基于改进音形码与HowNet的中文词相似度检测算法
2022-09-28王华敏黄梦醒冯文龙冯思玲
王华敏,黄梦醒,冯文龙,冯思玲
(海南大学,海南 海口 570228)
1 引言
目前存在许多基于字符相似度匹配的算法,比如edit distance,affine gap distance,Simth-Waterman distance,Jaro distance metric和Q-gram distance[1]或者在此基础上改进的算法,在处理拉丁文字的字符串匹配时,都能起到良好的效果。它们最先的设计目地也是为了处理拉丁文字遇到的字符匹配问题,因此在面对汉字的时候,效果往往差强人意。
针对汉字相似度匹配问题,在主流算法的启发下,许多研究者意识到可以将汉字先进行统一编码,编码时体现汉字特征的差异性,然后再将传统的拉丁字符匹配算法应用于汉字编码,可以大大提高准确率。
字形上,王东[2]等人把汉字表示为汉字结构、字首部件、和字尾部件三元组。祁俊辉[3]等人提出了基于特征向量和笔顺编码的字形相似算法,充分利用汉字结构、轮廓、笔画、书写顺序等特征来识别汉字。缺点在于组建汉字特征向量库后期还需要投入大量的工作,不过组建笔顺编码数据库值得借鉴。
发音上,已经有处理拉丁文字的Soundex算法,但是汉字种类繁多,且受方言影响,此算法无法满足要求。
音形结合上,俞荣华[4]等人在处理多语言文本的相似重复记录时,利用汉字的拼音序、笔划序、部首序对汉字进行排序处理,缺点是这种方法对汉字的特征差异描述还较为粗略。陈鸣[5]等人归纳出音形码,但拼音码没有体现出拼音发音的渐进变化,因此存在一个字对与之相近的发音字,与不相近发音字求出来的距离是一样的,而字形部分采用四角编码,只能粗略描述汉字的字形。周昊[6]等人在陈鸣的基础上改进了音形码的编码方式,将音形码按照发音以及字形的渐进变化编码,最后检测的结果更符合实际。但是其字形描述仍然采用四角编码,仍然无法将字形细致的描述,从而体现差异性。
基于语义的方法主要是利用释义词典或者一些大规模的本体[7]对词汇进行语义上的相似度计算[8],可以将完全不一样的文字,但表述相同语义的词语相似度正确计算出来。其缺点是被检测词语必须完全准确,不能存在错别字。
本文针对中文检测算法音码对汉字拼音描述不全,对汉字字形描述不够精确,仅仅做意思检测又太片面等缺点做出补充与改进,提出结合改进音形码与Hownet的算法。该算法基于中文的音形义特征,较为全面的检测相似度,大大提高了准确度。
具体工作:①改进音码,重新考虑了拼音可能存在声母缺失的情况。②改进形码,将四角号码改为笔顺编码,更加详细描述汉字的结构。③改进中文字符串相似度距离计算方法,在加权编辑距离的基础上,考虑汉字可能存在字序改变而意思不变的情况。④设计了结合音形义的中文字符串相似度检测算法。
2 相关工作
2.1 音码
汉字拼音由声母、韵母和声调组成,其次,有些拼音中间还有一个韵母,如,“chuang”中的‘u’,因此还将考虑添加一位韵母补码,最终生成的音码应该包含声母码、韵母码、音调码、韵母补码四个部分。
设计音码时,想要充分体现拼音发音的差异性,需要了解哪些拼音特性会影响到需要表达的汉字,然后针对性的进行设计。我国省市众多,不同的地方有着不一样的方言,尤其南方的语言变化更多,南方人的发音更容易带有方言特色,较为容易混淆。如,‘l’和‘n’,常常会有人将‘刘’和‘牛’混淆,因此算法设计上可认为是发音相似;又如,‘ang’和‘an’,容易将‘床’和‘传’混淆等。根据这些特性,得出容易混淆的发音具有更高的相似度。陈鸣[5]等人在设计音码时,根据这个特征将拼音的四个部分对应转为数字或者字母,其中容易混淆的声母或者韵母转化为同一个数字或者字母。
而周昊[6]等人在陈鸣的基础上改进音码的编码方式,采用格雷码表示声母和韵母,然后计算其汉明距离体现相似度,其结果能充分体现出拼音发音习惯的差异。
要用格雷码完全表示声母和韵母,一共需要5+5+5个二进制位,即声母码、韵母码、韵母补码。而音调只有四声,因此,一声 (00),二声 (01),三声(10),四声 (11)。最后一共可以用17个二进制位表示音码。
2.2 形码
用来表达一个汉字的字形特征需要知道汉字的结构,笔画以及按字形的编码,因此字形部分需要包括这三个部分[6]。由此,陈鸣等人对应设计了结构码,笔画码以及应用四角号码对汉字字形进行编码。其中四角号码根据汉字四个角按顺序对汉字编码,分别是左上角、右上角 、左下角 、右下角,具体的取角规则可参考徐祖友[9]。
考虑到结构与结构之间,有些存在相似性,可以在计算时加入考虑,周昊[6]等人根据这个特点改进了形码,设计了针对结构渐进变化的编码方式,使得相似结构间汉明距离相近。
2.3 HowNet
汉语博大精深,一个中文词语通常可能有多重意思,而一个意思通常也可以用不同的词语去描述,而由此产生的相似度问题是基于音形设计的算法无法解决的。因此,一些研究人员花费数十年的时间从各种词典和语言知识库筛选词义,并用这些词义对词语进行注释,以构建基于词义的语言知识,HowNet[10]就是此类最著名的知识库之一[11]。而自从HowNet发布以来,引起了广泛的关注,吸引了各种相关研究,如葛斌[12]等人,刘群[13]等人对基于知网的词汇语义相似度计算方法进行研究。其中刘群等人的词语相似度检测算法,是最具影响力的研究之一。
HowNet考虑到每个词语的多义性,为其注释了不同的含义,每个含义用中英文表达。如,对于“苹果”这个词的注释,它包括“电脑”、“电话”、“水果”、“树”这四种含义,每个含义下面又有相应的解释。
HowNet从提出至今不断完善,最新版本取名OpenHowNet,包含了HowNet的核心数据,并提供免费下载,此外还提供了OpenHowNet API,包含了词语的相似度计算接口,其算法基于[14]提出。本文词语语义相似度计算使用的便是OpenHowNet API。
3 音形码的改进
3.1 汉字音码的改进
在音形码的基础上,通过实验研究,发现有些拼音是没有声母的,如‘额’的拼音“e”,而它与“de”,“le”都有较高的相似度,所以缺少时,可以用一个相对与“00000”、“11111”有差不多汉明距离的编码。同理,声母和韵母中间不存在补码的,也取与两端差不多距离的编码。改进后的拼音编码见表1、表2。

表1 拼音声母编码

表2 拼音韵母编码
声母码、韵母码、韵母补码一共占有15个二进制位,音调只有四声,一声 (00),二声 (01),三声(10),四声 (11)。最后一共可以用5+5+5+2个二进制位表示音码。
因此,基于音码的汉字相似度计算公式为

(1)
其中,h(a,b)为汉字a,b的音码汉明距离,len(a)为a的音码长度,即17。
改进后的音码可以补充拼音缺少韵母和声母的情况,提高音码相似度检测的准确率。
3.2 汉字形码的改进
陈鸣[5]等人的形码是基于结构码,笔画码以及应用了四角号码表示。考虑到四角号码是根据字的左上角、右上角 、左下角 、右下角取码,存在无法细致描述字形的情况,因此本文采用笔顺编码代替。
根据汉字编码规则,任何汉字的结构都可以分成横、竖、撇、捺、折,即五笔结构。按照这个思路,可以将每个汉字的书写笔画对应相应的五笔编码,然后根据笔画出现的顺序,依次记下编码,即得到笔顺编码,其中笔画数即笔顺编码的字符长度。而笔顺编码是比较成熟的汉字表示方式,比较容易得到。按照编码规则对任意汉字生成的编码字符串,简称汉字笔顺编码。汉字笔画编码规则见表3。
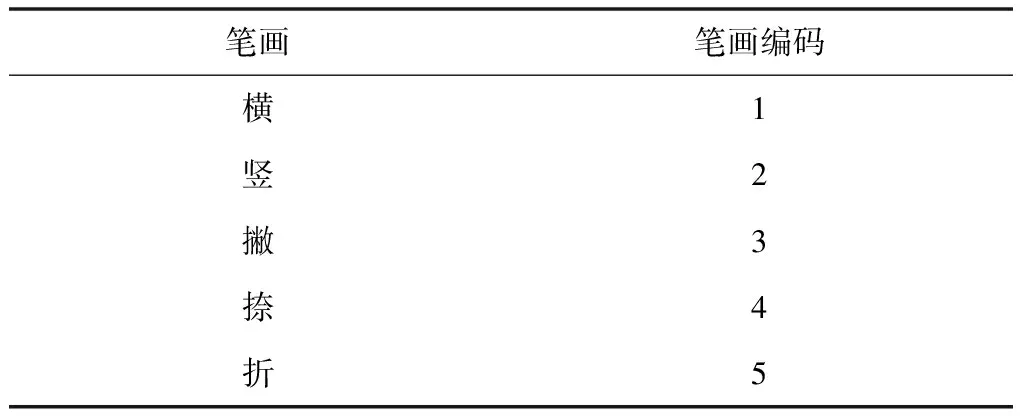
表3 汉字笔画编码规则
如,‘优’由撇、竖、横、撇、竖弯钩、点组成,根据对照表,对照生成笔顺编码“321354”。
笔顺编码反映了汉字的组成,相同的的编码说明有相同的笔画顺序组成,在一定程度上可以反映汉字的相似程度,再加上汉字的结构,这样从组成因素和组成方式大致描述了汉字字形,由这两部分编码计算出来的相似度,可以描述出汉字的直观形状。
最终本文采用陈鸣的结构码,笔画码,而用笔顺编码代替四角号码。改进后的形码可以比较细致的区分字形差异。
4 中文字符串相似度检测算法
4.1 改进形码的汉字相似度检测算法
生成包含结构码、笔画码、笔顺编码后的形码后,汉字字形相似度便可以基于此形码考虑。
汉字的直观形状受到结构的影响,本文结构码采用周昊[6]等人在陈鸣基础上提出的结构码,其优势在于体现汉字结构的渐进变化。
笔画在一定程度可以反馈汉字的复杂程度,笔画越多通常字形越复杂,笔画数差异越大则可以体现字形相似度越小。
不同汉字的笔顺编码并不是等长的,所以其相似度可以根据编码的最长公共子串来度量,最长公共子串便是两个相似的字形笔画组成部分,相似笔画越多,即最长公共子串占比越多,字形越相似。相似笔画所在的位置也是影响字形相似度的一大因素。如,‘时’的笔顺编码为“2511124”,而‘如’的笔顺编码为“531251”,可知两个字的笔顺编码最长公共子串为“251”,根据人们看汉字字形相似的习惯,字形的相似很大程度受到相似结构位置的影响,由编码“251”可知,他们相似的结构分别为少最后一笔的‘日’以及‘口’。按照习惯,完全不会将这两个字联系在一起。因此需要考虑最长公共子串在笔顺编码里的位置差,差值越小,相似度越高。
综合考虑汉字笔顺编码最长公共子串占比、汉字笔顺编码最长公共子串位置差、汉字笔画、汉字结构码四个因素,设计基于改进形码的汉字相似度检测算法。
算法1:改进的的单个汉字字形相似度计算
输入:汉字a、b
输出:汉字a、b的字形相似度Simxing(a,b)。
Step1:生成a、b对应的笔顺编码,字形结构码,笔画数。
Step2:考虑笔顺编码公共子串。由于公式计算需要,要先判断a、b汉字哪个笔顺编码较短和较长,d=Min(len a,len b),s=Max(len a,len b),计算最长公共子串长度为Lcs_len,则公共子串占比
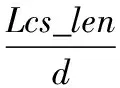
(2)
Step3:考虑汉字笔画。计算汉字笔画差c=|len a-len b|,计算笔画差对相似度的贡献比
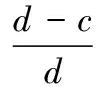
(3)
Step4:考虑笔顺编码最长公共子串的位置差。先得出最长公共子串在各自的位置。得到a的笔顺编码最长公共子串位置为a_p,b的为b_p,其中a_p和b_p分别为子串第一位在笔顺编码中的位置,计算差值p=|a_p-b_p|,最后得到位置对相似度的贡献比

(4)
Step5:考虑汉字结构。计算结构码的汉明距离ham,然后根据汉明距离计算结构因素
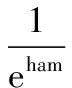
(5)
Step6:考虑到相似度不超过1,且分别需要考虑笔顺编码最长公共子串、汉字笔画数、笔顺编码最长公共子串所处的位置差异、汉字结构差异。设置贡献参数:α,β,i,j。本文分别设置为0.6,0.2,0.1,0.1,得到相似度计算公式
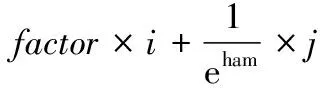
(6)
4.2 汉字音码或形码单个特征的中文字符串相似度检测算法
文献[15]提出将中文相似度计算分为一阶相似度计算和二阶相似度计算,即汉字相似度计算和中文字符串相似度计算。其中二阶相似度计算采用加权编辑距离,这种计算方式替换、删除的操作代价不单纯用0,1表示,而是利用单个汉字对比后的相似度表示。由于中文词语存在改变字的顺序而意思不变的情况,如,“互相-相互”,“察觉-觉察”等,按照此方法,没法识别这些词其实是同一个词,所以不能单纯按照字序分别比对词语中汉字的相似度。
基于加权编辑距离,将词语中的每个汉字转换编码后,分别比对,找出相互能够匹配的最高精度词语,然后计算其位置代价。如果词语中的每个汉字都能找到自己精确匹配的汉字,则不计算位置代价。如,“不好-好坏”,显然两个字符串都有共同的汉字‘好’,首先将各自最高精度的字符相互匹配,则得到“不好-坏好”,然后再用加权编辑进行计算相似度,最后考虑位置替换代价。但是如果单纯按照顺序比对,则无法将这两个字符串联系在一起。而“互相-相互”,则各自能完全匹配,这时则不计位置代价,可以得到其相似度为1。
算法2:改进的基于汉字音或形单个特征的中文字符串加权编辑距离相似度算法
输入:中文字符串s1、s2。
输出:s1、s2的音或形相似度Sim(s1,s2)。
Step1:min_s=Min(s1,s2),max_s=Max(s1,s2),将min_s和max_s中的所有汉字转为音码或者形码。
Step2:将min_s中的所有汉字与max_s中的所有汉字遍历进行相似度计算,min_s中每个字对应max_s中的相似度最近的一个字,将max_s重新排序。如:“教师-你教的师”,则变成“教师-教师你的”;“相互-互相”,计算后得到“相互-相互”。
Step3:然后比较min_s与max_s的长度,如果等长且完全匹配,即每个汉字匹配组相似度都为1,则执行Step 4,不考虑位置因素,否则Step 5,把位置因素考虑进去。
Step 4:

(7)
返回相似度,算法结束。其中sum_sim为对应位置每组汉字的相似度和。
Step5:考虑位置因素。由于匹配时,max_s的字符位置发生交换,则计算出交换前后的位置差,然后计算绝对值,设各个差值绝对值和为sum_position,则位置影响因素。

(8)
Step6:将发生位置交换的max_s与min_s用加权编辑距离算法求编辑距离,即lds(max_s,min_s)。
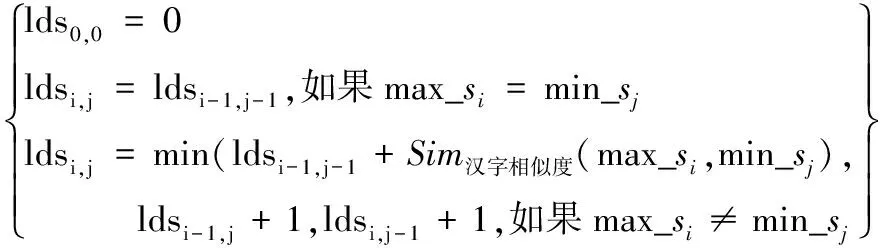
(9)
Step7:得到字符串相似度
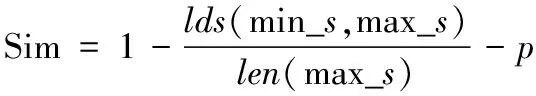
(10)
4.3 结合改进音形码与Hownet的中文字符串相似度检测算法
音、形、义是汉字的三大特征[15],也是汉字相似度考虑的主要因素。主流中文词语相似度检测大多分别从音形或者词义研究汉语相似度,对于结合二者的研究相对较少,而二者皆有各自优缺点。如,“西红柿”与“番茄”,光考虑音形,无法确定其相似度;而“彬彬”与“杉杉”光从词义也无法确定其相似度。针对此问题,提出结合改进音形码与HowNet的算法,从音形义三个方面综合考虑中文字符串的相似度。
在此算法设计中,需要考虑以下几种情况:①相同的意思,完全不同的词表达。设置阈值为t,如果单个特征相似度大于t,可以认为单个特征高度相似,则不考虑其他两个特征。②当词语存在错别字时,词语本身是无意义的,要判定它的相似度,必须要将其转换成与其最为相似而有意义的词语,再进行相似度比较。③当三个特征相似度都较低时,可以针对应用场景,分别设置各个特征的贡献参数。
由此,设计算法3。其中,算法3出现的基于音码的中文字符串相似度检测(Simyin)和基于形码的中文字符串相似度检测(Simyi)算法皆是算法2。
算法3:基于音形义的中文字符串相似度检测算法
输入:中文字符串s1、s2。
输出:s1、s2的相似度Simzong(s1,s2)。
Step 1:先将s1,s2进行意思检测,看看是否都有意义,如果有,先进行赋值操作,s1_change=s1,s2_change=s2,num=0,然后执行Step 3;如没有意义,则直接执行Step 2。
Step2:将无意义的字符串进行单个相似汉字替换,数据库为汉字同音词或者形近词库,替换后的词语再进行意思检测,循环到找到最接近相似度词语为止,然后设置替换惩罚参数f,被替换字数为num。根据实验经验,这里的f设置为0.1。替换后的字符串分别对应为s1_change、s2_change。
Step3:分别计算s1_change、s2_change的意思相似度
simyi(s1,s2)=simyi(s1_change,s2_change)-f×num
(11)
Srep4:计算s1、s2的音形相似度,根据贡献值a、b、c求最后相似度,其中a+b+c=1。如果单个特征相似度大于t,则以此特征为准,而不考虑另外两个特征的相似度。
Simzong=simyin×a+simxing×b+simyi×c
(12)
5 实验结果与数据分析
5.1 实验方案
以陈鸣[5]提出的音形码作为基础,用编辑距离计算字符串音形码相似度作为方法1,以HowNet义原检测作为方法2,以本文提出的基于音形义检测算法作为方法3。各方法比较如图1。
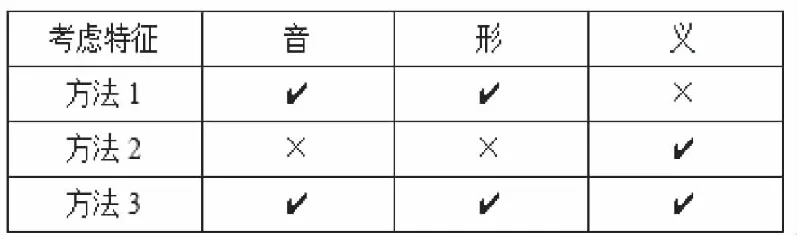
图1 各方法基于特征比较
实验方案:
方案1:选取12组典型中文字符串进行实验,比对音形义相似的情况。最后对结果进行分析比较,如图2。
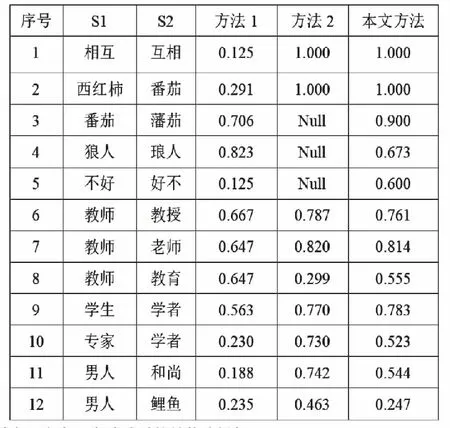
图2 典型中文字符串相似度计算结果比较(方案1)
方案2:分别用以上三个方法检测近义词大全[16],一共730组近义词。阈值都设为0.6,分别比较筛选出近义词的准确率,比较结果如图3。

图3 近义词识别率比较(方案2)
方案3(本文方法):分别用以上三个方法检测高中语文错别字[17],截取前85组近形(音)词。阈值分别设为0.6、0.7、0.8、0.9,比较三种算法筛选出近义词的准确率,比较结果如图4。
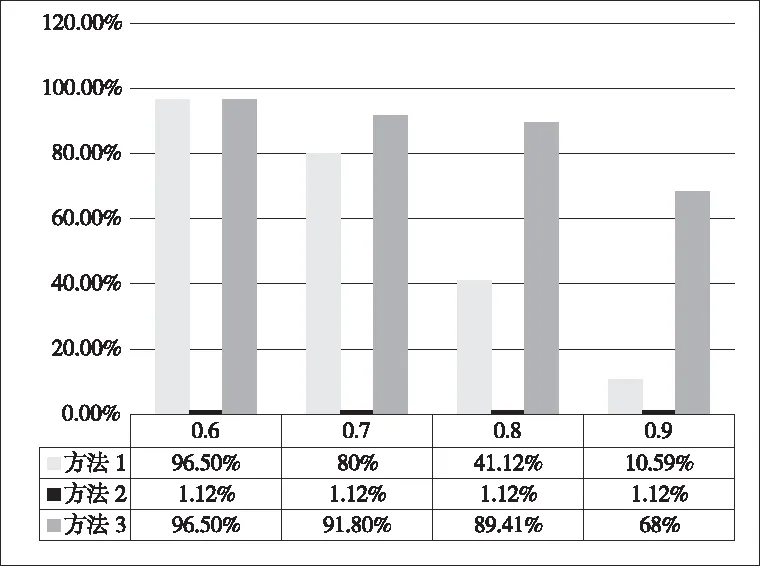
图4 形(音)近词识别率比较(方案3)
方案4:任意找一段文本(共1000字左右)[18],随机位置插入10个词语,分别为:相互、西红柿、藩茄、教师、衰豪、仓黄、徘回、悲创、宛转、凛列,找出人工判别对应相似的词语,分别为:互相、番茄、老师、哀嚎、苍黄、徘徊、悲怆、婉转、凛冽。用以上三个方法分别对文章进行文本检测,阈值分别设置为0.6,0.7,0.8,分析词语分类结果,如图5。

图5 词语检测召回率比较(方案4)
5.2 评判标准
由于中文词语相似度评价没有通用标准,受主观因素影响,所以主要按照人工判别的方式去比较各种方法的优劣。大致评价标准:相似度小于0.5时,为不相似;相似度为0.5-0.6,则说明有关联性;相似度0.6-0.8为比较相似;相似度0.8-0.9为相似;相似度0.9-1.0为非常相似。
5.3 结果分析
经过多次实验,4种方案实验结果以及结果分析如下。
对图2(方案1)分析如下:
1)对于“相互-互相”这类词语,字序改变,词义不变。方法1所得相似度没有参考价值,而方法2和方法3的算法基于语义,可以有效识别。
2)对于“西红柿-番茄”这类词语,描述方法不一样,而意思一样的词语,方法1也没有参考价值,而方法2、方法3则表现良好。
3)对于“番茄-藩茄”这类词语,假设其中有错别字,而HowNet语料库中是不可能存在这种错别字词语的,因此返回Null,没有参考价值。而基于音形码的方法1和基于音形义的方法3则具有一定参考价值,其中,方法3可以识别“藩茄”可能描述的词语为“番茄”,所以可以得出较高的相似度。
4)对于“男人-和尚”,“男人-鲤鱼”,显然,“男人”和“和尚”有较高的关联,而方法1并不能体现,而方法2则把前者的相似度计算的过于高了,方法3则体现其具有关联性,比较符合实际。
对图3(方案2)分析如下:
本次实验用三种方法从730组近义词中进行相似度计算,从而分析识别率。其中方法1识别组数为236组,识别率为32.3%,方法2识别组数为509组,识别率为69.7%,方法3,也就是本文提出的算法,识别组数为529组,识别率为72.5%。可以看出本文方法相对其他方法提高了识别率。
对图4(方案3)分析如下:
由于错别字组成的词语,HowNet词库并未收录,因此方法2基本失效,而当相似度阈值设置为0.6时,方法1与方法3效果相同,但是随着阈值的不断增加,方法1显然效果大大减小,其相似度分散在0.6-08之间,应用方法2在多组词组中找相似词组时,容易受其他词组的影响,而方法3,即本文方法,则可以在比较高的相似度下将形(音)近字筛选出来,在干扰下筛选词语的效果显然会强于方法1。
对图5(方案4)分析如下:
检测隐藏在文本中的词语,当阈值为0.6时,方法1召回率为70%。方法2召回率为30%。本文方法召回率为100%;当阈值为0.7时,方法1召回率为50%。方法2召回率为30%。本文方法召回率为90%;当阈值为0.8时,方法1召回率为30%。方法2召回率为30%。本文方法召回率为70%。实验表明,在文本中检测相似词,本文方法效果明显最好。
以上结果表明,无论是从音形还是词义检测中文词相似度,本文提出的算法都有更好的表现。
6 结论
1)通过完善拼音编码,算法提高了中文近音词检测精度。
2)通过优化字形编码方式,算法在近形词检测中表现更好。
3)在近义词检测方面,算法可以允许被检测词出现错别字的情况,识别率提高2.8%。
4)算法可满足多种应用场景,如,结构化数据项重复性检测,特别是存在手工输入错误的情况;另外,也可应用于存在利用别字隐藏敏感词的文本检测等。
