基于特征级联的肺炎咳嗽声识别
2022-09-09殷仁杰徐文龙
殷仁杰,徐文龙
(中国计量大学,浙江 杭州 310000)
0 引 言
肺炎是在肺部产生炎症影响的一种常见呼吸道疾病,其症状表现为持续的咳嗽和胸部疼痛等。根据2019 年国家卫生健康委统计信息中心数据显示,由主要感染性疾病导致死亡的概率中肺炎占比最高。文献[2]指出不同疾病引发的咳嗽声具有各种差异,根据差异对咳嗽声进行处理,达到识别肺炎的目的。当前在识别肺炎方面常采用肺音、呼吸音等作为信息载体,但相比之下识别咳嗽声具有非接触性、设备成本低、操作简单等优点。
对肺炎咳嗽声的识别研究主要是通过组合不同的浅层特征,或对组合后的高维特征使用遗传算法、主成分分析等降低维度保留良好特征,最后应用机器学习模型实现识别。文献[3]从咳嗽声提取梅尔频率倒谱系数等22 维特征,输入到人工神经网络分类器,实现肺炎的识别。文献[4]组合梅尔频率倒谱系数以及时间序列的最大值、方差等统计参数来识别慢性阻塞性肺炎,并使用信息增益方法选择特征,获得了85.4%的识别准确率。文献[5]采用小波分析方法,对爆裂音、啰音、喘息等不同状态的肺音,提取小波能量特征,在BP 神经网络上识别准确率为82.5%。文献[6]指出肺炎咳嗽声含有裂纹信号,使用小波分析方法得到小波系数特征,与非高斯评分、双谱评分、对数能量等30 维特征组合作为逻辑回归模型输入,得到88%的特异性。文献[7]提出通过短时傅里叶变换将咳嗽声转换成语谱图,通过图像识别的方法达到对咳嗽声的识别。使用深度网络模型对语谱图进行特征提取,可以很好地得到咳嗽声隐藏的深层特征。
本文通过特征级联方法结合两种层次特征,分别为小波包分解咳嗽声提取出的浅层特征,以及特征提取模型从语谱图保留的深层特征,实现同时保留咳嗽声的浅层细节和深层抽象信息的目的,较使用单一特征有效提高了识别准确率。
1 识别系统流程
肺炎咳嗽声识别方法主要对咳嗽声提取不同层次的特征,借助于信号处理和图像识别技术,采用深度网络模型作为分类器来识别肺炎。为患者提供一种自主检测手段,降低就诊成本,同时作为一种辅助型肺炎诊断方法。本文识别系统流程如图1所示。
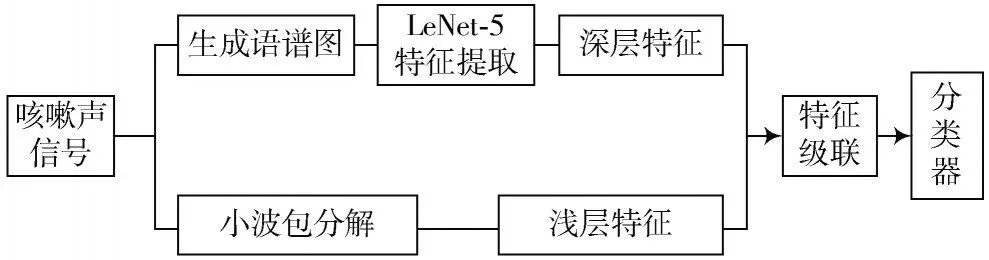
图1 咳嗽声识别流程图
2 咳嗽声处理
2.1 小波包分解
小波变换是一种时频分析方法,在处理非平稳信号领域被广泛使用。小波变换使用可变的时频窗,具有较高时频分辨率。小波包分解方法是在小波变换基础上改进得到的,对每次分解得到的频带再次分解为低频和高频部分。
层小波变换仅把信号分解为(+1)段频带,小波包可以分解为2段频带,使分解的频带更为精细,能得到更高的频率分辨率。
小波包分解公式中,将小波包系数d()分解为d()和d()。其中和代表层数和节点数,()和()分别保留信号低频或高频部分。

对小波包系数求平方得到小波包能量E,小波包能量占总频带能量的比值,即相对小波包能量,相对小波包能量可以体现出咳嗽声信号在每个频带内的能量分布情况。本文采用db3 小波对咳嗽声信号进行6 层小波包分解,使用相对小波包能量作为浅层特征。小波包能量E和相对小波包能量P计算公式如下:
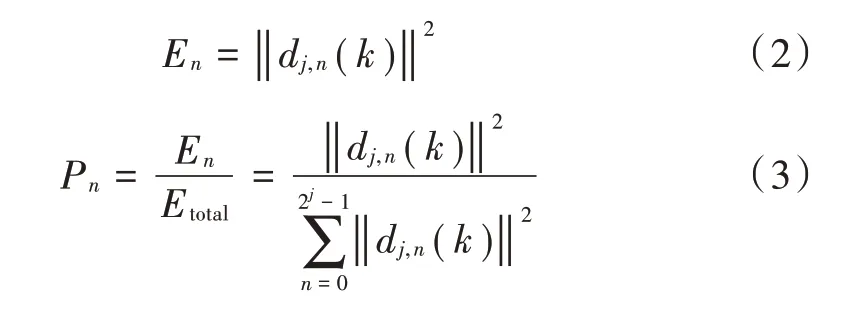
2.2 生成语谱图
语谱图含有大量的时频域特征,如基音周期、共振峰、能量密度、清音浊音等,超过了时域和频域的信息总和,在信号分析领域具有重要作用;结合频谱图和波形图两者之间的优点,使二维图像可以表达出三维信息;其横轴和纵轴方向分别代表时间和频率,而图上点的灰度值表示幅值的高低。
经过对咳嗽声信号进行分帧、加窗、离散傅里叶变换等步骤处理,生成语谱图。首先对咳嗽声信号S()加窗分帧处理,帧移设为帧长的1 2,使用汉明窗()作为窗函数,窗长为。其次对预处理后的咳嗽声信号求取傅里叶系数:
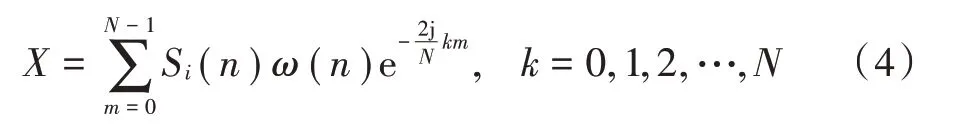
再求取傅里叶系数的对数能量:
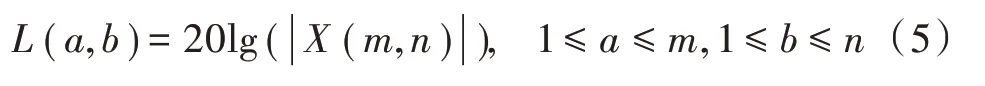
最大最小值归一化处理得到(,):
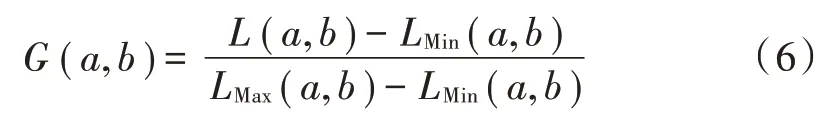


图2 正常与肺炎人群咳嗽声的语谱图
3 SELeNet-5 网络模型
3.1 LeNet-5 特征提取模型
卷积神经网络是一种具有局部连接、权重共享等特性的深层前馈神经网络,主要使用在图像分类和目标检测等方面。其中LeNet-5 是具有代表性的卷积神经网络之一,早期用于识别银行手写数字方面,本文将LeNet-5网络模型用于对图像进行特征提取,能很好地得到语谱图深层特征。LeNet-5 特征提取模型总共有7 层,由卷积层、池化层、全连接层交叉堆叠构成。首先经过卷积层通过卷积核对语谱图的局部区域进行特征提取,其中不同大小的卷积核相当于使用不同的特征提取器;其次池化层起到降维的作用,对卷积层得到的特征降低维度,从而大大减少了网络模型的参数数量,加快网络模型的运行速度;最后经过全连接层选取保留下语谱图深层特征。
LeNet-5 起始用于分类图像方面,其输入和输出分别为32×32 的图像以及10 个分类结果概率值。因此,对LeNet-5 网络模型的初始参数和网络层进行修改,以达到对语谱图特征提取的功能;将第一个全连接层神经元参数设为64,与浅层特征数量保持相等;省略最后输出层以达到特征提取的目的,最终将保留64 维深层特征。LeNet-5 特征提取模型结构如图3所示。

图3 LeNet-5 特征提取模型结构图
3.2 特征级联网络层
依靠单一的网络模型或特征,对于准确率的提升往往有限,而级联方法借助于级联对象之间的差异大小,相比单一对象可以在一定程度上提高准确率。根据级联对象的不同,级联可以分为特征级联、分类器级联两种。特征级联相比分类器级联方法,可以有效利用特征之间的差异,发挥不同层次特征优势。
特征级联方法主要是通过在网络模型中添加Add或Concatenate 网络结构层实现,将来源不同的特征向量进行合并,组合成一组新的特征向量,进而输入到分类器进行识别。两种特征级联结构层具有不同的合并特征方法,主要有以下区别:Add 网络层属于对特征通道内部包含的信息进行合并,并且保持特征通道数量不变;Concatenate 网络层是对特征通道的合并,增加了特征通道数量,通道内部包含的信息保持不变。本文选择Concatenate 网络结构层作为特征级联网络层,有效增加特征通道数量,使咳嗽声具有较多的特征表示,并在Concatenate 层后添加BN 层,可以有效加快收敛速度,防止过拟合。假设,分别是浅层和深层特征,分别使用两种特征级联方法得到级联特征,两种特征级联方法区别如下:
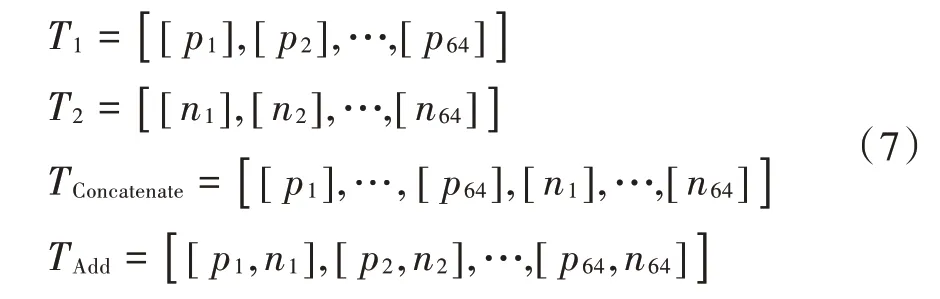
3.3 注意力机制网络模块
通过特征级联网络层结合浅层和深层特征,增加了特征通道数量,但各个特征通道对于识别结果的作用大小不同,无关特征会大大增加模型计算量,增加网络模型的计算复杂度。注意力机制网络模块是采用牺牲较小的计算成本和时间,对特征通道的注意力进行分配,将有限的计算资源聚焦于有效特征通道上,并带来一定的性能提升。
注意力机制网络模块由一个全局池化层、两个全连接层和Sigmoid 函数构成,根据模型训练损失值来确定各个通道的重要程度。首先第一个全连接层将原始特征输入降为其1 16维度;其次通过第二个全连接层将其升为原始维度,使其具有更多的非线性,得到通道之间的相关性;最终通过Sigmoid 函数归一化权重,输出新的特征通道权重集合。注意力机制网络模块结构图如图4所示。
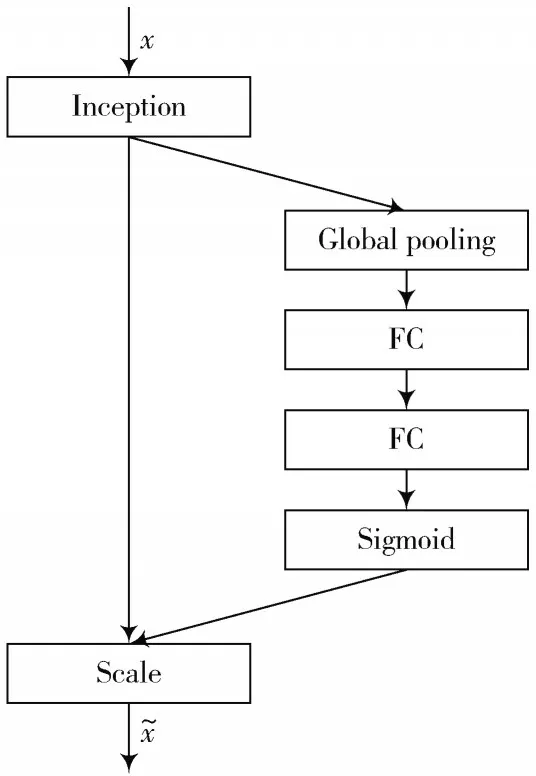
图4 注意力机制网络模块结构图
图4中,Scale 是将归一化权重以矩阵相乘方法加权到原始特征通道,完成对原始特征通道上的权重更新。权重更新公式如下:

式中:代表特征通道权重集合;为128 维级联特征的通道矩阵。
因此在特征级联网络层后加入注意力机制网络模块,调整特征级联得到的128 维特征通道的权重大小,加大有效特征通道的权重大小,提高模型准确率。将经过注意力机制网络模块更新权重后的特征,通过两个全连接层保留主要信息,输入到Softmax 函数,输出肺炎咳嗽声识别结果。整体网络模型命名为SELeNet-5 网络模型,网络架构如图5所示。
图5 SELeNet-5 网络结构图
4 实验结果与分析
4.1 数据采集与处理
实验所使用的肺炎咳嗽数据来源于医院病房,采集前已征得受试者的同意,对其多次连续性采集咳嗽声。采集设备为索尼PCM-D100 录音器,录音器采样率设置为44.1 kHz。采集过程中保持相对安静的环境,将录音器放置在受试者嘴部大约40 cm 的位置,使受试者肺部充分吸气,并多次主动性咳嗽。共获得23 名(男18 名,女5 名)受试者样本咳嗽声数据,受试者所患疾病包括慢性阻塞性肺炎、支气管肺炎等常见肺炎,且具有专业临床医生开具的临床诊断。正常受试者咳嗽声数据来源于课题组实验室,采集方法与肺炎咳嗽声的采集方法相同。为了保证数据分类的稳定,同样选取23名(男18名,女5 名)正常受试者作为样本采集,且选取与肺炎咳嗽声等量的片段作为正常咳嗽声数据。
使用Audacity 音频处理软件,人工选取咳嗽声并将其裁剪为等长320 ms 的片段,使每个片段均包含咳嗽声。总共得到肺炎咳嗽声片段和正常咳嗽声片段各418 个。采用数据增强对咳嗽声数据集进行扩充,避免数据集体量小,产生过拟合等问题。将音量调高为原始数据的1.5 倍,以及添加白噪声生成新数据,数据扩充后的数据量约为原始数据的2 倍。将数据扩充前后的咳嗽声片段混合,并随机划分为80%的训练集和20%的测试集。数据集组成如表1所示。
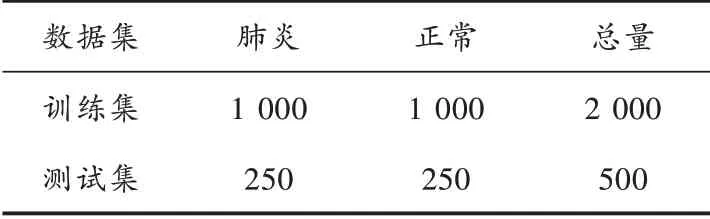
表1 咳嗽数据集组成 段
4.2 实验结果
为了体现特征级联方法对肺炎咳嗽声识别的有效性,采用不同层次特征进行对比实验。方法1 将相对小波包能量通过两层全连接层输出识别结果;方法2 将语谱图输入到LeNet-5 特征提取模型,再通过两层全连接层输出识别结果;方法3使用两种特征输入到SELeNet-5网络模型实现识别。三种不同输入特征对比实验结果如图6所示。
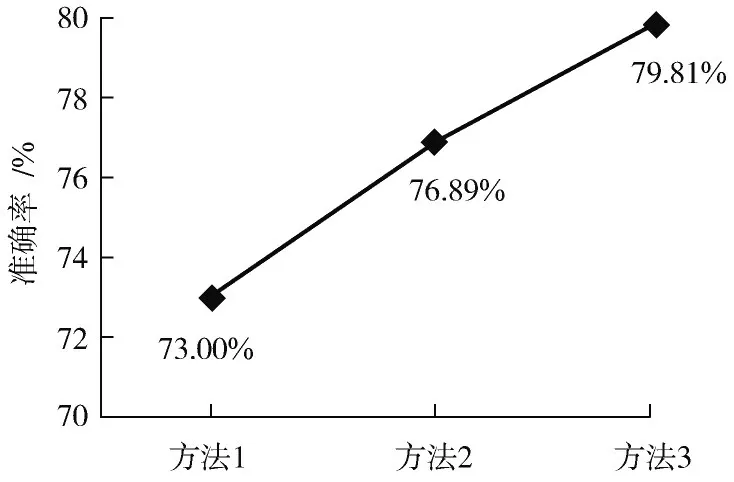
图6 准确率实验结果
由图6 得到:方法2 比方法1 的识别准确率高3.89%,证明了深度网络模型能很好地处理图像问题,以图像识别的形式可以较好地用于识别咳嗽声;方法3相比方法1 和方法2 准确率分别提高了6.81%和2.92%,表明通过特征级联方法及使用注意力机制网络模块,可以有效地兼顾浅层和深层两种特征,对于提高咳嗽声识别方面是有效的。
5 结 语
当前医学上对于肺炎疾病识别方面,主要依赖于胸片检查和专业医生听诊等手段,存在成本高、专业要求高等缺点。本文提出的基于特征级联的肺炎咳嗽声识别方法,提供了一种非接触性、低成本、较高准确率的肺炎识别方法,采用特征级联方法合并两种不同层次特征,实现对肺炎咳嗽声的识别。实验结果表明,特征级联方法可以有效提高肺炎咳嗽声识别的准确率。下一步将研究基于音频识别出咳嗽声并自动裁剪的方法,以及设计一套便携式硬件系统用于识别肺炎咳嗽声。
