增量文本软聚类速度改善算法设计及仿真
2022-09-28刘艳,周斌,2
刘 艳,周 斌,2
(1. 武汉工程科技学院信息工程学院,湖北 武汉 430200;2. 华中科技大学软件学院,湖北 武汉 430200)
1 引言
相对于普通文本而言,增量文本包含的数据信息量较大,在以往的增量文本聚类算法中,通常在计算时会存在较高的时间复杂度,导致计算性能下降,且不适用于动态变化文本集聚类,同时,硬聚类方法只将一个文本划分一个类别[1-3],无法全面展示文本信息,而软聚类能够依据主题的类别划分信息,使相同类别的文本信息分配到同一处中[4,5]。
目前,有较多学者研究文本的聚类算法,例如马武彬等[6],研究基于改进NSGA-Ⅲ的文本空间树聚类算法,但该算法计算时间复杂度较高,会使聚类计算时的聚类时间延长。除此之外,还有学者研究基于语义簇的中文文本聚类算法,但该算法仅能够处理中文文本,在对增量文本进行聚类时依然需要大量的时间。因此,本文研究基于群体智能的增量文本软聚类算法,通过划分语义序列特征,构建基于蚁群算法的增量软文本聚类计算,并采用Python语言构建SCAST程序实现算法计算过程。
2 增量文本软聚类算法
2.1 语义序列特征分析
由于增量文本存在一定数量的长文本,且具有多主题特性,因此,通过计算语义序列相似关系对序列集合的覆盖度进行计算,并对得到的结果进行聚类能够有效降低增量文本向量空间维数,缩短文本软聚类的计算时间[7]。
在语义序列中并不存在文本集中的全部信息[8],仅存在文本自身信息,因此,有效分析语义序列,能够得到增量文本中更加详细的共同点。分析语义序列的基本概念:
设需要聚类的增量文本集合为D={d1,…,dk,…,dn}(1≤k≤n),其中,dk表示每个文本,dk中的某个词汇序列由s描述,即s=w1w2…wm,而s中e(1≤e≤m)区域内的词汇由we描述。通过以下流程设定语义序列,使其能够应用于增量文本集。
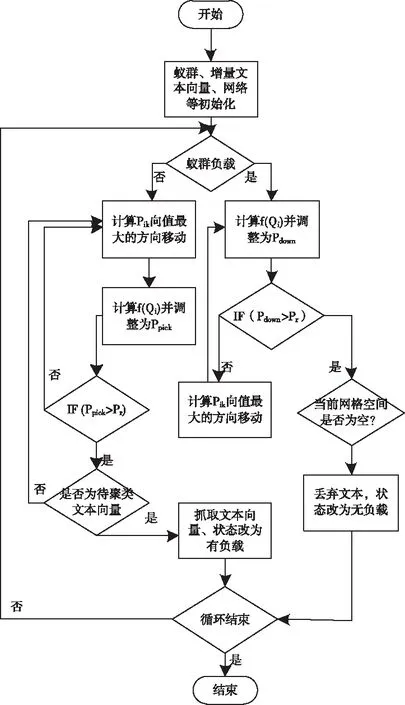
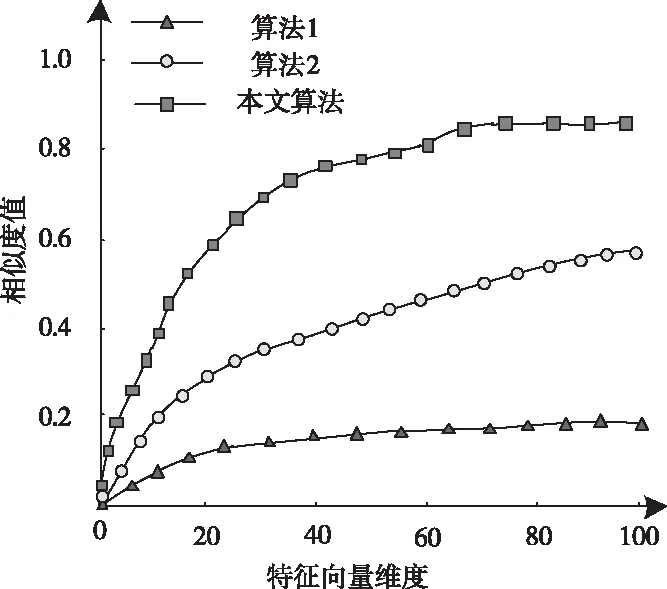
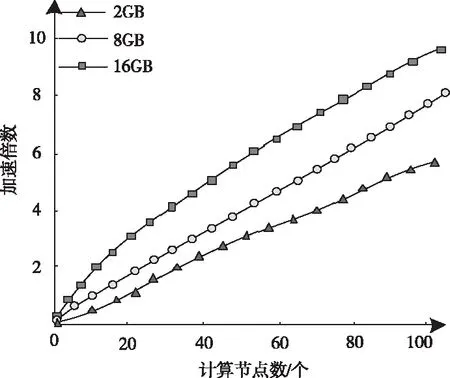
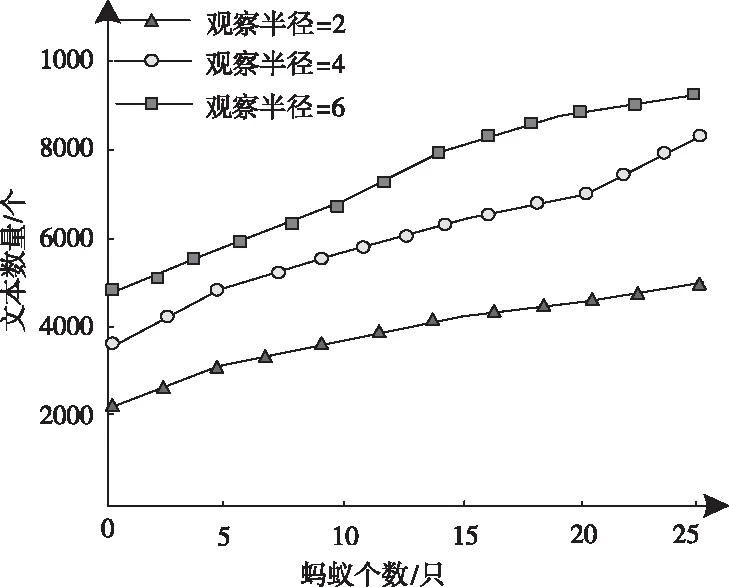
1)设定s内区域e中的词汇距离σ(e)为词汇we到词汇wh之间的词汇数量,设为σ(e)=e-h,词汇we=wh,同时we≠wk(1≤h 2)设ρ(e)=1/σ(e),即s内区域e中的语义密度ρ(e)为此处词汇距离的倒数。 在现实中,可将单个文本看作长度较长的词汇序列,而词汇序列s内区域e中的词汇距离即为σ(e),若σ(e)较短,则可以表示文本中某段落内的词汇we出现次数较多,即该词汇we的密度很高,所以,由此可认定在局部区域中,密度较高的词汇能够描述出该区域内的局部语义特性[9,10]。 3)设语义序列为s[e]=we1we2…wer,该序列为s中的子序列,在该序列中,e=[e1,e2,…,er](1 |s[e]|>1 (1) 0 (2) ρ(ek)≥δ,1≤k≤r (3) (e1-ε≤eh (er (4) (∀wek,wel∈s,ek≠el)→wek≠wel, 1≤k≤r,1≤l≤r (5) 上述公式中,δ、ε均表示阈值。 当剔除s中的低密度词汇之后,留下的一个连续词汇序列即为s[e],连续的含义为:s[e]内邻近的两个词汇在初始文本s中的位置差应不高于已设定的阈值ε。已设定的条件为:s中的非空子序列构成s[e];在该语义序列中的词汇间应存在连续性;s[e]内的词汇均应为局部频繁状态;需保证s[e]前后距离存在一段低密度范围,以保障s[e]不会出现无限扩展;确保s中不会出现重复词汇。 4)熵重叠。熵重叠能够描述出文本集合D的每个类Cq中的文本全部候选类中的划分情况,可通过式(6)计算 (6) 式(6)中,当dk为某个指定聚类的概率时通过pk=1/fk描述,而dk中存在的语义序列数量由fk描述。文本集合D的聚类结果集合为C={C1,…,Cq,…,Ct}(1≤q≤t),其中,Cq表示每一个类。若Cq中的每个dk只能够表明一个语义序列,则熵重叠为0,当fk逐渐增加,熵重叠也会上升,由此可知,熵重叠值越低,聚类纯度越好,这是由于熵重叠主要衡量语义序列分辨文本的能力。依据该特征,构建文本软聚类算法,实现增量文本聚类。 群体智能(Swarm Intelligence)是现阶段应用较为广泛的人工智能技术,随着该技术的发展已逐渐应用于社会、经济等各个领域[11]。群体智能算法中包含粒子群算法与蚁群算法等,本文选取蚁群算法实现增量文本软聚类。在蚁群算法中,由于蚁群的移动存在一定的随机性,因此,通过信息素操控蚂蚁移动能够加快算法的收敛,使聚类速度得到提升。在本文软聚类算法中,依据上述分析得到的文本语义词序特征,将其摆放在二维平面中,并为每个信息随机分配初始区域,全部蚂蚁均可通过随机形式在网格中爬行,之后计算群体相似度,得到计算结果后,采用概率转换函数继续计算,将相似度调整为蚂蚁抓取或丢弃的概率。通过大量蚂蚁的爬行,可以使相同属性的增量文本信息汇集在相同范围内。 通过图1表示基于蚁群算法的增量文本软聚类过程。在图1中,通过f(Oi)描述群体相似度;Ppick描述抓取的概率;Pdown描述丢弃的概率;Pr表示随机函数。 图1 增量聚类算法流程图 某个待聚类文本与当前区域内全部其它文本的综合相似性,即为群体相似度,通过式(7)计算该相似度 (7) 式(7)中,局部环境由Oj∈Neights×s(r)描述;通过b×b设定单元r的邻域面积;而对象属性空间内Oi、Oj的间距由u(Oi,Oj)描述;相似度因子为α,同时α表示群体相似系数,α能够直接对聚类数量造成影响,因此,α为比较重要的参数,当α越大,则会导致群体相似度f(Oi)变大,使得并不存在相似性的对象归类到同一处,以此降低聚类数量并提升收敛速度,若α取值越低,则会使收敛时间变长以及聚类数量增大。 与群体相似度f(Oi)存在关联的函数,即为概率转换系数,通过概率转换,能够使群体相似度调整为文本对象的抓取概率与丢弃概率。 其中,抓取操作是在蚂蚁不存在负载的情况下,抓取蚂蚁邻域内的文本对象,确定该文本对象可以抓取的概率可通过式(8)计算 (8) 而丢弃操作是指在蚂蚁负载文本情况下,若发现空闲网格,则蚂蚁可丢弃该文本对象,确定丢弃的概率可通过式(9)计算 (9) 式中,可变动的参数为kd、kp,文本对象Oi与邻近对象之间的平均相似度测量结果为f(Oi)。 本文通过Python语言构建SCAST程序,聚类算法的计算过程,具体设计如下: 初始化网格grid与蚂蚁列表antList; for(迭代次数)i∈iterationdo{ for(eachant∈antList)do{ if((ant_tv==null)&&(xy_tv!=null)) {Computer f(Oi); P_pick←Computer Ppick(Oi); if(P_pick>r)then {抓取Oi;} } else if((ant_tv!=null)&&(xy_tv==null)){ Computer f(Oi); P_drop←Computer Pdrop(Oi); if(P_drop>r)then {丢弃Oi;} for(i=0;i C.add(cov(S[e])); for(k=i+1;k } } next_step_random(); } } 主要通过以下步骤实现该算法: 1)依据配置文件,对网格与蚂蚁列表进行初始化。 2)设iteration为迭代次数,计算蚂蚁迭代次数,依据现阶段环境与蚂蚁是否负载信息判定蚂蚁抓取或丢弃增量文本。 3)通过Computer函数对文本相似度进行计算,将蚂蚁所在位置是否存在增量文本向量采用xy_tv描述,蚂蚁是否负载由ant_tv描述。若蚂蚁所处位置存在增量文本向量且负载为空,则对抓取概率与群体相似度进行计算,若计算得到的抓取概率高于随机值,则抓取增量文本。 4)计算S[e]的熵重叠值并存储,同时选出最小熵重叠值的语义序列集,将该序列集与S[e]进行交换,之后再次计算熵重叠值并存储。 5)将蚂蚁ant随机爬行至下一网格的函数通过next_step_random描述。分析该算法的复杂度,若现阶段蚂蚁总量为m,共进行n次迭代,则可计算得出时间复杂度O(m·n)。 通过VC6.0构建仿真环境进行实验,在实验环境中构建增量文本集,并选取基于改进NSGA-Ⅲ的文本空间树聚类算法(算法1)和基于语义簇的中文文本聚类算法(算法2)进行对比实验。 对比三种算法,分析不同文本向量空间维数下,语义序列的相似度计算能力,分析结果如图2所示。 图2 语义序列相似度分析 根据图2可知,随着特征向量维度的不断增加,三种算法计算得到的语义序列相似度值也有所上升,其中,算法1的相似度值始终最低,算法2计算得到的相似度虽然有所上升,但依然低于本文算法,本文算法在特征向量维度为100时,相似度值达到了0.88,由此可知采用本文算法计算语义序列相似度值较高,相似度计算能力强。 从该增量文本库中选取三类文本集,分析不同文本数量下,不同文本集的聚类召回率,分析结果如图3所示。 图3 聚类效果分析 由图3可知,三类文本集在文本数量逐渐上升的情况下召回率均有所降低,其中,由于医学类词汇较为复杂,因此医学类文本集的召回率在三种文本集中保持最低,而计算机类文本集召回率最高,在三种文本集的聚类过程中,召回率均保持在80%以上,说明本文算法聚类时具有较高的召回率。 分析本文算法在不同计算节点数下,计算2GB、8GB、以及16GB文本量情况下的计算加速倍数,分析结果如图4所示。 图4 不同文本量大小时聚类加速比分析 由图4可知,当计算节点数不断增长,加速比也随之增加,其中16GB文本量的聚类加速倍数最高,而2GB文本量的加速倍数相对较低,说明数据量越大,在进行聚类时的加速倍数就越高,同时,三种大小的文本量最终加速倍数均保持在5以上,因此,本文算法聚类时的加速效果较好。 蚁群算法中蚂蚁观察半径是影响聚类效果的关键因素,选取不同蚂蚁个数,分析在不同蚂蚁观察半径下,蚂蚁观察到的文本数量,分析结果如5所示。 图5 观察得到文本数量分析 根据图5可知,由于蚂蚁个数的不断增多,不同观察半径下观察到的文本数量也随之增加,其中,观察半径为2时观察到的文本数量较低,而观察半径为6时,观察得到的文本数量最高在9000个以上,说明观察半径越大,观察到的文本数量就越多,同时,采用本文算法观察到的文本数量均在2000个以上,说明本文算法具有较高的文本观察能力。 对比三种算法聚类时的算法性能,分析结果如表1所示。 表1 聚类效果分析 根据表1可知,三种聚类算法中,算法2的聚类时间较长,且对异常文本并不敏感,同时聚类时内存占比较大,算法1的聚类时间消耗过长,通过对比可知,采用本文算法能够更好地实现聚类。 本文研究基于群体智能的增量文本软聚类算法,通过语义序列特征分析得到增量文本特征,依据该特征,选取基于群体智能的蚁群算法,设计增量文本软聚类算法,并通过Python语言构建SCAST程序,实现聚类算法的计算过程。同时采用仿真形式进行实验,得出本文算法具备较低的聚类执行时间,能够改善聚类效果。在未来研究阶段,可依据现有聚类分析继续优化,实现多种形式文本的聚类。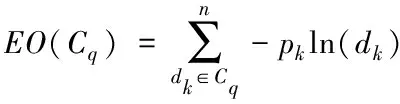
2.2 基于群体智能的增量文本软聚类
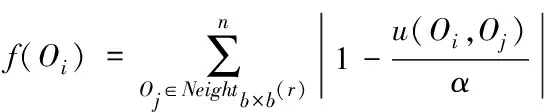
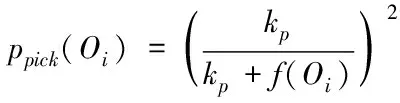
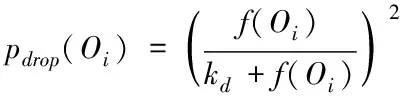
3 实验分析


4 结论
