基于EEMD的融安方言语音合成算法研究
2022-08-25王学松王世刚郭毅峰
王学松 王世刚 郭毅峰
广西科技大学 电气电子与计算机科学学院,广西柳州 545616
0 前言
语音属于非线性信号。在提取语音特征的过程中,不可避免地会丢失一些细节信息[1],主要原因是提取特征参数的方法对于非线性信号处理能力较弱。融安县地处广西北部地区,县内共计25万余人,居民对外的通用语言是西南官话,对内使用的方言包括:百姓话、阳山话、麻介话等[2]。其中百姓话是融安地区最流行的方言。百姓话具有18个声母,75个韵母,9个声调,这导致其发音种类多且复杂。因此,增强语音特征参数提取算法对非线性信号的处理能力,最大限度地保留语音细节信息是改善融安方言语音合成效果的关键[3]。
通过改进特征参数的提取算法能够提高特征参数对信号的划分精度。以往对改进特征参数提取方式的研究包括:利用语音信号的声道特征和人耳听觉感知特征与梅尔频率倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)相融合来提高模型的鲁棒性[4];将MFCC与信号轮廓相融合来描述声音信息,提高特征参数的提取精度[5];采用耳蜗滤波倒谱 系 数(cochlear filter cepstral coefficients,CFCC)代替MFCC参数,以提升系统的性能[6];提出基于F比对MFCC进行加权优化,有效提升系统的抗噪性[7];将MFCC与短时傅里叶变化(short-time fourier transformation,STFT)特征融合构成新的特征参数,提高特征参数对信号的划分精度[8],提出了一种具有融合策略多触点的MFCC参数[9],提高了在噪声环境下系统的语音识别精度等等。以上研究表明,通过改进MFCC的提取过程,或是采用其他参数代替MFCC,可以提取高精度的特征参数。
为了进一步加强语音特征提取算法对非线性信号的处理能力,本文提出将集合经验态分解(ensemble empirical mode decomposition,EEMD)算法融入提取语音特征参数的过程中,将语音信号分解成若干线性分量,即固有模态分量(intrinsic mode functions,IMF),从而提高对语音信号的划分精度,保留更多细节信息。实验结果表明,采用本文算法合成融安方言语音的MFCC参数的均方根误差(root mean squared error,RMSE)明显低于传统算法,并且能够保留更多融安方言语音的细节信息,取得了较好的合成效果。
1 融安方言语音特征分析
融安地区使用百姓话的范围广泛,包括泗顶镇、大良镇、长安镇等,使用人口近20万[10]。具体分析如下:
(1)声母系统:声母分类如表1所示。

表1 声母分类
(2)韵母系统:韵母分类如表2所示。

表2 韵母分类
其中,单元音韵母[a]发音时舌位偏夹,带鼻音韵母[i ŋ ]中的[i]实为[I],记作[i],复元音韵母[ik]与韵母[i ŋ] 相近,并且阴声韵母、阳声韵母、入声韵母的差异较大,发豪韵的字和发歌韵的字基本相混。
(3)声调系统:声调分类如表3所示。
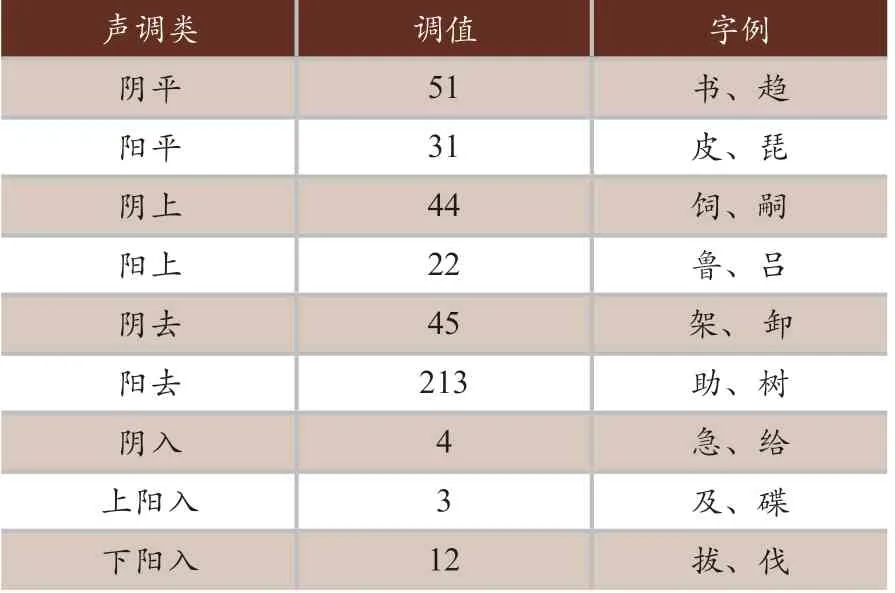
表3 声调分类
其中,在全浊声母上声字中大部分属于归阳去,少部分则属于归阴去。次浊声母上声字中有2/3属于阴上和阴去,剩余1/3属于阳上。浊声母中的入声字大多数属于上阳入,其余属于下阳入和阴去。清声母中入声字属于阴入。
通过上述分析可知,百姓话具有较多的韵母和声调,从而能够表达更多、更复杂的信息,语音信号也相对更复杂。描述语音信号的特征参数直接影响合成系统的性能,需要提高特征参数提取算法对语音信号的划分精度。
2 融安方言语音合成算法
2.1 MFCC特征参数
常采用LPC参数合成语音,并通过比较MFCC参数的RMSE指标来评价合成效果。Mel频域尺度能描述人耳的频率特性[11]。提取MFCC的过程如图1所示。
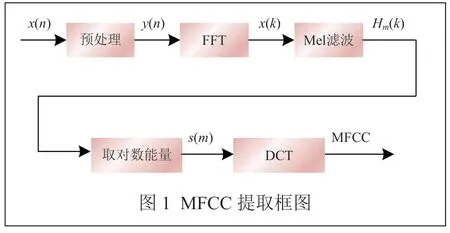
(1)预处理:由于语音信号包含的信息量较大,因此需要进行加窗、分帧等处理,将语音信号切分成小段。加窗主要采用汉明窗,其函数w(n)表达式为:
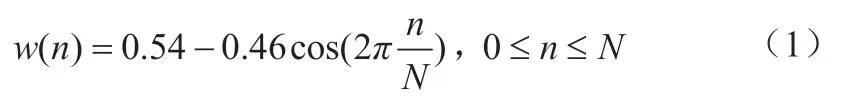
其中,N——窗函数的尺度。
经过汉明窗卷积后的语音帧信号为:

其中,y(n)——卷积后的语音帧信号;
x(n)——卷积前的语音帧信号。
(2)频域转换:通常是在频域内分析语音信号,通过快速傅里叶变换(fast Fourier transform,FFT)将语音信号由时域转换为频域,具体过程如下:

其中,X(k)——转换后的频域信号。
(3)Mel滤波:采用Mel滤波器组消除语音信号中的谐波,其函数Hm(k)的表达式为:
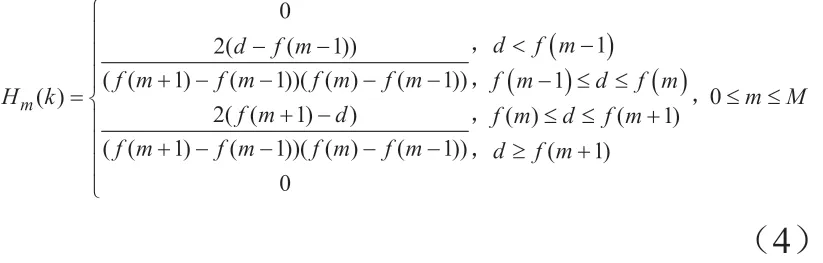
其中,M——Mel滤波器组包含滤波器的个数;
d——滤波器组对比参数。
其函数表达式为:

其中,fh——语音信号最高频率。
滤波过程为:
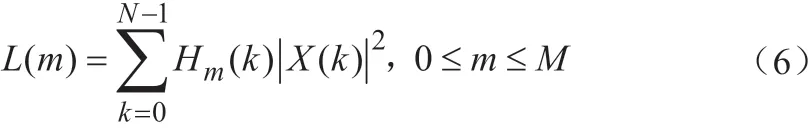
其中,L(m)——经Mel滤波后的频域信号。
(4)取对数变换:对Mel滤波器组的输出结果取对数变换,得到语音信号的对数能量,其过程为:

其中,S(m)——取对数变换后的频域信号。
根据《备忘录》,联合惩戒对象为在科研领域存在严重失信行为,列入科研诚信严重失信行为记录名单的相关责任主体。联合惩戒措施将依据相关责任主体失信行为严重程度,对其采取其中一项或多项惩戒措施。43项措施中包括限制或取消一定期限申报或承担国家科技计划(专项、基金等)的资格;依法撤销国家科学技术奖奖励,追回奖金、证书;暂停或取消国家科学技术奖提名人资格;一定期限内或终身取消国家科学技术奖被提名资格等。
(5)DTC变换:采用DTC变换将对数能量转换为MFCC,DTC变换过程为:

其中,L——MFCC的阶数;
C(n)——提取的MFCC参数矩阵。
通过对上述MFCC提取算法分析发现,在对语音帧信号进行FFT变换过程中,由于FFT变换对于非线性信号的处理能力较弱,从而导致提取的MFCC参数对原始语音信号的描述能力较差。因此,为了改善FFT变换的处理效果,需要保证输入的信号是线性的或者是近似线性的。
2.2 EEMD算法
EEMD算法能够将任意一个信号按自身时间尺度特征逐级分解,目的是得到若干个线性IMF分量和一个剩余分量[12]。EEMD算法的具体步骤如下:
(1)将白噪声w(t)加入原始信号x(t)后,得到信号x′(t),过程为:

(2)采用经验模态分解(EMD)对第一步的合成信号x′(t)进行分解,从而获得n个IMF分量和一个剩余分量,第二步过程表达式为:

其中,cj(t)——各个阶段的IMF分量;rn(t)——剩余分量。
(3)循环前两个步骤,且每次执行第一步时都要加入白噪声,这些白噪声的强度一样,但是具体序列不同,第三步过程表达式为:
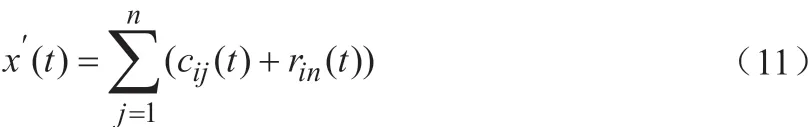
(4)对上一步求出的各阶的IMF分量取平均值,并最终得到平均后的IMF分量,第四步过程表达式为:

其中,cn(t)——取均值后的IMF;
cin(t)——每次求得的IMF。
EEMD算法的步骤框图如图2所示。

2.3 基于EEMD的融安方言语音合成步骤
考虑到FFT变换在处理线性信号时效果较好的情况,将EEMD算法、FFT变换与逆快速傅里叶变换(inverse fast Fourier transform,IFFT)三者结合,构建融安方言语音合成算法。基于EEMD的融安方言语音合成算法框图如图3所示。

本文提出的基于EEMD的融安方言语音合成算法包含两个阶段,分别是训练阶段和语音合成阶段。
(1)训练阶段:首先选取融安方言语音样本,对语音样本进行预处理,接着采用EEMD算法将语音分解为若干IMF分量,对每个分量进行FFT变换,最后对所有分量进行频率求和,并将求和后的频率数据储存在参数模板库中;
(2)语音合成阶段:首先对输入的文本进行文本分析,文本分析的目的是为了在参数模板库中找到与文本相匹配的语音参数,本文采用人工标注的方法实现对文本的分析,最后对经文本分析找到的参数进行IFFT变换,得到融安方言语音信号。
3 实验结果与分析
3.1 实验数据与设置
本文选取的是广西省融安县融安方言,具体选择了当地居民所说的百姓话作为研究对象。语音样本是在安静的环境内选用Adobe Audition CS6软件进行录制的,语音信号的采集频率为44,100 Hz,采样位深度为16 bit,并保存为.wav格式。语音样本共由8人录制,其中男5人,女3人。录制人员的年龄在20~60岁之间,共分为4组年龄段,每组2人。要求每人依次对选定的10组百姓话词语进行发音,每隔5分钟录制1次,每人录制8次,共录制640组融安方言语音样本。选取每人录制语音样本的20%作为训练样本,剩余80%则作为测试样本。测试实验分别采用LPC语音分析法和本文算法完成语音合成,并对结果进行分析。
采用MATLAB 2018a平台完成仿真。仿真系统中设定预加重系数为0.98,窗口尺度为320,帧移160。设置LPC的阶次为16,在提取MFCC参数时,设置Mel滤波器组的尺度为24,窗函数选择汉明窗。合成语音信号与样本语音信号的MFCC参数距离采用RMSE进行评估,RMSE的函数表达式为:

其中,N——语音信号具体的分帧数量;
hMFCC——合成的语音信号MFCC参数;
yMFCC——原始语音信号的MFCC参数。
3.2 实验结果与分析
分别利用传统算法和本文提出的算法对所有融安方言语音样本进行训练与合成,提取合成后的MFCC参数,计算各个词语的RMSE大小,记录平均值,如表5所示。
从表5中可以看出,利用本文提出的算法合成的融安方言语音MFCC参数的RMSE值比传统算法的RMSE值低一些。试验结果表明,改进后的融安方言语音合成算法比传统算法有7.38% 左右的性能提升,合成效果更好一些。

表5 融安方言语音词语的RMSE值
为了更好地验证改进算法的优势,需要对两种算法合成的语音信号波形图进行分析。由于语音样本数量较多,因此选择一组词语作对比。原始的融安方言词语语音波形图、利用传统算法和本文提出的算法合成的语音波形图如图4所示。
从图4中可以看出,传统算法合成的融安方言语音信号外部轮廓较为杂乱,且高频部分的还原度较低,因此语音信号失真严重,而本文算法能够基本还原外部轮廓信息,且在高频段的还原上比传统算法好,合成度与传统算法相比较高。

4 结束语
为了改善对融安方言语音的合成效果,本文提出了一种基于EEMD的融安方言语音合成算法,并选择当地具有代表性的“百姓话”作为实验对象。由于融安方言语音较为复杂,语音特征也更难提取,为了加强语音特征提取算法对非线性信号的处理能力,将EEMD算法融合进语音特征参数的提取过程中。先对融安方言语音帧信号进行EEMD分解,得到若干IMF分量;然后对所有分量进行FFT变换;再对所有的分量进行频率求和得到融安方言语音特征参数;最后利用此参数对融安方言语音进行合成。实验结果表明:本文算法合成的融安方言语音MFCC参数的RMSE值与传统算法相比降低了7.38%,并且能够保留更多的语音细节信息。
