基于Weka平台和代价敏感特征选择的基因表达数据分类研究
2022-08-31韩磊黄瑞龙范文静叶明全
韩磊,黄瑞龙,范文静,叶明全
皖南医学院 医学信息学院,安徽 芜湖 241002
0 引言
肿瘤是目前人类在疾病面前面临的主要威胁之一。据2014年的《世界癌症》报告[1]显示,仅2012年一年就有超过1000万的癌症新发病例。肿瘤不是瞬间产生的[2],肿瘤细胞的分类增殖存在一个相对较长的演变时期。因此,这种在基因层面对肿瘤进行早期识别的研究[3],对患者的治疗具有重大意义[4-5]。
由于肿瘤基因表达数据是一种典型的不平衡数据[6-7],使之很难直接应用于肿瘤的分类诊断[8-9]。因此本文提出了一种基于Weka平台和代价敏感特征选择的基因表达数据分类方法[10]用于解决这类基因表达数据分布不平衡的分类问题[11-12]。该方法弥补了分类器只注重分类精度的片面性,并且它的合理性在于通过引入代价敏感而寻求总体的最小代价,而不是仅仅拥有精度最高这个特性。通常在代价敏感学习中,对于一个N分类问题,用
1 资料与方法
1.1 资料来源
本文实验从Kent Ridge Biomedical Data Set数据库中选取两个类别,共计六个小组的肿瘤样本数据,分别为神经系统疾病NervSys(central nervous system embryonal tumor)、结肠癌(colon cancer)、弥漫性大B细胞瘤(DLBCL)、卵巢癌(ovarian cancer)、前列腺癌(prostate cancer)和肺癌(lung cancer)。数据集的详细描述见表1。
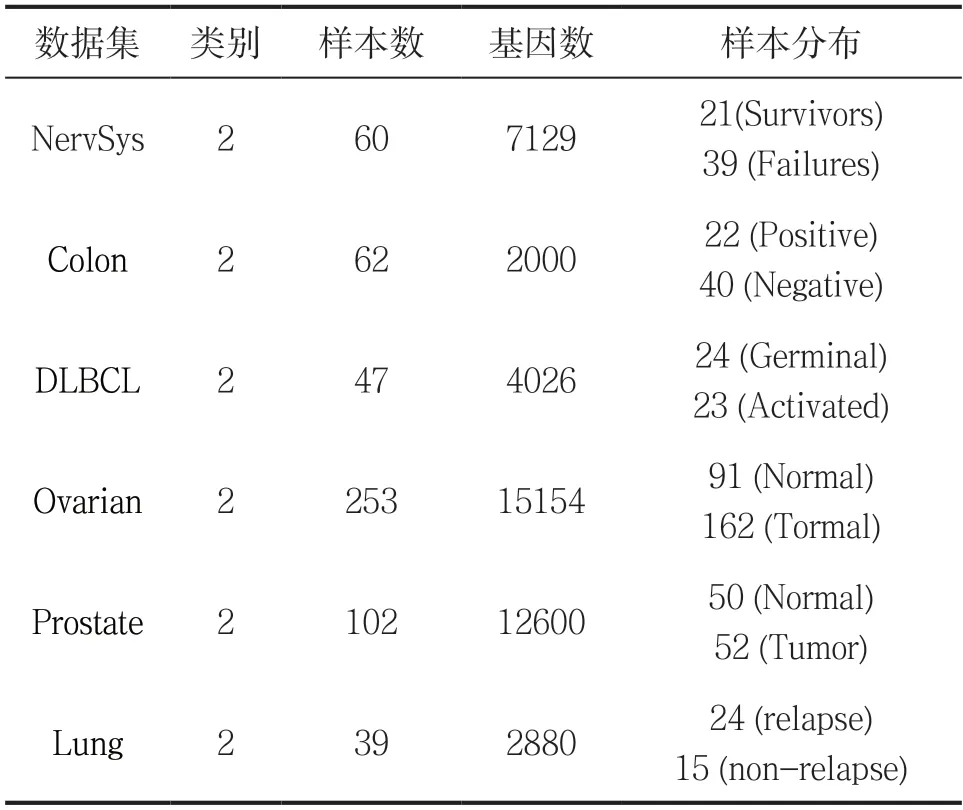
表1 实验数据集描述
1.2 实验方法
本文实验基于Windows 平台完成和实现。为了消除不同量纲对实验结果的影响,实验过程中,我们首先通过Weka平台[13-14]对实验数据集进行标准化预处理,使数据分析更加准确,然后选择本文提出的代价敏感特征选择方法(cost sensitive attribute eval),使用特征选择的搜索函数Ranker来调整信息基因个数,并且通过支持向量机(SVM)、K近邻(IBK)、朴素贝叶斯(NB)和随机森林(RF)这4种分类器对数据进行分类得到的分类准确率来评估该方法的有效性。在实验过程中均使用Weka平台中分类器的默认参数。具体实验流程见图1。
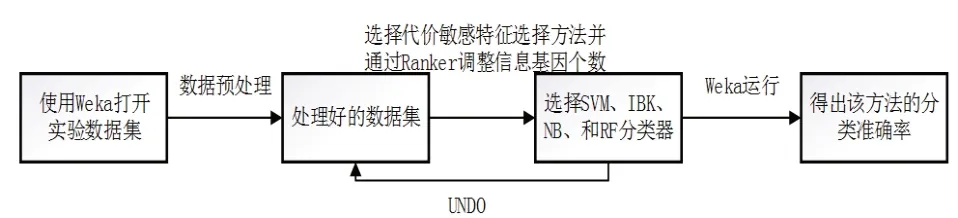
图1 实验流程图
2 实验结果及分析
表2为4种分类器在6组两类别的肿瘤样本数据的分类准确率,表中Std表示在原始实验数据[15]上只执行标准化处理后就进行4种分类器的分类建模,本文方法即通过代价敏感特征选择[16]处理后再进行4种分类器的分类建模。
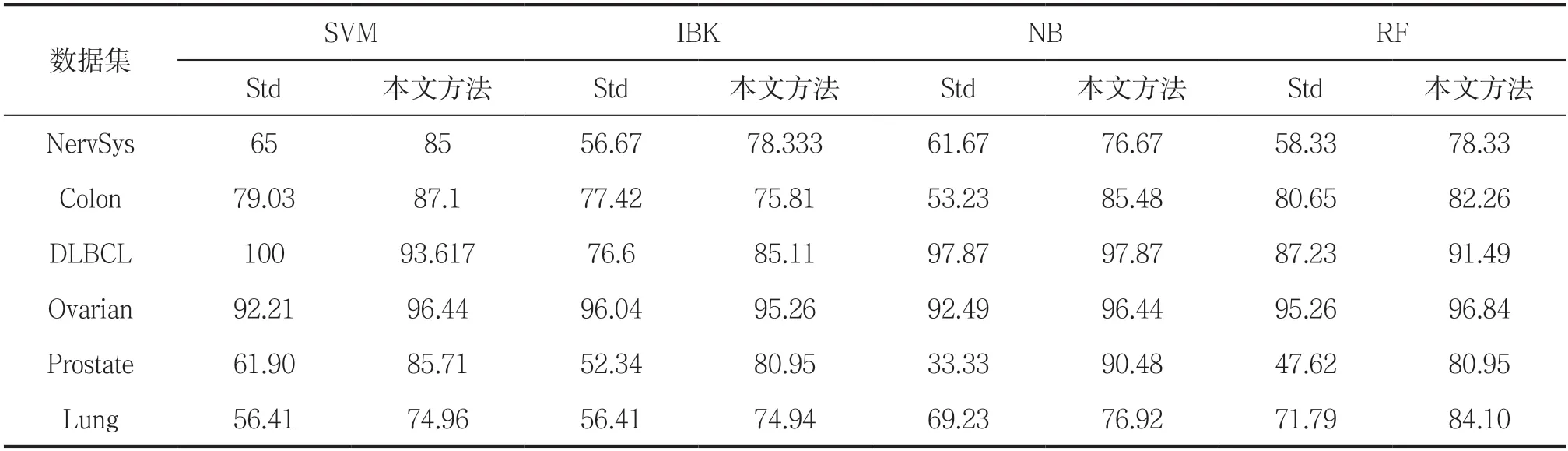
表2 4 种分类器在6 个数据集上的分类准确率对比
为了方便对比,本文实验选择的信息基因数分别为3、4、5、6,选择4种分类器中最高分类准确率作为最终评价值。具体实验结果见表2。
从图2可以看出,六组数据直接在只进行标准化预处理后,在SVM、IBK、NB和RF分类器评估分类性能时,大部分分类准确率较低。但是通过本文实验方法得到的分类准确率大部分高于只进行标准化预处理的分类准确率,这在一定程度上说明了本文提出的代价敏感特征选择方法的有效性。

图2 4 种分类器在6 个数据集上的分类准确率对比
为了更直观地表明本文方法在提高分类准确率上的优良性能,实验还对比分析了其他两种流行特征选择方法的分类准确率。包括SUAE(symmetrical uncert atrribute eval)根据属性的对称不确定性评估属性和CA(correlation attribute)通过测量特征与类别之间的皮尔逊(Pearson's)相关性评估基因的价值。具体实验结果见表3。

表3 3 种方法在6 个数据集上的最优分类准确率
从图3可以看出,对比SUAE和CA的特征选择方法在六组数据的最优分类准确率,本方法也获得了相对更好的分类准确率,进一步有力地证明了该方法具有良好的特征选择效果,能够针对肿瘤基因表达数据获取较高的分类性能。
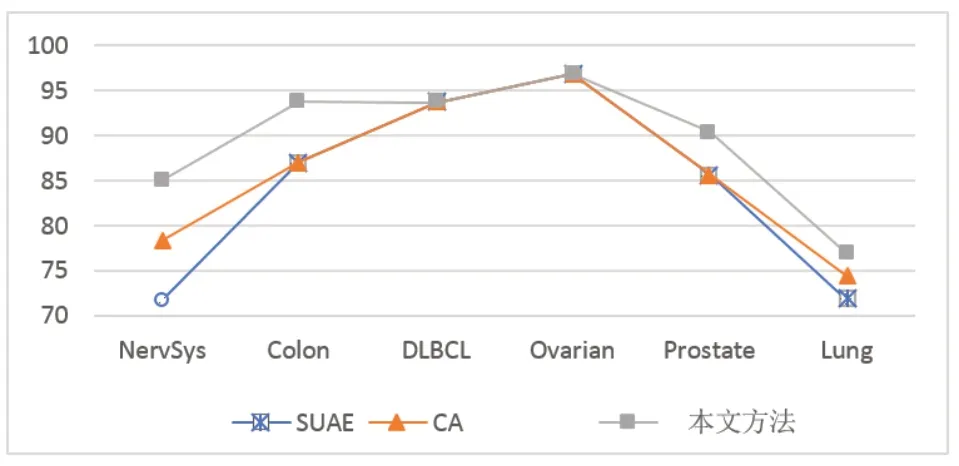
图3 3 种方法在6 个数据集上的最优分类准确率
3 结论
本文提出的基于Weka平台和代价敏感特征选择的基因表达数据分类方法可以有效地解决肿瘤基因表达数据不平衡数据的分类问题,大幅度提高分类准确率,但仍存在一些不足和缺陷[17],如分类过程中真实的误分类代价很难通过人为经验进行准确估计。由于此方法本身的性能指标与代价参数设置等方面存在一定空缺,可能会导致其最终的分类结果存在相对较强的主观性而不够客观,因此代价敏感算法[18]仍有继续完善优化的空间。通过改变一些相关代价参数从而进一步改进本文方法等方式,都是今后的研究方向。
