基于手机的OCR测试集构建及自动化评估模型
2022-08-29曹慧静
曹慧静
(传音控股技术有限公司,上海 202106)
0 引 言
针对人工智能,训练数据量的大小和丰富性决定了其准确性,因此数据集的构建对识别的准确性非常重要。针对印度市场用户语言翻译的问题,引入了选区翻译功能(用户在当下使用的界面上可以选择需要翻译区域进行翻译)。根据用户选中的内容图像识别成文字,再把文字翻译成需要的目标语言,用户选中的区域内容根据用户的使用场景和用户的偏好而不一样。选区翻译相比竞品有其优势,能够不中断用户当前使用页面的阅读体验,而把需要翻译的内容直接覆盖在选中区域原文上,而不影响其他未选择区域的阅读,使得翻译体验更加便捷。
1 OCR 技术现状研究
OCR(Optical Character Recognition)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。
OCR 识别应用很多场景,例如OCR 视频文字识别、人脸识别、身份证件识别、票据识别、车牌码识别、银行卡识别等等,在业界也属于比较成熟的应用;但是对于小语种OCR 识别能力应用于翻译场景有待继续提升和挖掘。OCR整体识别的流程如图1所示。
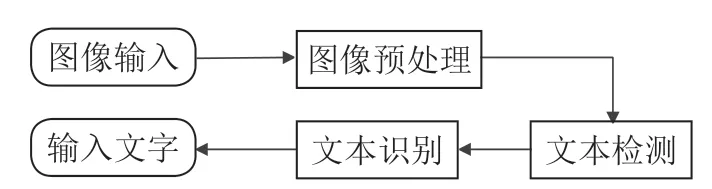
图1 OCR 整体识别的流程
图像预处理。通常是针对图像的成像问题进行修正。由于深度学习的发展,现在普遍使用基于CNN 神经网络的特征提取手段,得益于CNN 强大的学习能力,配合大量的数据可以增强特征提取的鲁棒性。常见的预处理过程包括:几何变换(透视、扭曲、旋转等)、畸变校正、去除模糊、图像增强和光线校正等。
文字检测。即检测文本的所在位置和范围及其布局,框选出图像中的文本区域,通常也包括版面分析和文字行检测等。文字检测主要解决的问题是哪里有文字,文字的范围有多大。
文本识别。是在文本检测的基础上,对文本内容进行识别,将图像中的文本信息转化为文本信息。文字识别主要解决的问题是每个文字是什么,识别出的文本通常需要再次核对以保证其正确性,文本校正也被认为属于这一环节。
文字识别包括以下几个步骤:特征提取和降维—分类器设计—训练—后处理;
2 针对手机终端上图像测试构造方法
根据用户在手机终端真实的使用场景,不同用户在不同界面用户翻译的需求是不一样的,翻译的页面元素类别不一样,翻译的选区大小也会有差距,需要贴合用户的真实使用场景构造测试数据集。同时针对印度市场应用和用户的使用习惯;印度市场语言人口使用排行榜如下:印度语—孟加拉语—古吉拉特语—奥里亚—阿萨姆语—克什米尔语。印度手机销售市场,受教育程度低,每四个人中就有一个文盲,无法顺利完成阅读和书写,因为基于手机目标销售市场的小语种和用户真实使用的场景来准备测试集至关重要,用户场景基于以下几个维度来分析:
图像大小:根据选区翻译的用户使用场景,选区翻译的大小需要覆盖几种典型的不同比例的大小,例如:选区翻译界面是手机界面全屏、是手机界面1/4、是手机界面1/2、是手机界面3/4、是手机界面1/3、是手机界面2/3、是手机界面1/5 等。
图像元素分析:在手机终端上,不同的用户使用场景,界面包含的元素是不一样的,和APP 设计和内容强相关。经过在不同用户场景下分析手机终端上界面元素,大体上分类以下几类:纯文本型、图片型、视频型、图片型文字、纯文本和图片组合、纯文本型和视频型组合、纯文本和图片型文字组合等几种场景。
图像上文本内容特征分析:经过分析手机不同用户场景,不同场景的文本,其文本内容特征也有比较大差异。图像上文本的内容特征也影响文本提取的准确性,因此测试集包含的文本内容特征越丰富,其准确性就越高。根据手机终端本文特征分析,测试集的文本特征应包含以下集中特征:不同的标点符号(: , .? ; / “”- & # ~ ...)、不同字体大小、字体加粗、项目符合、数字和文本的结合、金钱符号($)、不同语种混合(中英混合等)等等。
用户场景APP 需求分析:根据用户的选区翻译需求,需要覆盖不同的类型的应用场景,满足不同的翻译诉求。手机终端上的APP 大致可以分为几大类:新闻阅读类APP,社交类APP,电子读书类APP、视频类APP、游戏类APP、购物类APP、银行类APP,其中购物类APP、游戏类APP、银行类APP 偏工具类使用,对翻译的诉求理论上不是特别大,因此需要重点覆盖新闻阅读类APP、社交类APP、电子读书类APP 都是偏沉浸式阅读体验类APP,需要重点去覆盖。
印度市场各类APP 基本与国内市场相同,除了金融投资领域,各行各业基本都有相应的互联网服务,印度市场APP 有自己独立的本土化的APP。
阅读类APP:Daily hunt、谷歌News、FK、Inshorts、Prime Video、Netfix、Linkin 等。 交流场景:Whatsapp、Facebook、Outlook、Uber、Mail 等。观影场景:YouTUbe、Prime Video、Zee5、Hotstar、OOT 等。
根据上述分析后,手机终端OCR 文本识别再翻译的算法模型测试集构建方法如图2所示。

图2 印度手机终端OCR 测试集构建方法
3 针对手机终端界面OCR 识别评估模型
准对不同的OCR 使用场景,评估维度会有差别,大体上分为以下两种:字符准确率、召回率和整行准确率、召回率。
字符准确率:即识别对的字符数占总识别出来字符数的比例,可以反映识别错和多识别的情况,缺点是无法反应漏识别的情况。
字符识别召回率:即识别对的字符数占实际字符数的比例,可以反映识别错和漏识别的情况,但是没办法反应多识别的情况,可以配套字符识别准确率一起使用。
文本行定位为的准确率和召回率:同字符识别的准确率和召回率。主要反应文本行定位的指标,是OCR 算法的重要指标;一个字段算一个整体,假如100 个字分为20 个字段,里面错了5 个字,分布在4 个字段里,那么识别率是16/20=80%。
针对用户场景的测试集构建之后,在手机终端阅读类APP 上,为了更好体现OCR 文本识别后体可读性,提出OCR 识别的句准率统计方法,同时除了计算句准率之外,为了更直观看到OCR 句准确率、OCR 识别性能以及错误的情况。提出手机终端页面OCR 识别评估模型如图3所示。
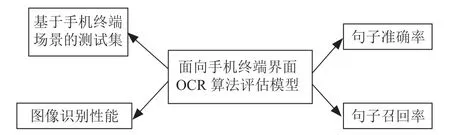
图3 OCR 算法屏幕模型
其中图像识别性能影响手机终端页面翻译体验的时间,OCR 识别性能越好,基于OCR 应用的印度等小语种翻译速度越快,体验越好,因此图像识别性能也是基于面向用户手机终端OCR 模型质量的关键指标之一。
4 OCR 评估模型自动化实测试实现方法
根据上一章节提出的OCR 评估模型,无法高效的通过人手动统计方式来实现,为了提高统计的效率和准确性,需要开发一套OCR 评估模型的自动化实现方案,如图4所示。
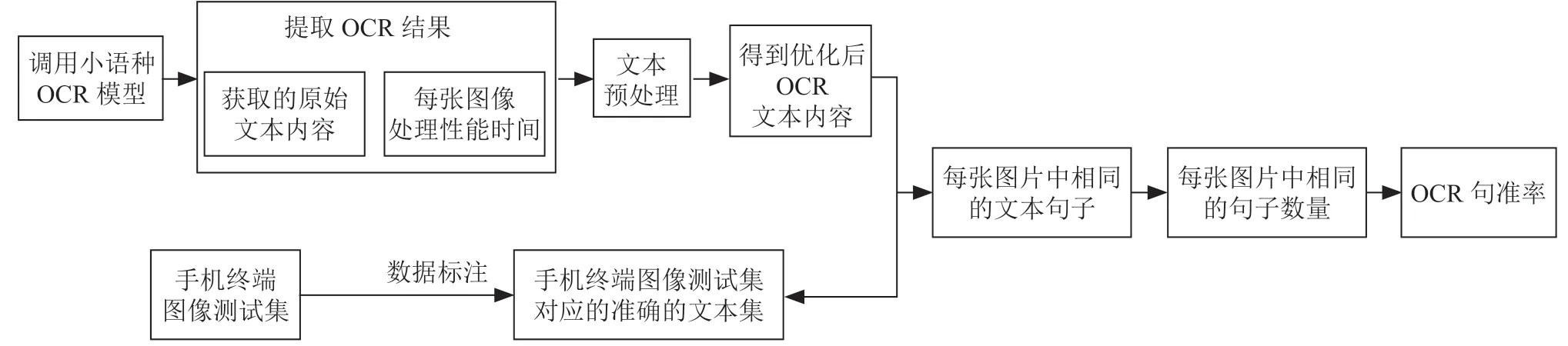
图4 OCR 评估模型自动化实现方法
OCR 识别的关键指标中图像识别性能的计算方法,调用小语种OCR 模型后,根据开始读取每一张图片的时候,记录每一张图片开始读取的时间,以及图像文本识别完之后的时间,通过计算两者的时间差即为每张图片的文本识别性能。在同一手机上,图像识别的时间的大小和图像大小以及和含有的文本内容数量强相关(图像大小覆盖在第3 章节介绍中有覆盖到),图像中包含的文本信息内容越多,OCR 识别的时间就越长,反之。不同的手机上,OCR 识别性能还和手机芯片平台强相关,手机芯片性能越好,OCR 识别性能越好。
OCR 性能的关键性能指标中句准率/召回率体现文章中句子的准确性,句子是文本中相对较小的单位,句准率越高越能体现OCR 的模型和算法的优劣,为了自动化计算文本的句准率需要准备每一张图像测试集对应的文本集,OCR识别到的文本后通过标点符号进行切分统计,通过逐一对比OCR 识别的文本和测试集对应的文本集对比是否匹配,通过句准率计算模型的平均准确率是在60%左右。
同时为了测试和研发方便查看,把以上相关的测试结果通过自动化写到同一张Excel 表中统计显示如图5所示。
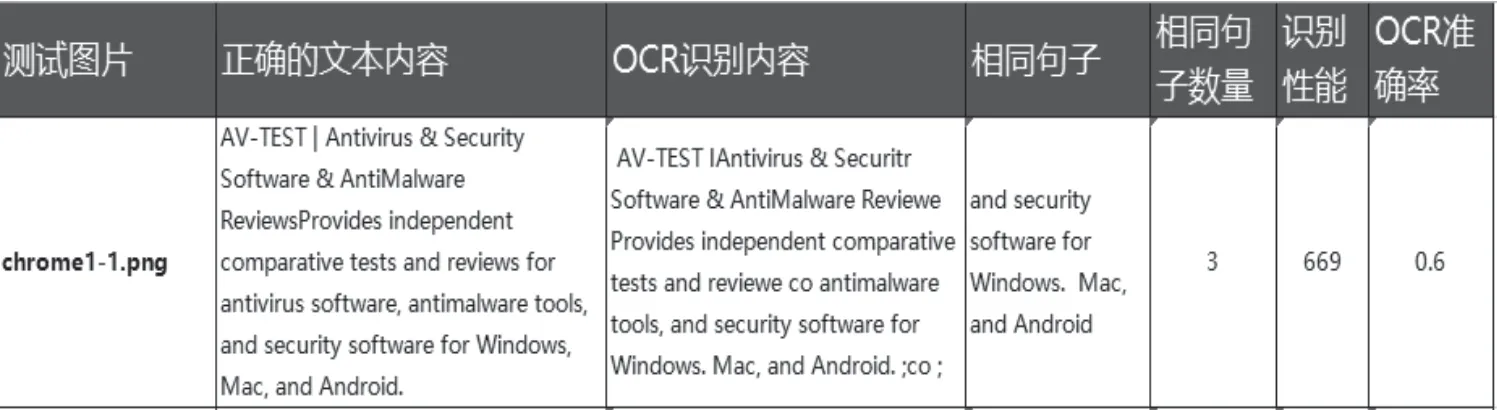
图5 测试结果
对测试集中的每一个测试图像中的句准率和性能数据有了很好的对比和参考;通过该自动化方法评估OCR 模型优劣。
5 结 论
根据用户场景来构建测试集,对OCR 模型和算法的准确率至关重要。没有符合目标用户场景的测试数据,无法度量模型和算法的优劣,因此需要研究用户场景中的用户习惯和用户的偏好,针对用户场景的测试集才能更好地发现用户场景的问题,提升用户场景的体验。因此提出了基于手机终端用户场景OCR 测试集的构建的方法,如果是针对某单一用户使用场景则需要去针对性地去根据用户体验或者人因分析后再构造该特定场景的测试集。基于该测试集提出了适合手机终端的OCR 识别的评估模型:基于用户手机终端场景的测试集、更好体现句子可读性的句准率/召回率来度量准确率、影响使用性能体验的OCR 图像识别性能以及该OCR 评估模型自动化实现。
