火电厂监控视频安全帽检测方法研究
2022-09-24游锦伟于俊清
游锦伟,薛 涛,于俊清*
(1.国能长源汉川发电有限公司,湖北 汉川 431614;2.华中科技大学计算机科学与技术学院,湖北 武汉 430074)
0 引言
安全帽作为工业生产过程中必不可少的人身安全防护装备,可以有效保障生产人员的安全。当前安全监管部门在火电厂区内部安装监控摄像头,通过人眼观看监控视频的方式巡视工业生产运行过程中是否存在安全隐患。但是通过人眼查看监控视频的方式存在诸多缺陷,比如长时间疲劳工作的监管人员容易遗漏监控视频画面中工作人员没有穿戴安全帽的危险情况,由于监管人员自身的麻痹大意无法做到及时预警。利用计算机视觉领域中的相关技术,替代监管人员查看监控的方式完成安全帽检测任务。开展基于工业监控视频的安全帽检测算法研究,可以起到保障工业安全生产、维护工作人员生命安全、提高工业生产管理效率的作用。
在计算机视觉领域中,目标检测是非常重要且基础的一项任务,其中相关的目标检测算法可以根据实现原理分为传统目标检测算法和基于深度学习的目标检测算法[1]。传统目标检测算法主要是通过手工的方式提取目标的特征,例如安全帽的形状颜色等特征,主要有维奥拉-琼斯目标检测框架(Viola-Jones Object Detection Framework,VJ-Det)[2]、可 变 型 部 件 模 型(Deformable Part-based Model,DPM)[3]、选择性搜索(Selective Search,SS)[4]等。随着深度学习的发展,基于深度学习的目标检测算法因其优越的鲁棒性逐渐取代了传统算法,成为工业领域安全帽检测算法的主流技术[5]。Krizhevsky 等人在2012 年提出AlexNet[6],该算法获得了ILSVRC-2012 图像识别比赛的冠军,之后更多更深的深度学习目标检测算法被提出。2014 年,Girshick 等人发现了基于卷积神经网络特征提取的区域检测模型(Regions with CNN features,R-CNN)[7]。后来者们在R-CNN的基础上对模型继续优化,例如在网络中加入空间金字塔池化层(Spatial Pyramid Pooling,SPP)[8]或特征金字塔网络(Feature Pyramid Networks,FPN)[9]等,用来提高模型的检测准确率,又提出了Fast R-CNN[10]、Faster R-CNN[11]、Mask R-CNN[12]等优秀的算法。2016年,Liu W等人提出了SSD算法[13],并在此基础上改进得到了DSSD算法[14],同年,Redmon J等人提出YOLO[15],该算法凭借较高的检测精度与简单易用的特性被广泛运用于工业环境中各项目标检测任务,之后经过迭代衍生出了一系列的YOLO算法[16-18],本文对安全帽进行目标检测任务是基于YOLOv5完成的。在工业生产环境中,目标检测算法除了能够识别安全帽的形状和颜色外,还需要考虑复杂的背景、光照变化、遮挡以及摄像头过远导致目标过小等复杂问题,原有的YOLOv5算法并不足以应付这些场景,实际应用场景中容易出现误检、错检等问题。
为了能够在复杂场景中实现更好的鲁棒性和小目标的检测精度,本文提出了改进的YOLOv5 算法,对YOLOv5 的Head 模块进行了重构,通过基于k-means聚类算法对Anchor数目大小调整,增加网络自顶向下特征提取过程中的上采样,进一步扩大特征图,并与浅层特征信息充分融合,增强了多尺度特征提取能力,并将改进后的算法应用到工业监控视频的安全帽佩戴行为检测中,实际应用结果表明,改进后的算法对安全帽的检测效果得到了有效提升,能够满足工业场景中的检测需求。
1 基于VOLOv5的安全帽检测算法
1.1 YOLOv5 网络结构
本文选取YOLOv5算法作为基础目标检测模型框架。如图1所示,YOLOv5的网络模型结构由4部分组成,包括图像输入(Images)、骨干网络(Backbone)、颈部(Neck)与检测头(Head)。
Anchor 是目标检测算法中常用的一种技术手段,通常目标检测算法会对预测的对象范围进行约束,避免模型在训练时盲目地寻找,如图2。
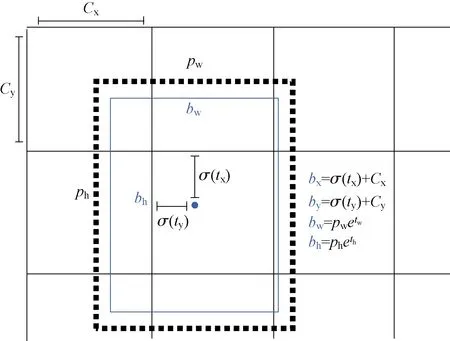
图2 Anchor Fig.2 Anchor
如图1,YOLOv5中的Head模块中的主体部分为3个Detect 检测器,利用基于网格的anchor 在不同尺度的特征图上进行目标检测,不同的算法计算anchor 的位置都有所不同,YOLOv5算法中是使用k-means聚类算法来对数据集中目标的边界框进行计算,得到大小不同的矩形框,并根据待检测目标对象的尺寸进行匹配,从而识别出不同大小的物体。图像输入模块会对输入图片进行自适应缩放,YOLOv5 算法的图像输入定义为640×640,当输入为640×640 时,3 个尺度上的特征图分别为:80×80、40×40、20×20。
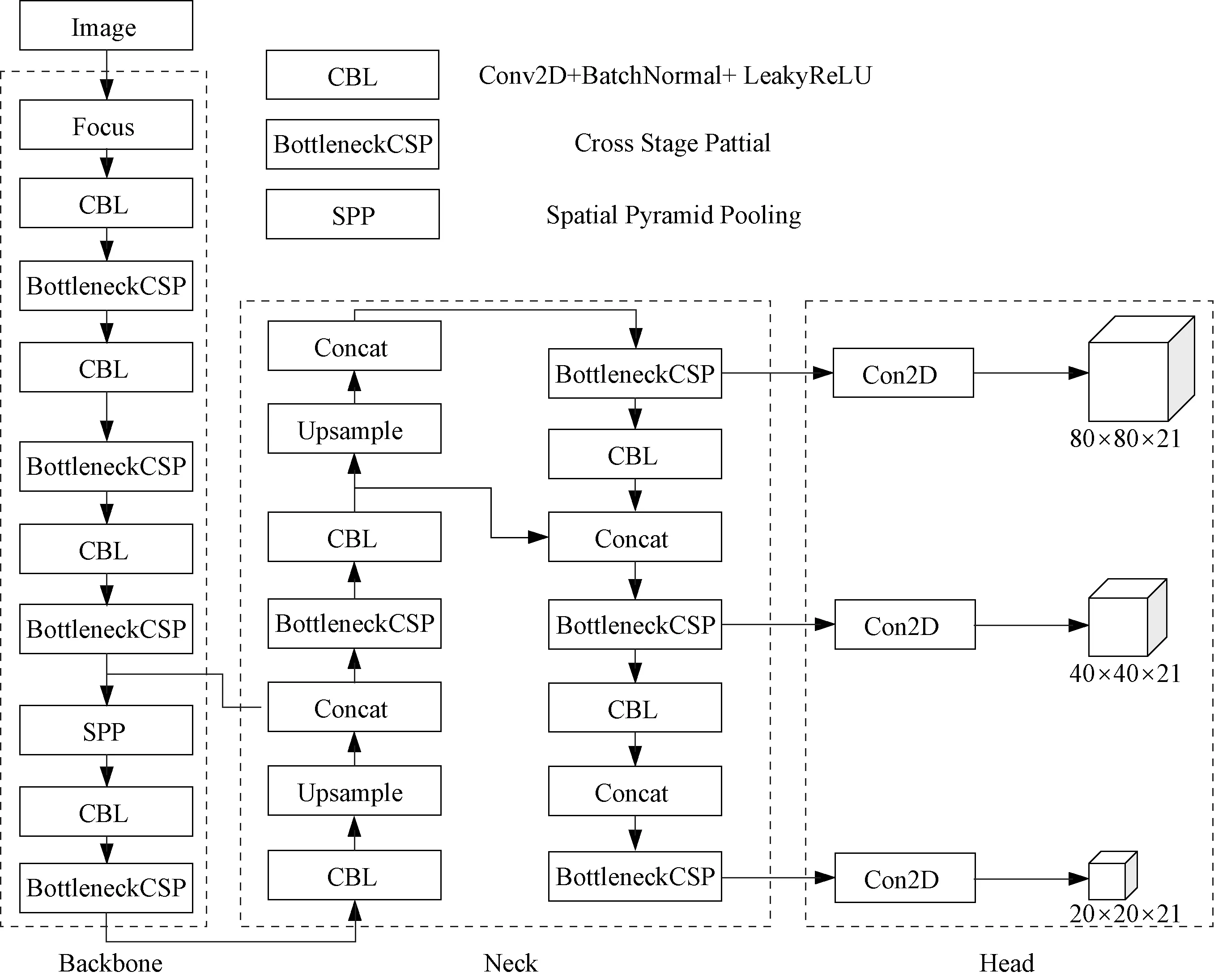
图1 YOLOv5 网络结构Fig.1 YOLOv5 network structure
1.2 基于k-means 聚类算法的Anchor 调整
YOLOv5 算法基于k-means 聚类算法得到的9 个Anchor 进行预测,在YOLOv5 的网络配置文件中可以看到初始的Anchor 维度参数为:(-[10,13,16,30,33,23]#P3/8;-[30,61,62,45,59,119]#P4/16;-[116,90,156,198,373,326]#P5/32)。如图3 所示,YOLOv5 预测输出端由3 个检测头组成,每个检测头对应一组Anchor 参数。YOLOv5算法会对输入图片进行自适应缩放操作,将网络的图像输入尺寸统一调整为640×640。而#P3/8 网络层检测头尺度为80×80,所以用于检测尺度为8×8 的小目标。同理,#P4/16 网络层检测头尺度为40×40,用于检测尺度为16×16 的目标。而#P5/32 网络层检测头尺度为20×20,用于检测尺寸为32×32 的 较 大 目 标。YOLOv5 的3 组Anchor 是 基 于COCO 数据集聚类得到,并不适用于本文所构建的安全帽目标检测数据集。由于YOLOv5具有在模型训练过程中自适应重新计算并调整Anchor大小的能力,故本文使用k-means聚类算法对安全帽数据集重新进行聚类分析,在YOLOv5 的Head 模块网络结构的AnchorBoxes中增加一组专门针对于小目标的Anchor:(-[5,6,8,14,15,11]#4)。
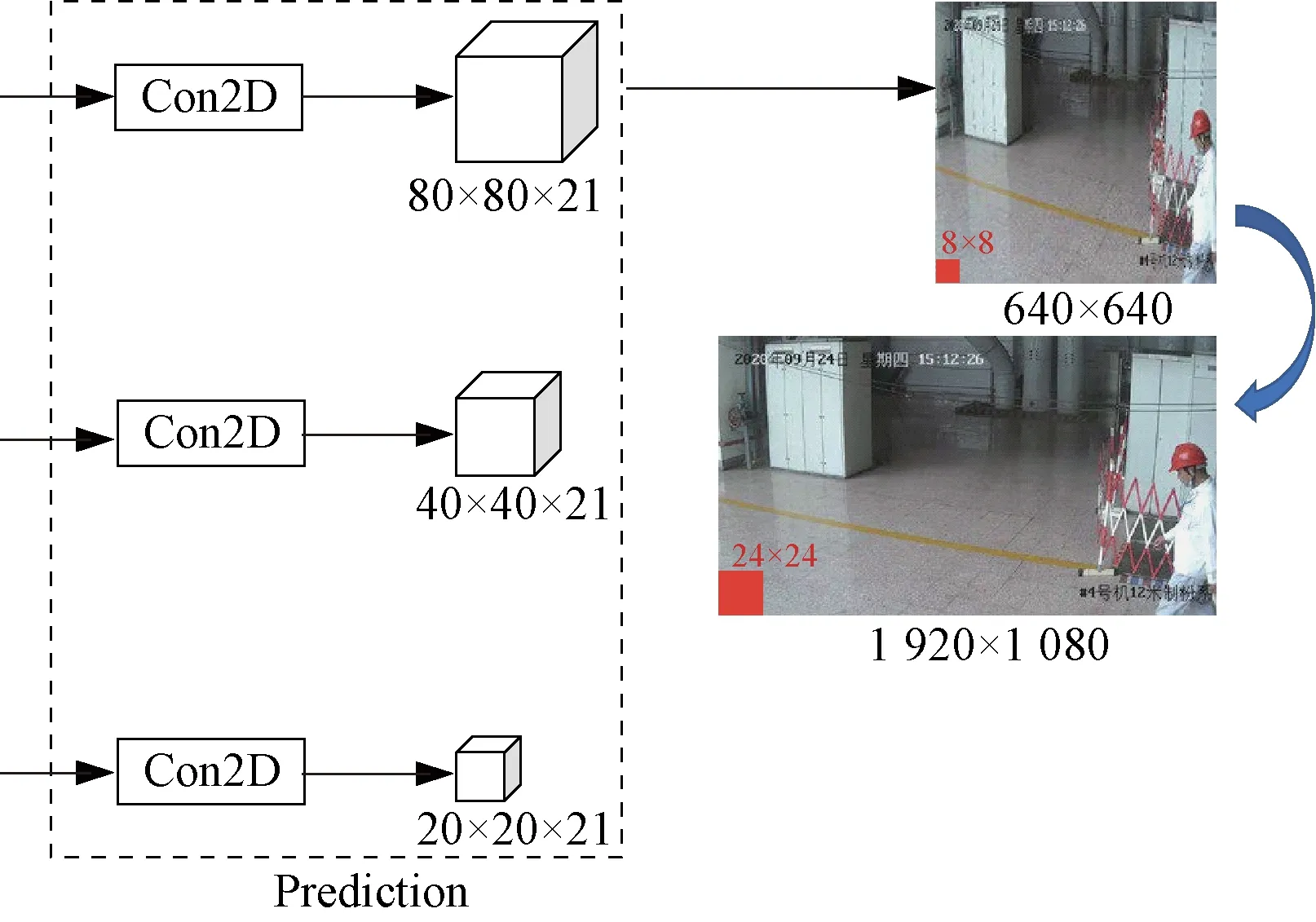
图3 YOLOv5 检测头Fig.3 YOLOv5 head module
1.3 多尺度特征提取
深度学习中,感受野指的是网络模型提取的特征图在原始输入图片中对应区域的大小。如图3 所示,本文构建的安全帽数据集中图片尺寸为1 920×1 080,以图片矩形长边1 920作为放缩标注,针对较小目标的检测头在安全帽图片上的感受野边长为1 920/640×8=24。也就是说,如果安全帽数据集图片中的目标区域面积小于242像素,YOLOv5网络进行相应的特征提取与学习就会非常困难。
卷积神经网络对图像进行特征提取的方式主要是上采样与下采样。如图4 所示,通过多次卷积上采样操作,卷积网络将提取到的特征图尺寸不断放大,生成逐渐抽象的特征。通过多次卷积下采样操作,对图像特征信息进行池化降维,避免过拟合。随着卷积神经网络层数的加深,所得到的感受野面积也在逐渐扩大。其中浅层网络卷积操作较少,映射于原图像的感受野面积较小,可以提取到更细粒度的特征信息,比如安全帽的形状、颜色等特征。而深层网络经过多次卷积下采样,映射于原图像的感受野面积越来越大,丢弃了许多细节特征,所提取到的特征信息也更加抽象。
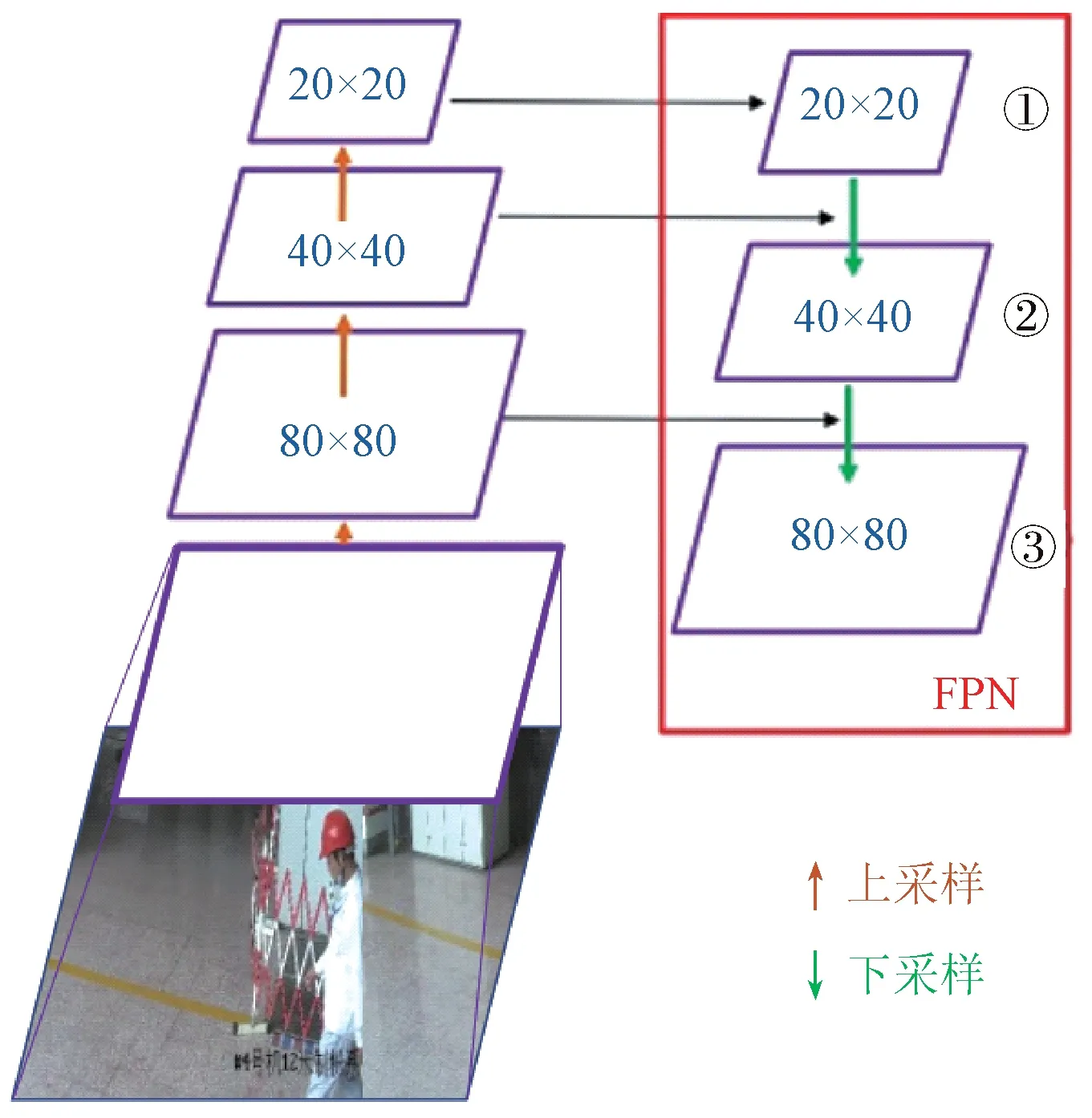
图4 YOLOv5感受野Fig.4 YOLOv5 receptive field
基于YOLOv5的小目标检测网络改进思路就是在输入图像中较小的目标对象区域尽可能多地提取到更完整的特征信息。本文考虑增加YOLOv5 的Head 模块中的上采样操作次数,扩大网络中的特征图尺寸,增加特征提取网络对输入图像进行多尺度的特征提取,并增加网络结构中的连接层,充分融合浅层特征信息与深层特征信息。改进前YOLOv5 的Head 模块网络结构层如图5所示。
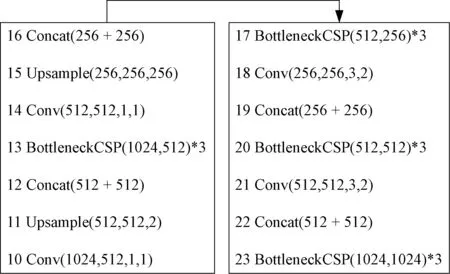
图5 改进前Head模块网络结构Fig.5 Head module network structure before improvement
改进后的YOLOv5的Head模块网络结构层如图6所示。在Head网络第17层BottleneckCSP 网络提取特征完成卷积操作之后,对提取到的特征图增加上采样操作,可以进一步扩大特征图的尺寸。在Head网络第20层将得到的包含浅层网络信息的特征图与YOLOv5的Backbone 模块中深层网络信息特征图进一步融合,以此获取更多的特征信息。在Head 网络的第31 层,即网络的预测输出层,为了与新增一组Anchor进行匹配,增加小目标检测层,共使用[21,24,27,30]4 组检测层进行计算。改进后的网络模型结构更加复杂,FLOPs计算量增加,受到GPU计算资源的限制,在模型训练过程中需要调整网络的batch-size,将YOLOv5 原始batch-size默认值做减半处理。

图6 改进后Head 模块网络结构Fig.6 Head module network structure after improvement
2 模型训练
2.1 安全帽目标检测数据集构建
本文构建数据集的视频来源于海康威视智能监控视频管理平台,感兴趣区域(Region of Interest,ROI)内的待检测目标对象为监控视频画面中的工作人员。为保证所构建的工业数据集能够最大程度真实反映实际生产作业情况,多次实地走访与现场调研,选取接近一年时间跨度获取监控视频,筛除画面模糊不清的模拟摄像头监控视频片段,选取数字摄像头监控视频流中画面清晰的视频片段,得到视频分辨率为1 080P(1 920×1 080)的原始视频。获取原始视频之后,本文设计了一种针对工业监控视频的关键帧提取算法的方式,筛选关键ROI 片段,完成视频切帧与关键帧保存,对得到的图片帧使用LabelImg 标注工具采用PASCAL VOC 格式进行标注。构建的数据集命名为安全帽目标检测数据集(HUST Safety Helmet Object Detection Dataset,HUST-SHOD),其中根据检测任务,HUSTSHOD 可细分为安全帽佩戴状态检测数据集(HUST Safety Helmet Wear Dataset,HUST-SHWD)与安全帽佩戴颜色检测数据集(HUST Safety Helmet Wear Dataset of Color,HUST-SHWD_Color)。
2.2 安全帽目标检测数据集划分
对安全帽目标检测数据集进行划分,训练集:验证集:测试集比例设定为8∶1∶1。对数据集中的15 774个实例进行划分,HUST-SHWD 中训练集包含6 225个正样本实例,4 419 个负样本实例,验证集与测试集数据量相同,都包含784 个正样本实例与493 个负样本实例。HUST-SHWD_Color中训练集包含3 395个佩戴蓝色安全帽实例,1 443个佩戴黄色安全帽实例,1 001个佩戴红色安全帽实例,436个佩戴白色安全帽实例,以及4 279 个负样本实例。验证集与测试集数据量相同,都包含430 个佩戴蓝色安全帽实例,178 个佩戴黄色安全帽实例,100个佩戴红色安全帽实例,51个佩戴白色安全帽实例,以及563个负样本实例。
2.3 数据增强技术
人体头部区域面积较小,不易被遮挡,故采用Mosaic 和MixUp 数据增强技术对训练过程中一个Batch图片进行不同程度的混合,增强模型的鲁棒性。
1)Mosaic:文献[17]提出在模型训练过程中对于获取到的同一个Batch 中的4 张不同图片按照一定比例混合成为一个全新的图片帧。如图7 所示,在训练过程中使用Mosaic 数据增强,可以使得模型学习如何在非正常情况下识别更小比例的目标,同时它还可以使模型在合成图片帧的不同区域分别识别定位不同类别的目标。

图7 Mosaic数据增强示意图Fig.7 Schematic diagram of Mosaic data enhancement
2)Mixup:文献[19]提出,在模型训练过程中生成虚拟实例。随机挑选两张图片并按照一定比例(α:β)进行混合得到全新图片,模型对新图片分类结果的概率遵循α:β的混合比例,改变模型在训练过程中对于单个实例的线性分类结果,决策边界更为平滑,泛化能力更强。基于MixUp 的虚拟实例构建公式,其中xi,xj是原始图片输入得到的向量,yi,yj是经过一次标签重新混合编码得到的输出向量。
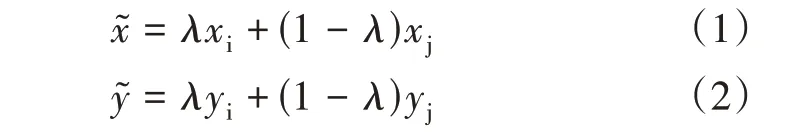
Mosaic 与Mixup 数据增强方式优点明显,其本质思想都是通过在模型训练过程中通过混合不同的图片或实例生成全新样本来提高模型的分类与泛化能力。并且混合后不会生成与原始数据无关的干扰信息,模型在学习到更多的实例分类结果,极大地提高训练效率。
3实验结果与分析
安全帽目标检测实验基于HUST-SHWD 与HUST-SHWD_Color 数 据 集,选 取 文 献[20]中XuanyuWang 等人改进后的YOLOv3算法、文献[21]中LeeCH 等人所使用的YOLOv4 算法、原始YOLOv5 算法、优化后的YOLOv5 模型融合算法与改进后的YOLOv5-SOD算法对比实验。
3.1 安全帽佩戴检测实验
安全帽佩戴检测实验基于HUST-SHWD,对工作人员头部是否佩戴安全帽的情况进行检测。表1列出使用不同目标检测算法对安全帽佩戴状态的检测结果,采用准确率(P)、召回率(Recall)、mAP@.5 与mAP@.5:.95 4 种指标对算法进行评估。本文提出的YOLOv5 模型融合算法,使用深度神经网络模型替换YOLOv5的Backbone 网络,以ResNet-50与EfficientNet作为其Backbone 网络的模型mAP@.5 值均得到提升,但前者mAP@.5:.95 值低于原YOLOv5 算法。使用轻量化网络模型替换,与优化前的mAP@.5 值相比没有得到显著提升。YOLOv5+EfficientNet 模型融合算法mAP@. 5=0.985,本文改进后的YOLOv5 算法mAP@.5:.95=0.766,本文改进优化的两种算法取得最优效果。
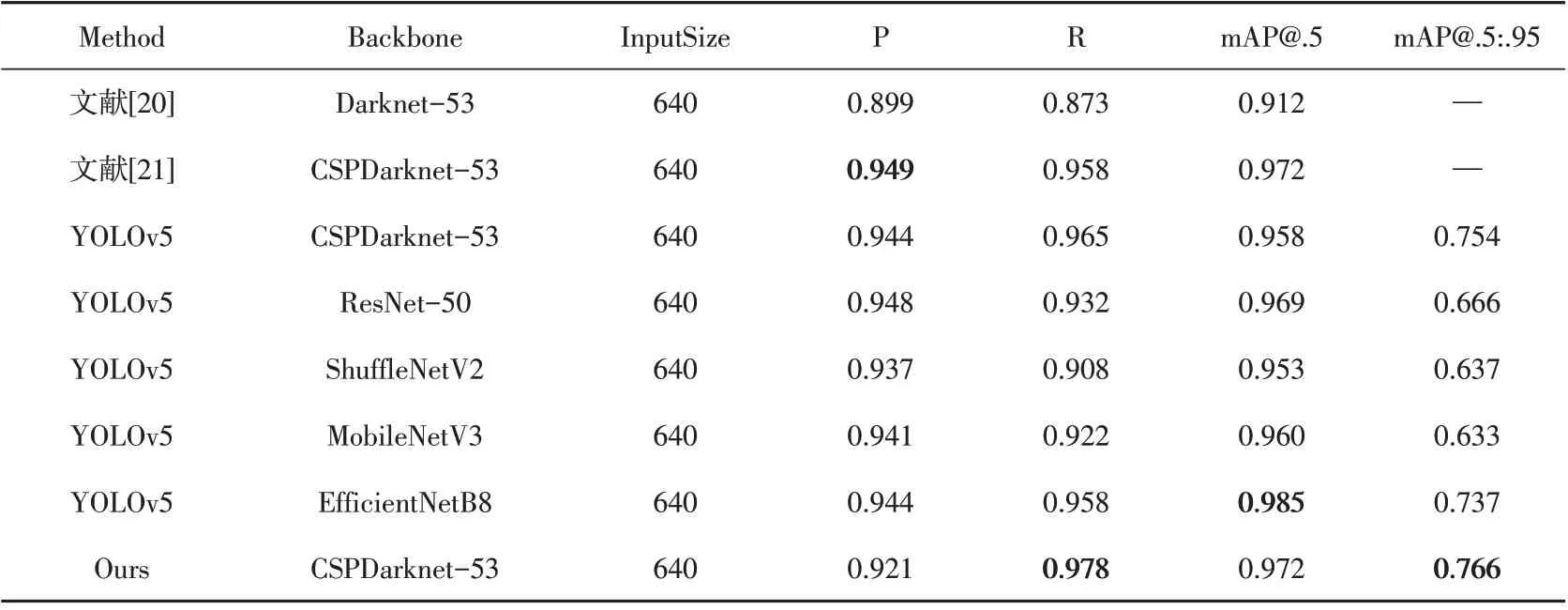
表1 安全帽佩戴检测对比实验结果Table1 Results of comparative tests of helmet wearing detection
3.2 安全帽佩戴颜色检测实验
安全帽佩戴颜色检测实验基于HUST-SHWD_Color,对工作人员头部佩戴安全帽颜色的情况进行检测。表2列出使用不同目标检测算法对安全帽佩戴状态的检测结果。本文提出的YOLOv5模型融合算法,使用深度神经网络模型替换YOLOv5的Backbone网络,以EfficientNet 作为其Backbone 网络模型mAP@.5 值与mAP@.5:.95 均 得 到 提 升,但 以ResNet-50 作 为 其Backbone 的mAP@.5 值 与mAP@.5:.95 值 均 低 于 原YOLOv5算法。使用轻量化网络模型替换,与优化前的mAP@.5值与mAP@.5:.95值相比均有不同程度的下降。改进后的YOLOv5 算法mAP@.5=0.981,mAP@.5:.95=0.775。本文改进算法检测准确率取得提升。
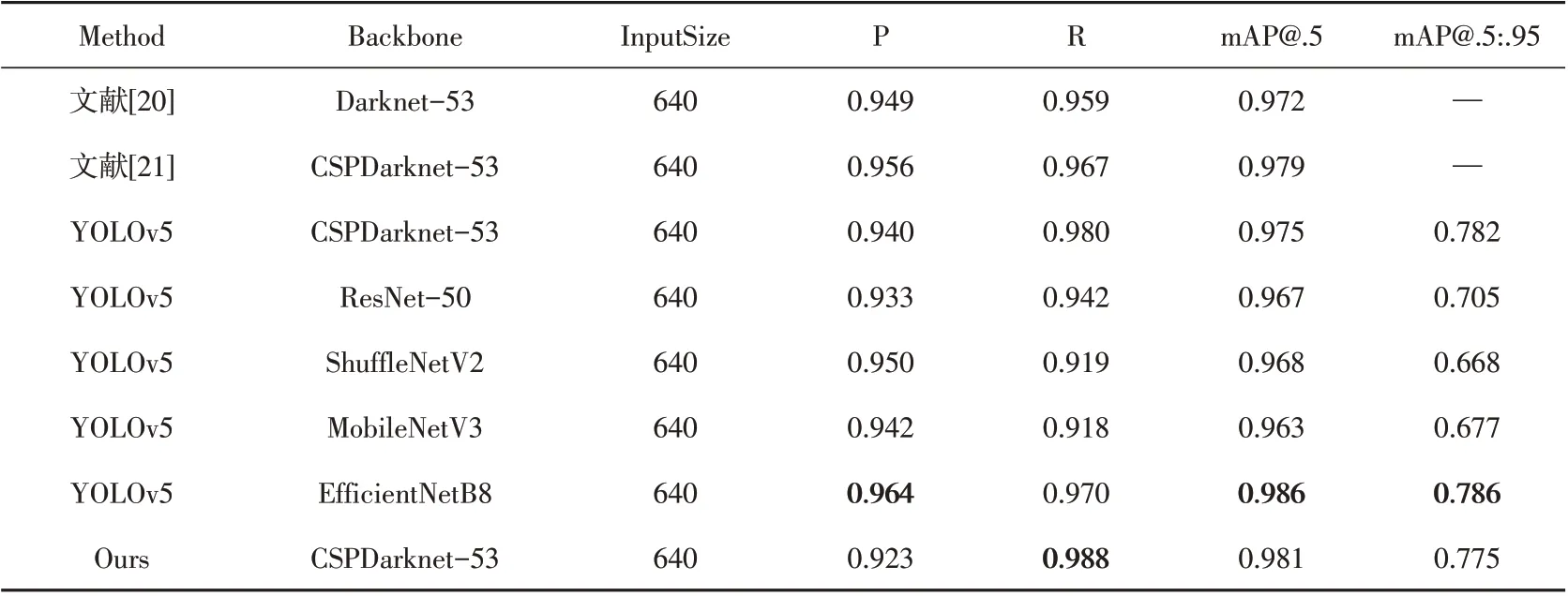
表2 安全帽颜色检测对比实验结果Table2 Results of comparative tests of helmet color detection
对比改进前后的算法对于实际样例的检测效果,如图8所示,改进前的YOLOv5算法无法检测到工业生产作业区域复杂背景中被遮挡的困难目标与受到光照变化影响的困难目标,以及远景图像中的小目标。本文改进的YOLOv5算法在工业环境复杂背景中具有小目标鲁棒性、遮挡鲁棒性、光照鲁棒性等诸多优点,优于原始的YOLOv5算法。
4 结语
本文选用基于YOLOv5的目标检测算法完成安全帽佩戴检测任务,并构建了安全帽目标检测数据集。安全帽目标检测数据集由HUST-SHWD 与HUSTSHWD_Color 两类构成。本文构建的5 类数据集涵盖了工业实际生产中各种情况。总数据标注量为图片29 865张,实例54 603个。在原有网络结构基础上,通过基于k-means聚类算法对安全帽数据集聚类得到的Anchor 数目与大小进行了调整,增加了自顶向下过程中的上采样,对提取到的特征图进一步扩大并与浅层特征信息充分融合,增强了模型多尺度特征提取能力,提高了YOLOv5算法对于小目标等困难目标的检测准确率。与改进前的YOLOv5 算法进行对比实验,从检测准确率、速度、模型体量等多方面综合考虑,选择改进后的YOLOv5 算法作为安全帽检测算法,实现算法的工程落地。
