基于人工智能的手语翻译系统实现
2022-08-30刘继兴张帅峰曾令辉段珍灵沈顺权
刘继兴,周 昕,张帅峰,曾令辉,段珍灵,沈顺权
(哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080)
随着社会的发展,人们的交际需求日益提高。健康人可以使用口语进行交流,而听障人士(失聪)则需要通过手语交流。由于大部分普通人日常生活中并没有学习过或接触过手语,在人与人之间的联系愈发密切的当代社会,听障人士与非听障人士的沟通需求愈发迫切。使用人工智能进行手语翻译可以为听障人士和非听障人士的沟通提供一定的便利。因此,人工智能手语翻译有着重要的理论价值、应用价值及社会意义。本手语翻译系统能够识别《国家通用手语常用词表》中单独手势以及特定情况下连续的手语视频,并将之翻译成较为符合语境且具有可读性的汉语,减轻听障人士与非听障人士沟通障碍。
1 系统功能描述
系统能够实现相对简单且连续的手语图像和视频的采集与翻译。当听障人士在摄像头可识别的范围内用手语与他人进行沟通,客户机会通过摄像头采集手语视频,将数据上传到云服务器。服务器会对数据流进行预处理、提取关键帧等处理并生成相应文字,然后将生成的文本发送给客户机。客户机接收到文字信息,显示文字并通过语音模块进行播放。
2 整体设计
整个系统可以分为客户机和云服务器,如图1所示。主控板收集摄像头采集到的手语视频,基于帧间差分算法在连续手语视频帧中提取出关键帧。使用Tcp socket方式将关键帧数据发送给云服务器。云服务器得到帧数据后,对数据流进行解析,使用YOLOv5自训练手部模型和OpenPose开源库对图像进行识别,生成相应的孤立的文字结果,然后采用隐马尔可夫模型对离散的识别结果进行处理,将最终的文本结果发送给客户机。客户机接收到信息,将文字显示到显示屏并通过语音播放模块播放语音。

图1 手语翻译系统整体架构图
3 预处理及关键帧提取
采集到的原始图像中存在大量噪声,因此需对图像进行预处理以减少噪声干扰,使其突出肢体运动区域信息。预选出2种方法。第一种是将输入图像阈值化为二值图像,然后采用高斯滤波对图像中的每一个像素点进行卷积计算,并加入到原始图像中进行噪声点覆盖;第二种是采用索贝尔算子进行边缘计算,对肢体部分进行边缘锐化,增强图像关键信息。但由于第一种方法会造成图像中的像素点与周围像素点相似,降低图像清晰度。所以综合考虑使用索贝尔算子增强关键信息,以减少原始图像中噪声的干扰。
利用Opencv库可以从手语视频中提取出每一帧图像,但如果对全视频的帧进行处理会非常耗时,所以采取提取有效关键帧的做法降低处理帧数。关键帧的提取是基于帧间差分算法。帧间差分算法的原理是将两帧图像进行差分,得到图像的平均像素强度来衡量两帧图像的变化大小。基于帧间差分的平均强度,每当视频中的某一帧与前一帧画面内容产生了大的变化,便认为它是关键帧,并将其提取出来。
基于帧间差分算法提取关键帧的方案如下。
3.1 使用差分强度的顺序
对所有帧按照平均帧间差分强度进行排序,选择平均帧间差分强度最高的若干张图片作为视频的关键帧。
3.2 使用差分强度阈值
选择平均帧间差分强度高于预设阈值的帧作为视频的关键帧。
3.3 使用局部最大值
选择具有平均帧间差分强度局部最大值的帧作为视频的关键帧。
在这里,选择第三种方案,将具有平均帧间差分强度局部最大值的帧作为视频的关键帧。
4 数据的传输
数据的传输使用Tcpsocket网络编程。在整个系统中多台客户机与云服务器进行通讯,对后台服务程序提出了并发要求。处理并发网络编程常用的几种方案如下。
4.1 单线程/进程
服务端程序只有一个进程/线程,没有客户端连接时会阻塞当前进程/线程。当检测到新连接时会解除阻塞,与客户端连接,进行收发数据。
4.2 多进程开发
服务端程序有多个进程,进程间具有父子关系。父进程负责监听,处理客户端的连接请求,创建子进程和回收子进程资源。子进程负责与客户机收发信息。
4.3 多线程并发
和多进程并发类似,此时主线程负责监听,处理客户端的连接请求,创建子线程和回收子线程资源。子线程负责与客户机收发信息。
4.4 IO多路复用epoll
epoll的好处就在于单个进程就可以同时处理多个网络连接的IO。其基本原理就是epoll这个function会不断地轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。用一个进程就能实现服务器并发。
5 手语图像识别
使用YOLOv5和OpenPose人体资态识别开源库对图像进行识别。YOLO(You Only Look Once)是目前流行的目标检测模型之一,在业界的应用也很广泛。YOLO的基本原理是:首先对输入图像划分成7×7的网格,对每个网格预测2个边框,然后根据阈值去除可能性比较低的目标窗口,最后再使用边框合并的方式去除冗余窗口,得出检测结果。OpenPose人体资态识别项目是美国卡耐基梅隆大学(CMU)基于卷积神经网络和监督学习并以caffe为框架开发的开源库。可以实现人体动作、面部表情和手指运动等资态估计。
手语图像识别流程如图2所示。
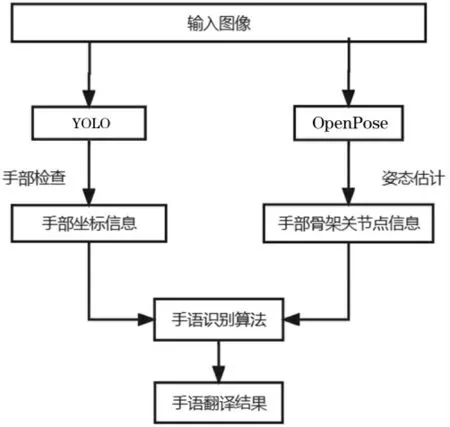
图2 手语图像识别流程图
输入图片经YOLOv5处理,检测出图片中手部所在位置,得到手部方框左上角横-纵坐标以及方框的宽-高,如图3所示。

图3 手部方框图
同时,输入图片经过OpenPose处理后,提取出图片中的人员手部骨架关节点坐标,如图4所示。

图4 手部骨架关节点图
最终用手语识别算法处理上述信息得到相应的离散的手语识别结果。
6 采用隐马尔可夫模型对离散的识别结果进行处理
HMM是一种基于贝叶斯的统计模型,主要用于处理基于时间序列或状态序列的问题。早期HMM在语音识别和手写字体识别中得到了良好的识别效果。基本的HMM技术,可以处理单个的时间序列特征向量。而手势识别面对的是更加复杂的手势信号,包括手形和运动轨迹等。因此,在手势识别中,需要采用合适的数据融合方法对各种手语信息进行有效融合。一般在模式识别领域常用的数据融合方法有2种,一种是特征层融合,就是把多个数据流的特征向量组合在一起构成一个新的向量;另外一种就是分类器融合。多数据流模型可以独立地处理多个数据流,每个数据流独立地进行训练,并允许数据流之间异步。同时在手语识别方面,Deng和Vogler提出利用并行HMMs来扩展可识别的手语词汇量,实验说明Pa HMM比传统HMM在识别方面更具鲁棒性。
在多流HMM中各个数据流是相互独立处理的,每个数据流独立地进行训练,在识别时按照前述对几个数据流进行融合,再计算与每个模型的匹配概率,匹配概率最大的模型即为识别结果。
7 结束语
本文提出了一种手语翻译系统设计方案,使用YOLOv5和OpenPose开源库对图像进行识别。系统采用了C/S架构,服务器在云端部署,多台客户机可同时工作。使用YOLOv5得到图片中手部位置坐标,使用OpenPose提取图片中手部骨架关节点坐标。这些信息作为手语识别算法的输入,最终输出手语对应的文字。接下来将进一步探寻手部骨架关节点坐标、手部位置与手语之间的联系,设计出合适的手语识别算法。
