基于卷积神经网络的脑电情绪识别方法
2022-09-28廉小亲罗志宏蔡沫豪
廉小亲,罗志宏,蔡沫豪,高 超*
(1. 北京工商大学人工智能学院,北京 100048;2. 北京工商大学中国轻工业工业互联网与大数据重点实验室,北京 100048)
1 引言
情绪是人当前精神状态的直接反映,在人做理性决策、交流和学习的过程中都有至关重要的影响[1]。通过对情感状态的识别,可以帮助人们管理自身的心理健康,提升工作效率,帮助更多需要心理治疗的人认清自身需要调节的地方[2]。但是,平常人们对于自己情绪的判断都是带有主观色彩的,难以客观地评估自身的真实情感状态。因此,基于多数研究者使用的脑电信号(Electroencephalogram,EEG)[3],建立一个客观的情绪识别方法来进行情绪分类尤为重要。
基于目前学者的研究,情绪大多是在Lang二维情绪模型[4]的基础上进行识别分类的。该模型是一个二维平面模型,通过定义效价(Valence)和唤醒度(Arousal)两个评判基准作为平面上的横纵轴,在该平面上表征了所有的情绪类别。目前的研究多是针对效价和唤醒度分别设置阈值进行情绪二分类,分类的方法主要有以下两种。
一种方法是将脑电信号进行特征提取以减小数据量,之后借助提取的特征建立浅层神经网络来进行情绪分类。比如王雪芹等人[5]提取了脑电信号在时域、频域以及熵值三个方面的特征,从特征融合与决策融合两个角度进行情绪识别,并在效价、唤醒度两个层面上进行情绪二分类,平均准确率达到72.01%;刘珂等人[6]先采用MI互信息矩阵进行脑电信号的特征提取,后采用SVM、FLDA、KNN等方法在效价、唤醒度两个层面上进行情绪二分类,平均准确率为68.85%;周丰丰、朱海洋[7]针对脑电信号分别提取时域、频域以及空间域特征,采用三段式特征选择策略进行特征筛选,最后使用SVM进行情绪二分类,平均准确率为71.00%。
另一种主要的分类方法是基于端到端的深度学习模型,将脑电信号进行预处理后直接输入到深度神经网络进行训练,该方法无需复杂的特征提取方法。比如 Li X等人[8]基于小波变换将脑电信号转换为网格状帧后,将其输入卷积神经网络与递归神经网络的融合模型进行情绪二分类,平均准确率达到73.12%;阚威、李云[9]利用预处理后的时序脑电信号训练LSTM情绪二分类器,平均准确率为73.75%;Yang Y等人[10]对脑电信号进行了一维至二维的转换,并将其输入设计好的并行CNN与RNN的融合模型进行情绪二分类,平均准确率为91.01%;程程[11]基于分层卷积模型依次提取脑电信号的局部卷积特征,并分别在效价、唤醒度两个层面上实现了情绪二分类,平均准确率为83.86%,之后通过优化脑电波波段和采集通道将准确率提高至91.55%。
但是,以上情绪二分类的方法都是基于复杂的脑电信号预处理方法以及复杂的深度学习模型实现的,在训练和实际进行识别操作的时候时间成本较高。考虑到Lang二维情绪模型是建立在效价和唤醒度两个维度上的,而前人做的二分类识别只是针对其中一个维度进行阈值二分类,无法对具体的情绪做到细粒度的识别。针对此问题,Zheng Weilong等人[12]在Lang情绪模型的基础上,首先采用微分熵对脑电信号进行特征提取、线性动态系统(LDS)方法进行特征优化、最小冗余最大相关(MRMR)进行数据降维,随后使用极限学习机(GELM)进行效价、唤醒度相结合的情绪四分类,平均准确率为69.67%。
针对目前情绪识别方法大多只关注相对简单的二分类问题,在更为精细、复杂的四分类问题上存在准确率不高、模型较为复杂的问题,本文通过调研,结合脑电电极的空间分布特征进行脑电信号重构,并设计轻量化的卷积神经网络模型进行情绪四分类,最终实现对情绪的细粒度识别.
2 脑电信号数据集处理
2.1 DEAP数据集
为了便于与前人的研究成果进行对比分析,本文采用DEAP(database for emotion analysis using physiological signals)公开数据集作为实验数据。该数据集是由Sanders Koelstra等[13]建立的公开情感数据集,包括了16名男性和16名女性被试者的脑电数据。被试者佩戴符合10-20国际标准的32导联电极帽,以512Hz的频率进行EEG信号采样。被试者在观看完40段时长为1分钟的刺激视频后,被要求以浮点数的形式(数值范围1-9),在效价(Valence)、唤醒度(Arousal)、优势度(Dominance)以及喜好度(Liking)四个方面对视频观后感做一个相对客观的评价,实验人员将该评价结果作为对应视频的样本标签进行记录。本文采用的实验数据为官方降采样至128Hz后进行4-45Hz带通滤波且去除眼电及其它肌电信号后的数据,本文依据Lang二维模型,采用官方记录四个标签值中的效价、唤醒度作为本文的评价标准。
2.2 数据集预处理
文献[14]的研究结果表明相同情绪的脑电信号在个体之间存在差异性,因此情绪分类模型的建立需要以个人为单位,即一个人对应一个模型。由于DEAP数据集的被试者仅仅观看了40段视频后作出评价,因此针对每个被试者只得到了40组数据和标签作为样本,该原始数据集较小且难以满足深度学习模型的训练要求。同时,DEAP数据集中每一采样时刻所对应的一维数据向量无法体现脑电电极在大脑上的空间分布特征。本文针对以上问题,对DEAP数据样本进行了特征重构。
2.2.1 脑电信号背景扣除及时域分割
根据文献[15],采集的脑电信号中往往包含大量的背景信号,而背景信号会影响后续情绪识别的准确率。因此,为了提高情绪识别的准确性,本文对原始脑电信号进行处理,将受刺激时记录的信号与背景信号的差值作为待使用的数据。DEAP数据集每个标签对应的数据中提供了32通道的3s背景信号,鉴于此本文以1s为时间窗将每个标签对应的背景信号分割成三段,将这三段信号取平均值后作为每个标签对应数据的背景信号,接着将后60s的受刺激信号也以1s为时间窗进行分割,再把每一段受刺激信号减去背景信号,进而得到受刺激信号与背景信号的差。具体的背景信号处理的流程图如图1所示[15]。
将这些去除背景信号后的数据作为新的脑电信号,并且按照1s的时间长度进行分段保存并延续使用原来的标签。这样,每个标签对应的样本就由1组变成了60组,扩充了后续模型训练时所需要的样本数。同时每个标签对应的实验数据由原来的32×7680(通道数×采样点)矩阵切割为60个拥有同样标签值的32×128矩阵,后续每个矩阵作为输入进行模型的训练,变相的缩小了每次训练时的样本数据大小,提高了后续神经网络的训练效率。

图1 背景信号处理流程图
2.2.2 脑电信号维度重构


图2 10-20系统平面图
其中颜色标注的就是DEAP数据集中使用的脑电测试点。从图中可以看出,每一个电极都与多个电极相邻。根据文献[16]可知大脑可以功能区的方式进行划分,因此电极的空间排布特征也是一种有助于情绪识别的特征信息,应当与数据集本身提供的脑电时序信号一同作为输入数据进行训练。基于以上分析,本文将分割完的数据集进行一维向量形式向二维帧矩阵形式的转换,具体如下:

(1)


(2)
其中,x表示数据帧从某个位置开始时的非零元素,μ表示所有非零元素的平均值,σ表示这些元素的标准差。因此,每个被试者的样本数都从原来的40个扩充到了2400个(40次实验×60个片段),并包含了电极的空间分布特征。
2.3 数据集筛选及标签阈值处理
根据常用的连续情绪模型——Lang二维情绪模型对于情绪的定义,每一个情绪都可以由效价(Valence)和唤醒度(Arousal)两个维度来共同表征。依此可以绘制出一个情绪平面分布图,如图3所示。
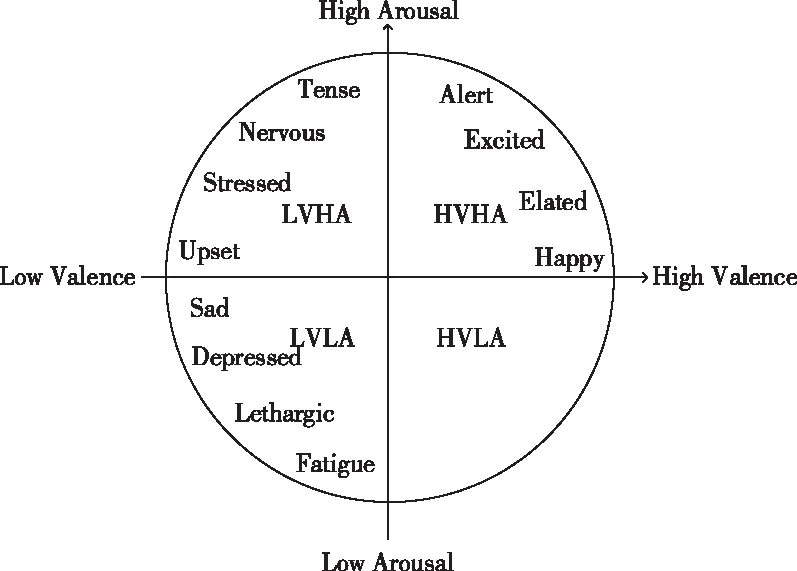
图3 Lang二维情绪模型
图中横坐标是效价,纵坐标是唤醒度。假设以回归问题来解决情绪识别问题,让每个情绪都定位于平面上具体的某一个点,这无疑是一个很难解决的问题。如果以分类问题对情绪进行效价或唤醒度层面的二分类,每一类的区域范围又过大,对于被试者当前的情绪很难精确描述。所以,本文将情绪平面如图3所示划分为四个象限区域,这样能够进一步实现最终识别的情绪与实际情绪相匹配。本文以5为阈值进行高低效价和唤醒度的划分,将所有的标签依照原浮点型标签统一改写为高效价高唤醒度(HVHA)、低效价高唤醒度(LVHA)、低效价低唤醒度(LVLA)以及高效价低唤醒度(HVLA)四类,并分别以0-3的整数进行编码。根据文献[17],被试个体差异会导致样本在阈值附近形成模糊样本,所以应该舍弃效价和唤醒度标签值在4.8-5.2之间的样本,从而更好地实现情绪分类。
3 基于脑电信号的情感分类模型
随着计算机视觉识别技术的更新迭代,卷积神经网络的识别分类效果也不断提高[18]。本文参照成熟的计算机视觉识别图像技术,从其原理的角度出发寻找合理的方法与模型来解决情绪分类问题。
3.1 模型输入设计
在计算机图形学的领域中,一张图片可以用红、绿、蓝三原色来表示(即RGB)。在RGB三个通道中用0-255的值来表示图像上某一像素点的某一原色强度,彩色图片是最终呈现给人的三个通道融合后的结果。
计算机视觉图像可以看成一个三维矩阵,RGB三种原色在视觉光谱中属于不同的频段范围,每个原色通道都是一张单独的图片。如果一张图片的三原色通道排布均匀,那么每个通道的图片都会带有图片中待识别物体的特征。以此为启发,考虑到脑电信号的标签是一段连续时间的标签,那么一段时间内的某一个时刻的脑电信号也可以带有待识别标签的特征,所以将预处理好的每个标签对应的1s的脑电数据帧段以采样时刻为单位进行堆叠。因为数据的采样频率为128Hz,所以仿照图像构成的原理将脑电数据帧段看做是9×9的128通道的图像,每一通道都是1s样本中某一采样时刻对应的帧矩阵。这样仿照图像识别的方式,将9×9×128的一组样本输入卷积神经网络中进行加权训练,即可达到与图像识别一样的分类效果。图像与脑电信号类比的关系如表1所示。

表1 图像与脑电信号的对应术语
3.2 模型结构设计

图4 连续卷积神经网络结构
3.3 模型训练
模型的训练是通过前向传播进行卷积操作输出结果,接着将误差反向传播进行卷积核的值的调整。通过这样的迭代,在保证模型具有较大泛化能力的同时提高模型的情绪分类准确率。具体的训练方法为Adam(Adaptive Moment Estimation)梯度下降法,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定的范围,使参数比较平稳。其公式如下
mt=μ*mt-1+(1-μ)*gt
(3)

(4)

(5)

(6)

(7)
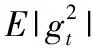
全连接层的输出使用Softmax函数。Softmax函数的作用就是将每个类别对应的输出分量归一化,使各个分量的和为1,即可以理解为将任意的输入值转化为概率,而概率最大的即认为是最终的分类结果。Softmax计算公式为:

(8)
损失函数使用交叉熵的方法,它是用来描述两个分布的距离函数,对于神经网络来说就是检测g(x)逼近p(x)的程度。在多分类的情况下,由Softmax计算出每个类别的概率,代入以下公式进行计算:
(9)
其中K是类别的数量,N是样本的数量,y是标签,i是观测样本,c是真实类别。在此公式中如果i=c则yic=1,否则等于0,pic是神经网络对观测样本i是否属于c的预测概率,这个输出值由Softmax函数计算得来。
在干燥处理之前,茎瘤芥分别在功率为0,200,400,600 W的超声波条件下进行30,60 min预处理(见表1)。在超声波预处理过程中,将茎瘤芥样品放入500 mL蒸馏水中。超声波处理后,用吸水纸吸去表面多余水分,随后放入干燥箱中进行热风干燥[5]。
同时网络训练的结束标志是参考准确率以及损失函数的值的,当模型训练的准确率提升不到1%,或者损失函数值下降时没有做到准确率的提高的时候网络的训练终止。
4 实验结果对比分析
依照前面几节的内容,对DEAP数据集进行数据重构并建立模型进行训练,同时对每个人的样本进行十折交叉验证(10-fold cross-validation)来对模型的分类效果进行评估。十折交叉验证就是将数据集分成十份,轮流将其中的九份作为训练数据,一份作为测试数据进行试验,每次试验都会得到相应的准确率,十次结果的准确率的平均值作为对算法精度的估计。在DEAP数据集中一共有32个被试者,在进行标签筛选后每个人的样本数也不一样,通过十折交叉验证将数据集分为训练集和测试集后对应的数量如表2所示。
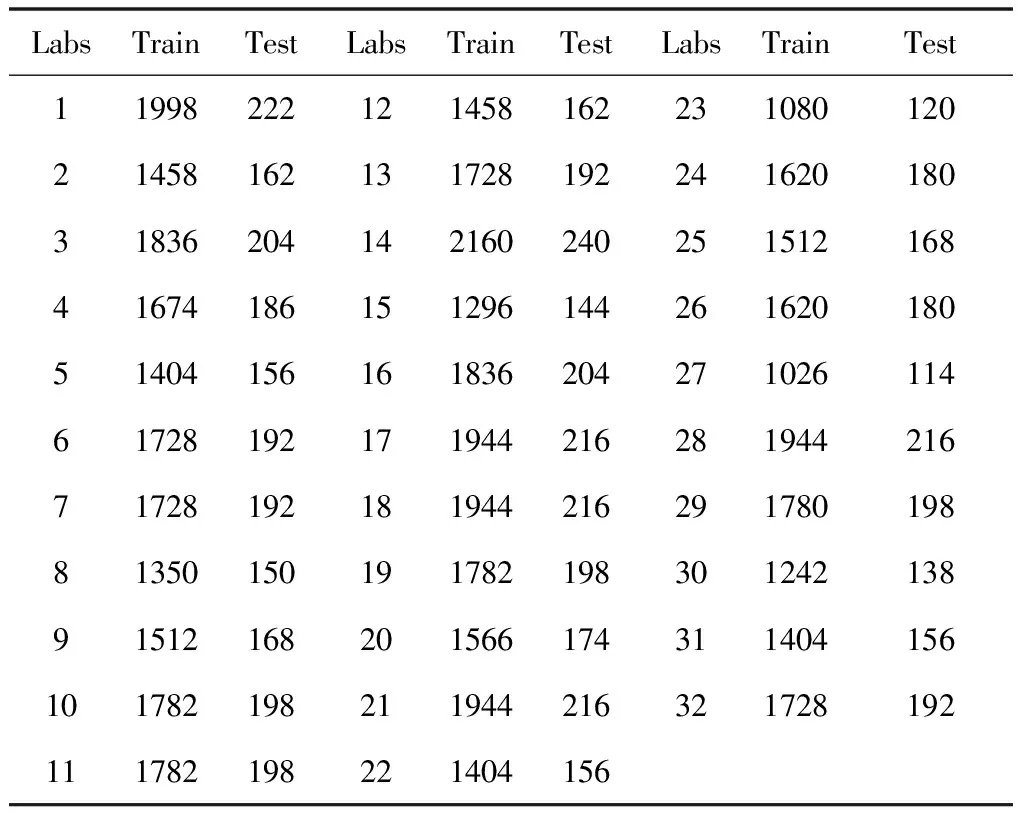
表2 标签筛选后被试者训练样本与测试样本的个数
从表中可以看出,每个被试者通过标签筛选后的样本数量基本都不相同,这从另一方面验证了对于同一段视频刺激,不同被试者的脑电数据及其对应的情绪标签也是不尽相同的。因此在建立情绪分类模型的时候,以个人为单位建立的模型要比以所有被试者的数据集合建立的模型更合理准确。因此,本文依次对每个被试者建立轻量化卷积模型,分别按照十折交叉验证的规则进行实验。模型建立主要借助TensorFlow框架实现,在Inter(R) Core(TM) i7-10870H CPU上进行训练,模型batch设置为32时,训练的迭代次数最多为7即可满足模型准确率要求,每次迭代用时1s。实验的分类结果如表3所示。

表3 轻量化CNN四分类结果
但以上都是样本标签在阈值范围内的理想情况,还需要测试以理想情况训练出来的模型是否适用于阈值边缘的情况。因此将先前筛选出来的阈值边缘样本作为测试集,以所有阈值内的样本作为训练集,以此进行实验。这样每个DEAP数据集中的对象都会得到一个相关的准确率,具体结果如表4所示。
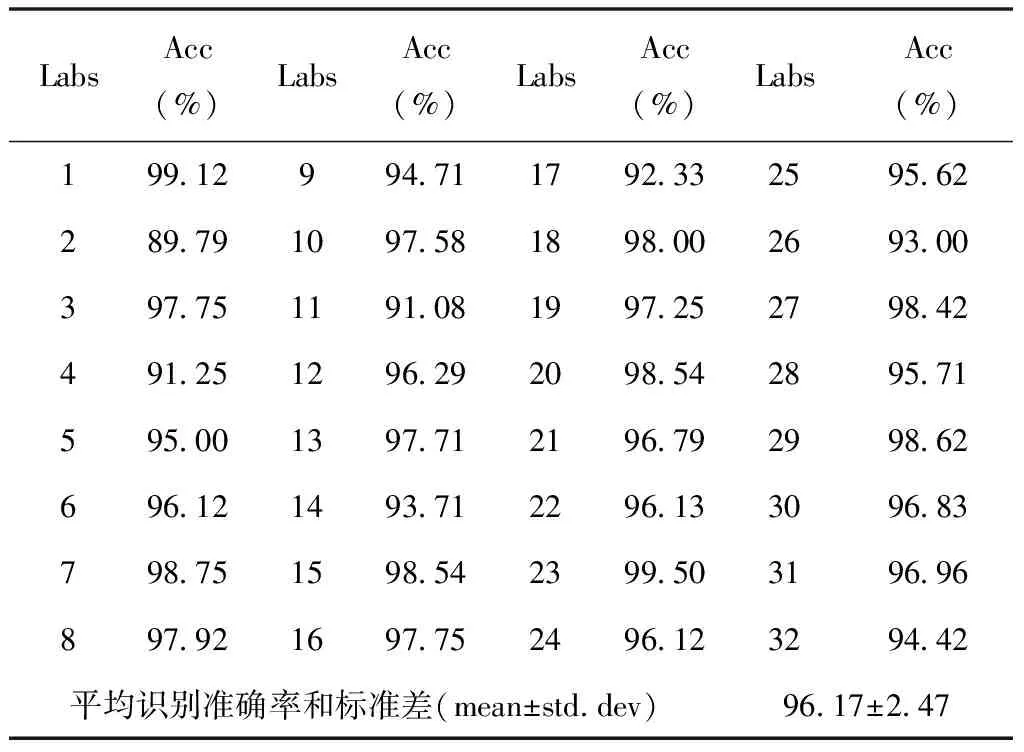
表4 边缘样本测试准确率
样本标签在阈值范围的数据属于常规数据,而从表4可以看出使用常规数据训练出来的模型同样适用于识别边缘样本。
本文的数据预处理与类比计算机图像识别的思想参考了文献[10][15]的方法。Yang Y等人[10]将脑电信号预处理为二维矩阵后使用CNN与RNN的融合模型进行情绪二分类,平均准确率为91.01%,低于本文的四分类准确率,且该文献的模型包含了并行的两个基础模型,本文的模型为轻量化卷积神经网络,相对简单、高效。杨一龙[15]将脑电信号的不同频段计算出差分熵矩阵进行堆叠,并输入四层卷积层的卷积神经网络进行情绪二分类,平均准确率为89.88%,低于本文的四分类准确率,而本文的脑电信号除了去除背景信号的操作外没有进行任何的计算步骤,直接进行二维转换,在数据预处理的计算量上小很多,同时模型的复杂度更低。由此可见,本文在情绪识别的类别数量、数据预处理计算量、模型复杂度这三个方面均优于以上两篇文献。
本文在保证数据完整性的前提下充分利用了深度学习网络自主提取特征的特性,对原始数据进行维度重构并加入了脑电采集的电极空间分布特征,提高了情绪分类的准确率。前人研究多是先人工进行脑电特征提取,这一操作大多会造成特征缺失的问题,后续网络训练就很难做到在有限的特征中高准确率的进行情绪识别分类;并且少有人进行背景信号去除的操作,这样会让提取的特征中夹杂有大量的噪声信号,对识别会形成很大的干扰;同时本文针对待处理的脑电信号特征设计了轻量化卷积神经网络,对最终的高准确率情绪分类起到了关键作用。所以本文的最终情绪识别准确率和识别种类数均优于前人研究结果。具体的对比结果如表5所示。

表5 使用DEAP数据集评估方法对比
综上所述,本文所使用的方法在保证数据预处理和模型复杂度低的同时也保证了较高的准确率。
5 结论
本文使用公共DEAP数据集进行情绪识别模型的评估,考虑了脑电背景信号的影响,采用了一种简单且计算量小的数据预处理方法获取了脑电信号的时域特征信息,同时结合脑电电极的空间分布获取了脑电信号的空间特征信息,两者融合后的脑电信号时空二维矩阵作为卷积神经网络的输入,参考计算机视觉图像识别的成熟技术设计了轻量化连续卷积模型,通过该模型自提取对应标签的情绪特征,进行基于Lang二维情绪模型的四分类,对情绪的情况判断更为精细。结果表明在该方法下,情绪识别在四分类上准确率明显提高。
本文的方法适用于个人情绪模型的快速训练及识别的问题,该方法在实际的应用中,可以基于个人脑电信号建立情绪识别模型,从而较好的监测个人的情绪状态。考虑到每个人的同一种情绪在脑电信号中都存在一定的共性特征,基于这些共性特征是否可以建立一个适用于多人的情绪识别模型,这也是目前基于脑电信号的情绪分类方法的研究热点与难点。
