地质采矿条件对铁路路基沉陷预测影响研究
2022-09-22邓念东刘东海
丁 一,邓念东,姚 婷,2,刘东海,2,尚 慧
(1.西安科技大学 地质与环境学院,陕西 西安 710054;2.重庆一零七市政建设工程有限公司,重庆 401120)
0 引 言
山西常村煤矿井田范围内铁路专用线压煤量达3 500万t,占常村煤矿可开采储量的4.7%,根据国家产业政策,铁路下压覆煤炭资源应遵循煤炭资源优化利用,保护生态环境和企业经济与社会效益,保护对象安全的总原则,凡技术上可行、经济上合理,丢弃后带来用不可采或其他严重后果的,必须进行回采[1]。在充分利用资源的同时要保证铁路的安全运行,开采沉陷预测显得尤为重要。概率积分法理论成熟,易于计算机实现,是我国目前运用最成熟、最广泛的预测方法[2-3],而预计参数选取的准确与否直接关系到地表移动和变形预计的精度[4-5]。查剑峰等[6]提出利用遗传算法反演概率积分参数,并对该方法的准确性和可靠性进行了研究。李培现等[7]提出了运用地表空间移动矢量反演概率积分法参数的遗传算法模型,为多工作面及非矩形参数反演的工程应用问题提供了新的计算方法和解决思路。王磊等[8]基于D-InSAR技术成果和遗传算法理论,构建了融合两者的概率积分预计全参数反演模型,并编制了求参软件。沈震等[9]利用 Matlab软件,运用最小二乘法拟合出观测点变形数据,进而对概率积分预计参数进行解算,并开发了集开采沉陷预计和反演为一体的可视化开采沉陷预计系统。杨靖宇等提出利用一种基于BFGS算法的概率积分模型进行参数反演,结果表明该方法相较于传统优化算法和智能优化算法具有一定的可行性和优越性。研究表明,概率积分预计参数受到覆岩岩性、结构、开采厚度、开采深度、开采方法、采动程度、煤层倾角、地质构造、地形地貌等许多地质采矿因素的影响[11-15],是地质采矿条件对开采沉陷的综合反映。然而我国复杂的地质环境决定了不同地区不同矿区的地质采矿条件存在很大的差异,不可盲目参考,因此,从地质采矿条件的角度出发对概率积分预计参数进行解算,并将其运用于铁路路基的开采沉陷预测,为铁路的变形预测提供理论基础,为后续工作面的开采和铁路的变形防治措施提供理论依据,从而实现煤炭开采与铁路运行同时进行的最佳协调状态,保证铁路安全运行的前提下,因地制宜地在铁路下采煤,研究成果对于煤矿的发展以及促进资源高效利用具有重要的理论意义和现实意义。
1 研究区概况
郭庄煤矿和常村煤矿同属山西潞安集团,郭庄煤矿铁路专用线从常村煤矿井田范围穿过,为促进煤炭资源综合开发和合理利用,常村煤矿开采计划中未留设保护煤柱。影响郭庄煤矿铁路专用线运营的回采工作面总共7个,对铁路的影响范围为K0+634~K6+145,工作面与铁路位置关系如图1所示。其中S3-13工作面已回采完毕,2105工作面正在回采,其他均未开采。S3-13工作面的开采导致本段工作面上方铁路路基最大下沉量达4 m以上,致使郭庄煤矿铁路专用线停止运营。为达到工作面开采同时铁路正常运营的目的,郭庄煤矿欲通过对开采沉陷进行预测,从而控制铁路变形来实现此目标。
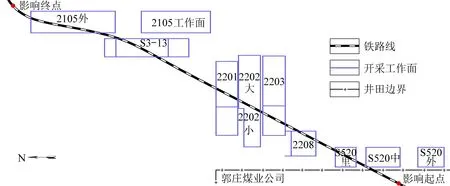
图1 工作面与铁路位置关系Fig.1 Relationship between working surface and railway position
常村煤矿位于长治盆地西部,全区广为第四系黄土沉积掩盖,地形平缓,属温带半干燥大陆性气候,四季分明,地质构造形态主要为轴向近南北的相互平行的褶曲构造,井田内各含水层之间的水力联系较弱。常村煤矿主采3号煤层,位于山西组的中下部,煤层厚度为0.50~7.33 m,平均厚度6.04 m,结构简单~复杂,上覆基岩以砂岩和泥岩为主,松散层厚度0~110 m。
2 基于地质采矿条件的预计参数求取
运用概率积分法对研究区内工作面的开采沉陷进行预计,概率积分预计参数包括:下沉系数q,主要影响角正切tanβ,水平移动系数b,开采影响传播角θ,拐点偏移距s(一般用s/H0表示,H0为采深)。
2.1 地质采矿因素选取
在国内外研究现状的基础上,遵循科学性、代表性和易操作性的原则,结合研究区自身特点[16],选取了影响概率积分预计参数的地质采矿因素,包括:煤层倾角α、松散层厚度h、覆岩综合硬度Q、平均采深H0、采厚M、工作面推进速度C,采动程度n(采动程度n分2个方向,n1为倾向采动程度,n3为走向采动程度。)以及工作面倾向长度D1和走向长度D3。
研究区各工作面的上述地质采矿条件参数见表1。
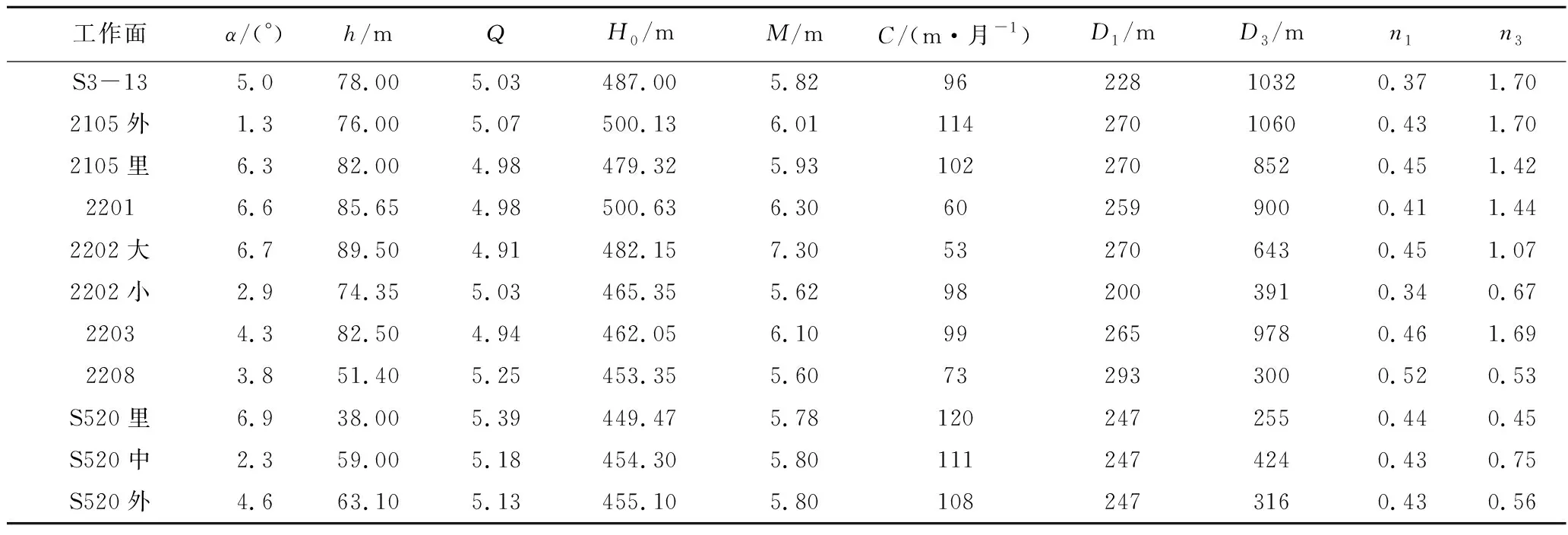
表1 研究区工作面地质采矿条件参数
2.2 GA-BP神经网络模型构建
概率积分预计参数与地质采矿条件之间存在复杂的非线性关系,很难利用一个确定的函数模型去进行准确的描述,BP神经网络具有能够以任意精度逼近任何非线性函数的特性,因此,采用BP神经网络算法建立地质采矿条件与概率积分参数之间的非线性关系。但BP神经网络易陷入局部最优解,且收敛速度慢,预测精度也有待提高,为此,运用遗传算法(GA)对BP神经网络的初始权值和阈值进行优化,使BP神经网络能够得到精确的预测输出。
遗传算法优化BP神经网络包含BP神经网络结构确定、遗传算法优化和BP网络预测输出3部分。首先,根据样本数据的输入输出确定BP网络的结构及遗传算法个体的长度;其次,个体基于适应度函数进行选择、交叉、变异操作寻找最优个体适应度值,并将其作为BP网络的初始权值和阈值进行运算;最后,网络经训练后输出预测函数[17-18]。GA-BP神经网络的算法流程如图2所示。
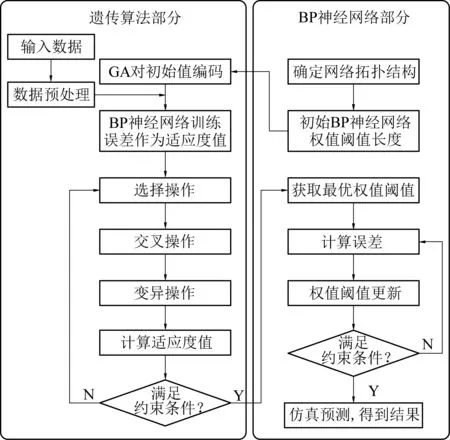
图2 GA-BP算法流程Fig.2 GA-BP algorithm flow
模型建立过程中,输入变量原为选取的地质采矿因素,为简化模型,利用主成分分析法提取出5个主成分作为输入变量,概率积分预计参数作为输出变量,为提高预测精度,采用多输入层单一输出层的网络结构,即将5个概率积分参数分别作为单一输出层,建立5个独立模型,每个模型的输入层节点数为5,输出层节点数为1。收集了76组观测数据作为神经网络的训练和测试样本,其中前70组数据是从文献[19]中的地表移动观测站资料筛选得来,将其作为训练数据,后6组为研究区所在潞安矿区的实测数据,用于测试网络性能,试验数据见表2。
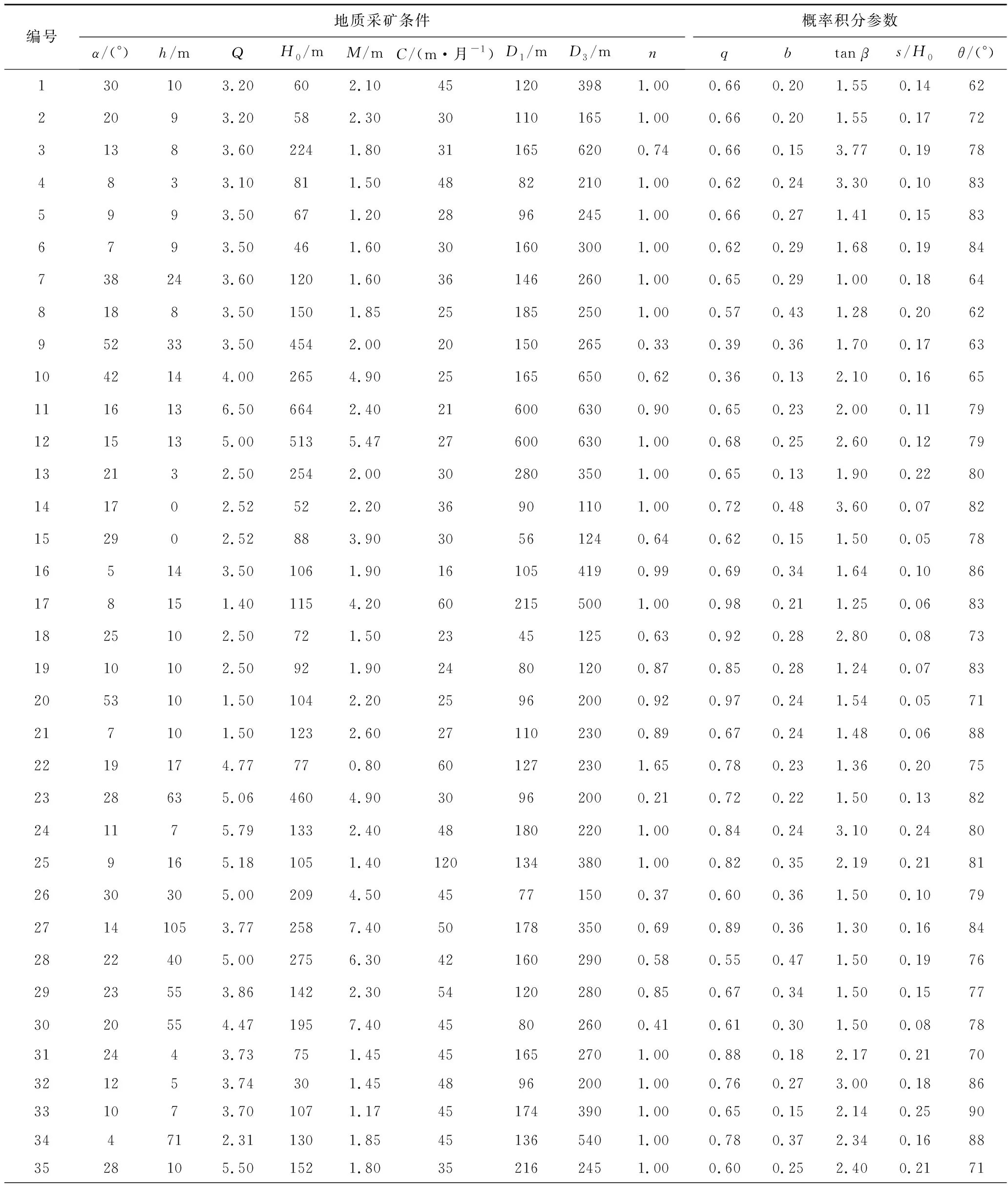
表2 试验数据
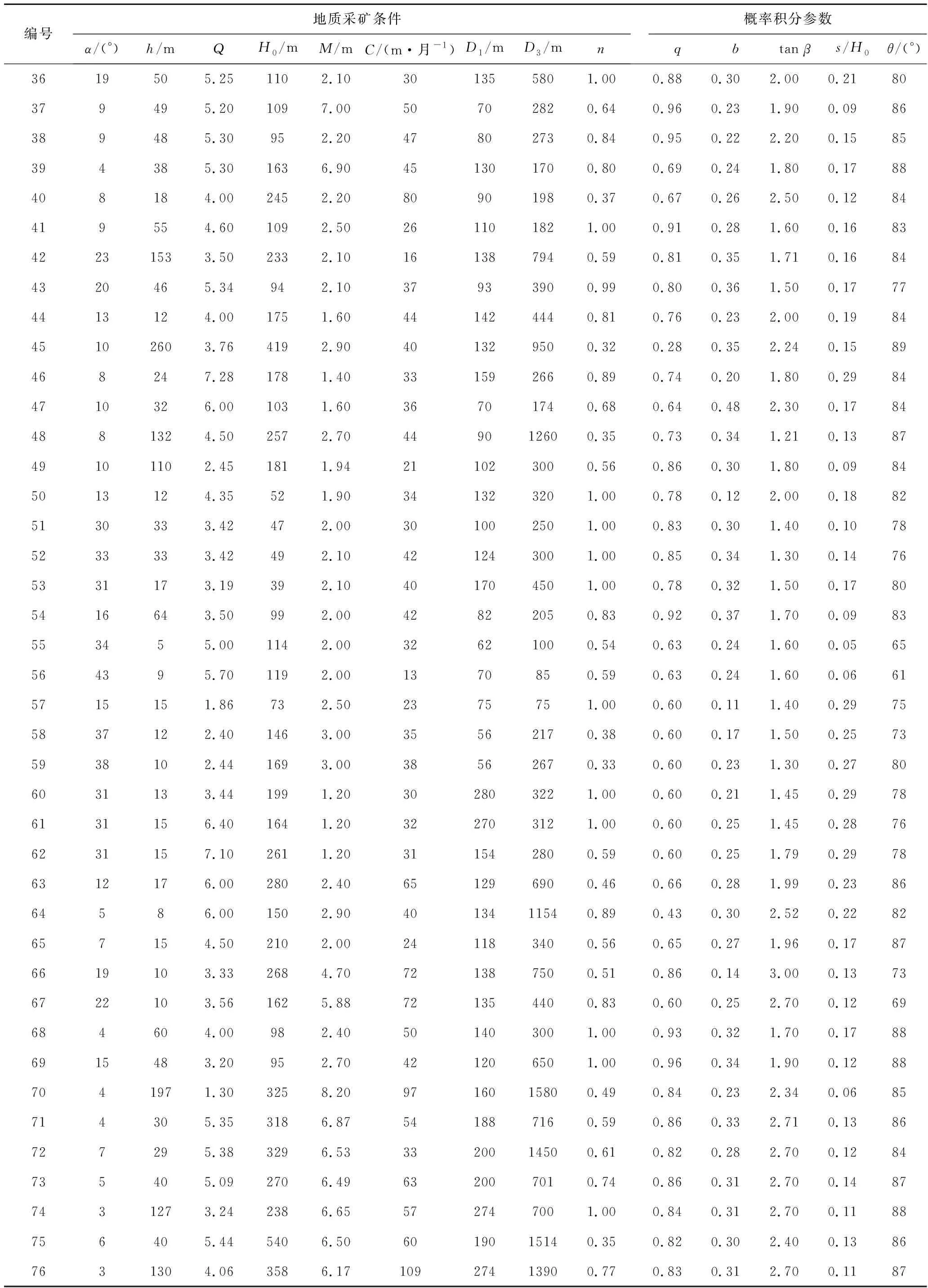
续表
利用Matlab对模型进行反复的训练学习,各模型的参数设置见表3。
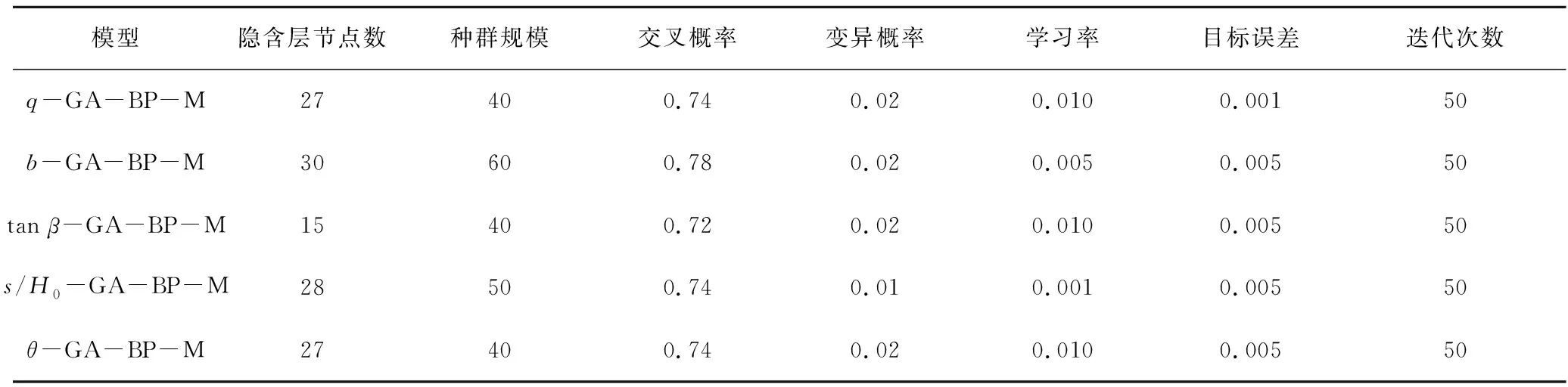
表3 GA-BP神经网络参数设置
2.3 模型精度检验
对模型经过不断的学习训练之后,分别对5个概率积分参数进行了预测输出,现从网络的误差分析、对数据的拟合度以及测试结果对模型精度进行检验。
由图3可知,GA-BP神经网络数据训练集在训练5次时开始收敛,最佳验证性能为0.005。由表4和图4可知,6个测试样本中实测值与预测值的最大相对误差为2.81%,最小相对误差对1.49%,平均相对误差仅为2.06%,误差较小;表明该模型收敛速度快,预测精度较高。
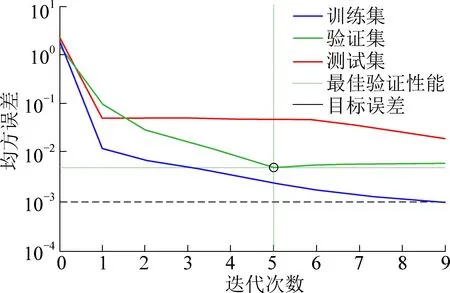
图3 下沉系数预计模型均方误差曲线Fig.3 Mean square error curve of sinking coefficient prediction model
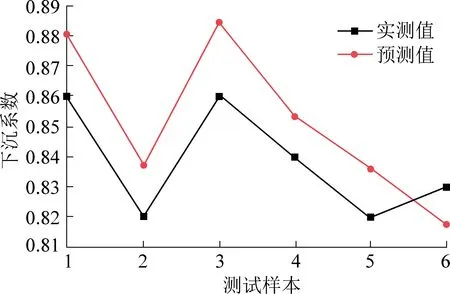
图4 下沉系数预测与实测对比曲线Fig.4 Comparison curve between prediction and actual measurement of sinking coefficient
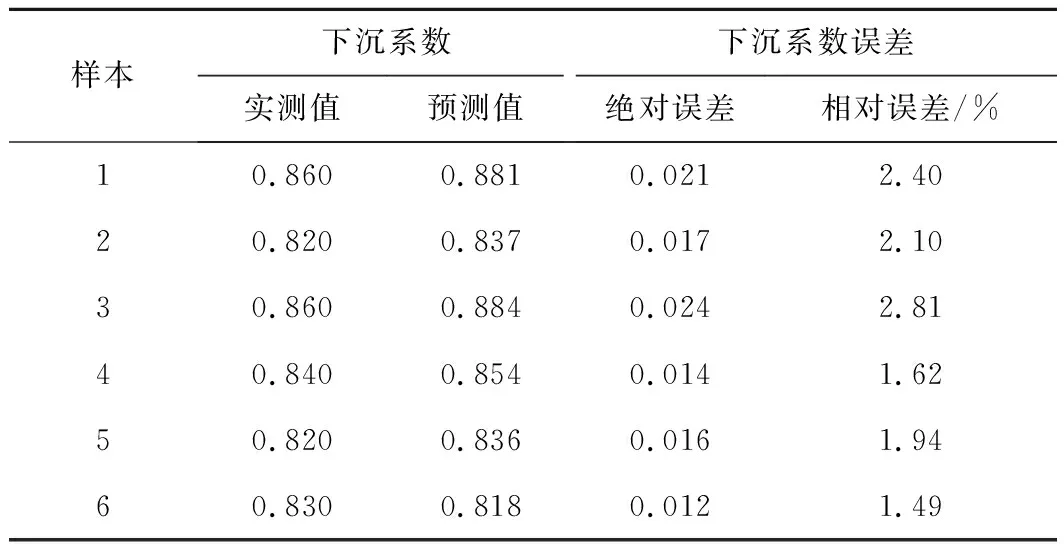
表4 下沉系数预测与实测对比结果
图5中利用相关系数R来反映样本数据拟合效果,R的绝对值介于0~1,R越接近1,表示实测值与预测值的相关性越强,拟合程度越好;反之,R越接近于0,实测值与预测值的相关性就越弱,拟合程度越差。下沉系数预计模型中训练集的相关系数为0.886,验证集的相关系数为0.806,测试集的相关系数为0.868,全部数据的相关系数为0.858,相关系数均较高,对数据的拟合效果较好。同理,对其余4个模型的精度均进行了检验,各个模型的误差分析结果见表5。
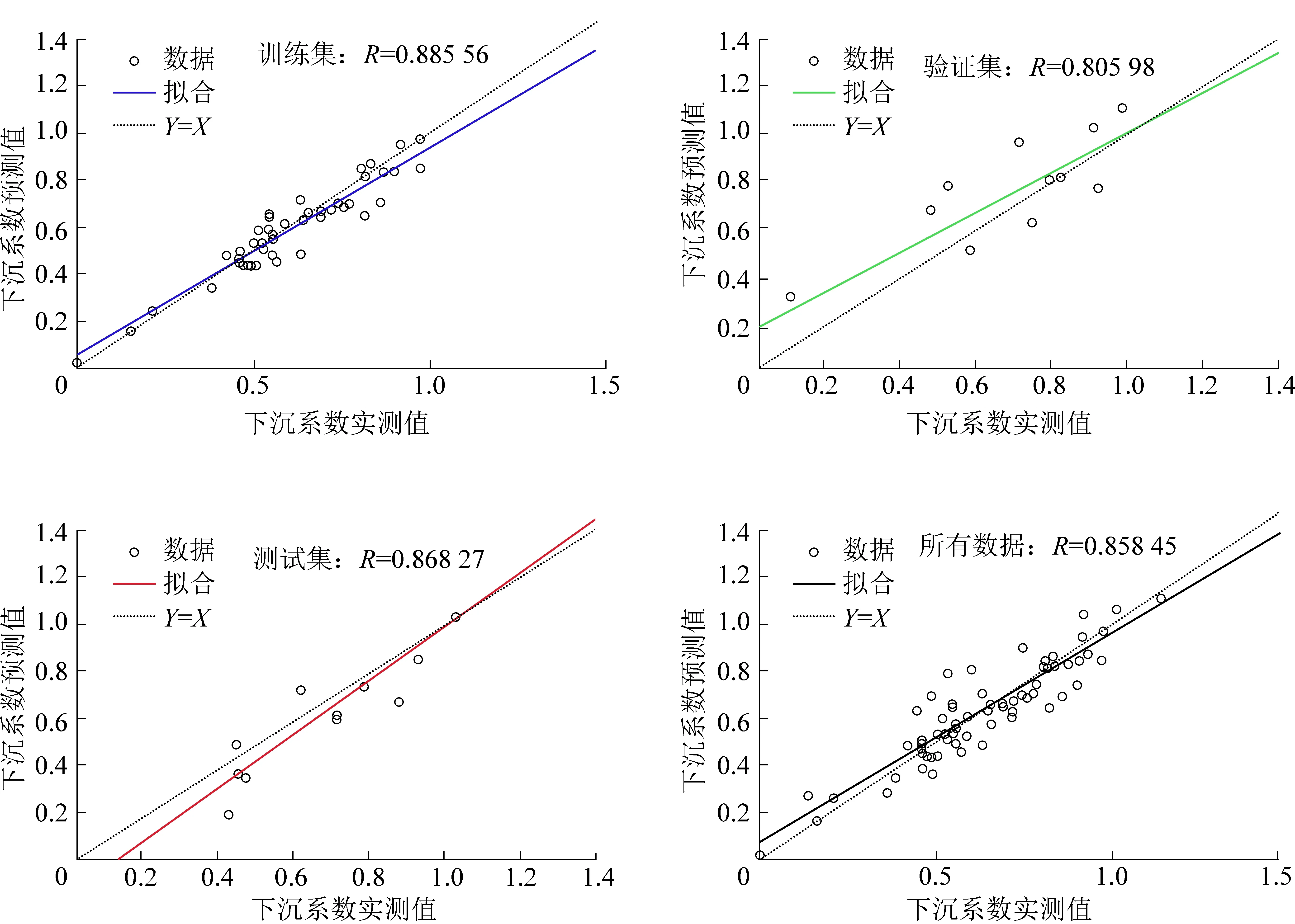
图5 下沉系数预计模型回归状态曲线Fig.5 Sinking coefficient prediction model regression state curve
由表5可以看出各模型的最佳验证性能均保持在10-3级别,平均相对误差均小于3%,且样本数据拟合的相关系数均大于0.8。同时采用威尔莫特一致性指数(IWA)来评价GA-BP神经网络的泛化性能,当IWA>0.6时模型才有实际的预测价值[20],由表中可知各模型的IWA均大于0.8。以上检验结果表明模型的预测精度均较高,且具有良好的预测能力,能够达到开采沉陷预计的精度要求,可利用该模型进行预测。
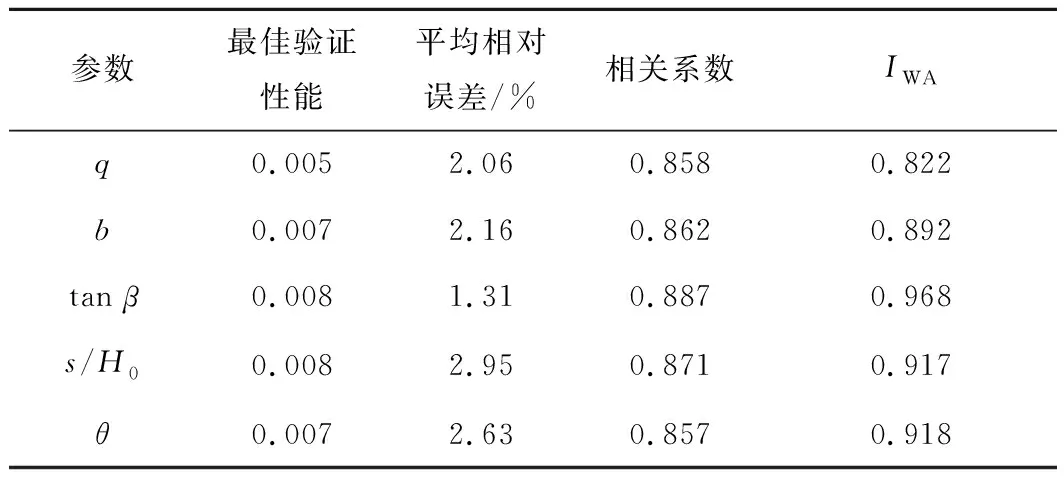
表5 预计参数神经网络模型误差分析
2.4 预计参数求取
根据研究区各工作面地质采矿条件参数,运用以上建立的5个GA-BP神经网络模型,求得研究区内各工作面开采沉陷的概率积分预计参数见表6。
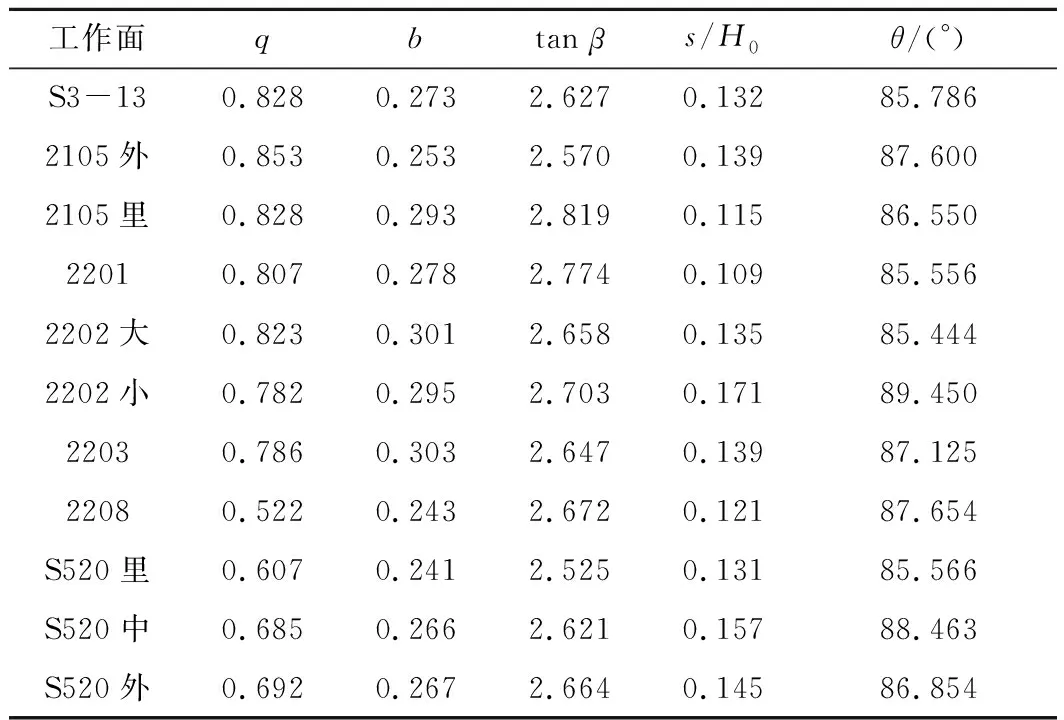
表6 研究区工作面开采沉陷概率积分预计参数
3 铁路路基沉陷预测
根据以上得到的研究区各工作面开采沉陷预计参数,运用概率积分法对各工作面开采引起的地表沉降变形进行了稳态预计,得到了地表最大下沉值,并绘制了地表下沉等值线和下沉曲线。
3.1 S3-13工作面开采沉陷实测与预测对比
S3-13工作面开采范围内沿铁路专线布置有监测点(图6),并且进行了沉降监测,获得了部分监测数据,因此,以下将S3-13工作面的预测结果与实测数据进行对比(表7和图7),确保预测结果的准确性。
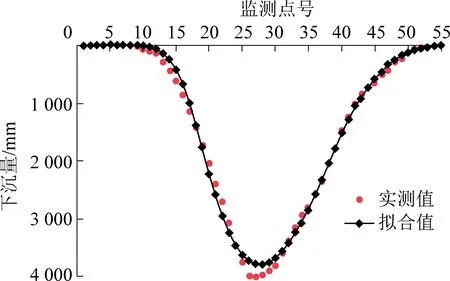
图7 S3-13工作面实测与预测下沉曲线对比Fig.7 Comparison of measured and predicted subsidence curves of S3-13 working face
由表7可以看出,实测值与预测值的误差较小,经计算,两者的差值平方和[VV]为6.21×105,中误差为104.38 mm,为观测点最大下沉值的2.60%;由图6实测与预测下沉曲线的对比可知,曲线的拟合效果较好,说明本文利用概率积分法对研究区工作面开采沉陷所做的预测精度较高,预测结果具有一定的可靠性,同时也说明上述通过GA-BP神经网络计算得到的概率积分预计参数是可靠的,可以用来对其余工作面进行沉陷预测。
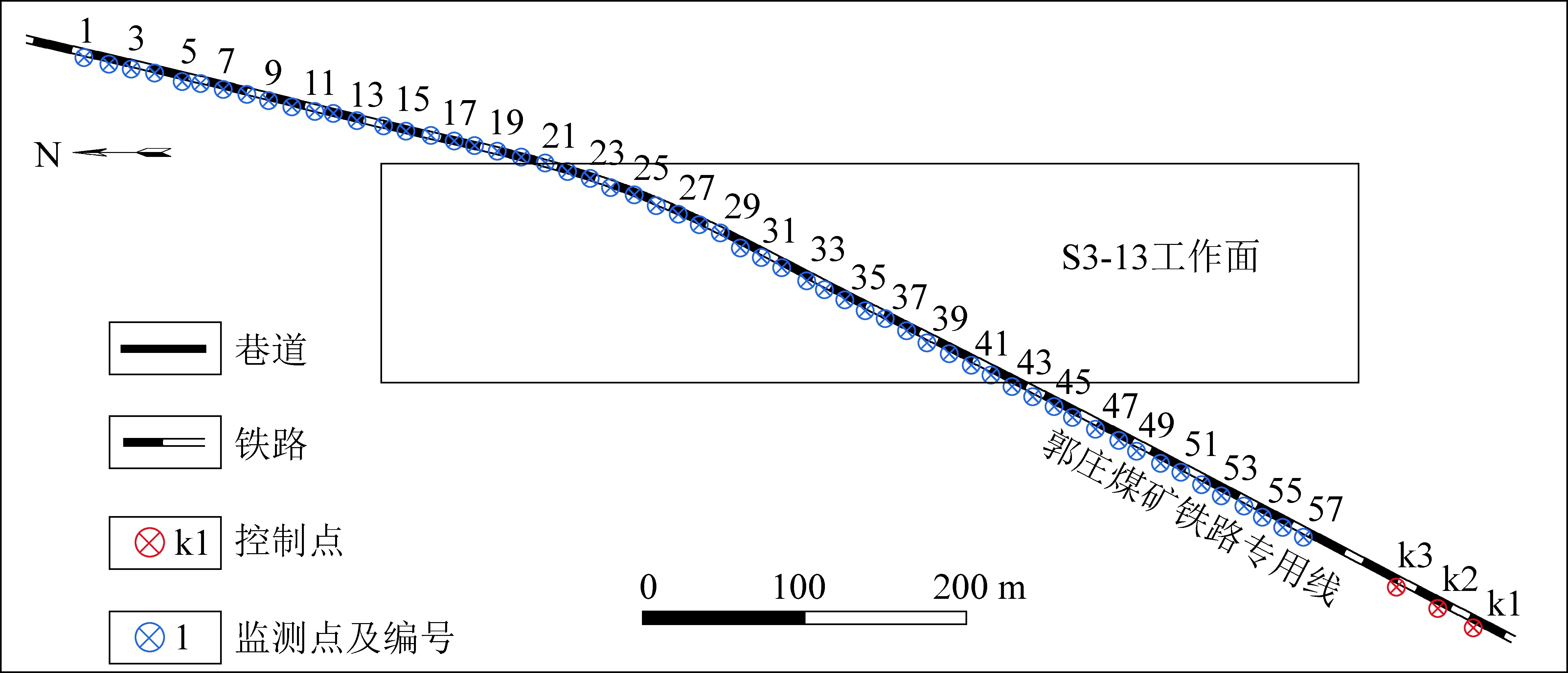
图6 监测点布置Fig.6 Monitoring site layout
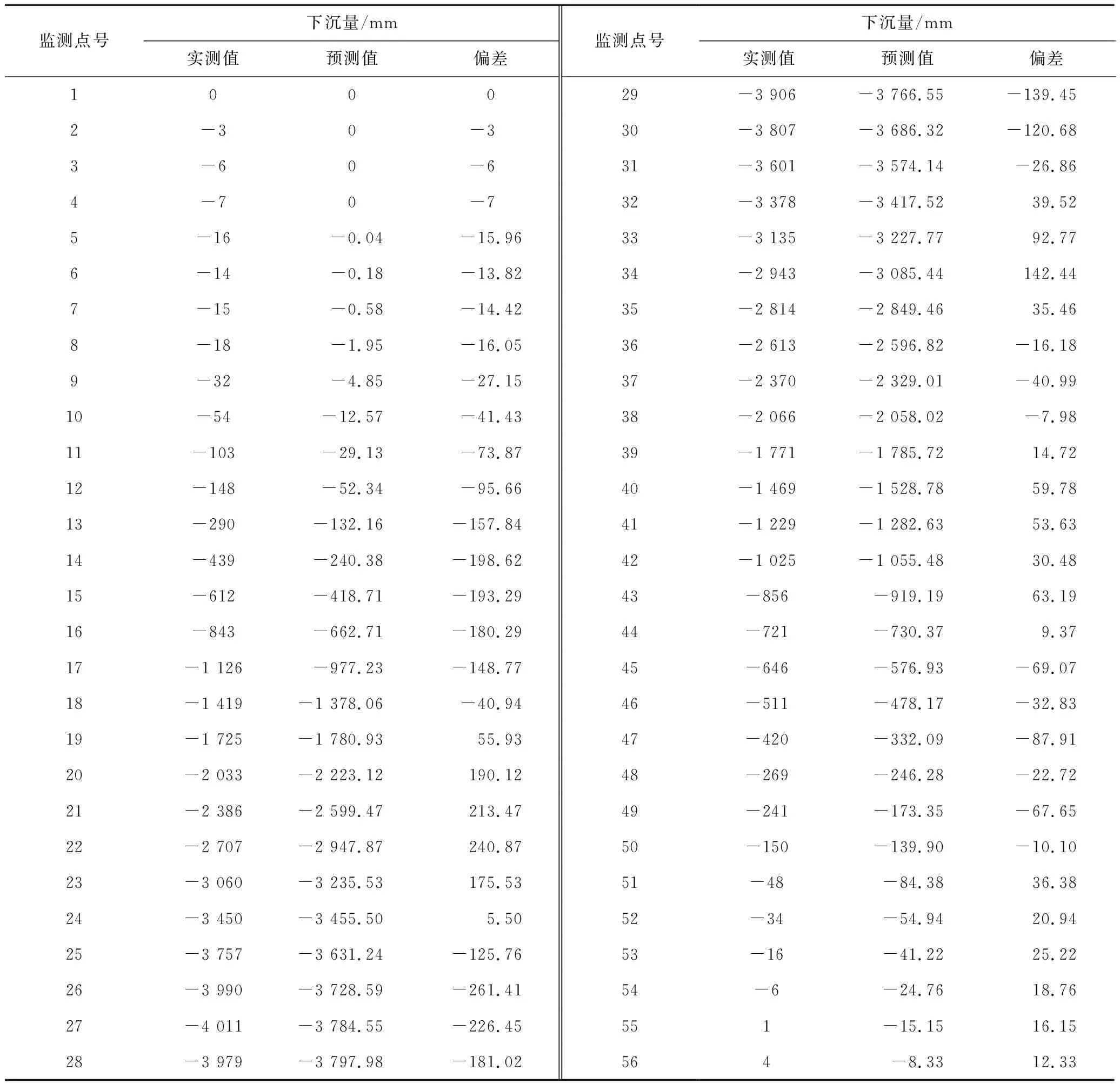
表7 S3-13工作面下沉实测与预测值对比
3.2 铁路路基沉陷预测
基于上述分析结果,对研究区所有工作面开采后的沉陷情况进行了预测,得到铁路沿线的下沉等值线如图7所示。依据《建筑物、水体、铁路及主要井巷煤柱留设与压煤开采规范》中下沉值为10 mm时移动期开始的规定,将下沉值为10 mm的等值线作为下沉边界。
由图8可以看出,研究区内所有工作面开采完毕后,区内会形成2块比较大的沉降,铁路专线在其影响范围之内,沿铁路线切剖面得到铁路沿线的下沉曲线如图9所示。
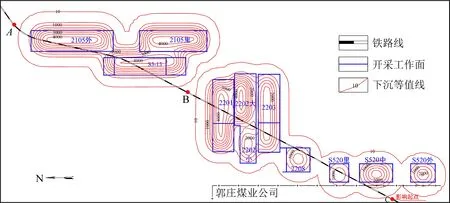
图8 铁路路基下沉等值线图Fig.8 Contour map of railway subgrade subsidence
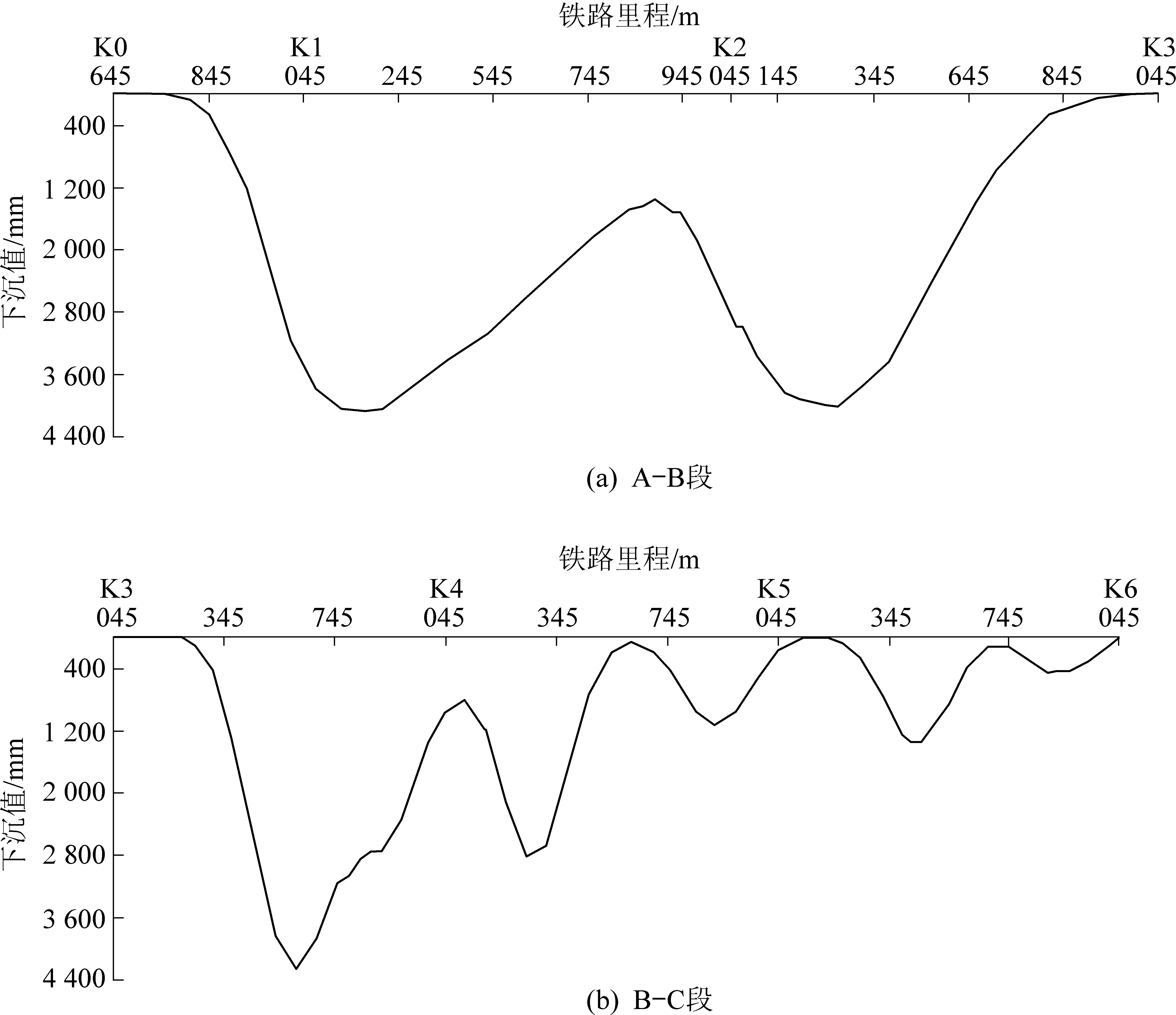
图9 铁路路基下沉曲线Fig.9 Railway subgrade subsidence curve
由图9可以看出,研究区内工作面开采对铁路造成的影响很大,预测铁路路基最大下沉值达到4 261 mm,其中K0+745~K3+045以及K3+245~K4+045两个路段将会形成最大值大于4 000 mm的下沉盆地,铁路将会发生严重的变形破坏,丧失其正常运营能力。因此,为保证工作面开采与铁路运输同时正常进行,还需对其进行动态预测以及实时监测,通过及时的起道、拨道、串轨等一系列维护方法将铁路线路病害规模控制在允许的限界范围内,从而实现边开采、边维修、边运营的最终目的。
4 结 论
1)在国内外研究现状的基础上,结合矿区自身特点,选取出9个地质采矿因素作为输入变量,概率积分法的5个预计参数分别作为输出变量,建立了地质采矿条件与概率积分预计参数之间5个独立的GA-BP神经网络模型,并将收集的76组数据进行主成分分析后应用于模型的训练和测试。
2)从网络的误差分析、对数据的拟合度、测试结果以及泛化性能4个方面对模型的精度及可靠度分别进行了检验,结果表明网络的收敛速度均较快,模型的平均相对误差均小于3%,对数据的拟合程度均大于0.8,泛化性能指数均在0.8以上,说明模型的预测精度均较高,能够达到开采沉陷预计的精度要求,且具有良好的预测能力。
3)根据研究区工作面的地质采矿条件,运用GA-BP神经网络模型求得了各工作面开采沉陷的概率积分预计参数,并对S3-13工作面开采沉陷进行了预计,将预测与实测数据进行对比,发现实测与预测的误差较小,两者的差值平方和为6.21×105,中误差为104.38 mm,为观测点最大下沉值的2.60%,表明预测结果精度较高,同时也说明得到的概率积分预计参数具有一定的可靠性。
4)对研究区所有工作面开采完毕后的地表沉陷情况进行了预测,得到了铁路路基的下沉等值线及下沉曲线,预计铁路沿线最大下沉值达4 261 mm,并有两个路段将会形成大于4 000 mm的下沉盆地,结果表明工作面开采将会对铁路造成严重的破坏,因此应提前做好监测预测以及防治工作。
