近红外光谱结合灰狼算法优化支持向量机实现烟叶产地快速鉴别
2022-09-05耿莹蕊沈欢超倪鸿飞刘雪松
耿莹蕊, 沈欢超, 倪鸿飞, 陈 勇, 刘雪松*
1. 浙江大学药学院, 浙江 杭州 310030 2. 浙江大学智能创新药物研究院, 浙江 杭州 310018
引 言
在烟草行业中, 种植产区是烟叶品质分类管理的重要依据, 目前大多企业依靠外观评价和传统化学分析方法对烟叶产地进行鉴别, 存在主观性强、 准确性低、 费时费力等缺点。 因此, 建立一种快速有效的非人工烟叶产地鉴别方法具有重要意义。
近红外光谱(near infrared spectroscopy, NIRS)技术, 具有快速、 高效、 无损等优点, 已在烟草行业中得到广泛应用[1-2], 但由于近红外光谱数据维数高、 信息量大, 往往需要结合多种化学计量学方法, 以提取关键光谱信息构建与烟叶产地之间的联系, 实现烟叶种植区域的识别[3]。 支持向量机(support vector machine, SVM)是一种监督式机器学习算法, 它在解决小样本非线性数据的分类回归方面具有强大的能力。 惩罚因子C和核参数σ是SVM模型的关键参数, 其设置对模型预测能力具有较大的影响。 目前已有遗传算法(genetic algorithm, GA)、 粒子群算法(particle swarm optimization, PSO)等优化算法被用于SVM参数寻优, 并成功应用于烟叶质量评价中[4-5]。 虽然这些优化算法使得SVM模型效果得到改善, 但仍然存在收敛速度慢、 易陷入局部最优等问题。
灰狼算法(grey wolf optimizer, GWO)作为一种高效的优化算法, 相较于其他寻优算法, 具有参数更少、 收敛性更强的特点, 已成功应用于工程损耗定量检测[6]、 电力质量控制[7]、 食品溯源[8]等领域。 本研究基于近红外光谱技术, 首次将基于GWO优化的SVM算法应用于烟叶产地分类模型建立, 以提高烟叶产地判别准确率, 降低建模成本。
1 实验部分
1.1 数据收集
烟叶样本来源于中国八个省份, 包括福建省、 广西壮族自治区、 贵州省、 河南省、 湖北省、 湖南省、 四川省和云南省, 共824份烟叶样本, 由浙江中烟工业有限责任公司提供。 实验采用Antaris Ⅱ FT-NIR(Thermo Fisher Scientific)分析仪, 波数范围为10 000~3 800 cm-1, 分辨率为8 cm-1, 每条光谱代表64次扫描的平均值。 由于八个烟叶产区地理位置比较接近, 因此产地来源分辨具有一定难度。
1.2 光谱预处理
为了消除基线漂移, 降低噪声干扰, 同时又能保证校正后不会过多地降低频谱的信噪比。 采用Savitzky-Golay(SG)卷积平滑结合一阶导数(first derivative, 1stD)对光谱进行预处理。
1.3 特征变量选取
为了获得更稳定的近红外判别分析模型, 剔除光谱中的无关变量[9], 分别采用竞争自适应重加权采样(competitive adaptive reweighted sampling, CARS)和随机青蛙(random frog, RF)算法对全波长的特征变量进行提取以降低数据维度, 从而可以输入较少变量以提高分析速度。
1.4 基于GWO-SVM的产地识别模型
1.4.1 支持向量机(SVM)
SVM是Vapnik等在1995年基于统计学习理论(statistic learning theory, SLT)所提出的新型模式识别方法。 SVM可以很好地解决实际中线性不可分问题, 它以最大间隔超平面为原则, 首先将非线性原始数据映射到一个新的高维空间, 然后在新的维度空间利用核函数从训练数据中学习分类模型, 找到恰好能将数据分开的超平面, 这样就将问题成功转化为高维线性可分问题[10]。
1.4.2 粒子群优化(PSO)
PSO算法又称为鸟群觅食算法。 在PSO中, 粒子是随机生成的, 这些粒子会根据当前的特征行为和位置动态变化随时调整搜索位置, 每组粒子会跟踪先前的最佳位置和适应度进行最优解的寻找, 而每一个粒子找到的最优解会引导其他粒子收敛到最佳方案, 利用粒子群之间的竞争和协作完成每一次迭代, 在粒子不断演化的过程中, 根据当前最优值搜索到适应性最大的解, 则成为全局最优解[11]。
1.4.3 遗传算法(GA)
遗传算法是基于生物在自然界中“适者生存, 优胜劣汰”的进化机制所演化出的一种寻找全局最优解的搜索算法, 通过模拟自然界中生物进化、 遗传变异来实现全局寻优[12]。 在初始种群中, 某些适应度大的个体被选为父代, 父代间进行交叉和突变操作, 以此产生适应度更大的子代, 组成新种群, 再评估每一个体的适应度值, 选择值得进行下一代遗传的个体, 进行下一次迭代。 为了找到合适的遗传个体, 每一个个体都会经过预先设定的适应度函数进行选择, 以使得新一代的染色体比上一代有所提升, 在这样反复的遗传演化过程, 好的基因被遗传, 呈现劣势的基因被淘汰。
1.4.4 灰狼算法(GWO)
GWO的提出是受到了来自于自然界中灰狼生存等级和捕猎的启发[13], GWO模拟了灰狼族群中严格的统治阶级, 并通过灰狼种群捕猎阶段中跟踪、 追逐、 包围、 攻击等行为寻找最优解, 以此实现对支持向量机等智能算法的优化。 采用GWO优化函数进行建模时,α表示最合适的解决方案, 其次分别是β和δ,β和δ主要负责辅助α进行决策, 并且听从α的指令进行猎捕, 狼群最低等级是ω, 它们必须跟随α、β和δ的领导对猎物进行围攻, 以此寻找全局最优解。
在狩猎过程中, 狼群的包围行为由式(1)和式(2)表示
(1)
(2)
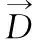
(3)
(4)
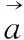
在搜索空间,α,β和δ这三个最优解的位置起着关键的作用, 由这三者预估猎物的大致位置, 而ω会根据这三者更新自己在猎物周围的位置, 以此实现对猎物的最终包围狩猎。
(5)
(6)
(7)
1.4.5 GWO-SVM
采用选择高斯核函数作为支持向量机的核函数, 此时SVM受到惩罚因子C和高斯核参数σ的影响。 在此, 使用GWO算法来对SVM进行参数优化, 通过不断迭代优化, 寻找最佳的参数C和σ, 提高模型的准确率, 降低识错率[14]。 GWO-SVM算法过程如下:
(1) 将烟叶样本数据划分为训练集和测试集, 并对光谱数据进行归一化处理。
(2) 初始化SVM的参数, 并设置SVM中C和σ作为GWO优化值。
(3) 根据C和σ初始化狼群的位置, 使用训练样本对SVM模型进行训练, 并将初始位置输入模型, 以计算灰狼个体的适应度值。
(4) 保留具有最优适应度值的α,β,δ三只狼, 并根据当前最优适应度值, 更新每只狼的位置。
(5) 若已达到最大迭代次数, 则终止迭代循环, 输出由最优位置得出的全局最优参数C和σ, 若未到达最大迭代次数, 则返回步骤4继续进行迭代。
(6) 输出最优参数C和σ, 并对训练数据重新进行SVM训练。
(7) 通过GWO-SVM模型对测试样本进行预测, 并对模型性能进行评价。
以上数据处理均在Windows 10操作系统下, 使用MATLAB R2018 b进行。
2 结果与讨论
2.1 样本划分
图1用不同颜色的曲线展示了824份不同产区烟叶样品的原始近红外漫反射光谱, 八个省份样本的原始近红外光谱并无太大差距, 可见烟叶产地的鉴别有一定难度。 使用基于x-y距离样本集划分(set partitioning based on joint x-y distance, SPXY)算法按照7∶3的比例进行样本划分, 将824个烟叶样本划分为617个校正集样本和207个验证集样本。

图1 烟叶样品的原始近红外光谱图
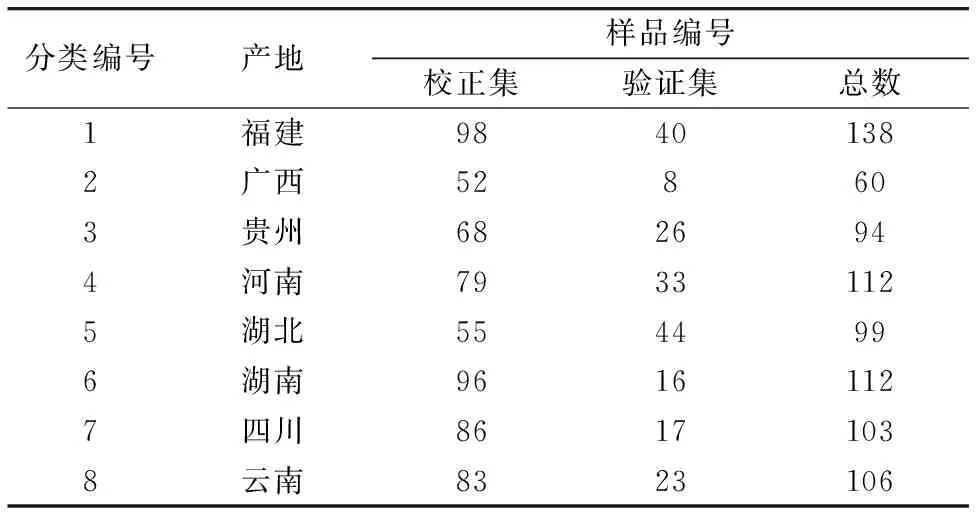
表1 不同产地烟叶样本划分情况
2.2 特征变量筛选
2.2.1 CARS法
在CARS算法中, 将蒙特卡洛采样运行次数设置为100次, 通过五折交叉验证选择具有最小均方根误差(root mean square error of cross validation, RMSECV)模型所对应的波长变量。 图2(a)显示了蒙特卡洛采样次数和采样变量数之间的关系, 前20次采样中, 采样变量数快速下降, 主要反映的是消除无信息变量的过程, 下降至一定程度后趋于平缓。 从图2(b)中可以观察到当采样次数达到37时, 对应的RMSECV最小为1.72。 图2(c)显示的是随着采样次数不同而变化的变量系数, 图中用“*”描述了最小RMSECV所对应的最佳特征波长。 结果, CARS选择了141个变量。
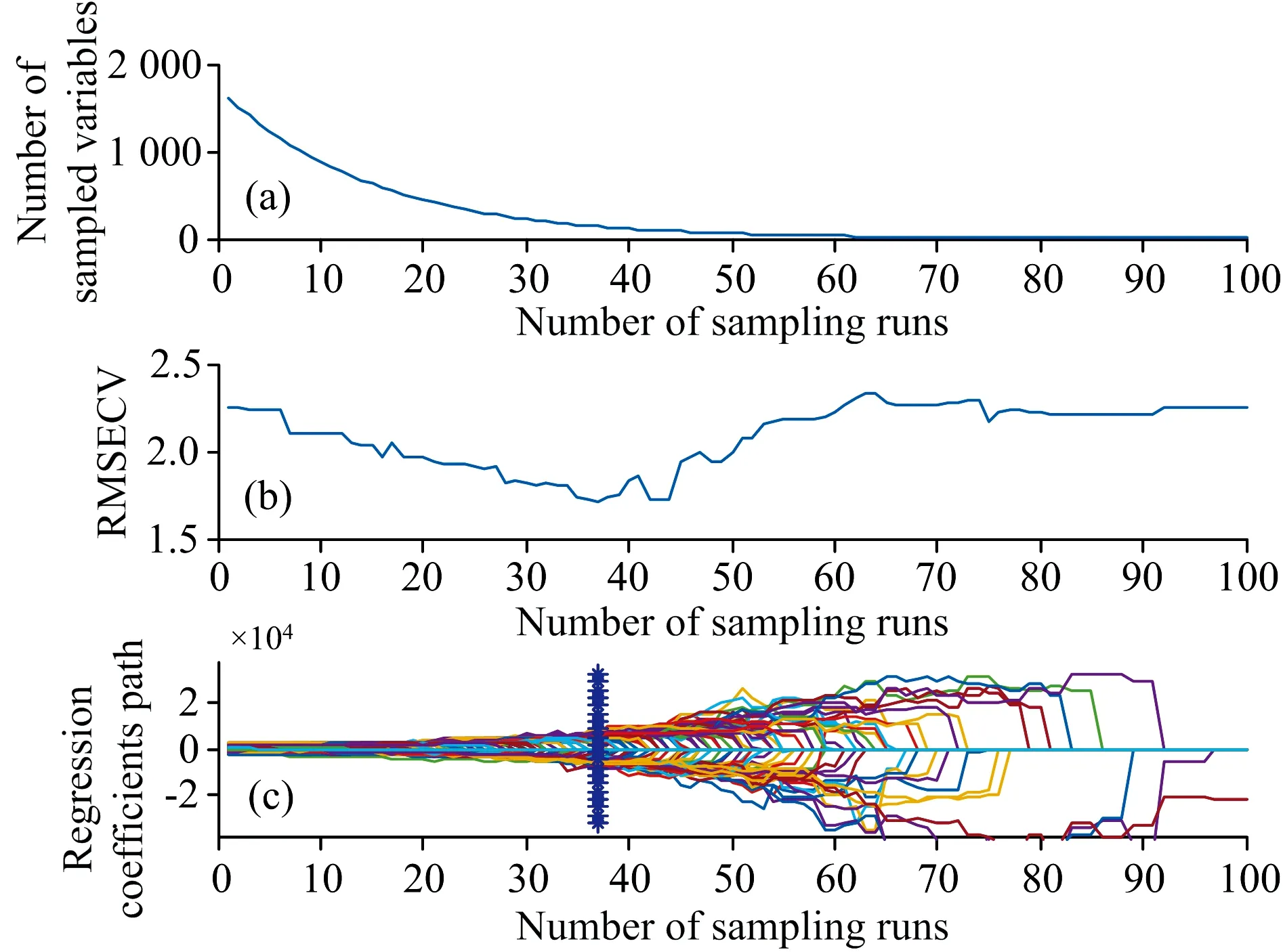
图2 CARS变量筛选优化结果
2.2.2 RF法
随机青蛙算法通过计算每个建模变量被选择的概率, 从中选出被选概率高的变量组合成为特征波长; 由于随机青蛙采用蒙特卡洛随机采样, 因此为了降低随机性, 将所有波长变量运行1 000次, 计算平均筛选概率[15], 设置0.04为筛选阈值, 最终从1 609个变量中选出534个变量作为特征变量, 结果如图3所示。

图3 RF变量筛选结果
2.3 不同优化模型分析
为了准确对比各优化算法的分类效果, 考虑了不同的控制参数, 三种优化算法均设置相同的参数: 种群规模为20, 最大进化次数k为200,C和σ的搜索范围为(0.01, 100)。
分类模型的性能使用准确度和混淆矩阵来评估, 混淆矩阵主要用于比较客观结果和实际类别。 下面分别计算了PSO-SVM, GA-SVM和GWO-SVM模型的分类准确度和混淆矩阵, 结果见表2和图4。 混淆矩阵用横坐标表示真实类别, 纵坐标表示预测结果, 以此描述模型对单个产地的判断分类性能, 颜色越深, 代表正确分类的数量越多, 图4中对角线的颜色越深, 代表准确率越接近100%, 分类性能越好。

表2 不同模型分类效果
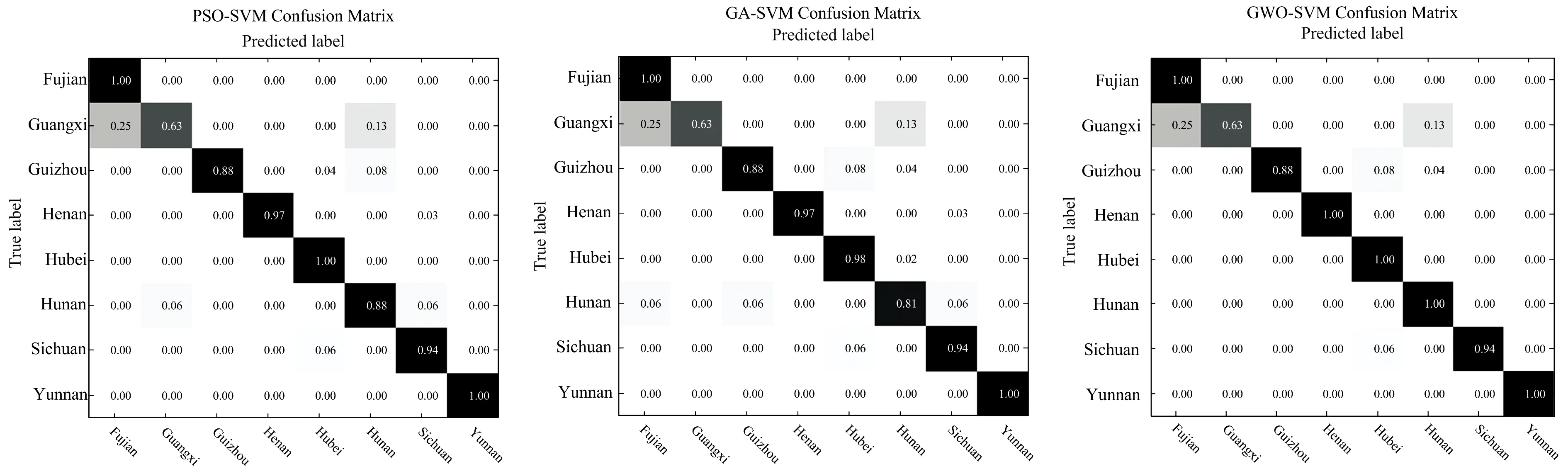
图4 不同分类模型的混淆矩阵
由表2的结果统计可以看出, 在建立烟叶产地分类的SVM模型过程中, 采用RF筛选出的波长组合, 三种模型的判别准确度更高, 其中RF-GWO-SVM的分类正确率最高, 达到96.62%, 说明RF算法具有良好的关键信息筛选能力; 从运行时间来看, GWO-SVM相比于其他两种模型, 寻优时间大大缩短。 这很好的说明, 在相同的测试样本、 相同搜索条件下, GWO算法对SVM的两个参数寻优具有更快速、 更优化的能力, GWO-SVM模型对于烟叶产地的识别效果明显优于PSO-SVM和GA-SVM。
根据混淆矩阵结果, GWO-SVM模型识别正确率达到100%的有五个省份, 分别是福建省、 河南省、 湖北省、 湖南省和云南省, 河南省的分类正确率比其他模型提升了3.03%, 湖南省的分类正确率比其他模型提升了12.5%~18.75%; 但对于来自广西壮族自治区的样本识别仍然不理想, 原因可能是广西的烟叶样本总数仅60个, 分到验证集仅8个, 面对类别不平衡样本时, SVM模型的分类精度受到较大影响。 另外, 将贵州烟叶错分至湖北和湖南, 可能是因为几个省份地理位置接近, 经纬度相似, 烟叶样本中化学成分与物理特征差异不够明显, 从而造成误分。 除此之外, 各个地区的烟叶产地鉴别都得到了很高的精度, RF-GWO-SVM的总体正确率达到了96.62%, 分别比RF-PSO-SVM和RF-GA-SVM提高了1.45%和2.42%。 从预测结果可以得出结论, GWO-SVM的识别效果明显优于其他两个模型。
3 结 论
基于近红外光谱技术, 以824份来自8个省份的烟叶样品为研究对象, 采用CARS和RF进行特征变量筛选, 通过GWO算法对SVM中参数C和σ进行优化, 并建立烟叶产地分类模型。
将GWO-SVM应用于烟叶产地分类, 与PSO-SVM和GA-SVM相比, 该算法所建立的分类模型具备更佳的分类识别性能, 对烟叶产地有更高的判别精度, 总体识别正确率达到96.62%。 同时该算法寻优速度快, 计算成本低, 可以更高效获得SVM模型全局最优参数。 因此, 基于灰狼算法优化的支持向量机模型用于烟叶产地分类是一种更有效、 更强大的方法, 为NIRS技术实现烟叶产地高效鉴别提供参考。
