云端大数据流序列异常挖掘数学建模仿真
2022-09-28徐成桂徐广顺
徐成桂,徐广顺
(成都理工大学工程技术学院,四川 乐山 614000)
1 引言
近年来,计算机技术飞速发展,计算机网络[1]规模愈加庞大,随着网络使用范围的增加,计算机网络安全问题逐渐成为各个国家的重点关注对象。数据流异常数据挖掘因其高强度网络防御特性,受到广泛应用。云端数据流作为计算机网络的重要组成部分,对其有效的异常数据检测[2]是计算机领域亟待解决的问题之一。
早于20世纪90年代,哥伦比亚大学就有学者就数据流异常数据挖掘的检测给出了具体方法,从而为云端数据流的异常序列挖掘奠定了坚实的基础。在此背景下,当前也出现了较多的研究成果。文献[3]提出基于BiGRU-SVDD的ADS-B异常数据检测模型。该方法基于神经网络方法计算数据差值;再将获取的计算结果放入支持向量机中进行训练,完成数据分类;最后依据分类结果确定数据滑动窗口,缩减神经网络训练时间,从而建立数据的异常检测模型,实现数据异常检测。该方法由于未能在模型建立前,提取数据融合特征,所以该方法建立的模型数据挖掘时间长。文献[4]提出基于三次指数平滑模型与DBSCAN聚类的电量数据异常检测。该方法首先依据历史数据预测当前时刻数据量,计算与实际值的残差;使用DBSCAN聚类算法对数据残差进行聚类处理,最后依据三次指数平滑模型建立数据的异常检测模型,实现异常数据的检测。该方法在对数据聚类处理时存在问题,导致该方法建立模型的挖掘效果差。文献[5]提出基于逆向习得推理的网络异常行为检测模型。该方法依据提取的数据特征项对数据进行离散化处理,并对离散结果进行归一化处理;再利用改进的ALI算法对数据进行训练处理,生成数据检测集;最后使用异常数据检测函数判断数据距离是否异常,将深层结构能量模型与高斯编码混合模型进行结合,完成异常数据检测模型的建立,从而实现异常数据的检测。该方法在判断数据距离时,存在较大误差,所以该方法建立的模型数据的挖掘性能差。
为了解决上述传统方法的应用弊端,本研究提出云端大数据流序列异常挖掘数学建模方法。实验结果证明了所构建的模型应用效率果高,相关系数和召回率指标也均高于文献方法,说明所提方法具有可行性。
2 提取云端大数据流特征
在对云端大数据流的异常序列挖掘前,需要结合神经网络与布谷鸟算法[6]提取云端大数据流的数据特征。数据流在进行特征提取时需要检测数据流信息,获取数据流多项信息特征并进行特征重构,利用布谷鸟搜索算法对重构特征寻优处理,从而提取云端数据流的特征。
2.1 建立数据流神经网络模型
设定云端数据流的神经网络模型[7]共分为三层架构,分别为输入层a、输出层c以及隐含层b,由若干节点q组合而成。将神经网络输入层节点数量设定成x,隐含层节点数量标记z形式,输出层节点数量标记y,网路训练权值为ω,建立云端数据流神经网络模型,具体模型结构如图1所示。
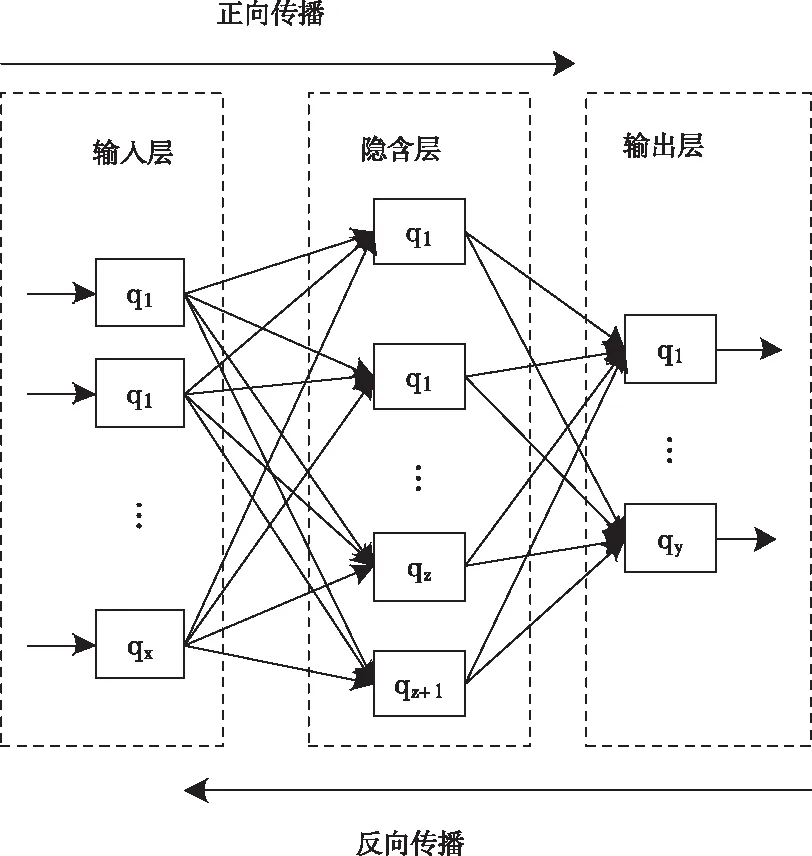
图1 大数据流神经网络具体结构
神经网络模型建立后,基于大数据流参数确定神经网络各个层级权重ω,其中输出层至隐含层单元权重标记ωij形式,隐含层至输出层权重标记ωjk,通过确定的单元权重对大数据流数据进行训练,过程中需要建立相关激活函数,过程如下式所示
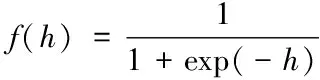
(1)
式中,激活函数标记f(h)形式,指数函数标记exp(-h)形式,数据流训练样本数量标记h。通过对网络阈值的调节,获取数据流[8]信息的均方误差值ς,结果如下式所示
ς=1/2(Jn-Ln)
(2)
式中,云端数据流样本信息的均方误差标记ς形式,样本信息的训练结果标记Jn,误差函数标记Ln,神经网路训练样本数量标记n。
2.2 检测数据流信息
首先依据上述获取的均方误差函数对数据流进行分割处理,将云端数据流D分成若干数据段,并将其作为数据流滑动窗口Dm。依据滑动窗口建立数据流的调度集函数,结果如下式所示

(3)
式中,云端大数据的数据平均熵sn(u),信息样本集中心点标记n形式,数据流信息谱特征量标记kn(u)形式,神经网络迭代次数标记u,大数据流中的数据总量标记E形式。依据上述计算结果获取数据流信息谱α,通过信息融合提取数据的多维时间序列。
2.3 建立大数据流特征提取模型
结合上述建立的神经网络与提取的数据流多维时间序列,建立数据流的空间融合模型[9],结果如下式所示
pm(u)=(aj+δj(u))+(bj+εj(u))
(4)
式中,融合模型参数标记aj和bj,误差扰动标记δj(u),数据均值噪声标记εj(u)。提取数据流融合特征时,设定数据段Yj初始分割点为Yj(1),并以此获取模型参数向量β。通过上述计算,获取数据流的融合特征集R=(supk1(r),…supkf(r)),并使用聚类算法[10]计算数据段聚类迭代方程,结果如下式所示

(5)

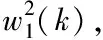

(6)

2.4 搜索最佳特征值
使用布谷鸟算法计算数据流融合特征值,从而搜索数据流的最佳特征。过程如下:
1)初始化数据流
2)更新循环鸟窝位置

(7)
3)替换位置较差的鸟窝
对获取的鸟窝位置进行高斯扰动,获取新的鸟窝位置P″,通过对比测试将鸟群中位置较差的鸟窝进行替换处理。
4)寻找最佳鸟窝位置
替换后,搜索鸟群中最佳的鸟窝位置,获取数据流的最佳融合特征,结束搜索。
最后通过上述搜索流程输出结果,获取云端数据流的最佳融合特征信息。
3 建立云端大数据流异常序列挖掘模型
3.1 确定模型阈值自适应调整策略
云端大数据流由若干n数据序列组合而成,并会随着时间的变化而发生改变,表现形式标记{z1,z1,…,zn},数据流[12]的最大近似序列用zn表述。

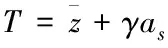
(8)

(9)
式中,数据流序列的阈值调整条件标记G形式,调整因子标记μ形式,当序列阈值比重为0时,t可作为常数处理。
3.2 计算相关系数
设定云端大数据流序列之间的相关系数[13]为F(0),长度用l表示,若序列长度小于l,则默认序列长度为0,说明该序列为滞后序列。一般来说,计算云端大数据流序列相关系数时,可使用皮埃尔系数ρ完成相关系数的计算,结果如下式所示

(10)
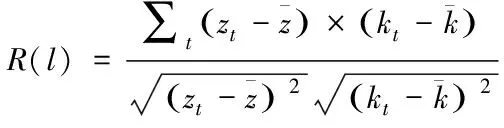
(11)
式中,序列滞后相关系数标记R(l)形式。
3.3 建立相关约束条件
基于上述数据流序列相关系数的计算,引入遗忘机制建立模型相关约束条件。
在建立数据流异常序列挖掘模型时,设定序列的决策变量为A,遗忘因子为Y,序列衰减因子用σi(N)表示,并以此建立数据流异常序列挖掘模型的约束条件,过程如下式所示

(12)
式中,序列的最大相关系数标记Rmax(l),最小相关标记Rmin(l)。
3.4 建立模型
基于上述确定的阈值、序列相关系数以及约束条件,建立云端大数据流序列的异常挖掘模型[15],过程如下式所示

(13)
式中,云端大数据流序列异常挖掘模型标记P(x)形式。
最后将云端大数据流中相关待检测序列放入模型中,通过模型输出,获取数据流异常序列值。
4 实验设计与指标测试结果
为了验证上述云端数据流序列异常挖掘模型建立方法整体有效性,需要对此方法进行测试。
4.1 实验结果及分析
分别采用云端大数据流序列异常挖掘数学建模仿真(本文所提方法)、基于BiGRU-SVDD的ADS-B异常数据检测模型(文献[3]方法)、基于三次指数平滑模型与DBSCAN聚类的电量数据异常检测(文献[4]方法)进行测试;
在建立异常挖掘模型时,数据流序列挖掘时间的长短、相关系数的大小以及检测效果的优劣都会给模型的检测性能带来影响,采用本文所提方法、文献[3]方法以及文献[4]方法建立异常数据挖掘模型时,利用上述测试指标检测三种模型的模型检测性能。
1)模型挖掘时间测试
在建立异常数据挖掘模型时,模型检测时间的长短能够直接反映模型的检测性能,采用本文所提方法、文献[3]方法以及文献[4]方法建立异常数据挖掘模型时,对三种模型的异常数据挖掘时间进行测试,测试结果如图2所示。

图2 不同模型异常数据检测时间测试结果
分析图2可知,检测次数的增加会提高模型对异常数据的检测时间。在测试初期,文献[3]方法测试结果与本文所提方法测试结果相一致,随着检测次数不断增加,二者之间差距拉开,本文所提方法测试结果低于文献[3]方法检测结果。本文所提方法的测试结果同样会随着检测次数的增加而提升,但是当检测次数达到一定范围时,本文所提方法能够将异常数据挖掘时间稳定在固定时间内。由此可知,本文所提方法的异常数据检测时间低于其它两种方法,文献[3]方法测试结果略高于本文所提方法,文献[4]方法测试结果较差。
2)模型相关系数测试
在建立异常数据挖掘模型时,模型相关系数的大小会对模型的挖掘效果带来影响。设定皮埃尔系数ρ为模型相关系数指标,最佳区间为[0,1],模型的相关系数越高,模型的挖掘效果越好,反之则越差。采用本文所提方法、文献[3]方法以及文献[4]方法建立异常数据挖掘模型时,测试三种方法的模型相关系数,测试结果如图3所示。
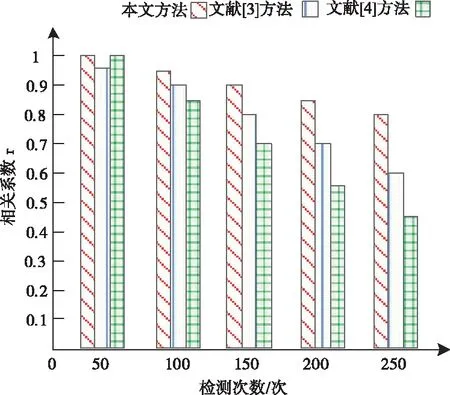
图3 不同模型的相关系数测试结果
分析图3可知,模型相关系数的大小会随着检测次数的增加而有所下降。在测试初期,文献[4]方法检测出的模型相关系数与本文所提方法测试结果相一致,随着测试的进行,文献[4]方法测试结果急速下降,直至低于文献[5]方法测试结果。本文所提方法虽然也会随着检测次数的增加有所降低,但是测试出的模型相关系数依然高于其它模型。这主要是因为本文所提方法在建立异常数据挖掘模型前,提取了数据流融合特征,所以本文所提方法建立的异常序列挖掘模型具备较高的相关系数。由此可证明本文所提方法的挖掘效果好。
3)检测效果测试
基于上述测试结果,选定5000个待挖掘数据,采用本文所提方法、文献[3]方法以及文献[4]方法建立异常数据挖掘模型时,对三种方法的模型挖掘效果进行测试,测试结果如表1所示。

表1 不同方法的模型挖掘效果测试结果
分析表1可知,本文所提方法在挖掘数据流异常序列时,检测出的挖掘效率、召回率高,检测出的数据误报个数低。
综上所述,本文所提建立的数据挖掘模型在进行异常数据挖掘时的挖掘时间短、挖掘效果好、挖掘性能高。
5 结束语
随着网络应用范围的增加,云端数据流的异常序列检测就变得尤为重要。针对传统数据流异常数据挖掘方法中存在的问题,提出云端大数据流序列异常挖掘数学建模方法。该方法依据提取的云端数据流融合特征,获取模型的自适应阈值;再通过相关系数以及约束条件的建立,完成异常挖掘模型的建立,实现数据流序列的异常挖掘。
