观测资料的收集与处理流程。图1 是台站分布,这些台站中245 个来自中国大陆构造环境监测网络(CMONOC,蓝点),1019 个来自中国气象局观测站网。从图中可以看到气象局台站主要密集分布在我国东部地区,空间分布不均匀,不同省份之间有较大差异;CMONOC 台站空间分布相对均匀,我国中西部地区主要以CMONOC 台站为主。
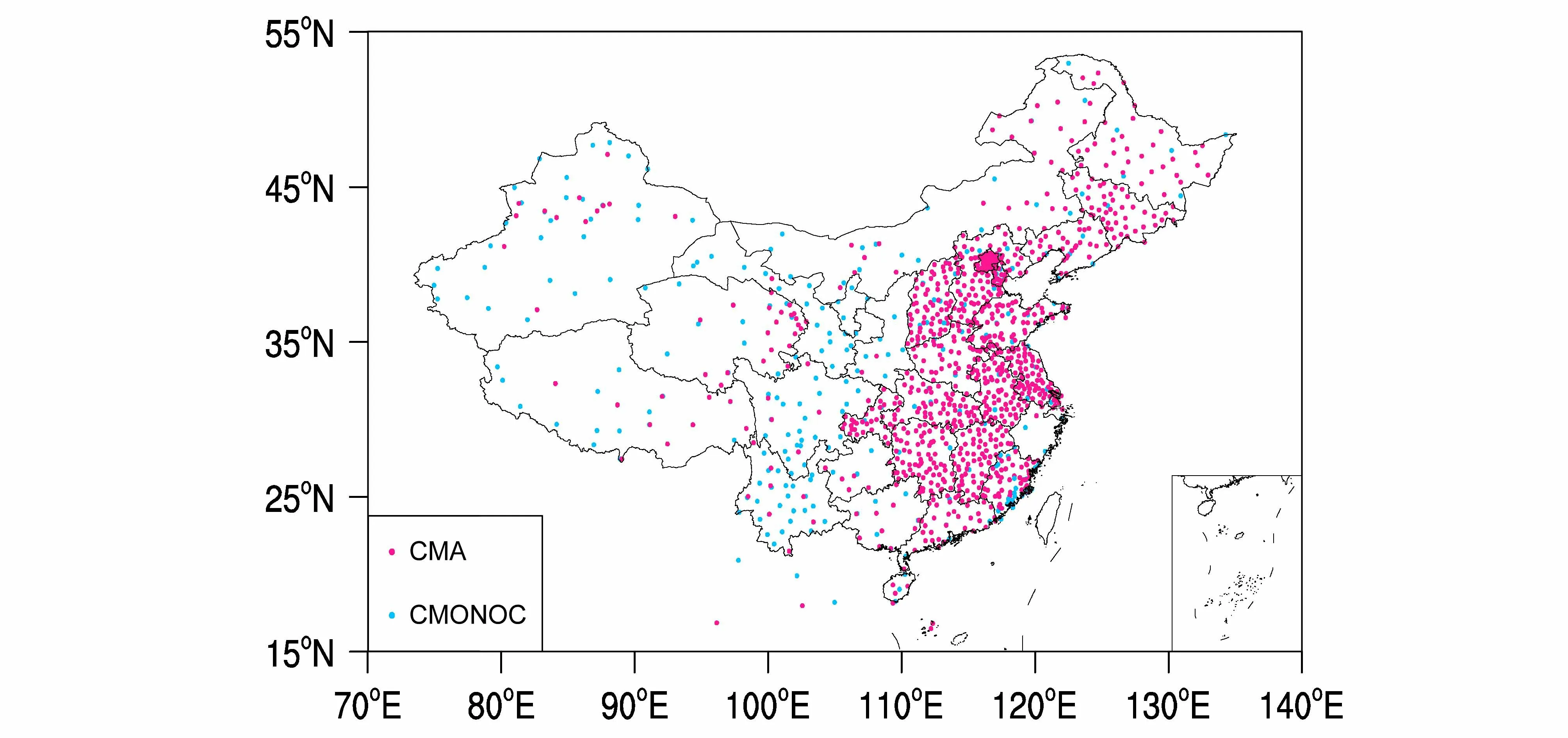
图1 地基全球卫星导航系统气象GNSS/MET 台站分布,红点代表气象局(CMA)观测站点,蓝点代表中国大陆构造环境监测网络CMONOC 观测站点Fig. 1 Distribution of GNSS/MET (Ground-based Navigation Satellite System/METeorology) sites. The red dots denote the CMA (China Meteorological Administration) sites, whereas the blue dots denote the CMONOC (Crustal Movement Observation Network Of China) sites
2.2 再分析资料
本文用PWV 观测资料与中国第一代全球大气再分析产品CRA(China’s first-generation global atmosphere reanalysis,http://idata.cma/idata/web/fact/toTechReport2 [2021-10-08])以及另外四套再分析资料提供的PWV 要素或整层积分水汽含量TCW(Total Column Water)进行了对比评估:ERAІnterim(Dee et al., 2011)、ERA5(Hersbach et al.,2020)、JRA55(Kobayashi et al., 2015)和NCEPDOE AMІP-ІІ(Kanamitsu et al., 2002)。上述几类再分析产品均未同化GNSS/MET 水汽资料。评估时取液态水的密度为1×103kg m-3,将TCW 换算成PWV,采用双线性插值的方法将不同分辨率的再分析格点资料插值到最近的GNSS/MET 站点上,再用公式(1)和公式(2)计算观测资料与再分析资料的偏差Bias 和均方根误差RMSE。

3 综合质量控制(CQC)方法与效果评估
CQC 方法包括质量检查环节和综合决策环节两部分(图2),其中质量检查部分包括界限值检查、临近点检查、滤波检查等7 个检查模块。综合决策环节包括权重评分系统和最终判断算法。
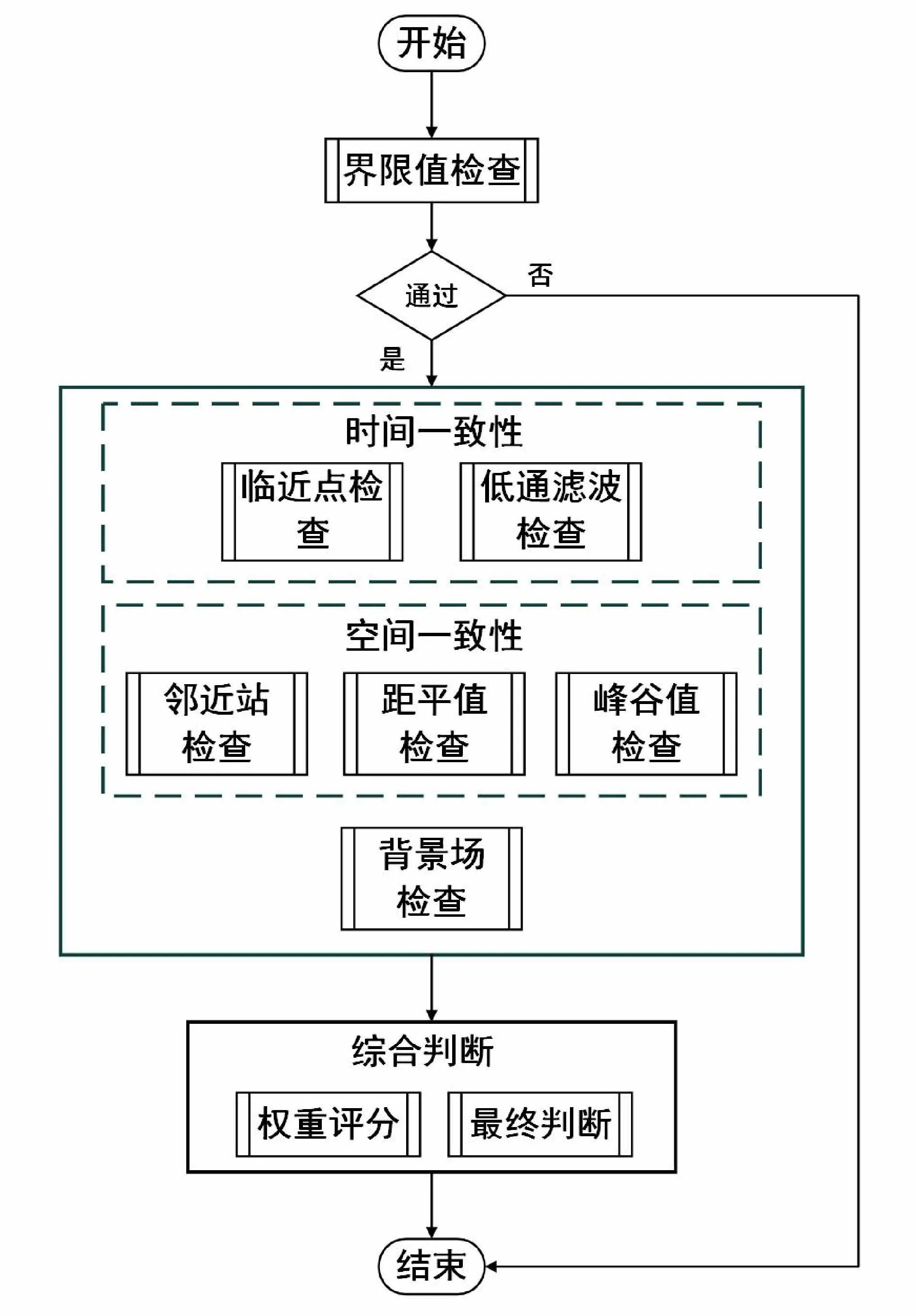
图2 GNSS/MET 水汽产品质量控制流程Fig. 2 Quality control flow of the GNSS/MET data
3.1 质量检查
质量检查包括界限值检查、考察时间一致性的临近点检查和低通滤波检查,考察空间一致性的邻近站检查、距平值检查和峰谷值检查,以及针对同化应用的基于背景场的粗大误差检查。本文中“阈值”指的是某个观测值合理的取值范围的上下限,而“参数”则是与阈值的选取相关的统计量。CQC 中除界限值和峰谷值检查以外的几项检查采用的是预设标记比例的方法(Graybeal et al.,2004),这里我们对10%、5%、1%和0.1%四个不同标记比例(以下称为PS10、PS5、PS1 和PS0.1,PS 为Parameter Scheme 的简称)进行评估后,最终选择PS1 作为质量控制参数。
3.1.1 界限值检查
界限值检查通常是质量控制算法的第一步,目的是检查数据是否在该要素观测值允许的物理范围内(仪器、逻辑等)。ZTD 的界限值范围是[1000.0 mm, 3000.0 mm],PWV 的界限值范围是[0 mm, 100 mm](Jones et al., 2020)。
3.1.2 临近点检查
作为小时值数据,相邻两个时次数据之间的变化量应该在合理的范围内。为了确定这个范围,我们计算了所有台站的时间序列上每个非缺测点与其前一个非缺测点的差值绝对值 γti=|Vi-Vi-1|的概率分布函数(i=1, 2, 3,···,N,N为观测数据量),以ZTD 为例,90%、95%、99%和99.9%的函数值对应的γti值分别是14 mm、18 mm、27.5 mm和37 mm(表1),即γti值超过上述参数的比例分别为总数据的10%、5%、1%和0.1%。当待检数据与前后两个时次数据的绝对偏差γti均超过表1中PS1 对应的参数时,视为不通过临近点检查。

表1 不同标记比例下的参数Table 1 Parameters of different flag rate
3.1.3 低通滤波检查
低通滤波检查与临近点检查都是针对单个台站,目的是找出时间序列上的离群点。针对所有台站的时间序列,选取7 小时时间窗,对观测序列进行加权滑动平均[见公式(3)和公式(4)]得到其低通滤波值Fi,计算每个非缺测点Vi与Fi的差值绝对值γfi=|Vi-Fi|的概率分布函数,确定不同概率分布函数值所对应的参数PF(表1)。当待检查数据与其滤波值的差值绝对值γfi超过表1 中PS1 对应的参数时,视为未通过该步检查。

式中,Fi是i点的加权滑动平均值(i=1, 2, 3,···,N,N为观测数据量),hj是权重系数,d是数据与滑动窗口内均值的绝对偏差,n是滑动窗口内非缺测数据量。
3.1.4 邻近站检查
地基水汽资料有较好的空间一致性,在地形相差不大的情况下,某个站的某次观测值与其周围邻近参考站的差值应该保持在合理范围内。邻近站检查的目标是找出那些数值上偏离周围台站的观测。对于某时刻的空间场,计算每个点Vi与其邻近站平均值Mi的差值绝对值γni=|Vi-Mi|的概率分布函数,确定不同概率分布函数值所对应的参数PN(表1)之后,选择PS1 作为质量控制参数,对于某个目标点Vi,取为[Mi-PN,Mi+PN]作为Vi的阈值,超出阈值范围视为未通过该步检查。
本研究中邻近参考站选取方法如下:
(1)空间距离方面,目标站和待选参考站空间距离不超过200 km,海拔2500 m 以下两站高度差不超过200 m,海拔2500 m 以上两站高度差不超过500 m。
(2)相关性方面,以2016~2019 年共四年数据为统计样本,要求目标站和待选参考站相关系数超过0.8,同时要求待选参考站样本量超过6500,并且与目标站在同一观测时间能匹配的样本量超过2000。有些台站自身或周围台站序列较短或缺测较多则可能无法取得参考站。
(3)空间分布方面,以目标站为中心,参考站尽可能位于四个不同象限内。对于满足距离条件和相关性条件的待选参考站,分别在目标站的四个象限内按相关系数大小排序,目标站的第1 至第12 个参考站依次在四个象限内挑选,即第1、5 和9 个待选参考站是目标站为原点的第一象限中相关系数最高的三个台站,第2、6 和10 个待选参考站是目标站为原点的第二象限中相关系数最高的三个台站,以此类推。若某个象限中待选参考站不足则跳过该象限,在下一个象限中进行选择。总共不超过12 个参考站。
按照上述条件,在台站相对密集的东部地区,多数台站都能在四个不同象限找到邻近参考站。图3 是山西汾阳站(站号53679,红色十字)的12 个参考站(红点)分布,可以看到邻近参考站相对均匀的分布在目标站周围。图中有些空间距离较近的台站由于时间序列过短或缺测数据太多而无法成为目标站的参考站。

图3 山西汾阳站(红色十字,站号53769)及其周围站点,其中红点为所选的汾阳站的邻近站Fig. 3 Fengyang station of Shanxi Province (red cross, station ІD:53769) and nearby stations. The red dots denote the selected reference stations
3.1.5 距平值检查
距平值检查也是针对空间场的检查,旨在剔除空间距平场中的离群点。首先计算各台站各月的多年平均值Mv,随后计算各台站数据Vi相对于Mv的距平ANOi并进行升序排列,得到上下四分位值(Q75和Q25,即75%和25%),然后计算四分位间距外的距平值与Q75和Q25的差值 γai(公式6)的概率密度函数,
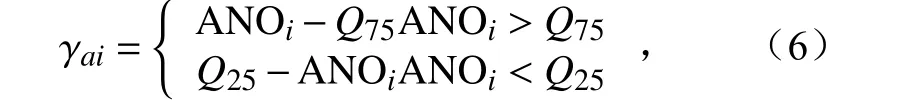
其中,i=1, 2, 3,···,N,N为某时刻的观测数据量。这里比较 ANOi与上下四分位而不是中位数或平均值的差异,是因为不同时刻的 A NOi可能不是正态分布,例如某时刻有大范围强降水发生时,空间场上正距平会明显多于负距平。计算选取PS1 时 γa对应的参数PA(表1)之后,对于某个目标点,取[Mv-Q25-PA,Q75+PA+Mv]作为阈值。如超出阈值,视为未通过该步检查。
3.1.6 峰/谷值检查
对于大量样本的评估发现地基GNSS/MET 水汽数据的异常值经常表现为一个空间场中的孤立极值,正常情况下这些极值可以通过对比该点与时间和空间上的临/邻近点进行检查,但是对历史资料的分析发现有部分时次、部分台站数据完整性较差,难以找到参考点对目标数据进行判断,因此本文在CQC 算法中增加了峰/谷值检查,考察某个时刻的整个空间场中最大和最小的三个点是否超出特定范围。将某时刻空间场中所有N个非缺测数据进行降序排列Vi(i=1, 2, 3,···,N,N为观测数据量),评估最大(峰值,i=1, 2, 3)和最小(谷值,i=N-2,N-1,N)的三个点偏离其他点的程度。这里我们参考了Houchi et al.(2015)的方法,比较相邻两组数据的差异,并利用经验试错的方法对参数进行调整,最终确定Di,计算公式为对峰值,从V3开始,若D3超过8.0,则将V3作为该时刻的阈值,空间场中超过或等于V3的数据会被标记出来,若D3未超过8.0,则考察D2。对谷值从VN-2开始,也进行类似处理。

3.1.7 基于背景场的粗大误差检查
地基水汽资料在同化和预报中有重要意义,本文也提供了针对背景场的基本质量控制,剔除与背景场偏差较大的观测点。对于某时刻的空间场,计算每个点(O)与背景场(B)的差值绝对值γbi=|Oi-Bi|的概率分布函数,确定不同概率分布函数值所对应的参数PB(表1)之后,对于某个目标点Vi,取 [Bi-PB,Bi+PB]作为Vi的阈值,对超出阈值的数据进行标记。
3.2 综合决策算法
综合决策算法包括两部分:权重评分系统和最终判断算法(Decision Making Algorithm,简称DMA)。首先,根据CQC 方案的设计思路给出相应权重(表2)。若某数据通过了某项质量控制检查,则该检查权重为0,若未通过,则权重为表2所示。权重的选取遵循以下原则:(1)若某个目标观测数据未通过“界限值检查”和“峰/谷值检查”,则可以认定该数据为“错误”,这两个检查的权重设定为1.5~2.0 之间。(2)对于采用预设标记比例的检查(即除界限值检查和峰谷值检查的其他五项检查),任意一项检查的权重低于1.0,任意两项检查权重相加低于1.5,任意三项检查权重相加高于1.5。基于上述条件,五项检查的权重设置为0.5~1.0 之间。(3)在给定范围内对各检查模块的权重进行微调,使得任意项检查权重值相加的结果互不相同,以保留质量控制过程信息。

表2 各检查模块权重Table 2 Weights of the checks
每个观测数据经过质量控制后会得到一个质控评分(SQ,公式13),为其经过的检查权重之和。数据经过质量检查后可能出现的结果共64 种情况,权重值的设计使得不同组合的SQ不会重复,通过分析SQ能够反推某个数据未通过哪些检查。例如,某数据的SQ是2.87,则表示它未通过滤波检查、峰/谷值检查和背景场检查(0.65+1.53+0.69=2.87)。

为了用户使用方便同时也考虑当前数据业务质量控制码的相关规范,经过综合判断之后我们用DMA 给数据标注最终质量控制码,如表3 所示。

表3 最终判断算法Table 3 Decision making algorithm
3.3 质量控制结果分析
以2019 年数据为样本,选取PS1 为各检查模块的预设标记参数,经过综合判断后未通过质控的ZTD 数据比例为0.125%,PWV 数据比例为0.129%。我们同时分析了标记比例分别为PS10、PS5 和PS1 时未通过质量控制的数据比例。当标记比例为PS0.1 时,未通过质控的ZTD 数据比例为0.043%,PWV 数据比例为0.046%,存在较多漏判数据。当标记比例为PS5 时,未通过质控的ZTD数据比例为0.836%,PWV 数据比例为0.841%。通过PS1 方案但是未通过PS5 方案的数据多在阈值边界,对其正确性的判断较为困难,可能存在误判的风险。以山西永和站为例,图4 中横坐标0 时刻是2019 年9 月9 日12:00(协调世界时,下同)的观测,该点未通过滤波检查和邻近站检查。可以看到该点确实是一个极大值点,也是前后24 h 内的最大值,但是该点未表现出明显的“离群”特征。在实时数据处理业务或者在研制基础数据集时,由于数据用途广泛,应该采取较为“保守”的质量控制算法以尽可能保留更多数据,因此本文选择了PS1 作为标记的参数。

图4 山西永和站(站号53852)2019 年9 月9 日12:00(图中横坐标0 时刻)及前后24 h 大气可降水量PWV 变化(黑色实线)及相关QC 阈值(PS5 参数。粉线:临近点检查,蓝线:滤波检查,橙线:邻近站检查,紫线:距平值检查,绿点:背景场检查,深红线:峰/谷值检查)。灰色区域是能够PS5 参数条件下通过CQC 的数据取值范围Fig. 4 GNSS/MET precipitable water vapor PWV data (black dotted line) 24 h before and after 1200 UTC on September 9, 2019, from Yonghe station in Shanxi Province (station ІD 53852) and the associated QC thresholds of buddy check (pink line), low-pass filter check (blue line),neighboring station check (orange line), anomaly check (purple line), background check (green dots), peak–valley value check (carmine line) (PS5 parameters; the gray shaded area denotes the range of the data that can pass CQC under the PS5 parameter conditions)
图5 给出PS1 条件下,ZTD 和PWV 不同错误类型所对应的数据比例。从图中可以看到,未通过质控的ZTD 数据中最多的三类组合依次是T+F(1.205)、A+F(1.24)和T+A(1.145),而PWV数据中最多的是T+F(1.205)、A+N(1.19)和F+N(1.25)(字母含义见表3)。对于ZTD,接近一半的疑误数据是由时间一致性的两项检查(T+F)标记出来,而对于PWV,两项空间一致性检查的权重相对于ZTD 有所增加,这可能是由于从ZTD 解算PWV 的过程中用到了地面气压、气温和高度等参数,可能将局地因素引入PWV,比起ZTD,某个点的PWV 值偏离周围台站的可能性增加。

图5 不同错误类型所占比例Fig. 5 Proportions of different error types
图6 是多个错误类型的个例,可以看到质量控制算法能够通过不同检查的组合剔除离群点(图中0 时刻的点)。对质控结果的分析发现,未通过两项质控而被检出的疑误观测数据通常超出阈值(图中阴影)但与阈值较为接近(图6b、c、d),我们通过对大量个例的人工分析认为在PS1 条件下将检出的数据判为疑误是较为合理的。

图6 同图4,但为(a)湖北宜昌(站号57461)2019 年8 月27 日12:00,(b)河北滦平(站号54420)2019 年7 月13 日12:00,(c)重庆巫山(站号57349)2019 年7 月3 日05:00,(d)江苏徐州(站号58027)2019 年7 月15 日06:00 PWV 观测和PS1 条件下的阈值范围Fig. 6 Same as Fig.4, but for (a) Yichang station in Hubei Province (station ІD 57461), (b) Luanping station in Hebei Province (station ІD 54420), (c)Wushan station in Chongqing Province (station ІD 57349), and (d) Xuzhou station in Jiangsu Province (station ІD 58027). The gray shaded area denotes the range of the data that can pass CQC under the PS1 parameter conditions
分析发现,观测数据中的离群点经常以异常大值的形式出现。为了验证质控算法的有效性,我们参考Houchi et al.(2015)采用的百分位方法对质量控制前后的观测数据进行了分析。将每个时刻所有台站的观测值按照从小到大的顺序排列,利用公式(14)计算百分位值。图7 是ZTD 2018 年质量控制前后各时刻的空间场中多个百分位的变化曲线,这几条最外层的百分位曲线基本能够展现大值的分布,其中图7a 中“100%”代表了各时刻观测场中的最大值。可以看到质量控制后绝大部分异常大值被剔除,但是图7a 中仍有极个别异常大值由于观测数据量太少、CQC 算法难以发挥作用而无法剔除。

图7 2018 年全国台站ZTD 质量控制前(蓝线)后(红线)不同百分位值的分布Fig. 7 Time series of the ZTD percentiles of all sites before (blue line) and after (red line) quality control in 2018
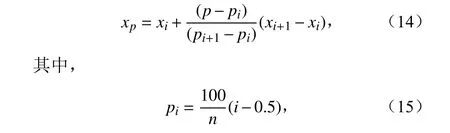
式中,i=1, 2, 3,···,n,n为某个时刻观测样本数。
在缺乏“真值”的情况下,利用数值模式结果对观测资料进行评估是验证资料质量的重要手段( 王丹等, 2020)。目前全球多套再分析资料均未同化地基GNSS/MET 水汽资料,因此观测与再分析资料作为两个相对独立的数据源可以充分利用各自优势进行对比分析。本文采用CRA 作为背景场来评估质量控制的效果。为了更客观地进行对比,这里的质量控制结果关闭了背景场检查。图8 给出的是PS1 条件下观测与背景场对比的效果,从图8a可以看到被剔除的点观测与背景场的值均存在较大差异,质控前后观测与背景场的相关系数从0.940提高到0.964。图8b 则是2018 年未通过CQC 的观测PWV 与背景场的对比,图中黑色虚线是二者的拟合曲线(公式16),可以看到其较为明显的偏离了对角线。观测值与背景场的相关系数为0.742,明显低于图8a 所示的正常情况。

图8 (a)2019 年4 月1~7 日18:00 质量控制前(红点加蓝点)、后(蓝点)PWV 观测值(Obs)与背景场(CRA)对比的散点图;(b)2018 年未通过综合质量控制的观测场(Obs)与背景场(CRA)的散点图。图中黑色虚线是观测与背景场的线性拟合结果,灰色虚线是若观测值与背景场相等时线性拟合结果。Fig. 8 Comparison of PWV between observation and background field (CRA): (a) The red dots denote the error data detected by the QC algorithm at 1800 UTC from April 1 to 7, 2019; (b) blue dots denote the error data detected by the QC algorithm in 2018 (the black dashed line denotes the linear fitting, the gray dashed line denotes the linear fitting when the observations equal to the background data)
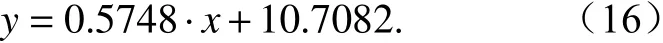
图9 是PWV 观测与背景场对比的数据量和均方根误差(RMSE)的时间序列(为保证资料稳定性,这里只挑选完整性超过40%的台站与再分析资料进行对比,另外为了更独立评估算法效果,图9 中的质量控制关闭了背景场检查)。结合表4可以看到,质量控制在一定程度上降低了观测与再分析的均方根误差,在2018 年1~5 月以及2019年4、5 月份原始RMSE 波动比较明显时,质量控制效果也格外显著,表明本文提出的方案能够有效稳定资料质量。
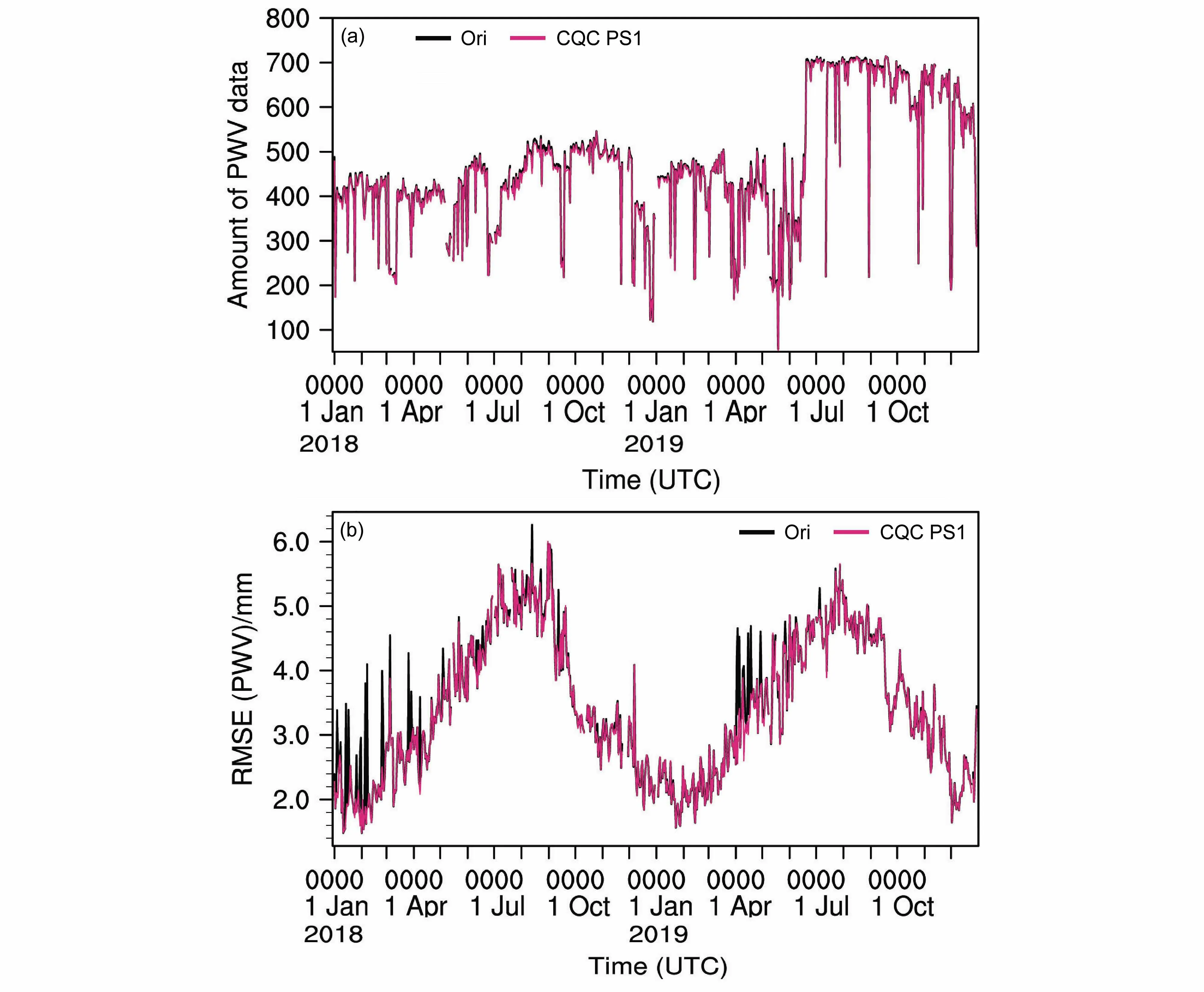
图9 2018~2019 年每日00:00 质量控制前(黑线)后(红线)用于与背景场进行比较的(a)PWV 的数据量和(b)观测与背景场的均方根误差(RMSE)时间序列Fig. 9 Data quality of (a) CRA for PWV and (b) RMSE of observation and background fields at 0000 UTC everyday of 2018–2019:Before (black)and after (red) quality control

表4 2018~2019 年每日00:00 质量控制前后PWV 观测与CRA 的均方根误差(RMSE)Table 4 RMSE of observation and CRA for PWV before and after quality control at 0000 UTC everyday of 2018–2019
4 与再分析资料的对比评估
本文用2018~2019 年经过质量控制的PWV观测与多套再分析资料进行了对比。为了更客观比较不同再分析资料,这里的质量控制关闭了背景场检查。图10 是观测与背景场的平均偏差(Bias)和均方根误差(RMSE)的时间序列(进行了5 点平滑)。从整体来看,春季和秋冬季二者偏差(O-B)基本在零线上下波动(图10a),其中冬季略为负偏差,春秋季略为正偏差。在水汽更充沛的夏季出现较为明显的正偏差,表明再分析资料中夏半年整层大气含水量低于观测。CRA、ERAІnterim 和ERA5 三套再分析资料与观测结果更为一致,优于JRA55 和NCEP2 再分析结果,特别在夏半年。表5 给出观测与CRA、ERA-Іnterim、和ERA5 三个再分析资料的平均偏差和均方根误差,可以看到CRA 的全国平均偏差为0.633 mm,均方根误差为3.650 mm,介于ERA-Іnterim 和ERA5 之间。

图10 2018~2019 年00:00 GNSS/MET PWV 观测与几套再分析(CRA(红线)、ERA-Іnterim(蓝线)、ERA5(黑线)、JRA55(黄线)和NCEP2(绿线))数据的偏差(Bias, a)和均方根误差(RMSE, b)时间序列Fig. 10 Time series of (a) Bias and (b) RMSE of PWV observation and reanalysis: CRA (red), ERA-Іnterim (blue), ERA5 (black), JRA55 (yellow)and NCEP2 (green) at 0000 UTC of 2018–2019

表5 2018 年GNSS/MET PWV 00:00 观测资料与CRA、ERA-Interim 和ERA5 再分析资料的平均偏差(Bias)和均方根误差(RMSE)Table 5 Averaged Bias and RMSE of PWV observation and reanalysis of CRA, ERA-Interim and ERA5 for the year 2018 at 0000 UTC
图11 是冬季(1~3 月)PWV 观测与CRA 和ERA5 再分析资料对比的空间分布,可以看到冬季全国大部分地区再分析资料相对于观测以偏湿为主,四川和华南几个省份略有偏干(图11a 和c)。整体而言CRA 和ERA5 的Bias 分布较为一致(图11e),CRA 在西北地区有少量正偏差,表明冬季CRA 在西北地区的含水量比ERA5 略低一些。有个别台站观测与再分析的差异较为显著(主要位于江西地区),提示该地区可能存在数据观测、处理或传输过程的错误,原因有待进一步分析。另外从RMSE的分布(图11b 和d)可以看到各省之间存在较为明显的差异,表明不同省份之间观测资料质量也有差别。图12 是夏季(7~9 月)观测与CRA 和ERA5 再分析资料的对比(O-B),可以看到夏季CRA 和ERA5 再分析在太行山脉一线、华南、青藏高原以东地区均存在偏干(图12a 和c),CRA在西北地区偏干比ERA5 更明显(图12e)。两套再分析RMSE 的分布基本一致(图12b、d 和f),CRA 在西北地区RMSE 更大一些;此外不同省份之间RMSE 的差异在夏季表现的更加明显,可能与各省观测所用仪器以及数据处理方式有关。综上所述,CRA 和ERA5 两套再分析与观测的偏差空间分布基本一致,都在水汽较多的时段(夏半年)和空间范围内(南方地区)整层大气含水量略低于观测,对干旱少雨中国西部地区模拟的水汽含量也略低,其中CRA 在西北地区的PWV 比ERA5 更低。

图11 2018 年1~3 月每日00:00 GNSS/MET PWV 观测数据分别与CRA、ERA5 再分析数据的对比分析:(a)PWV 与CRA 的偏差(BiasC);(b)PWV 与ERA5 的 偏 差(BiasE);(c)PWV 与CRA 的 均 方 根 误 差(RMSEC);(d)PWV 与ERA5 的 均 方 根 误 差(RMSEE);(e)BiasC 与BiasE 的差值;(f)RMSEC 与RMSEE 的差值Fig. 11 Comparison of observation and reanalysis data: (a) Bias between PWV observation and CRA (BiasC); (b) Bias of PWV observation and ERA5 (BiasE); (c) RMSE of PWV observation and CRA (RMSEC); (d) RMSE between PWV observation and ERA5 (RMSEE); (e) difference between BiasC and BiasE; (f) difference between RMSEC and RMSEE for January to March at 0000 UTC everyday of 2018

图12 同图11,但为2018 年7~9 月每日00:00 数据Fig. 12 As in Fig.11, but for July, August and September at 0000 UTC everyday of 2018
5 结论与讨论
地基GNSS/MET 水汽资料有高时效、高时空分辨率的等优点,在资料同化、降水特别是强降水预报等方面有重要作用,但是多种原因都可能造成资料出现各种错误,在资料投入科研业务应用前将错误数据剔除是必不可少的步骤。本文介绍了针对GNSS/MET 地基水汽资料的综合质量控制(CQC)算法。CQC 算法由质量检查环节和综合决策环节两部分组成,质量检查环节首先用界限值检查剔除超出物理允许值范围的数据,随后针对时间一致性进行临近点检查和低通滤波检查,针对空间一致性进行邻近站检查、距平值检查和峰谷值检查,以及针对同化应用的基于背景场的粗大误差检查。
本文采用预设标记比例的方法获得了质量控制过程中所需要的大量参数,但是如前文所述,该方法必然会造成第一类错误(“弃真”),因此引入综合决策算法来定位被各检查模块反复标记的数据以减少误判,并最终判断是否正确、可疑或错误。本文选用PS1 方案统计确定了各个质量控制检查过程所需的参数和阈值。评估表明,在假设每项检查未通过检查的比例约为1%的前提下,对各检查结果进行综合判识后,最终未通过质量控制的ZTD数据比例为0.125%,PWV 数据比例为0.129%。本文通过个例分析、百分位分析以及与再分析资料的对比评估等三个方面证明质量控制算法较为合理,能有效剔除粗大误差。
随近些年观测手段的不断发展,新型观测资料越来越多,但是新型资料的质量控制方法、特别是质量控制所需参数往往比较匮乏,本文提出的“多个检查模块+预设标记比例+综合决策”的质量控制思路可以供读者参考借鉴,开展对这些新型资料的清洗。
在实时应用时,按照Liang et al.(2015)所介绍的资料处理流程,目前我国GNSS/MET 资料业务上采用组网处理的方法,各台站观测文件基本上传完成后再开展解算ZTD 和PWV 的过程,因此在质量控制时空间一致性相关的检查(邻近站检查、距平值检查、峰/谷值检查)都可以正常进行。时间一致性相关的两个检查中,滤波检查需要用到当前时刻之后三小时的观测值,在实时业务中无法开展;临近点检查可在本文3.1 节的基础上略做调整,改为考察当前时刻与前一时刻的差值是否超出阈值。此外,在实际业务应用时,也可以根据需要选取表1 中所示的更严格的阈值。
利用质量控制后的地基水汽观测数据与CRA、ERA-Іnterim 和ERA5 等五套再分析资料进行了对比评估。评估表明,几套再分析资料整层大气含水量在冬季整体略高于观测,夏季则明显低于观测;空间上在中国南方地区和西部地区模拟的水汽含量低于观测,这种情况在夏半年更加明显。相对于观测,CRA 的平均偏差(O-B)为0.633 mm,均方根误差为3.650 mm,介于ERA-Іnterim 和ERA5 之间,明显优于JRA55 和NCEP2 再分析结果。本文的评估采用的是各套再分析提供的PWV 或TCW(整层水汽含量)要素,不同模式地形差异、各高度层水汽含量差异等因素造成的影响都包含在其中,造成图10 所示差别的原因还有待于进一步分析。
