基于时间序列的微博谣言检测*
2022-09-28韩连金潘伟民张海军
韩连金 潘伟民 张海军
(新疆师范大学计算机科学技术学院 乌鲁木齐 830054)
1 引言
微博是帮助人们发布、传播和共享信息的开放式社交媒体平台。凭借文本简短及使用便捷等特点,吸引了大量用户,改变了社会的信息传播格局。作为开放的公共信息平台,微博的低门槛造就了谣言产生的低成本,导致其不可避免地被注入大量谣言[1],而这些谣言的传播会对用户使用、平台发展和国家稳定造成不良影响[2]。因此,研究如何快速有效地检测微博中的谣言具有重要的现实意义。
微博事件是由源微博及其相关的微博、转发和评论一起组成,是典型的时间序列数据,包含丰富的上下文信息[3]。对于庞大的时间序列数据,可以将一个较长的时间序列划分为几个相对较短的子序列[4]。分割后的时间序列数据进行了一定的压缩,模型复杂度会降低,有利于计算[5]。针对分割后时间序列的数据挖掘,同样符合数据变化的模式和规律[6]。因此,本文针对时间序列划分方法进行研究,提出基于聚类的微博事件划分方法。根据微博在时间上的聚合程度,针对时间戳进行聚类,将微博事件分割成若干时间段,构建时间序列。同时,基于GRU 网络构建事件分类模型,自动捕捉微博事件特征随时间变化的情况,对谣言事件进行检测。实验结果表明,本文提出的基于时间序列的微博谣言检测方法可以有效检测谣言事件。
2 相关工作
早期谣言检测普遍采用基于机器学习的方法,其核心技术包括特征提取和训练分类器。Castillo等[7]提取基于文本、用户信息、话题和消息传播的特征,利用J48 决策树进行检测,准确率达到86%;Yang等[8]从微博中提取基于内容、账号、传播、客户端和位置的特征,在基于SVM 构建的检测模型上获得了5%左右的性能提升;毛二松等[9]开始考虑情感倾向性和意见领袖传播影响力等深层特征。此外,也有研究通过构建时间序列获得更高的谣言检测性能。Kwon 等[10]引入时间序列拟合模型来捕获传播过程中特征随时间变化的情况,根据选择的特征对谣言进行分类,召回率在87%到92%之间;Ma 等[11]在Kwon 等[10]的基础上使用动态时间序列扩展了时间序列拟合模型;王志宏等[12]引入域划分的思想,通过构造动态时间序列特征提高谣言检测准确度。总体上讲,基于机器学习的方法初具成效,特征提取开始挖掘深层特征,同时通过构建时间序列提升性能。但该类方法依赖于特征工程,需要耗费大量的人力、物力和时间,并且需要一定的专业背景。
为了解决基于机器学习方法存在的问题,研究者探索出基于深度学习的方法,自动学习数据中包含的特征。Ma等[13]首次使用深度学习进行谣言检测,利用tf-idf得到时间段向量表示,然后训练循环神经网络自动学习微博特征,在双层GRU 网络上获得91%的准确率;Yu 等[14]利用doc2vec 获取时间段向量表示,采用卷积神经网络自动学习微博特征,在评价指标上优于支持向量机等对比方法;Chen 等[15]将微博按固定数量分成时间段,通过注意力机制选择性地学习时间序列内的特征用于谣言检测。基于深度学习的方法可以自动学习特征,取得了较好的检测效果。同时,由于事件之间的微博发帖数量存在很大的差异,每个神经元不可能只处理一条微博。因此,出现了基于等长时间间隔(TETS)[13]和基于固定帖子数(PETS)[15]的微博事件时间序列构建方法。其中,TETS 方法可以保证模型具有合适的输入序列,而PETS 方法可以使每个时间段有合理的数量[16]。上述方法虽然都考虑了要合理划分时间序列,但是时间长度固定会导致时间序列内帖子数量不合理,出现帖子数量过多或过少的问题;固定帖子数划分出的时间序列又不能保证模型得到合适的输入序列。在这种情况下,本文考虑事件在时间维度上的分布,提出基于聚类的微博事件划分方法,构建合理的时间序列作为模型输入,训练GRU 网络自动学习特征,对谣言事件进行检测。
3 本文模型介绍
谣言事件检测可以看作是二分类问题,对给定的微博事件集合E={Ei},本文任务就是检测事件Ei是不是谣言。其中,Ei={pij} 包括源微博及其相关的微博、转发和评论,pij表示事件的某一条文本。在本文提出的基于时间序列的谣言检测模型中,首先对数据进行预处理,其中包括去噪、去停留词和分词;然后基于k-mean 算法针对时间戳进行聚类,实现对微博事件的分割,构建时间序列;最后将时间序列使用doc2vec 进行向量化作为GRU 网络的输入,并进行参数调优,返回谣言和非谣言这两个类别的概率。具体结构如图1 所示。

图1 谣言检测模型结构
3.1 时间序列构建
本文提出基于聚类的微博事件划分方法,首先将源微博作为时间序列的第一个时间段,之后基于k-mean 算法根据每条微博的时间戳进行聚类,将微博事件划分成若干时间段,将所有的时间段按时间顺序组成时间序列。描述如下:对于每一个事件Ei={(Pij,tij)},Pij表示事件相关的微博,tij是对应微博的时间戳。设置k-mean 的聚类数目为K,即将事件划分为K 个时间段。基于聚类的微博事件划分方法伪代码如算法1所示。
算法1:基于聚类的微博事件划分算法


3.2 GRU网络
循环神经网络是处理序列数据的常用神经网络,在许多自然语言处理任务中取得了良好的效果。其中GRU网络对谣言事件的检测效果较好[13],可以学习语法特征和语义特征。因此,本文采用GRU 网络进行特征学习,其包括四个部分的计算,结构如图2所示。

图2 GRU单元结构
首先是重置门。GRU 使用重置门选择前一时刻要放弃的信息,其中Wz和Uz为权重,ht-1为前一时刻的输出值,bz为偏置:

接下来是更新门。GRU 通过更新门选择有多少信息需要保存并更新当前时刻,其中Wr、Ur为权重,ht-1为前一时刻的输出值,br为偏置:

然后GRU 决定如何合并之前的信息和新的输入,这是计算当前输出的一个重要步骤,其中Wa和Ua为权重,ba为偏差:

最后,GRU根据以上结果计算输出:
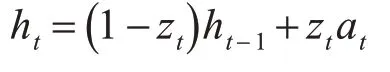
随后将GRU 网络输出的特征矩阵传入由神经元和Softmax 激活函数构成的全连接层,进行Softmax操作计算谣言和非谣言这两个类别的概率。
4 实验及结果分析
本文采用Ma 等[13]公开的用于谣言检测的数据集,包含4664 个事件及事件对应的标签,其中包含谣言事件2313 件和非谣言事件2351 件,微博总数3752459条,表1为实验数据集统计表。同时,在谣言检测任务中使用准确率、精确率、召回率和F1值做为评价指标。

表1 实验数据集统计表
4.1 验证时间序列划分方法
本文首先对提出的划分方法所构建时间序列的合理性进行验证,实验结果如图3 所示。同时为了验证基于聚类划分方法的有效性,本文和基于等长时间间隔(TETS)及基于固定帖子数(PETS)的时间序列划分方法做对照实验,实验结果如图4 所示。
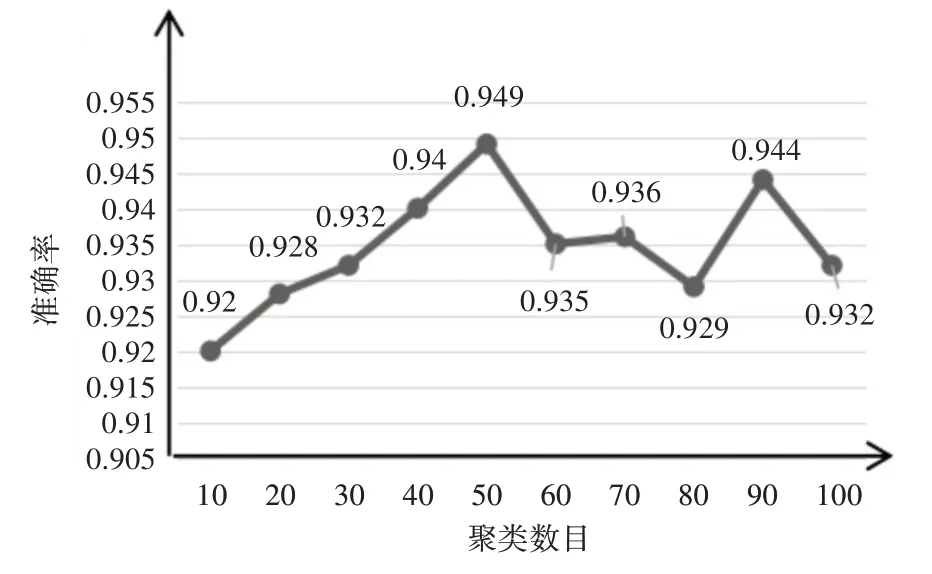
图3 不同聚类数目的检测结果

图4 不同划分方法的检测结果
通过图3 可以看出,在构建谣言事件时间序列的过程中,合理的时间序列划分能够影响谣言检测任务的性能。其中,聚类数目在50 和90 时获得了94%的准确率,时间序列划分能反映事件在时间上的聚合程度。上述实验结果表明,构建时间序列应该考虑事件在时间上的分布特点,合理的事件划分得到的时间序列应该跟数据在时间上的分布有关。
图4 实验结果表明,PETS 对谣言检测的性能提升最少,在准确率上与TETS 相差3.4%。由表1可以看出,事件平均时长是2460.7h。因此,固定的时间间隔划分可以得到合适的输入序列,取得优于PEST 的性能。由表1 还可以看出事件最大帖数为59318 而最小帖数只有10,事件发帖数在时间维度上分布是不均匀的,所以固定的时间长度会导致时间序列内部分时间段的帖子数过多或过少。相反,基于聚类的方法根据设定聚类数目保证了合适的输入序列,同时k-mean算法利用时间戳进行聚类,根据时间上的聚合程度,保证了每个时间段具有合理的帖数。与这两种方法相比在准确率、精确度、召回率和F1 值上都取得了更好的结果,能提高谣言检测性能。
4.2 验证基于时间序列的谣言检测模型
为了验证基于时间序列的谣言检测模型的有效性,本文将与选取的基准方法在相同的数据集上开展实验,实验结果如表2所示,以下为4个选取的基准方法。

表2 不同模型的检测结果
1)DTC 模型[7]。该模型属于基于机器学习的方法,通过特征工程提取特征,并采用J48 决策树进行分类。
2)SVM-TS 模型[11]。该模型通过动态时间序列模型来捕获微博传播过程中特征随时间变化的情况,采用SVM分类器进行分类。
3)GRU-2 模型[13]。该模型先构建时间序列,然后采用tf-idf 计算得到每个时间段的向量表示,最后采用双层的GRU 网络来学习微博特征实现对谣言事件的检测。
4)CAMI模型[14]。该模型先将微博事件划分为等长的时间段,并利用doc2vec 方法获取时间段内向量表示,之后利用卷积神经网络学习微博特征进行事件的分类。
实验结果表2 表明,基于机器学习方法的DTC模型和SVM-TS 模型实验结果在评价指标上相对较低。其原因在于通过人工提取特征进行谣言检测,特征选取主观性强且无法获得深层潜在特征及其关系。同时,本文提出的方法和GRU-2 模型使用了相同的网络结构,对谣言事件的召回率同样达到95.6%,能很好地学习语义等特征。而在基于聚类的微博事件划分方法的帮助下准确率能达到96.7%,比利用卷积神经网络的CAMI 模型高出3.4%。与其他基准方法相比,本文方法的实验结果在其他评价指标上同样表现更好,由此验证了所提方法可以有效地检测微博中的谣言。
5 结语
本文提出了一种基于时间序列的微博谣言检测方法,利用基于聚类的微博事件划分方法,根据微博在时间上的聚合程度将微博事件分割成若干个时间段,构建的时间序列能提高谣言检测性能。同时,基于GRU 网络构建谣言检测模型,捕捉微博事件特征随时间变化的情况。该方法在对微博数据集的实验中取得了理想的效果,准确率达到96.7%,为微博谣言检测提供了新的有效方法。在进一步的研究中计划对时间序列内每个时间段进行特征提取,获得更细粒度的特征,进一步提升谣言检测的效果。
