注意力叠加与时序特征融合的目标检测方法
2022-09-15吴雨泽聂卓赟周长新
吴雨泽, 聂卓赟, 周长新
(华侨大学 信息科学与工程学院, 福建 厦门 361021)
在先进驾驶辅助系统与自动驾驶技术中,图像视频处理是重要的一环,通过机器视觉对行人、车辆等交通环境进行目标检测[1],以确保驾驶安全.然而,实际行车环境的复杂性(光照、雨雪天气、道路杂物、道路拥挤等)常导致检测目标被遮挡,从而引起安全隐患,特别是在高速行驶下的目标丢失极具危险性.因此,研究适用于短暂目标遮挡的目标检测算法具有重要意义.
近年来, 随着深度学习的发展, 目标检测算法取得了很大的突破,如两阶段的FasterR-CNN[2-4]系列、一阶段的SSD系列[5-9]和YOLO系列[10-13].特别是2020年Facebook AI提出直接将transformer架构适配到视觉领域的端到端目标检测(DETR)网络[14],将注意力机制在图像中的应用带到了台前,并取得了前所未有的检测精度.国内商汤科技的也进一步肯定了注意力机制的作用[15-17].
目前,大多数应用场景是以视频作为信息的载体[19],除了常规视觉信息外,视频还提供了额外的时间维度信息.针对视频进行目标检测,通常可以进行两类识别计算:一类是对每一帧进行目标检测;另一类是利用时间维度信息,将被检测的目标物跨帧链接成轨迹[18-25],并利用生成的轨迹进行下次目标状态预测和跟踪.在检测任务中,为充分利用时间维度信息,本文将检测与跟踪集成于一体,以DETR网络为主干,通过时间序列信息增强目标检测的效果.
1 融合上下文信息的增强型目标检测网络

算法1:融合跟踪目标信息的目标检测算法
输入:video framesFt
输出:bounding boxBt,t=0,…,T
B0=DetectionDETR(F0)
D0=B0
For t=1 to T
Bt=EnhancedDetect(ω,Ft,Dt-1)
Bt=NMS(Bt)
Dt=Binary Graph Matching(Bt,Dt-1)
1.1 整体框架
整体框架,如图1所示.图1中:CNN为卷积神经网络;FFN为前馈神经网络;NMS为非极大值抑制层;re-id为重检测;x′为提取的特征序列;x为叠加位置编码后的图像底层特征信息;y为对应位置的特征向量;z为输出的特征序列;α,θ,γ为可学习参数;ω为相似度.
DETR采用resnet-50[15]作为主干网络,该网络以Block作为基本单位,每个Block包含两层1×1的卷积层和一层3×3的卷积层,外加跳接层传输残差,其中,1×1卷积层主要用于减少通道数,降低网络整体参数量.主干网络一共包含48个Block用于提取图像底层特征,而后展平为序列x′,叠加位置编码后的x输入Transformer[16]网络.Transformer网络分为Encoder与Decoder两大模块.不同于以往CNN获取图像信息的方式,Encoder采用文献[16]所提出的注意力机制,主干网络提取的特征序列经过自注意力层与全连接层(共有6组Encoder串接),可以提取图像中长距离相关信息作为输出的特征序列z,克服了CNN过于关注局部信息的问题.Decoder的输入为固定数目的object query序列(每个序列元素代表图像某个位置的编码,可学习)及Encoder输出的从图像中所提取到的特征序列z,输出为图像上该object query对应位置的特征向量y.经过两层FFN和NMS[17]后,得到图像上对应位置包围框的定位数值序列b及包围框内存在目标物的概率值P(c|b),其中,c表示类别.
为解决视频信息中常存在的模糊、遮挡问题,提出基于注意力叠加的标识提取模块,将叠加的Transformer网络注意力σb作为每个输出目标的空间信息,用于抽取图像上对应空间的底层特征.通过计算跟踪目标(上、下帧所有检测目标经二分图匹配所得)的相似度ω,将已有跟踪目标的特征信息融入本帧检测,增强本帧图像目标检测效果.
1.2 注意力机制
Attention机制最早在视觉领域提出,Google Mind采用循环神经网络(RNN)模型结合Attention机制完成图像分类需求[17].而后,Bahdanau等[25]又将其引入到神经语言程序学 (NLP)领域,采用Seq2Seq融合Attention机制进行机器翻译.将Attention机制推向研究热点的是Google机器翻译团队,Vaswani[16]提出Transformer网络结构,完全抛弃RNN,CNN等传统结构,仅仅依靠Attention机制进行翻译任务,并取得惊人的效果.
Transformer网络结构,如图2所示.图2中:a为解码器的展开;b为Transformer网络简图;c为中的编码器模块,通过上、下文(即寻找源句中与之相关的词语,称为自注意力,即每个词汇对其他词汇关注度的权重)将每个词汇编码为中间向量r;d为自注意力层的展开.求某词汇相对另外一个词汇的“关注度”时,注意力权重ω最终输出r=ω×v.以此逐个计算每个词汇相对源句中其他词汇的注意力,使r中每个语义编码都包含某个词汇在特定上、下文表示的语义信息,即

图2 Transformer网络结构Fig.2 Network structure of Transformer
ωAtt(q,k,v)=softmax(q×k).
(1)
式(1)中:q为该词汇的索引信息;k为匹配信息,v为词汇语义信息.
通过引入注意力机制,克服了RNN,CNN在计算序列信息上存在的窗口问题.序列上每个元素之间的距离不再成为影响结果的重要因素,使长期记忆变为可能.解码器同样使用注意力机制,完成从语义信息编码到目标语言编码的变换,区别只在于解码器注意力层使用编码器输出k,v,不再赘述.
1.3 基于注意力叠加的像素级标识的提取模块
2020年,Facebook AI提出直接将transformer架构适配到视觉领域的DETR网络,不再采用传统的基于预先生成的锚定框回归候选框误差的策略,直接从图像特征并行地回归候选框与类别,最大特点是使用注意力机制Transformer网络中Encoder层自注意力权重热点图,如图3所示.图3中:(8,13),(9,25),(9,3),(8,32)为编码器在特征图上的4个位置.
由图3可知:在DETR网络中,Encoder每层的注意力有集中于目标实例的特性,而在Decoder各层的注意力则分散于每个目标实例的边缘处.因此,依据该特性提出基于注意力叠加的标识提取模块,通过叠加Encoder与Decoder每个检测实例的注意力权重,获取在预测该目标时网络重点关注的空间位置信息,用于提取像素级别的网络低维度特征.Transformer网络中Encoder层各通道自注意力权重的叠加,如图4所示.图4中:a为解码器注意力叠加;b为编码器自注意力叠加.

图4 Transformer网络中Encoder层各通道自注意力权重的叠加Fig.4 Superposition of Self-attention weight of each channel in the encoder layer in transformer network
由图4中的a可知:原图像经过主干网络输出为w×h的featuremap,将其展平成长度为n=w×h的一维向量x,则Encoder层注意力权重矩阵为Nn×n,每一行代表某像素点对与其他像素点的注意力值,共n行,即有n幅注意力权重热点图.
同理,Decoder层注意力权重矩阵为Mm×n,m为object query序列长度(有100个预测结果),每一行代表某个输出对Encoder输出r的注意力权重.设σm×n代表m个预测结果所关注的featuremap上的空间位置信息,则图4中b的第i个预测结果的权重信息为
(2)
(3)
式(3)中:xt为主干网输出的特征图.
1.4 时序特征的融合模块
网络通过之前帧的目标检测与跟踪所提供的信息增强本帧目标检测效果,也即在构建的网络在进行目标检测时,不仅使用了本帧里的图像信息,还使用了从前些帧中恢复的tracklet信息,即增强型目标检测网络融合了上、下文信息.
(4)

(5)
式(5)中:参数θ,γ初始值分别为θ=20.0,γ=8.0.
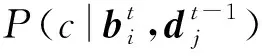
(6)
式(6)中:α的初始值为0.5.
早在2014年,杰卡斯开始颠覆传统,采用全新酿造工艺,钻研双桶陈酿。“我们除了把控传统的酿造技艺,在杰卡斯双桶创酿系列上,还额外增加酿制步骤,把葡萄酒置入陈年威士忌酒桶中。用时间酝酿出更完美的酒体。”国际酿酒师Bernard Hickin如是说。据介绍,酿制时,得先把红酒放到传统橡木桶内12-18个月深度熟成,然后再由经验丰富的酿酒师,把葡萄酒放入陈酿威士忌酒桶中陈酿,进行二次熟成。
(7)
包围框与跟踪目标的匹配有多种方法[10],采用基本的KM算法进行匹配,代价矩阵C为
(8)
本帧所预测的目标为以最小代价匹配已有跟踪实例,设定最大代价值为2.0,超过此值忽略匹配.本帧预测目标匹配成功的实例根据式(7)更新已有跟踪实例数据,已有跟踪实例在本帧未被匹配者,则从缓存中删除.即
2 实验部分
实验平台硬件配置如下:Intel(R) Xeon(R) CPU E5-2623 v4@2.60 GHz;内存32 GB;TITAN Xp型显卡,12 GB.软件配置如下:Ubuntu18.04LTS,CUDA11.2,python3.6,pytorch1.6.0.为验证文中方法,采用KITTI数据集对不同方法进行对比.KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集.该数据集用于评测立体图像、光流、视觉测距、3D物体检测和3D跟踪等.KITTI数据集包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断.同时,KITTI数据集包含多个类别的标签,但大部分类别数据量较少,文中取数据最多的Car,Pedestrian与Cyclist三项.
2.1 模型训练
为减短模型训练时间,部分网络初始权重采用在ImageNet上预训练好的DETR模型参数,并冻结主干网络权重,不参与学习.损失函数loss为
(9)
式(9)中:ρ,ζ为超参数,均取1;Bpre为预测的包围框集合,Btru为包围框标签集合.
训练采用Adam优化算法,初始学习率为0.000 1,权重衰减参数为1×10-5,学习率衰减策略为StepLR,StepSize为200.输入图像分辨率1 242 px×375 px,为体现网络在遮挡条件下融合上、下文信息预测的能力,除通常的归一化等图像预处理外,还对目标进行随机的遮挡.训练集图片总数为7 121,随机抽取3张连续帧作为一个训练单元,则每个epoch有7 118个训练单元.网络训练损失函数曲线,如图5所示.图5中:loss为损失函数.由图5可知:网络在快速下降后,逐渐趋于平稳.
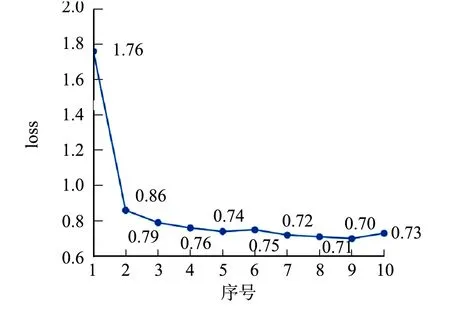
图5 网络训练损失函数曲线Fig.5 Loss function curve of network training
2.2 检测结果
被遮挡目标的检测效果图,如图6所示.图6中:每个样本包含连续的3帧图像,并在第3帧人为添加遮挡物;红色框为目标检测效果;蓝色框为原DETR网络目标检测效果.为排除训练次数带来的干扰,测试的两模型中相同网络部分具有同样的权重.

(a) 样本1 (b) 样本2

(c) 样本3 (d) 样本4图6 被遮挡目标的检测效果图Fig.6 Detection effect diagram of occluded target
由图6可知:目标物无遮挡的情况下,两网络表现效果相近;而对于被遮挡的目标物(遮挡物为实心黑色圆,遮挡比(η)为圆半径与包围框宽度比),文中网络具有更好的效果.
改进前、后目标检测精度数据,如表1所示.表1中:AP为精度.

表1 改进前、后目标检测精度数据Tab.1 Target detection accuracy dates of improving before and after
由表1可知:随着遮挡比的增大,两种方法的检测准确率均出现了下降的趋势;但文中网络在目标物被遮挡的情况下有更好的表现效果,且两种方法的差距随着遮挡比的提升而提升.
不同遮挡物比下各检测网络的平均精度对比,如表2所示.

表2 不同遮挡物比下各检测网络的平均精度对比Tab.2 Comparison of average accuracy in different detection network with different occlusion proportions
3 结束语
针对视频中的目标物移动可能产生遮挡、姿势的变化,光照的差异等问题,提出一种基于注意力叠加与时序特征融合的目标检测方法.引入注意力权重叠加的像素级标识提取模块,更好地匹配轨迹.通过已有轨迹信息,采用时序特征融合的方式增强当前帧下的目标检测精度.实验结果证明,文中方法能有效修正目标物被遮挡等情况下的检测效果,是一种具有强鲁棒性的目标检测方法.
