网络可用带宽大数据流量调度模型仿真
2022-09-28敖永霞
张 慾,敖永霞
(福建农林大学计算机与信息学院,福建 福州 350002)
1 引言
现今社交网络以及移动互联网等相关业务的快速发展,数据中心作为所有业务发展的基础,已经发生了重大变化。数据中心规模的不断增加,网络业务开始向着多样化以及复杂化发展,促使网络流量增长速度增加。因此,数据中心网络的流量调度已经成为当前研究的热点话题[1,2]。
国内相关专家针对宽带流量调度的问题得出了一些较好的研究成果,王耀民等人[3]将FTO算法嵌入到分析预测以及在线调度中,最终获取网络流量调度的最优解和多个具有价值的次优解。臧韦菲等人[4]优先在算法中引入松弛时间的相关概念,根据松弛时间计算传输时延宽容度以及时间流完成时间,同时借助最小累积发送量优先策略对网络流量进行调度。由于以上两种模型未能对可用带宽流量进行特征提取,导致吞吐量、能量节省率等指标下降,计算时延增加。
为改善以上文献方法存在的应用弊端,构建一种大数据网络可用带宽流量调度模型,经实验测试证明:所提模型能够全面提升宽带流量调度的吞吐量、能量节省率以及内存利用率,同时模型的时延问题也得到了有效降低。
2 大数据网络可用带宽流量调度模型
2.1 可用带宽流量特征提取
为实现大数据网络环境下可用带宽流量的特征提取,首先需要构建时间序列,分析不同流量序列之间的结构关系。设定可用带宽流量的时间序列本体O为式(1)的形式
O={C,I,P,Hc,R,A0}
(1)
式中,C、I、P、Hc、R以及A0分别代表不同的子时间序列。
在可用带宽流量数据传输结构模型的基础上,需要对可用带宽流量特征进行自适应提取[5,6]。

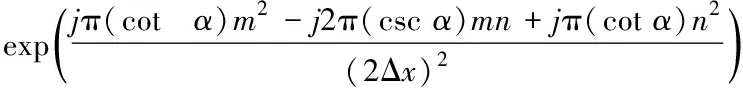
(2)
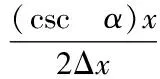
将各个流量时间序列按照Taylor级数进行展开,获取概率密度函数f(x),同时设定可用带宽流量时间序列的第一特征函数为Φ(ω),将其表示为式(3)的形式
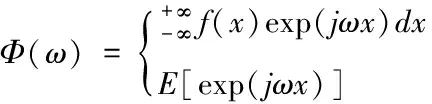
(3)
式中,ω代表权重取值;E代表累积量。
将随机变量的高阶矩ck和高阶累积量ψ(ω)k两者进行自适应分解,进而得到两者之间的关系,如式(4)所示

(4)
式中,ψk代表分数阶等级;ωk代表第k阶导数的权重取值;ψ(ω)代表片段集合总数。
通过流量时间序列特征函数对已有的流量时间序列进行变换,获取网络坐标原点的k阶累积量最大值,则对应的第一特征函数mk可以表示为以下的形式
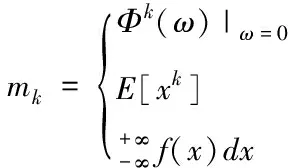
(5)
对于零均值的随机变量而言,可用带宽流量时间序列的k阶中心距和k阶原点距两者是等价的。当可用带宽流量时间序列属于准平稳随机序列时,则说明累积量中只包含k-1个独立单元,同时满足设定的约束条件,对应的四阶累积量c4x(τ1,τ2,τ3)可以通过以下形式完成估算
c4x(τ1,τ2,τ3)
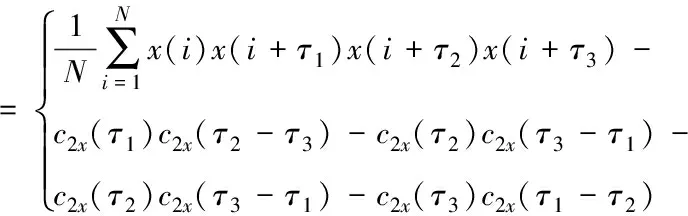
(6)
式中,x(i)代表二阶累积量。
其中,可用带宽流量的四阶累积量自适应提取的特征g(n)可以表示为以下的形式
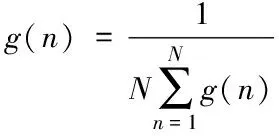
(7)
在上述分析的基础上,需要对可用带宽流量完成拟合,有效提取四阶累积量特征,将提取到的特征设定为后置聚焦算子,为后续流量特征提取奠定基础[7,8]。
利用四阶累积量后置聚焦可以对可用带宽流量中的噪声进行有效滤除。假设大数据网络可用带宽流量时间序列中的噪声项为w(n),对应的表达式为
w(n)=c4(n,τ)
(8)
假设w(n)为非高斯色噪声,需要提取大数据网络中可用带宽流量的约束指向特征,同时采用多普勒实现信号调制,最终获取四阶混合累积量切片算子cw(τ),对应的计算式如下

(9)
式中,γ代表噪声产生过程中的峰度;h(j)和h(j+τ)分别代表不同的数据振荡频率。
对可用带宽流量时间序列进行核变换Kp(t,u),具体的表达形式如下
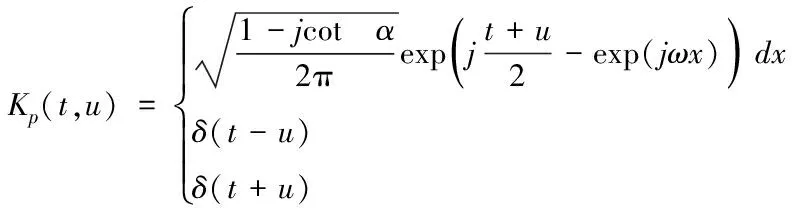
(10)
式中,δ代表线性积分;t代表变换用时;u代表算子。
通过四阶累积量对可用带宽流量特征进行自适应提取,具体计算式如下
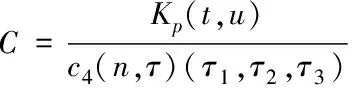
(11)
2.2 大数据网络可用带宽流量调度模型的构建与求解
流量分布不均匀是造成网络负载不均衡的主要原因,因此对于可用带宽中的小流主要通过静态路由算法ECMP进行调度[9,10],详细的操作步骤如下所示:
1)当交换机收到主机发送的数据流时,需要通过目的地址判断是否需要进行直连,假设需要,则直接向下转发;反之,则需要对流量进行判别。
2)当交换机中判别流属于小流时,则需要借助ECMP进行调度;反之,则需要向控制器发送对应的消息。
3)控制器根据在交换机获取的拓扑、负载以及时延等相关信息,采用ECMP对大流转发路径进行计算,同时将流表信息进行下发,交换机主要通过下发的流表对大流依次进行转发。
当进行大流转发路径计算时,需要通过交换机获取对应的网路信息,其中需要将控制器作为判定依据。在大数据网络中,可用带宽流量中变量φ的计算式为
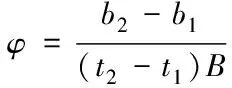
(12)
式中,b2和b1代表大数据网络中的交换机总数;B代表可用带宽流量的速率。
根据实时监测网络中各个端口和对应链路的流量信息,设定共有P条路径中包含n条链路,则路径P的实时负载Load可以表示为以下的形式
Load=max{load1,load2,load3,…,loadi,…,loadn}
(13)
各条链路上传输时延Num的获取主要是通过LLDP数据包和Echo数据包的时延经过计算得到,具体的计算式为
Num=max{num1,num2,…,muni,…,numn}
(14)
控制器主要获取的信息为依据,将最小计算时延和最大内存利用率设定为目标函数,建立大数据网络可用带宽流量调度模型Delay,如式(15)所示

(15)
为了获取最优调度路径,需要求解构建的调度模型,以下主要采用蚁群优化算法。蚁群算法[11,12]主要具有分布式计算以及稳健性等相关特点,被广泛应用于不同的研究领域中,利用图1给出蚁群算法的具体操作流程图。

图1 蚁群算法操作流程图
在蚁群优化算法中[13,14],蚂蚁会在走过的路径下留下一定量的信息素。距离食物越近,释放的信息素就越多,但是信息素会随着时间的流逝而逐渐挥发。在蚁群中的其它蚂蚁也可以感知到信息素,其中,蚂蚁选取路径的策略如式(16)所示

(16)
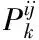
以下详细给出蚁群算法对模型进行求解的过程[15]:
1)通过大流的源交换机地址以及目的交换机地址,采用信息统计模块计算获取k条最短路径,组成最短路径集SP,蚂蚁在SP中获取最优路径,路径的选择依据为轮盘赌法,具体计算式如下

(17)
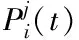
2)将路径上的大流数目和实时负载作为判断大数据网络传输路径负载情况的依据,通过路径上的大流数目对路径负载估算。
3)当m只蚂蚁完成搜索后会在各条路径上释放信息度。通过信息素更新方式得到路径解集合,进而达到提升收敛速度的目的。其中,信息素的更新公式如下
τi(t+n)=(1-ρ)*τi(t)+Δτi(t)
(18)
式中,τi(t+n)代表路径i信息素浓度变化情况;Δτi(t)代表在t时间段内路径i上的信息素增量。
4)重复上述操作过程,在已有的路径集中选择最优调度路径,同时对各个路径上的信息素进行更新。当算法满足设定的迭代次数,直接输出可用带宽流量最优调度路径;反之,则返回至步骤2)。
3 仿真研究
为了验证所提大数据网络可用带宽流量调度模型的有效性,采用20台普通物理PC机构建实验集群。为了确定参数θ(步长)的具体取值范围,实验主要选取吞吐量、计算时延、能量节省率以及内存利用率作为基准测试指标进行实验分析:
1)吞吐量测试结果分析/(103tuple·s-1)
选取文献[3]模型和文献[4]模型作为测试对象,将吞吐量作为测试指标,分析不同步长下各个模型的吞吐量变化情况。
分析图2中的实验数据可知,随着步长的不断增加,各个模型的吞吐量也会相应增加。但是当步长的取值较小时,各个调度模型的吞吐量明显更高一些。和另外两种调度模型相比,所提模型的吞吐量明显更高一些,由于模型建立前期,对大数据网络可用带宽流量进行特征提取,这样可以更好完成流量调度,进而提升吞吐量。

图2 不同模型的吞吐量测试结果对比
2)计算时延测试结果分析/ms
在吞吐量不断增加的过程中,需要尽可能将计算时延降至最低,这样才能有效保证调度方法的性能。为了进一步验证θ的取值,将计算时延作为测试指标,分析各个模型在不同参数θ下的计算时延变化情况,结果如图3所示。

图3 不同模型的计算时延测试结果对比
分析图3中的实验数据可知,当θ的取值较小时,计算时延明显较低。同时和已有的另外两种调度模型相比,所提模型的计算时延明显更低一些。
3)能量节省率测试结果分析/%
根据上述两组实验,确定了θ的具体取值范围。以下实验使用该取值分别对比三种不同调度模型的能量节省率,详细的实验结果如图4所示。

图4 不同调度模型的能量节省率测试结果对比
分析图4中的实验数据可知,当θ的取值为0.10时,三种调度模型的能量节能率达到最佳状态,且所提模型的能量节省率明显优于另外两种模型,更进一步验证了所提模型的优越性。
4)内存利用率测试结果分析/%
为了进一步验证所提模型的调度性能,实验对比不同节点上三种模型的内存利用率变化情况,具体实验结果如表1所示。
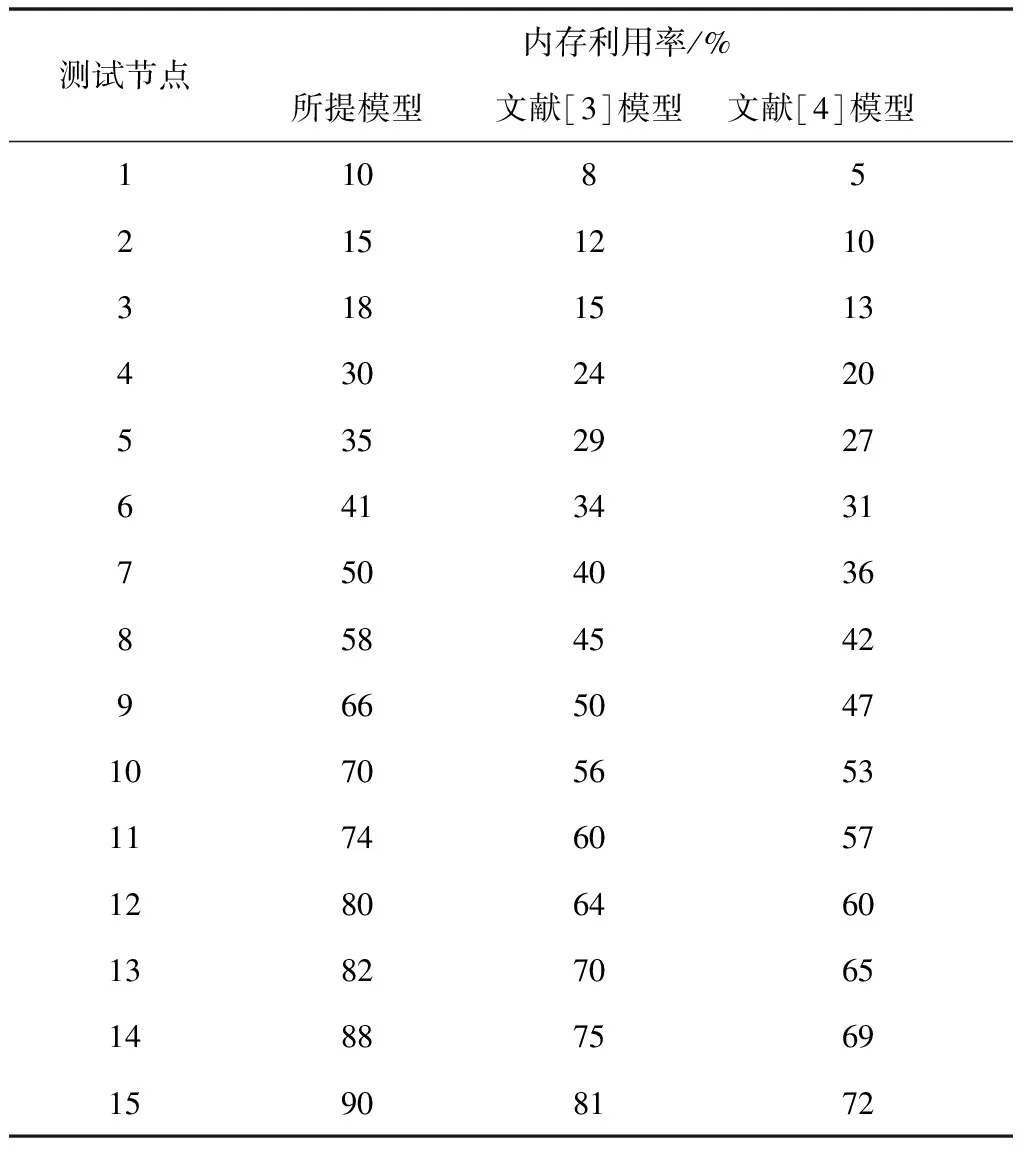
表1 不同调度模型的内存利用率测试结果
分析表1中的实验数据可知,所提模型对集群性能具有一定优化作用,可以有效提升每一个节点的内存利用率,合理完成负载均衡,具有良好的调度性能。
4 结束语
针对传统调度模型存在的一系列问题,设计并提出一种大数据网络可用带宽流量调度模型。和已有的调度模型相比,所提模型能够有效提升吞吐量、能量节省率以及内存利用率,同时还能够降低计算时延。
由于受到多方面因素的限制,所提模型仍然存在一定的不足,需进一步提升网络质量,同时考虑如何制定更加具体和完善的调度方案。且由于研究的数据规模比较大,采用单一的SDN控制器无法达到设定的要求,因此下一阶段将重点研究信息部署和共享问题。
