基于相似性指数聚类的风电功率预测方法研究
2022-09-28师洪涛张智峰丁茂生潘俊涛
师洪涛,张智峰,丁茂生,2,潘俊涛
(1. 北方民族大学电气信息工程学院,宁夏银川750021;2. 宁夏电力有限公司,宁夏银川750001)
1 引言
风能得到了广泛的开发利用,但是风的随机性、间歇性等特点造成风力发电的不稳定,大量的风电并入电网,会对系统产生冲击[1]。风电功率预测技术是解决这一问题的有效方法之一,通过提前对风力发电功率的预测,用于电力部门制定调度计划,从而提高风能的利用率,减小并网的冲击影响。
风电功率预测方法可大致分为两类:一是物理方法,通过对风电场周围的环境参数的采集,将其代入至风机曲线中,从而得到风电场的发电功率,但是此方法需要的参数较多[2];二是统计方法,根据风电场记录的天气预报数据和功率数据,将它们之间的非线性关系表示出来,建立对应的模型,采用天气预报等因素,对预测模型进行训练与预测。目前采用统计方法的预测模型较多,常用预测算法有神经网络[3]、支持向量机[4]、多种方法组合预测[5]等。
风电场记录保存的数据庞大复杂,很难直接从中直接得出天气因素与风电功率之间的关系,因此需要对数据做预处理,以提取数据中隐含的特性。聚类方法将具有相似特性的数据放在一起,数据之间的关联性强,从而容易提取数据中的特性信息,常用的聚类方法有k-means聚类[6]、模糊C均值聚类[7]、密度峰值聚类[8]等。
目前用聚类方法处理风电功率数据,一般可分为三类:一是将功率数值相近的数据归为一类,建立对应的预测模型进行训练,但在实际数据中存在天气数据差异较大、功率值相近的情况,会影响模型的预测精度[9];二是利用天气因素对风电功率数据进行聚类,如根据风速对风电数据进行一次聚类,在此基础上,再对每一个样本子集利用风向做二次聚类,这样忽视了功率点在整体上所处的功率段变化趋势[10];三是对天气数据和功率数据分别进行聚类,再将聚类出的子集进行组合,这样做虽然能够提高预测精度,但是增加了需要建立模型的数量,数据处理的过程更加复杂,需要较长的时间[11]。
欧氏距离是常用来计算数据之间距离的一种方式,其计算过程简单,物理意义明确。但是采用欧式距离作为样本点划分的依据,只表示出样本点与聚类中心的关系,没有将数据所包含的整体性表达出来。针对上述问题,本文提出使用指数相似系数法对模糊C均值聚类中的欧式距离进行改进,通过计算每个点与聚类中心在样本整体离散情况的相似变化程度,将数据点所处的天气变化程度和功率段趋势同时提取出来,得到的样本子集包含更多数据点在原来样本整体上的信息,再对此进行分类建模,建立不同的BP神经网络模型进行训练。
2 风电数据特征提取方法
2.1 传统风电预测中的聚类方法
以往对风电功率数据使用聚类算法进行预处理时,常用样本数据中的功率或几个天气因素,以此对风电数据进行分类,这样虽然可以进行一定的聚类划分,但忽视了各天气因素是整体对风电功率起作用,单一利用某一特征对记录的整个风电功率数据进行划分,是不合理的。风电功率预测框架图如图1所示。

图1 风电功率预测框架图
从图1可以看出,常用的风电影响因素中仍能挖掘出一些隐藏的特性数据,在聚类时如果能考虑到这些特性,就会使得样本子集更加紧致,但实际中很少被用到,这一点还需改善。
另外,大多数聚类算法采用欧氏距离度量数据点之间的关系,通过计算样本点与聚类中心之间的距离,将距离相近的样本点划分到一类中,具体的计算公式为(1)式

(1)
式中,dij表示第i个样本点xi到第j个聚类中心oj之间的距离;xik和ojk分别表示样本点xi和聚类中心oj的第k个特征数据。
但是,欧式距离只是将样本点与聚类中心当作两个孤立的点,注重两点之间的距离。然而,风电场所在地区的天气和功率数据是连续变化的,使用欧式距离作为判据,在聚类过程中,无法对数据中趋势特性进行有效提取,最终影响聚类出的样本子集内部的紧致性。图2为使用欧式距离聚类出的样本子集散点图。
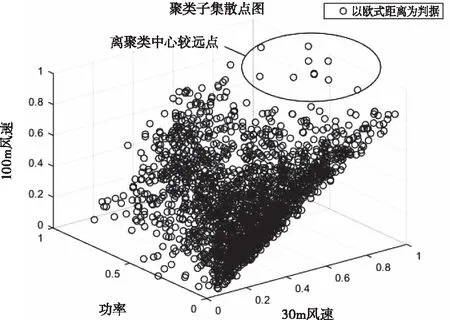
图2 聚类子集散点图
从图2可以看出,虽然使用欧氏距离聚类出的大部分样本点聚集在一起,但仍有少部分点远离原来的聚类中心,影响到聚类子集的紧致性。因此,应该选取一种能对样本数据整体进行更好衡量的方法。
2.2 趋势特性数据特性提取原理
风电功率变化是多种天气因素共同作用的结果,当前时刻的天气和风电功率较前一时刻的数据不完全相同的,且各天气因素对风电功率的作用不同,各天气因素的变化程度和功率段趋势可通过下列公式计算得到:
ΔXI=XIt-XI(t-Δt),I=1,2,…,d
(2)
上述公式,通过不断变化I计算风电数据中的风速、风向、温度、压强、功率等特征数据的变化ΔXI,XIt为当前时刻的风电功率数据,XI(t-Δt)为前一时刻的风电功率数据,d为记录的风电场数据的特征维数,Δt为采样的时间间隔。
风电功率频繁变化时,会影响风力发电并入电网的稳定性,也会导致预测模型预测精度降低[12]。因此,通过式(2)计算出各种天气变化和功率段变化趋势,再利用指数相似系数法,对风电中的隐藏特性数据进行有效提取,以下将对提取的方法进行详述。
3 基于相似性指数聚类的预测模型构建
3.1 基于相似性指数的多维数据距离度量方法
模糊C均值聚类算法(fuzzy c-means algorithm,FCM)是一种经典的用于提取具有相似特性的聚类方法[13-15]。为了对风电数据中包含的天气变化程度和功率趋势进行有效提取,而且不增加聚类算法的复杂度,本文提出使用指数相似系数法对FCM中的欧式距离进行改进。
指数相似系数法是一种常见的用于模糊聚类的判据[16],其具体的计算公式为式(3):
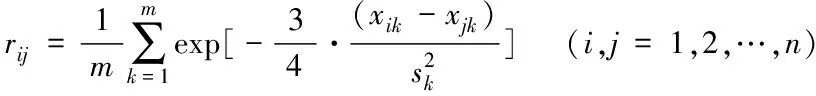
(3)
式中,xik为样本中第i个样本数据的第k维特征值,xjk为样本中第j个样本数据的第k维特征值。使用(3)式进行聚类时,需计算出每个样本点与所有点的指数相似系数,计算量较大,且具体将数据划分为几类,还需确定阈值。
考虑到要对样本点与聚类中心之间多维度数据进行衡量,且聚类中心影响到聚类的效果。因此,基于指数相似系数法,将距离判定公式改进为(4)式
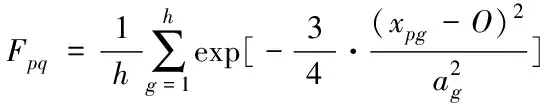
(4)
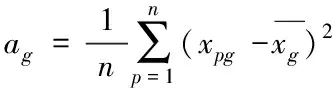

改进后的(4)式,只需要计算样本点与聚类中心的指数相似系数,减小了计算量。同时,聚类中心O的个数的确定,省去了原本模糊聚类中阈值设定的步骤。
另外,与使用欧式距离作为判据相比,聚类出的样本子集能最大程度上保留原有的特性,同时不会增加所需要建立预测模型输入的维度,帮助模型更好地学习数据中隐藏的关系,从而提高风电功率的预测精度。
3.2 功率与气象数据的相关性聚类流程
为了找寻功率与气象数据的关系,根据天气变化程度对风电功率造成的不同影响,利用3.1中的新判据对FCM算法进行相应的更新,将具有相似变化的风电数据聚在一起。
使用新判据后进行更新迭代的隶属度矩阵,如表1所示。

表1 隶属度矩阵表
表中,uqp表示的是样本点xp对于聚类中心oq的隶属度。
改进FCM聚类算法的流程图如图3所示。图中虚线部分为对算法进行改进的部分,分别是利用指数相似系数法计算各天气因素变化值、功率段变化值、计算综合天气变化和功率变化值,最终得到所需的各样本点与聚类中心的离散相似变化矩阵。
3.3 多神经网络模型的构建
使用指数相似系数完成对FCM的相关改进后,对每个样本子集建立相应的风电预测模型。如图4所示。
从图中可看出建立多神经网络预测模型的步骤如下所示:
1)对样本数据使用改进后的FCM进行处理,得到聚类出的各样本子集;
2)对每个样本子集分别建立相应的BP神经网络模型进行训练,调整好模型内部的参数;
3)再有新的数据进入时,根据数据对应的类别,送入训练好的神经网络模型中进行预测;
4)预测结果按照分类前相应的时间顺序进行排列,得到预测时间段的风电功率曲线。
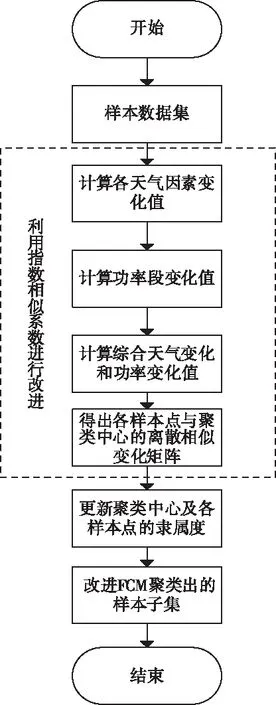
图3 改进FCM算法聚类流程图
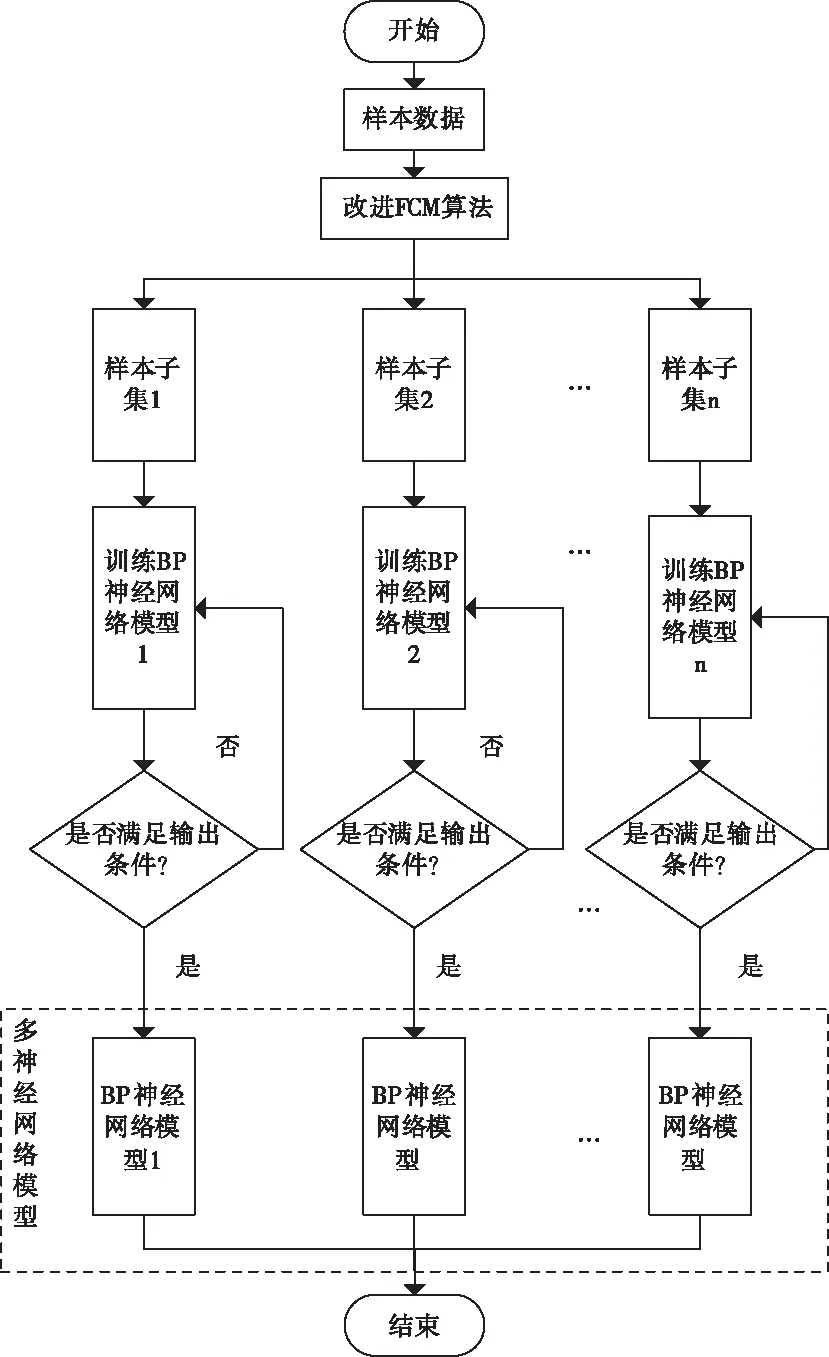
图4 多神经网络模型框架图
4 实验验证
采用风电数据进行验证,对数据先进行归一化操作,采样的时间间隔为1h,进行短期风电功率预测。选择30m风速、100m风速、100m风向、温度、压强和风电功率数据共同组成样本数据,分别使用改进后FCM和FCM进行聚类,具体步骤如3.2节所示,样本数据被聚为3类。使用CH(+)和FS(-)[18]两个指标对两种算法聚类结果的有效性进行评判,结果如表2所示。

表2 两种聚类算法聚类有效性表
由表2可知,以指数相似系数为判据的FCM聚类算法得到的样本子集的紧致性要优于使用欧式距离作为判据的FCM。将两种聚类算法得到的不同样本子集按照3.3节中的步骤分别建立对应的多神经网络模型进行训练,再建立一个BP神经网络模型直接进行预测,将三种不同方法的预测结果进行对比。预测的结果如图5所示。
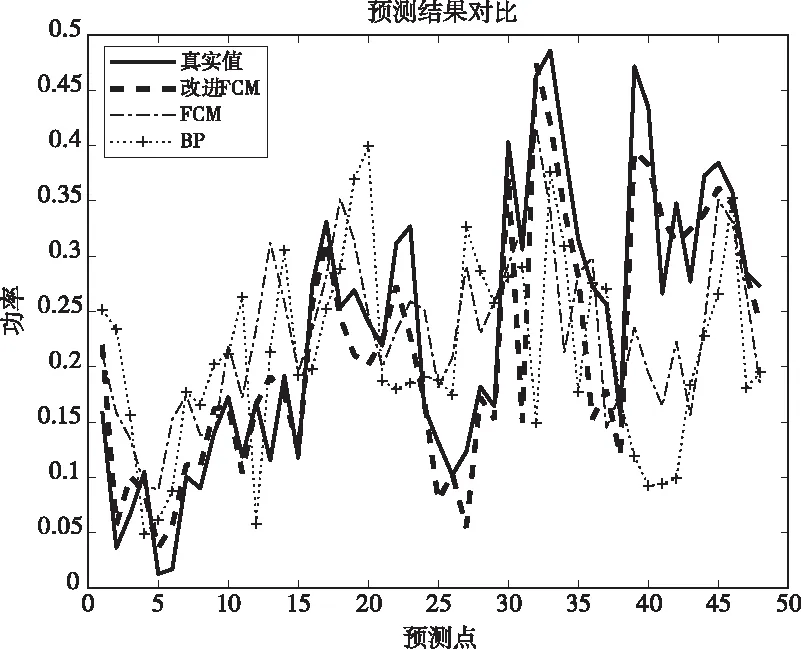
图5 不同方法的预测结果对比图
不同方法对应的误差分析图如图6所示。
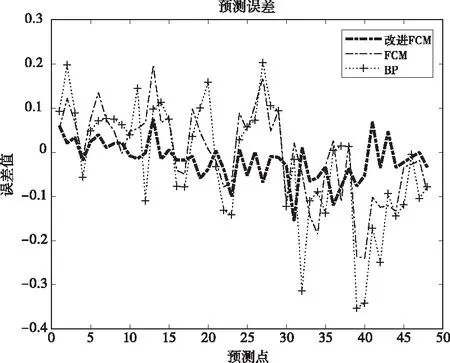
图6 不同方法的预测误差对比图
结合图5和图6,可以看出使用指数相似系数作为判据的FCM的预测图像与使用欧氏距离作为判据的FCM、直接使用BP神经网络相比,拟合效果更好。
采用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)进行结果评比,结果如表3所示。
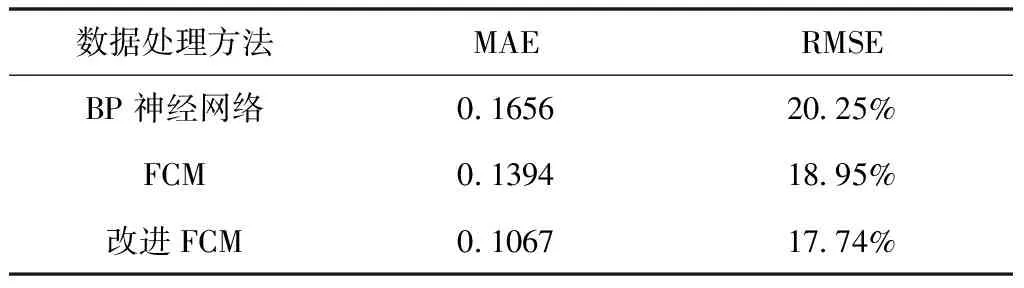
表3 不同方法的预测结果对比
从表3分析可知,使用聚类算法进行数据处理能够提高预测模型的预测精度,改进后的FCM与其它两种方法相比平均绝对误差分别降低了0.0589和0.0327,均方根误差分别降低了2.51%和1.21%,预测精度要优于其它两种方法。
5 结论
本文提出一种基于相似性指数聚类的风电功率预测方法,算例验证表明采用指数相似系数法对FCM中的欧式距离进行改进后,能够在聚类时考虑到样本点所在位置的气象因素变化程度和功率段趋势的关联性,进而聚类出的样本子集包含更多数据特征,且风电样本子集中的数据点更加紧凑;结合分类建模思想,建立多神经网络预测模型,与传统方法相比,风电预测精度有所提高,证明了所提方法的有效性;同时,该聚类方法对样本点隶属度的更新迭代计算量较大,对此可做进一步优化,以提升算法的性能。
