基于LSTM-BP组合模型的南太平洋海流流速预测
2022-08-30袁红春张天蛟
袁红春,管 琦,张天蛟
(上海海洋大学 信息学院,上海 201306)
引 言
海流变化对人类生产活动和海洋生物有着很大的影响,所以认识海流变化对航海、发电和鱼群分布研究等有着极其重要的意义。海流变化对全球气候调节也有着很重要的影响。南太平洋是全球海洋的重要组成部分,研究南半球海流能够帮助研究者更好地了解全球海流变化情况。由于南北半球海流相互作用,了解并预测南半球海流变化有助于对北半球海流的研究。海流变化主要是通过海流流速体现。
海流流速预测主要分为三类,海洋模式预报方法、时间序列模式和神经网络模型预测。刘子洲[1]用HYCOM模式对太平洋环流进行模拟,对太平洋海域进行流场模拟和季节性分析,计算主要海流的流速、流幅和流量,模拟结果较好。Wu X G[2]等人将流体动力学(CFD)模型与非结构化网格有限体积沿海海洋模型(FVCOM)结合预测小规模的沿海流量。CFD模型可以解析小规模的流量,FVCOM可以预测大范围的环流,效果能够捕获从几厘米到几百公里的空间尺度的流量。黄奇华[3]等将BP神经网络技术与空间插值方法相结合,建立了海流的BP神经网络插值模型,对实测数据进行缺失值的插值仿真。结果表明该模型预测效果良好,并且优于反距离权重法和线性插值法。董世超[4]考虑到海流流速的线性和非线性关系,结合ARIMA时间序列预测模型和BP神经网络预测模型的优点,构建ARMA-BP神经网络混合模型,提高了海流流速预测的精度。Chiri H[5]等以墨西哥湾为例使用自回归逻辑回归模型对洋流模式进行统计模拟,该模型再现了原始时间序列的年内和年际变化,显示出非常好的拟合能力。
本文结合LSTM时间序列预测模型与BP神经网络模型非线性的特点,构建了LSTM-BP神经网络组合模型对南太平洋海流流速进行预测。通过分别与BP和LSTM单个模型对比,组合模型预测效果更好。
1 材料与方法
1.1 数据的选择与处理
海流的流速分为经向流速和纬向流速,经向流速是海流的南北方向,纬向流速是海流的东西方向。本文选择亚太数据研究中心SODA3.3.1版本的月平均纬向流速作为研究对象,流速为正值的是向东流,流速为负值的是向西流动。按照1°×1°的分辨率采集了2004年1月—2015年12月共12年的数据,经度范围是(110°E~135°W),纬度范围是(5°S~40°S),深度共有24层,最小深度5.03 m,最大深度524.98 m。流速(u)是海流的东西流速,单位是m/s。每条数据包含时间索引、经度、纬度、深度和流速。
流速数据存在较多空值,不完整的数据会影响数据建模的预测效果。如果选择直接剔除,可用的数据量减少,也会导致模型训练的效果较差。在考虑到海流数据之间相关性较高,选择K近邻法(KNN)填充空值,预测效果会更为准确。
KNN是一种基于类比的算法,其基本思想是在多维空间中根据欧氏距离找到与待测样本最近邻的K个点,并根据这K个点的值加权平均估计样本的缺失数据。KNN用于回归估计即以这K个点作为训练样本来估计待测点的值[6]。欧式距离公式如下:
(1)
其中,xi,xj分别代表两个样本;a代表第几个特征值。K的取值对于K近邻模型有着重要意义,过大会导致泛化能力降低,过小会导致预测精度降低[7]。通过多次试验本文K值选择6较合适,由于数据集较大,故采取了分批填充数据的方法。
为减小输入样本的数值差距,提高网络模型的收敛速度和稳定性,对数据做归一化处理,归一化数据的取值范围是[-1,1]。经过归一化处理的数据仍会保留原来数据中存在的关系,但可以消除不同量纲和数据取值范围的影响[8]。预测之后,为了使预测数据符合实际的范围和真实的意义,还需对预测结果进行反归一化。归一化的公式为:
(2)
式中,X是原样本数据;max是样本数据的最大值;min是样本数据的最小值;X′是归一化数据。
1.2 LSTM-BP神经网络建模
1.2.1 BP神经网络
BP(back propagation)神经网络是由正向传播和反向传播组成[9],正向传播见公式(3)。正向传播时,将输入样本数据传到输入层,通过每一个隐含层处理后,再将处理后的数据传向输出层。如果输出层的输出值与所期望输出值不相符,则将误差传入反向传播。误差的反向传播是逐层反转的,将误差分摊给各层的所有单元,使各层获得误差信号并修正该层单元的权值。权值不断调整,当运行到实验设置的迭代次数或者输出误差减小到可接受范围内就停止训练。Kolmogorov理论上证明三层神经网络即可以实现任意复杂的非线性映射问题[10]。
(3)
其中,x是输入向量;h是隐含层输出向量;y是输出层向量;f表示激活函数;w1、w2分别表示输入层和隐含层的连接权重;b1、b2分别表示输入层和隐含层的阈值。
图1是BP神经网络由输入层、隐含层和输出层组成。
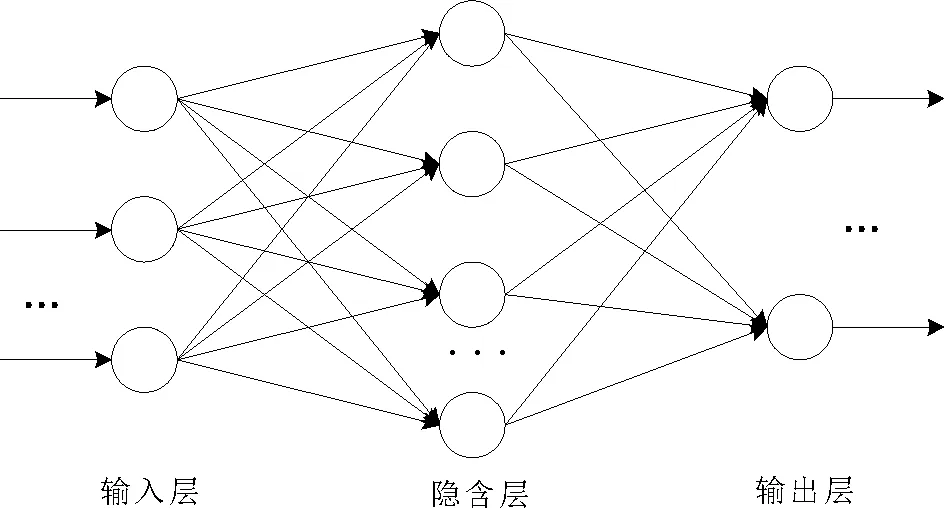
图1 BP神经网络的基本结构
1.2.2 LSTM神经网络
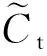
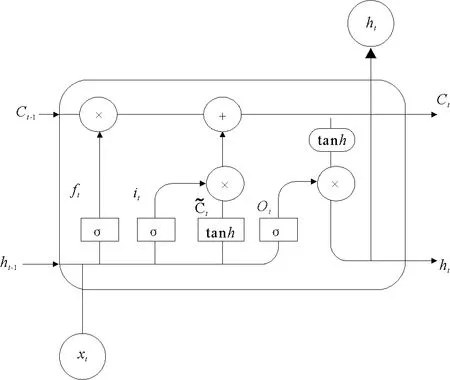
图2 LSTM记忆单元结构
ft=σ(Wf·[ht-1,xt]+bf)
(4)
it=σ(Wi·[ht-1,xt]+bi)
(5)
ot=σ(Wo·[ht-1,xt]+bo)
(6)
(7)
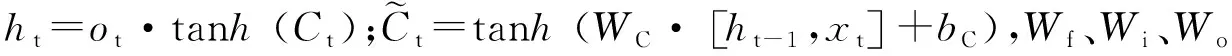
在实际预测中,采用历史数据作为LSTM网络的输入,经过网络的迭代计算和训练,不断更新记忆单元的状态,从而通过历史数据预测未来数据的变化。
1.2.3 LSTM-BP神经网络模型建立
本文将2004年1月—2015年12月12年按照10∶1∶1分为训练集、验证集和测试集。以2004—2013年的月序列数据来构建模型,用2014年的各月数据来调节超参数;再将132个月的序列数据重新拟合模型,并根据所建立的模型对2015年各月流速进行预测。基于LSTM-BP组合模型[12]预测海流的步骤如下:
1)将归一化的训练样本数据{X1,X2,…,XL}输入到LSTM神经网络中,其中Xt={lat,lon,depth,u}。利用LSTM记忆单元结构特性,提取数据变化的时间维度特征。LSTM隐含层包括L个时间序列的LSTM细胞,隐含层的输出为P={P1,P2,…PL},Pt=LSTMf(Xt,Ct-1,Ht-1),其中Ct-1,Ht-1分别是前一个样本隐含层的细胞状态和输出,LSTMf是LSTM的前向计算函数;
2)将LSTM网络隐含层的输出作为BP神经网络的输入数据,实现LSTM到BP的数据传递;BP网络的真实输出与理论的输出的均分误差作为误差计算公式,通过梯度下降法不断调整网络的权值和偏置,使得网络误差不断降低;
3)当误差满足要求时,模型停止训练,将训练好的模型对测试样本进行预测。
实验所搭建的LSTM-BP的网络结构见图3。
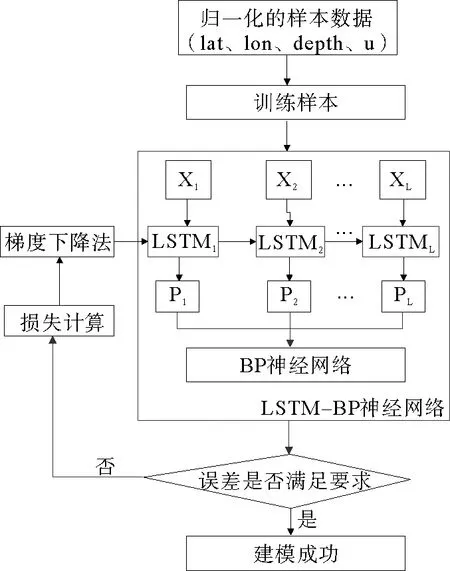
图3 LSTM-BP组合模型
在LSTM-BP神经网络建模过程中,将训练样本划分为训练集和验证集进行训练确定神经元、学习率等超参数等。其中神经元的个数是影响神经网络模型输出结果好坏的重要因素[13]。如果神经元个数太少,模型不易拟合。如果神经元个数太多,模型泛化性降低。本文选择BP神经网络的隐含层神经元个数为4~12比较预测结果的均方误差(MSE)和拟合优度(R2),公式见(8)、(9)。MSE的值越小,说明该模型模拟的实验数据具有更好地精确度。R2函数提供了一种衡量模型预测未来样本的可能性的方法,趋近于1说明模型越好。
(8)
(9)
从表1可见,神经元个数逐渐增加,2014年验证集的数据预测结果的R2逐渐接近1,但是神经元个数大于8时MSE较为上升。经过比较,我们选择8为BP隐含层神经元个数。
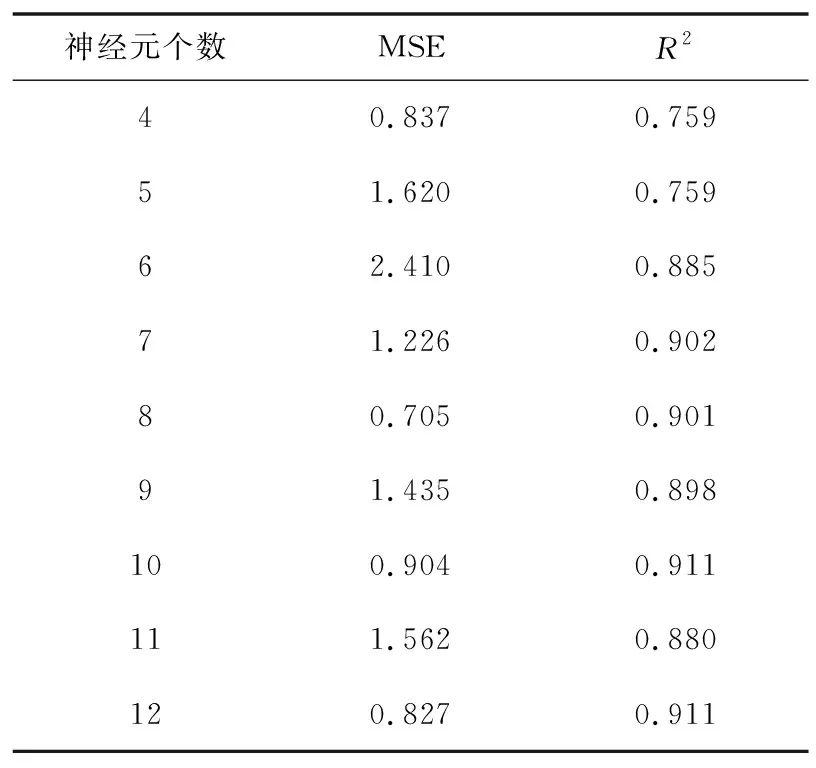
表1 BP隐含层不同神经元个数的预测结果比较
将处理好的数据传入到LSTM神经网络中,LSTM包含1个隐含层,神经元个数为4,隐含层输出形式(batchsize,1,4);BP神经网络包括1个隐含层和1个输出层。隐含层的神经元个数为8,激活函数为tanh函数,BP隐含层输出形式为(batchsize,1,8),最终模型的输出层以(batchsize,1,4)形式输出预测值。
本模型的损失函数以均方误差定义,在梯度优化算法上选择了Adam,学习率设置为0.001。批处理大小batch_size设置500,最大迭代次数200。另外,该实验设置了当被监测的数量不再提升,则停止训练,防止模型过拟合和减少不必要的训练时间。
2 结果与讨论
2.1 结果分析
为了验证LSTM-BP模型优越性,选择单个模型BP与LSTM与其比较。BP与LSTM参数都是经过实验多次调整得到的最佳参数。BP模型是4-12-4结构,隐含层激活函数是tanh函数,网络学习率为0.01。LSTM模型输入4维的训练样本,隐含层神经元个数为12。两种模型在梯度优化算法上选择了Adam。设置迭代次数200,每次训练500个样本,损失函数以均方误差定义。
数据样本在BP、LSTM和LSTM-BP三种模型上训练集和验证集的损失值下降情况见图4。横坐标是训练的迭代次数,纵坐标是损失值。图4即损失值变化情况,随迭代次数的变化,三种模型的损失值逐渐下降,训练集与验证集的损失值曲线基本重合,说明模型泛化能力较好。BP模型迭代200次停止训练,最后1次的训练集损失值为9.263 2×10-4,验证集损失值为8.876 7×10-4;LSTM模型迭代200次停止训练,最后1次的训练集损失值为5.987 1×10-4,验证集损失值为5.731 1×10-4;LSTM-BP模型迭代180次停止训练,最后1次的训练集损失值为5.620 2×10-4,验证集损失值为5.141 8×10-4。通过对比,组合模型相比于两种单个模型收敛速度更快,损失值也有明显的下降,泛化能力更好。
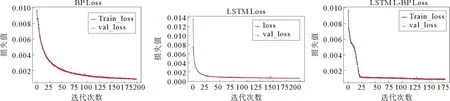
图4 损失值变化曲线
本文采用MSE和平均绝对误差(MAE)评估海洋流速模型,MSE的值越小,说明该模型模拟的海洋流速数据具有更好地精确度。MAE是绝对误差的平均值,能够很好地反应该模型预测值误差的实际情况。MSE见公式(8),MAE计算公式如下:
(10)
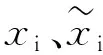
表2是三种模型的在测试样本上的MSE对比。由表2可见,LSTM-BP模型比BP模型大下降了约0.7,比LSTM下降了约0.5。表3是三种模型的在测试样本上的MAE对比。由表3知,LSTM-BP模型比BP模型大下降了约0.14,比LSTM下降了约0.21。综上,组合模型LSTM-BP综合了BP和LSTM单个模型的优点,预测精度更好,预测误差更小,预测结果相对准确和稳定。
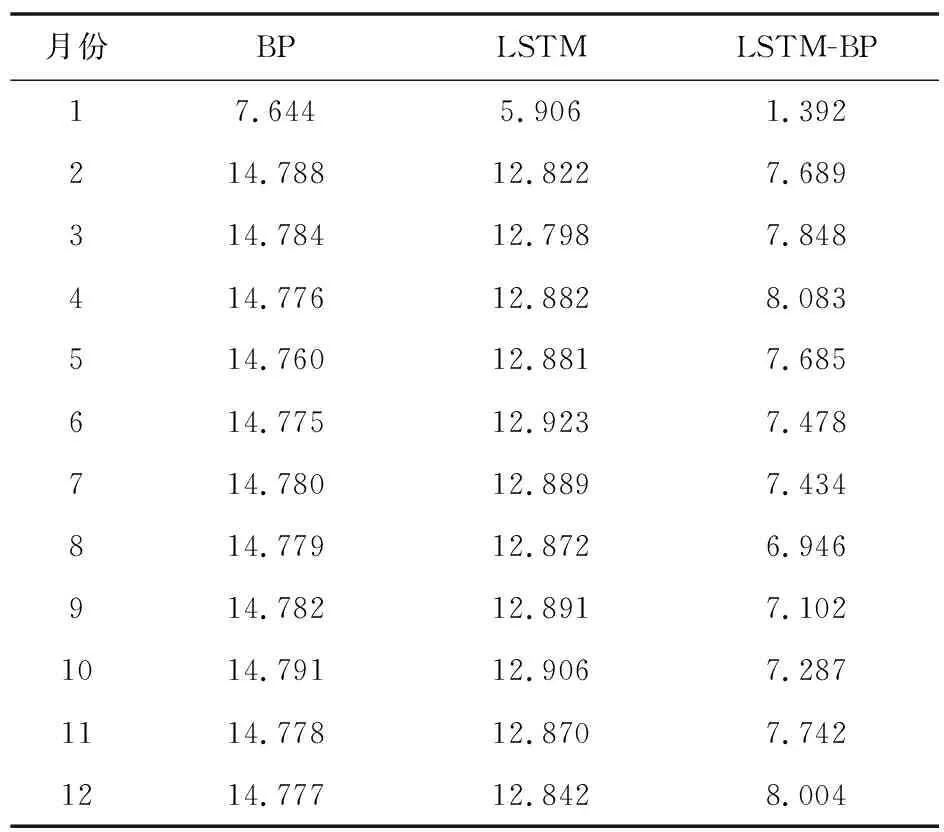
表2 三种模型预测结果MSE对比
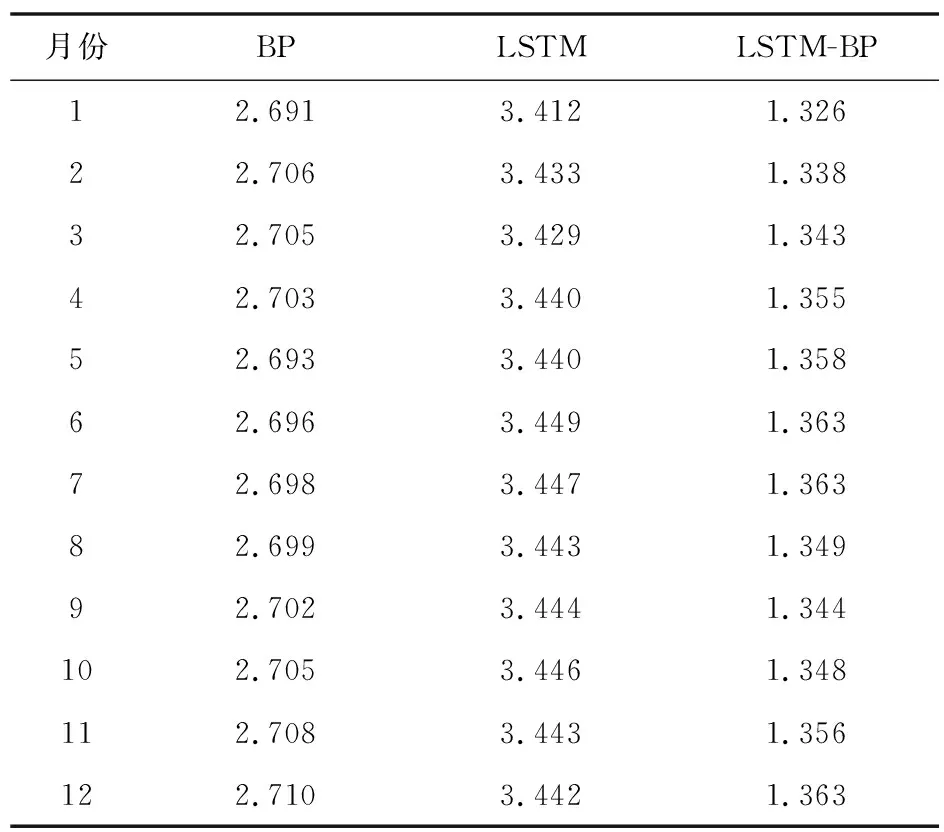
表3 三种模型预测结果MAE对比
2.2 讨论
目前,海洋环流预测的主要海洋模式有POM、FVCOM和HYCOM等。一般海洋动力模式必须给出初始条件和边界条件,但是获取边界条件比较困难[14]。FYCOM[15]主要适用于近岸海域的数值模拟,HYCOM[16]更加适用于开阔的大洋的数值模拟。海洋模式是对不同海域主要海流的流速、流幅、流量等进行计算,模拟海洋主要流场,无法对大洋某一段时间的某一个观测点预测。
时间序列法和神经网络预报法是利用已有的观测数据为样本进行预测,避免考虑所在海域是近海岸还是开阔大洋,而且减少了海洋模式的大规模计算,并且时间序列法和神经网络在预测海洋温度和海洋盐度等方面预测效果较理想。ARIMA模型拟合数据需要判断数据是否为高斯白噪声,如果不是,那么就说明ARIMA模型可能不是一个适合样本的模型,本文中的海流数据经过LB统计量检验,证明数据为非白噪声,ARIMA模型不是一个适合南太平洋海流数据的模型。刘军亮[17]建立小波神经网络对中国南海某近海观测站进行短时预测,但是小波神经网络主要提取的是时间尺度的信息。BP神经网络和LSTM神经网络分别属于前馈神经网络和循环神经网络。BP神经网络实现了一个从输入到输出的映射功能,具有较强的非线性映射能力,但不考虑输入与输出在时间上的滞后效应。循环神经网络RNN对时序性数据有着更好地适应性,LSTM是对RNN的改进,避免了RNN的梯度爆炸和消失的问题。LSTM可以选择性的将有用的信息通过,使得记忆细胞能够保存长期信息。海流流速既有时序性特征,又有非线性特征。如果只采用某一种模型,难以反映时间序列及非线性的两种特性。本文采用的LSTM-BP组合模型预测海流,LSTM网络记忆能力强,具有较长时间范围内的记忆功能,而神经网络具有非线性的结构特性,可用来模拟空间分布特征。
3 结论
神经网络模型目前在海洋领域方面的预测越来越多。本文利用SODA3.1.1版本的南太平洋区域12年的逐月海流数据,用LSTM-BP神经网络方法预测海流变化。研究结果表明,LSTM-BP适合南太平洋海流流速的预测。由于采集的数据存在缺失值,并且海流受多方面因素(风速、温度和盐度等)影响,对海流预测不能达到很高的准确率,故下一步研究工作的重点是收集更多影响海流的数据和不断优化网络模型。
