基于交叉分布对齐的深度自监督多视图聚类方法
2022-09-07陈泓达陈培钦
陈泓达 陈培钦
学术研究
基于交叉分布对齐的深度自监督多视图聚类方法
陈泓达 陈培钦
(广东工业大学,广东 广州 510006)
为高效利用多视图数据的一致性和互补性信息,提高多视图聚类效果,提出一种基于交叉分布对齐的深度自监督多视图聚类方法。首先,采用交叉对齐策略学习视图间的潜在联系,得到多视图共享潜在表示;然后,执行聚类操作,并将聚类结果作为伪标签信息,建立一条自监督路径;接着,在统一的框架中联合学习优化;最后,在3个公共多视图数据上进行实验,结果表明,本文提出方法的聚类评价指标均表现出较好性能。
多视图聚类;变分自编码器;交叉分布对齐;自监督
0 引言
聚类作为一种无监督学习方法备受研究者关注,并在计算机视觉和机器学习等领域被广泛研究[1-2]。随着互联网和传感器技术的迅速发展,相关领域的数据每天都呈指数增长,且这些数据已从单一视图描述演变成各种类型的多视图描述,从而形成多视图数据。多视图数据从不同角度描述同一对象的多种信息,提供丰富互补信息,使不同视图之间既存在联系又存在差异。
多视图聚类(multi-view clustering, MVC)是将多视图特征信息相似的对象分到同一类,不相似的对象分到不同类,且可跨不同视图搜索其一致性的集群。自1967年以来,研究人员已提出许多聚类算法,如K-means[3]、谱聚类[4]和子空间聚类[5-8]等。但这些算法仅适用于单视图数据,无法扩展应用于多视图数据。
从21世纪初开始,多视图聚类方法得到多方面研究。NGIAM等[9]通过训练双峰深度自动编码器获取视图共享表示;WANG等[10]扩展典型相关性分析,引入自编码器正则化,提出一种深度典型性相关自动编码器(deep canonically correlation autoencoder, DCCAE),但上述方法仅适用于2个视图的情况。2012年,HUANG等[11]提出谱聚类的亲和度聚合(affinity aggregation for spectral clustering, AASC)算法,将谱聚类扩展应用于多视图数据,并取得较好效果。2014年,XIA等[12]利用各视图转移概率矩阵获取共享低秩转移概率矩阵,并通过低秩和稀疏分解的鲁棒多视图光谱聚类(robust multiview spectral clustering, RMSC)方法,取得令人满意的聚类效果。考虑到不同视图对全局聚类能力的差异,NIE等[13]提出多视图自适应Procrustes加权(adaptively weighted Procrustes, AWP)方法,对Procrustes均值进行加权改进,并应用于多视图数据。随着图学习的快速兴起,许多研究者将图学习应用于多视图聚类。ZHAN等[14]提出的多视图共识图聚类(multiview consensus graph clustering, MCGC),通过多视图学习具有个连通分量的共识图,可直接从共识图中获取聚类结果。LIANG等[15]在统一的目标函数中,同时对多视图一致性和不一致性进行建模,提出相似图融合(similarity graph fusion, SGF)和相异图融合(dissimilarity graph fusion, DFG)2种方法,前者通过相似图对多个视图信息进行融合,后者利用距离进行视图信息融合。
虽然现有的多视图聚类研究取得了一些进展,但多视图数据内在的有用信息尚未被充分利用,主要难点在于如何挖掘多视图数据的一致性和互补性信息来提升聚类效果。为此,本文将深度学习应用于多视图学习,并受自监督思想启发,提出一种基于交叉分布对齐的深度自监督多视图聚类(deep self- supervision multi-view clustering based on cross- distribution alignment, DSMVCCDA)方法,可有效提升多视图数据聚类效果。
1 基本架构
本文提出的基于交叉分布对齐的深度自监督多视图聚类(DSMVCCDA)网络架构如图1所示。
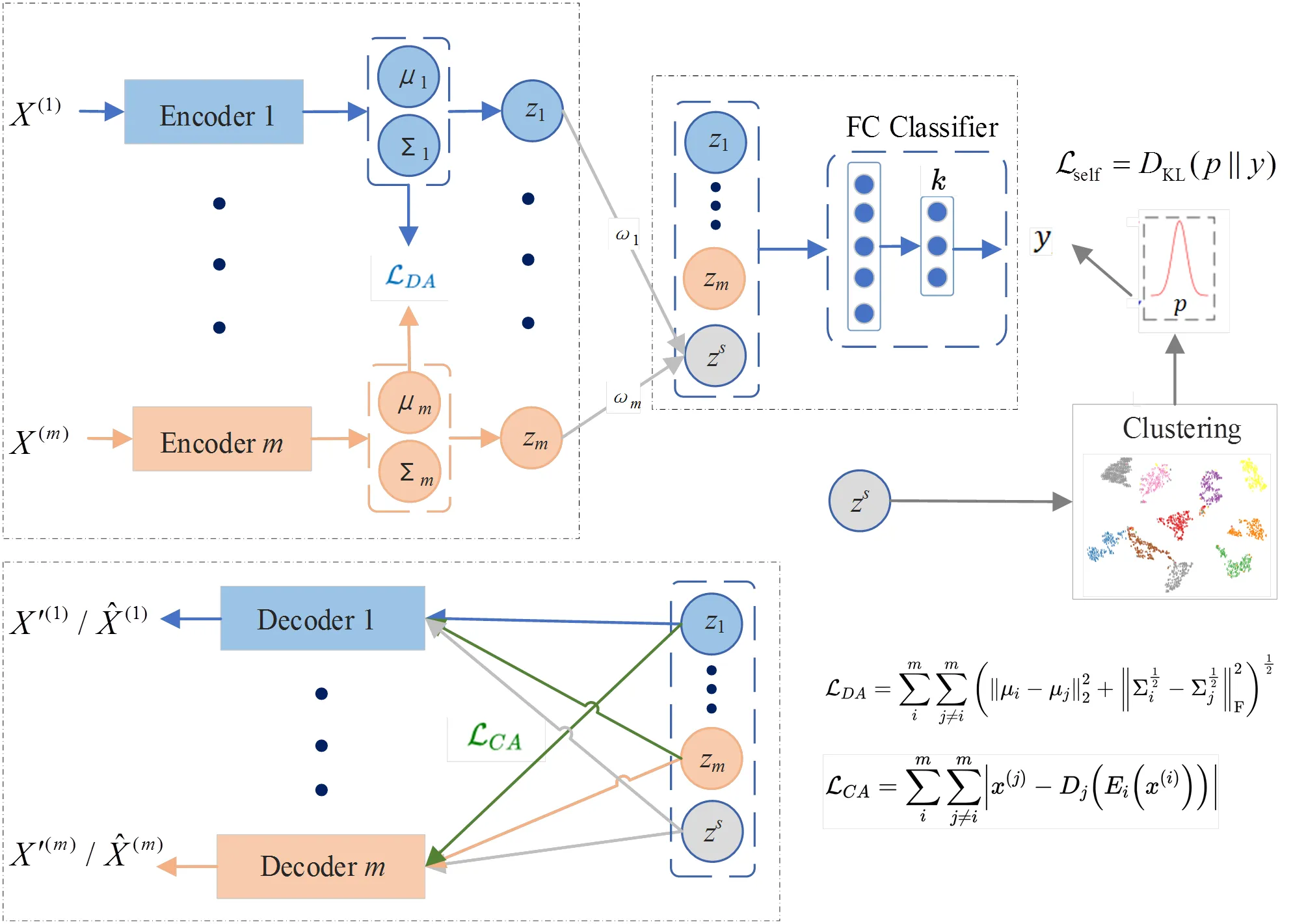
图1 基于交叉分布对齐的深度自监督多视图聚类网络架构
由图1可知,DSMVCCDA主要由3部分构成:
1.1 交叉分布对齐
交叉分布对齐是指利用VAE网络中编码器(encoder)对视图潜在分布进行对齐,同时为减少分布对齐损失的信息,在解码器(decoder)重构过程中引入交叉对齐来平衡多视图数据的学习。
由于DSMVCCDA的目标是学习多个视图间的交叉互补信息的组合形式,故VAE网络结构包含个视图编码器,且每一个视图编码器对应一个解码器,以映射到潜在表示空间。为使VAE网络在学习多个视图交叉互补信息的同时,能最大限度地减少信息丢失,需通过解码器网络重建原始数据,所以DSMVCCDA模型的基本VAE损失是个视图的VAE损失之和:


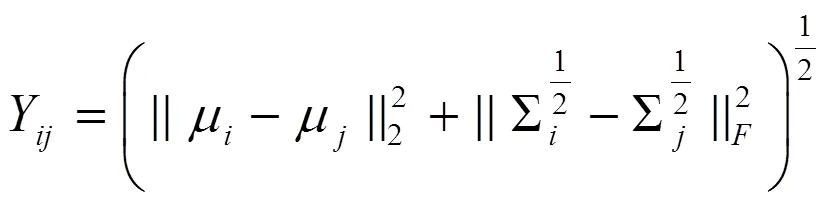
式中:
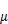

对具有组分布对齐的多视图数据,分布对齐损失函数可表示为

考虑到分布对齐给学习多视图一致性信息带来的较强约束,引入交叉对齐可以平衡DSMVCCDA模型对多视图一致性和互补性信息的学习。交叉对齐利用其他视图在VAE学习到的潜在表示,加入自身视图特定的解码器进行交叉学习,可以在保留特定视图信息的情况下,利用其他视图信息提高模型的学习能力。交叉对齐损失函数为

式中:
1.2 共享潜在表示

式中:


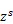

式中:


1.3 自监督聚类

式中:

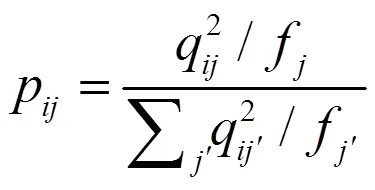
式中:

上述目标分布可通过提高软分配的高置信度得分来指导聚类[19],故聚类损失为

由于多视图聚类是不受监督学习的过程,无法得知学习的多视图特征信息的有效贡献程度。因此,为进一步挖掘多视图数据内在信息,提出了自监督学习方法。与无监督学习相比,自监督学习可利用数据集本身信息构造伪标签信息,监督网络的训练过程。本文提出的DSMVCCDA,将VAE网络学习到的多视图共享潜在表示执行聚类操作后得到的具有标签信息的分布作为伪标签,设计一个具有两层全连接层的分类器作为下游任务,该分类器的输入由所有视图的潜在表示和共享潜在表示组合而成,输出层则使用Softmax函数得到预测分类的概率分布。
本文采用KL散度来衡量2个概率分布的差异,并将其作为损失函数来优化分类器网络参数。自监督分类器损失函数为
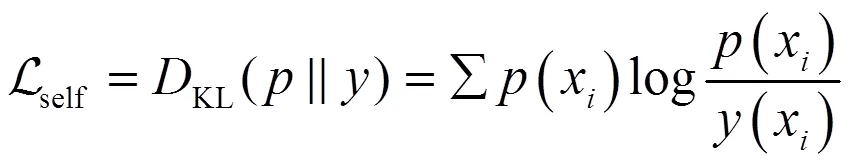
式中:
结合多视图特征学习和聚类损失,DSMVCCDA模型的总体目标损失函数为

式中:

2 数据集与参数设置
为验证本文提出DSMVCCDA方法的有效性,选取3个公开数据集MSRC-v1[20]、NUS-WIDE[21]和Caltech101进行对比实验,数据集统计信息如表1所示。

表1 3个数据集统计信息
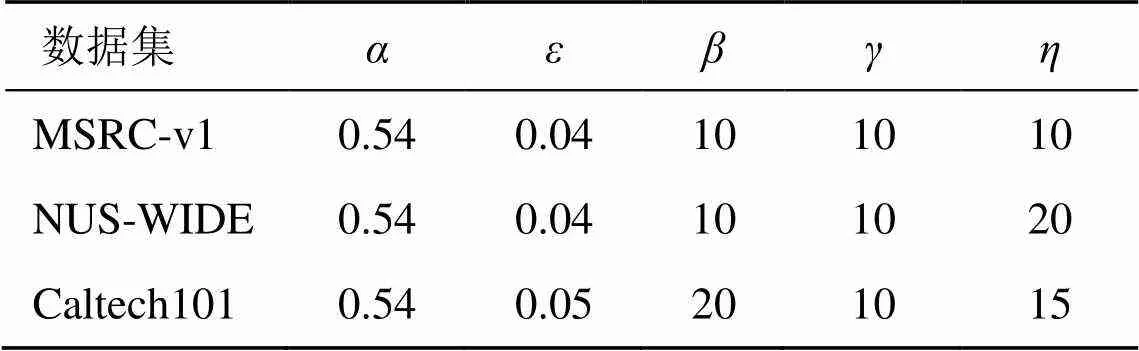
表2 3个数据集的最优参数设置
3 实验结果与分析
3.1 实验环境配置
本文实验基于Python3.6编程语言,采用深度学习框架Pytorch1.1.0搭建环境,显卡配置为GTX 1080Ti和CUDA10.0。
3.2 实验结果与分析
实验选用AASC、RMSC、AWP、MCGC、SGF、DFG等多视图聚类算法,在3个数据集上进行对比实验。聚类评价指标使用聚类准确性(accuracy,ACC)和纯度(purity)。其中,ACC用于测量聚类算法获得的实际标签和预测标签之间的准确性;purity则计算正确聚类数占总数的比例。2个指标值越大说明聚类算法性能越好。ACC和purity结果取10次实验平均值和标准差作为最终的聚类结果,结果分别如表3和表4所示。
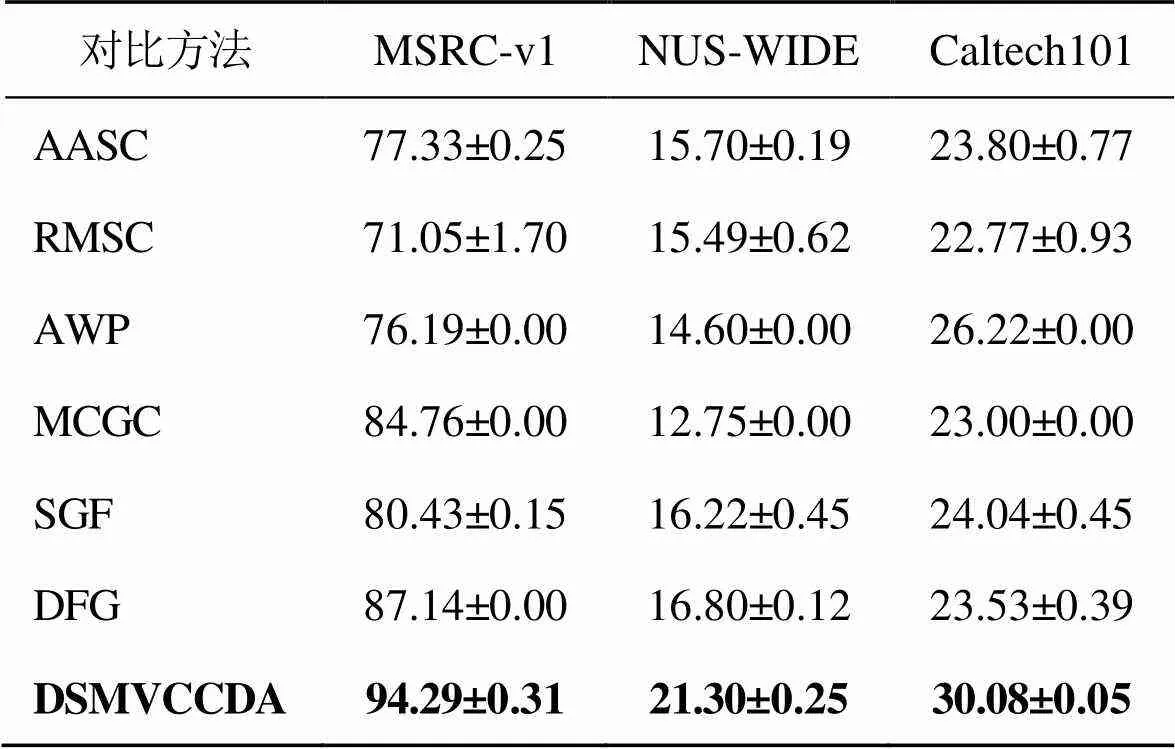
表3 多视图聚类算法在不同数据集上的ACC值 %
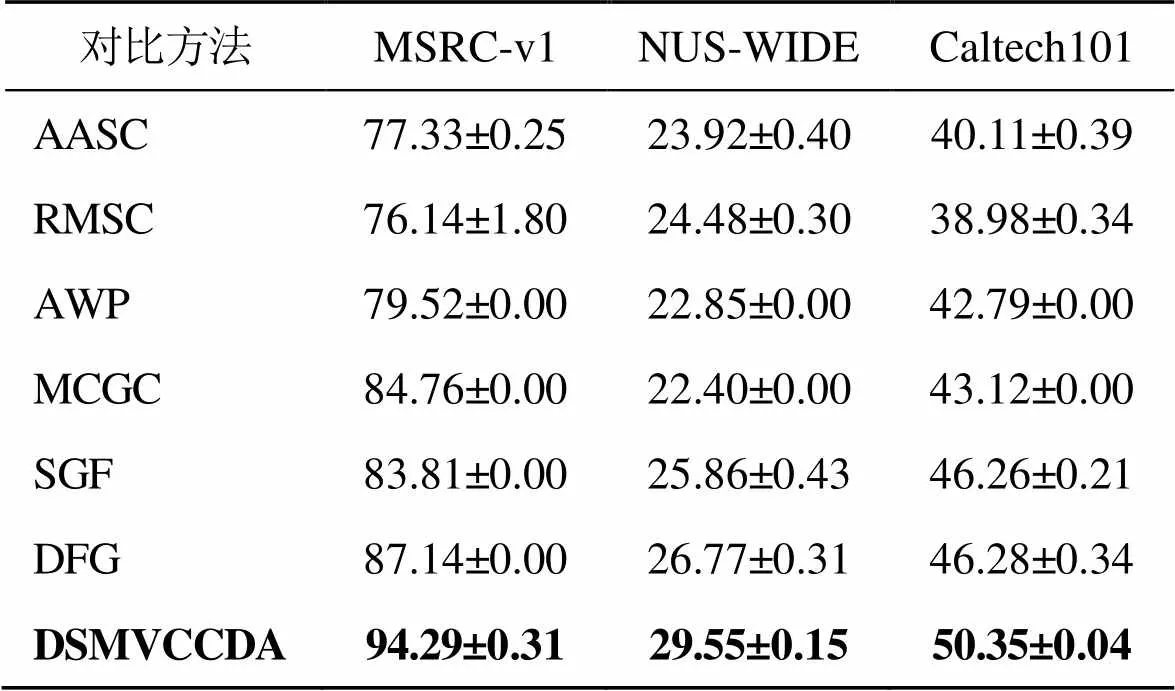
表4 多视图聚类算法在不同数据集上的purity值 %
由表3、表4可知:DSMVCCDA方法在聚类指标ACC上,数据集MSRC-v1、NUS-WIDE和Caltech101分别比次优值高7.15%、4.5%和3.86%;在聚类指标purity上,数据集MSRC-v1、NUS-WIDE和Caltech101分别比次优值高7.15%、2.78%和4.07%。
从不同数据集聚类效果的数值和稳定性来看,同一种多视图聚类方法在3个数据集上表现不尽相同,主要原因是多视图数据集本身结构的复杂性。主要表现在:
1)视图间相关性不强,如NUS-WIDE是由5个低级特征组成的多视图,其中颜色直方图(color histogram, CH)、块方式颜色矩(color moment of block mode, CM)和颜色相关图(color correlation, CORR)具有一定的相关性,而与边缘方向直方图(edge direction histogram, EDH)和小波纹理(wavelet texture, WT)相关性不强,可能造成聚类结果偏低;
2)低质量分类,数据集需要聚类的类别数量是按照人为拟定的标准给定,标准可能过于苛刻,且由于网络没有监督信息,也可能造成聚类结果偏低;
3)不平衡分类,即数据集的聚类类别数量和样本数不平衡,给网络训练带来一定的学习偏差。
得益于深度神经网络强大的拟合非线性能力,本文提出的DSMVCCDA方法采用深度生成式模型变分自编码器,可通过学习共享潜在表示来挖掘视图间的潜在相关性,且引入自监督学习方法可使网络减弱数据集本身结构带来的影响,充分挖掘多视图数据集内在信息,因此,本文方法在3个数据集上表现稳定且优异。
4 结语
为高效挖掘多视图数据的一致性和互补性信息,本文提出一种基于交叉分布对齐的深度自监督多视图聚类方法。该方法在变分自编码器中使用交叉分布对齐策略学习多视图共享潜在表示,执行聚类操作,并将聚类结果标签信息作为伪标签来监督网络的学习,共同优化网络参数。实验结果表明,本文方法在3个公共数据集上的聚类效果比其他多视图聚类方法表现更优异稳定,证明了该方法的有效性。
[1] CARON M, BOJANOWSKI P, JOULIN A et al. Deep clustering for unsupervised learning of visual features[C]// Proceedings of the European conference on computer vision (ECCV), 2018:132-149.
[2] CHANG J, WANG L, MENG G, et al. Deep adaptive image clustering[C]//Proceedings of the IEEE International Confe- rence on Computer Vision, 2017:5879-5887.
[3] HARTIGAN J A, WONG M A. A K-means clustering algorithm[J]. Journal of the Royal Statistical Society(Applied Statistics), 1979,28(1):100-108.
[4] GUO C, ZHENG S, XIE Y, et al. A survey on spectral clustering[C]//World Automation Congress. IEEE, 2012:53-56.
[5] VIDAL R. Subspace clustering[J]. IEEE Signal Processing Magazine, 2011,28(2):52-68.
[6] GAO H, NIE F, LI X, et al. Multi-view subspace clustering [C]//IEEE International Conference on Computer Vision. IEEE, 2015:4238-4246.
[7] ZHANG C, FU H, LIU S, et al. Low-rank tensor constrained multiview subspace clustering[C]//IEEE International Conference on Computer Vision. IEEE, 2015:1582-1590.
[8] YIN M, GAO J, XIE S, et al. Multiview subspace clustering via tensorial t-product representation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018,30(3):851-864.
[9] NGIAM J, KHOSLA A, KIM M, et al. Multimodal deep learning[C]//ICML, 2011.
[10] WANG W, ARORA R, LIVESCU K, et al. On deep multi- view representation learning[C]//International Conference on Machine Learning. PMLR, 2015:1083-1092.
[11] HUANG H C, CHUANG Y Y, CHEN C S. Affinity aggregation for spectral clustering[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2012: 773-780.
[12] XIA R, PAN Y, Du L, et al. Robust multi-view spectral clustering via low-rank and sparse decomposition[C]//Procee- dings of the AAAI conference on artificial intelligence, 2014, 28(1).
[13] NIE F, TIAN L, LI X. Multiview clustering via adaptively weighted Procrustes[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018:2022-2030.
[14] ZHAN K, NIE F, WANG J, et al. Multiview consensus graph clustering[J]. IEEE Transactions on Image Processing, 2018, 28(3):1261-1270.
[15] LIANG Y, HUANG D, WANG C D, et al. Multi-view graph learning by joint modeling of consistency and inconsistency [J]. arXiv preprint arXiv, 2008:10208,2020.
[16] KINGMA D P, WELLING M. Auto-encoding variational bayes y[J]. arXiv preprint arXiv;1312.6114,2013.
[17] GIVENS C R, SHORTT R M. A class of Wasserstein metrics for probability distributions[J]. The Michigan Mathematical Journal,1984,31(2):231-240.
[18] RUMELHART D E, HINTON G E, WILLIAMS R J. Learning representations by back-propagating errors[J]. Na- ture, 1986,323(6088):533-536.
[19] XIE J, GIRSHICK R, FARHADI A. Unsupervised deepembedding for clustering analysis[C]//Proceedings of the 33rd International Conference on International Conference on Ma- chine Learning-Volume 48, 2016:478-487.
[20] WINN J, JOJIC N. LOCUS: learning object classes with unsupervised segmentation[C]//Tenth IEEE International Conference on Computer Vision (ICCV'05), 2005,1:756-763.
[21] CHUA T S, TANG J, HONG R, et al. Nus-wide: a real-world web image database from national university of Singapore [C]//Proceedings of the ACM international conference on image and video retrieval, 2009:1-9.
Deep Self Supervision Multi View Clustering Based on Cross Distribution Alignment
CHEN Hongda CHEN Peiqin
(Guangdong University of Technology, Guangzhou 510006, China)
In order to efficiently use the consistency and complementarity information of multi view data to improve the multi view clustering effect, a deep self supervised multi view clustering method based on cross distribution alignment is proposed. First, the cross alignment strategy is used to learn the potential relationship between views and obtain the potential representation shared by multiple views; Then, the clustering operation is performed, and the clustering result is taken as pseudo label information to establish a self supervised path; Then, joint learning optimization in a unified framework; Finally, experiments are carried out on three public multi view data, and the results show that the clustering evaluation indexes of the proposed method show good performance.
multi view clustering; variational autoencoder; cross distribution alignment; self supervision
TP391
A
1674-2605(2022)04-0003-06
10.3969/j.issn.1674-2605.2022.04.003
陈泓达,陈培钦.基于交叉分布对齐的深度自监督多视图聚类方法[J].自动化与信息工程,2022,43(4):12-17.
CHEN Hongda, CHEN Peiqin. Deep self supervision multi view clustering based on cross distribution alignment[J]. Automation & Information Engineering, 2022,43(4):12-17.
陈泓达,男,1995年生,硕士研究生,主要研究方向:深度多视图聚类、机器视觉等。E-mail: chenhongdaCHD@163.com
陈培钦,男,1996年生,硕士研究生,主要研究方向:模式识别、机器视觉等。
