基于改进CNN-LSTM的飞控系统剩余寿命预测
2022-08-19李梦蝶罗灵鲲胡士强
李梦蝶,赵 光,2,罗灵鲲,胡士强
1.上海交通大学 航空航天学院,上海 200240
2.中国商用飞机有限责任公司,上海 200126
故障预测与健康管理(prognostics and health management,PHM)是保障设备安全和优化维修策略的重要技术,现已在诸多领域得到应用。PHM 技术旨在利用传感器数据评估系统健康状态,为故障处理和维修决策提供支持[1]。在航空领域,飞机的维修方式已经从事后维修逐步发展成定时维修和视情维修相结合的预防性维修策略[2]。剩余寿命(remaining useful life,RUL)预测作为PHM 的核心技术,能够监测飞机系统及其关键部件的退化程度。准确的RUL预测可以避免过度维修造成的成本浪费或维修不及时造成的安全性隐患,因此开展RUL预测方法的研究对预防性维修策略的制定有重要的指导意义[3]。
设备的RUL预测方法主要分为三大类[4]:模型驱动法、数据驱动法以及模型数据混合驱动的方法。模型驱动法通过建立系统或部件的物理失效模型[5]来预测RUL,建模有助于加深对系统失效机理的理解。但由于实际运营过程中的变化因素复杂,模型驱动法一般无法考虑到系统当前状态并进行模型更新,因此难以做出动态的预测。数据驱动法利用退化监测及寿命的大量样本,给出系统未来健康状态或剩余寿命的预测。数据驱动法通过记录当前状态作为新的样本,不断调整自身参数,以实现动态预测,并使得预测更加准确。在数据驱动的RUL 预测方法研究中,现存的一大问题是不易获取大量“运行至失效”的训练数据。其他预测问题也常存在数据集缺乏的问题,常用的数据生成方法包括生产对抗网络[6]、元学习[7]等,可以根据小样本数据完成网络的训练。然而在航空领域,对于RUL预测问题,即使是小样本的真实数据依然属于航空公司隐私,因此这类方法并不适用。目前部件层级的寿命数据常通过加速试验或飞行试验获取,获取成本高昂。模型和数据混合驱动的方法[8-9]则将模型与数据方法结合起来,根据对系统的理解构建仿真模型并生成数据集,再基于数据驱动实现动态预测。因此本文采用模型和数据混合驱动的RUL预测方法,以发挥各自方法的优势。
模型驱动法可以分为两类:数学建模法和仿真建模法。数学建模法指建立系统的失效传播模型,如裂纹传播模型等,从微观层面推导公式来计算RUL,但不适合为复杂系统的RUL预测提供数据帮助。仿真模型则从宏观层面出发,建立系统相关模型,模拟随机退化状况[10],生成大量数据样本,为数据驱动的预测提供基础。利用仿真模型获取数据是解决诸多领域数据缺乏问题的常用方法,现有较成熟的研究是NASA通过对航空发动机仿真建模来模拟发动机系统的故障传播过程获取“运行至失效”的寿命数据,产生了航空推力系统仿真(commercial modular aero-propulsion system simulation,C-MAPSS)[11]数据集,被广泛用于数据驱动的RUL预测研究中。国内也有许多学者在发动机性能退化仿真和飞控系统的故障数据生成方法进行了相关研究。现有飞控系统仿真数据生成的研究仍存在难以模拟系统的退化过程,并判断系统失效时刻来获取剩余寿命标签的问题。
基于数据驱动的RUL 预测方法主要分为两大类:基于统计概率的方法和基于机器学习的方法[12]。基于统计概率的方法包括贝叶斯网络[13]、维纳随机过程[14]等。首先构建合适的健康指示因子(health index,HI)函数,选择合适的统计分布假设来描述HI 函数的退化趋势,根据大量退化数据选取合适的分布参数,最终计算出系统剩余寿命的概率。然而传统概率方法的参数量有限,因此随着退化数据维度和长度的增加,基于统计概率的方法难以提升RUL的预测准确性。而基于机器学习的研究可以解决多维数据非线性拟合的准确性问题,因此引起了广泛关注。
近期,基于机器学习的RUL预测方法相关研究中,主要包括浅层机器学习和深度学习的方法。浅层机器学习包括浅层神经网络[15]、支持向量机[16]等;深度学习网络比浅层机器学习方法结构更复杂,参数量也更多,预测结果也更准确,因此本文采用了深度学习框架。胡昌华等[17]对基于深度学习的复杂退化系统RUL 预测进行了综述性研究,阐述了四种典型深度学习技术在RUL预测的优缺点。Babu等[18]将CNN的卷积和池化层运用在时间维度上来提取多维传感器数据的时序特征,进行故障特征提取和RUL预测。但CNN的特征提取更重视局部特征,可能导致整体信息的丢失,RNN网络独特的递归结构可以帮助记忆和传递后向信息,便于处理时序数据。Heimes[19]利用扩展卡尔曼滤波(extended Kalman filter,EKF)以及遗传算法自动迭代优化RNN 神经网络参数,用于航空发动机公开数据集的RUL预测,获得了当时的最佳预测成绩。然而由于RNN网络反向传播过程存在梯度爆炸或梯度弥散的问题,带有门结构的长短时记忆网络(long short-term memory,LSTM)[20]作为一种RNN 的改进算法被提出,适用于长序列时间数据的处理。Zheng等[21]证明了两层LSTM网络和两层前馈神经网络的组合,对多维长序列时间数据的预测能力优于BABU所提出的CNN网络。Wu等[22]对比了带有遗忘门的LSTM、标准RNN 以及门循环单元(gated recurrent unit,GRU)对RUL的预测效果,证明了LSTM网络的优越性。但是由于RUL预测问题不同于一步时间序列预测问题,其训练样本是包含了空间和时间结构的序列,因此LSTM 网络在RUL 预测方面仍然存在缺点,即容易忽略多维传感器之间的空间关联特征,而可能忽略空间上的部分故障信息。
结合上述分析以及前沿技术在本文研究任务中存在的问题,本文采用仿真模型生成数据集,并选择LSTM网络进行RUL预测。综上所述,本文主要贡献有以下几个方面:
(1)针对系统退化仿真数据集的生成问题,给出了模型驱动的失效数据集生成流程,利用蒙特卡罗(Monte Carlo,MC)仿真解决了剩余寿命标签的获取问题,为数据驱动的RUL预测提供了数据基础。
(2)针对LSTM 网络在RUL 预测上空间特征提取不充分的问题,提出了1D-CNN-LSTM 的RUL 预测算法,并结合滑动窗口解决了训练样本不充分、维度不统一的问题,进而提高了算法的预测准确率。
1 模型驱动的失效数据集生成
针对系统退化仿真数据集如何生成的问题,本文提出了模型驱动的失效数据集生成方法,流程如图1 所示。首先根据系统的架构以及系统组成部件的数学表达式构建对应的Simulink模型;其次分析系统的典型故障模式,包括各部件的渐进型故障和突发型故障等,对故障模式进行建模并将故障注入原系统得到退化仿真模型;最后基于蒙特卡罗仿真生成随机故障时间样本,按照时间样本的序列依次注入故障,根据故障判据判断系统响应是否超出失效阈值,记录仿真失效时刻所对应的故障样本时间,作为系统的失效寿命数据;退化仿真模型最终的输出是真实系统中可采集到的多组传感器的时间序列退化数据以及记录的系统失效寿命数据。
1.1 基于Simulink的退化模型构建
RUL预测不只是单纯地预测数据未来值,而是在此基础上预测系统中长期的性能衰退趋势以及距离失效的剩余时间。考虑到复杂系统各组成部件之间存在着冗余、耦合的高度集成关系,部件退化不一定会导致系统的失效,若仅考虑部件级的退化来进行维修决策可能造成维修资源的浪费。因此,需要通过系统建模仿真来评估部件级退化造成系统级性能退化的程度。
根据系统数学表达式和故障模式的特征表达式,可以搭建系统及其故障模式的Simulink 模型。此处不再赘述建模过程,而是更关注如何构建基于Simulink的系统退化模型。
本文利用MATLAB 和Simulink 给出了一种故障注入和退化模型的构建程序,如图2所示。在原输出与故障模式输出之间添加Simulink 模块库中的可变子系统“Variant Subsystem”,将故障模型和无故障模型添加到可变子系统内;接着在可变子系统的参数设置中为每一故障模式定义变体控制变量,并对定义的每一个控制变量设置唯一的控制条件,通过在MATLAB 中改变控制条件即可达到选择故障模式的目的。
利用故障模式建模表征部件的退化程度,通过控制故障注入程序,按照下一节的方法即可模拟系统在多种故障模式下的随机退化传播过程,达到构建系统退化模型的目的。
1.2 基于MC仿真的失效寿命数据获取
在构建了系统退化模型基础上,仍需解决系统随机故障时间及序列生成和失效时刻标签的获取问题。基于MC仿真的随机故障时间样本生成方法如下:假定系统组件故障概率服从指数分布,首先借助蒙特卡罗方法生成(0,1)之间的均匀随机数,并求解指数分布的反函数,综合(0,1)区间上的均匀随机数和反函数变换法产生服从指数分布的随机数。
记随机变量R 在(0,1)区间上服从均匀分布,部件故障时间t 是一个非负的随机变量,服从失效率为λ 的指数分布,则随机变量t 的概率密度函数为:

其对应的分布函数为:

如果随机变量t的分布函数F(t)连续,则R=F(t)是(0,1)区间上均匀分布的随机变量,取对数解得:

借助MATLAB 的rand 函数生成(0,1)区间上均匀分布的随机变量R,代入部件故障模式的失效率,即可生成服从指定分布的随机故障时间t。
蒙特卡罗仿真常被用于基于模型的安全性分析[23]中,根据概率分布随机抽样,生成系统各部件的随机故障时间样本[24],模拟部件不同故障模式的发生时刻;然后将时间样本对应的故障序列注入系统退化模型,模拟在不同风险场景下的系统响应,评估系统的各类性能指标是否符合性能要求的阈值范围,得到仿真失效时刻的时间样本值用于计算剩余寿命标签。退化仿真模型的建立和剩余寿命标签的获取为数据驱动的RUL预测提供了数据基础。
2 基于CNN-LSTM的RUL预测算法
针对LSTM 算法在时空结构数据的RUL 预测中提取空间故障信息不充分的问题,提出了1D-CNN-LSTM网络,结构如图3 所示,该网络既保证了LSTM 在预测时序数据时的优势,同时结合1D-CNN提取传感器之间的空间关联特征,以提高预测准确率。
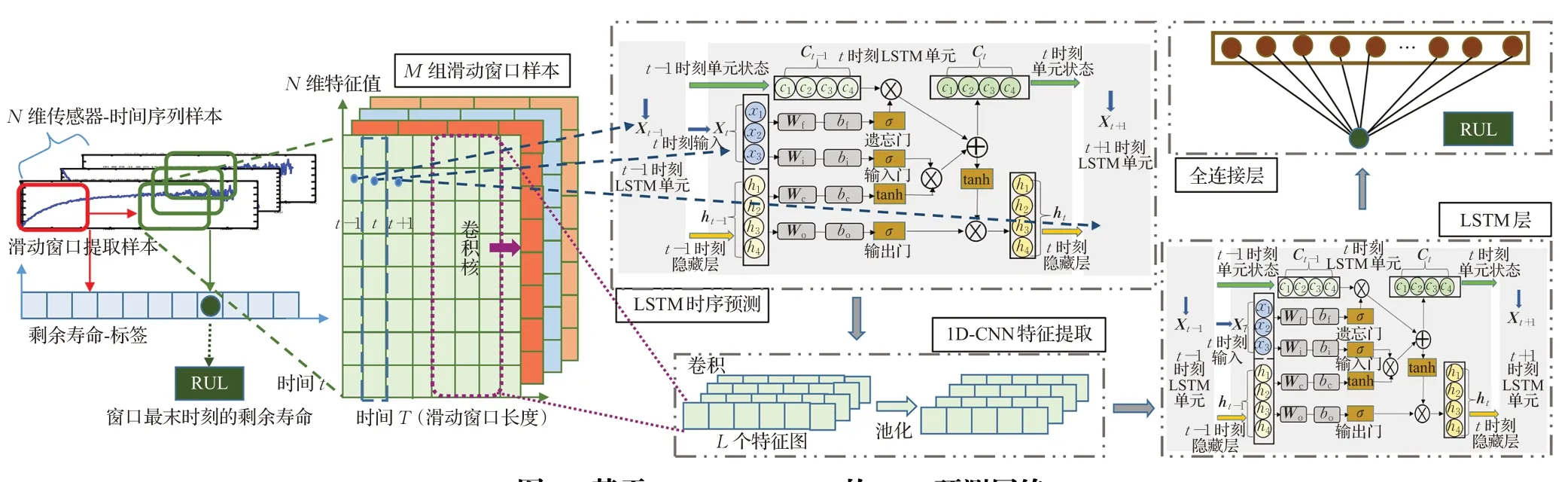
图3 基于1D-CNN-LSTM的RUL预测网络Fig.3 RUL prediction network based on 1D-CNN-LSTM
针对RUL预测问题中每一组“运行至失效”数据样本长度不等、总样本量有限的问题,采用了滑动窗口法提取等时间长度的数据样本以增加样本数量,从而减小网络的训练误差。如图3所示,样本中传感器的特征维度为N,滑动窗口的长度为T,滑动步长为1,提取的每一组样本尺寸为T×N,即可获得M组等大小的滑动窗口数据样本,每一组样本对应窗口的最末时刻的一维剩余寿命值,所提取的滑动窗口样本作为网络输入,对应剩余寿命值作为网络输出标签。
2.1 1D-CNN特征提取
CNN网络[25]相比于传统特征提取方法,在局部特征的提取上获得了很高的准确率,其权值共享的卷积核结构减少了训练参数,池化操作可以降低数据的维度。不同维度的CNN 方法在处理数据的方法上大致相似,区别在于卷积核的尺寸设置,以及其如何在数据上滑动。1D-CNN 的卷积核只在时间维度上滑动,2D-CNN 的卷积核在时间和空间的平面上按S 型滑动,如图4 为步长为1 的1D-CNN 和2D-CNN 卷积方式的区别,卷积核大小分别为8×3和3×3。
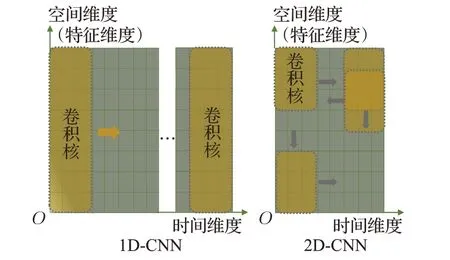
图4 1D-CNN和2D-CNN卷积方式区别Fig.4 Difference between convolution way of 1D-CNN and 2D-CNN
从图4中可以发现1D-CNN的卷积核能够对空间维度上所有的特征进行卷积,而2D-CNN可能忽略距离较远的特征之间的关联特征。考虑到RUL预测问题的输入为多维传感器,若使用2D-CNN 进行特征提取,则在数据预处理时应当尽量将具有关联故障信息的传感器邻近排布,人工经验可能对预测结果造成一定程度的影响。
因此本文选择1D-CNN 进行多维传感器数据的特征提取,第一层LSTM网络的输出作为1D-CNN网络的输入,经过卷积和池化后再输入到第二层LSTM 网络,保证了时序和空间信息的完整性。
2.2 LSTM时间序列预测
长短时记忆网络(LSTM)在时序预测方面的准确率较高。LSTM 是循环神经网络(RNN)的一种特殊变体,它通过引入遗忘门ft、输入门it和输出门ot来保存或遗忘当前信息,以达到长期记忆的功能。LSTM三组门单元的计算公式如下:

式中,Wf、Wi、Wo、WC和bf、bi、bo、bC分别为遗忘门、输入门、输出门、细胞单元(cell)的权重系数矩阵和偏置矩阵。上一时刻隐藏层的输出ht-1与当前时刻输入xt组合成新向量,与对应权重系数矩阵相乘,并加上对应偏置矩阵后,经过激活函数,即可得到对应门单元输出。
隐藏层ht和LSTM的细胞单元Ct分别用于储存短期记忆和长期记忆,计算公式如下:

遗忘门ft可以有选择地遗忘上一时刻细胞单元的信息,与输入门it和C~t求和后,共同决定当前时刻细胞单元状态的更新,输出门和当前时刻细胞单元状态的卷积决定了隐藏层的更新。
图5给出了t时刻的LSTM cell 的数学架构图,每个cell 中包含了4 个节点(unit),输入的序列特征维度为3。LSTM 通过细胞单元状态和隐藏层传递时序信息,并在时间维度共享权重系数,经过多个时间步长后,输出可以是最后一个时刻的隐藏层状态值或所有时刻的隐藏层状态值。

图5 t 时刻的LSTM数学架构Fig.5 Mathematical architecture of LSTM at time t
在1D-CNN-LSTM 网络中第一层LSTM 网络输出为所有时刻的隐藏层值,并作为1D-CNN 网络的输入,这样可以更好地保存时序信息;第二层LSTM网络输出为最后一个时刻的隐藏层以简化网络,输入到全连接层,最终输出一维标签值。此外为防止过拟合,在每层LSTM网络后添加了Dropout层,随机丢失一些节点权重。
针对LSTM 空间信息提取不足的问题,文献[26]使用了2D-CNN展平和LSTM层并联的双通道结构,将两个通道网络的输出展平并求和。该方法一方面需要保证网络的维度相等,增加了算法的复杂度;另一方面2D-CNN 和展平层可能导致信息的丢失和混乱。而本文提出的1D-CNN-LSTM 网络在解决LSTM 空间信息提取不足问题的同时,简化了网络结构,避免了不必要时序信息的丢失,提高了算法的预测准确率。
3 仿真及实例
本文以某型号飞机的横侧向飞行控制系统为例,选取典型故障模式进行故障注入,并结合MC仿真生成了仿真失效数据集,将其与数据驱动的RUL 预测领域得到广泛应用的公开数据集进行了对比,论证了本文数据生成方法能够生成具有统一标准的失效数据集,可用于不同系统的数据驱动RUL 预测。本文论述了基于1DCNN-LSTM 的RUL 预测步骤,并开展了公开数据集的RUL预测实验,讨论了方法中滑动窗口长度选取对预测准确率的影响,通过与其他网络的预测结果对比,验证了本文提出的1D-CNN-LSTM网络预测的准确性。
3.1 仿真模型设置
选取某一型号飞机的双通道三余度横侧向飞行控制系统进行建模分析[27],结合Simulink工具对飞控系统的每一部件单独建模,最后根据系统架构进行综合与集成,系统架构如图6所示。

图6 某型号飞机横侧向飞行控制系统架构Fig.6 Architecture of a lateral flight control system
考虑横侧向飞控系统机电部件[28]的渐进型故障具有逐渐演变的趋势,可能不会使得系统立刻失效,但随着故障程度的加深会造成一定危险,可以用来表征系统的退化趋势。表1 给出了飞控系统的典型故障模式及其参数[29]。按第2章所提方法进行故障注入即可得到系统退化模型,此处不再赘述。
为了确定系统的失效状态,得到失效时刻标签,应根据系统功能性质和所关注性能要求的重要程度来决定故障判据。本文采用体轴滚转角φ(t)作为性能指标,ΩZ为系统未失效(R)的状态集合,与其对应的故障判据为:

式中性能指标的阈值范围[23]取值为:

仿真所选取的工况是巡航阶段,假设飞机处于巡航阶段,所处状态点速度为178 m/s,迎角为0.216 rad,巡航高度10 668 m,架构评估时间20 s。滚转命令为幅值0.2 rad,周期0.1 Hz 的方波信号。通过比较随机故障序列注入后的性能指标值与无故障构型下理想值的差值是否超出给定范围,可以判断系统是否失效,并记录系统失效时刻。
3.2 仿真失效数据集分析
利用MC 仿真生成100 组随机故障时间,重复两次分别作为训练集和测试集,将每一部件每一种故障模式按照式(3)的故障发生时间依次排序后注入模型,直至系统故障判据失效,即可得到一个组别(id)的“运行到失效”数据。训练集中是从正常到失效的完整周期内全部时间序列的采样值,测试集中是失效前一随机时间点之前的状态参数值及其对应真实寿命。
表2为所生成的横侧向飞控系统退化数据集中每一列的含义。数据集中的退化数据是状态空间参数的传感器值,包括滚转率、滚转角、偏航率的三余度惯性测量元件(IMU)输出和舵偏角的三余度位置传感器输出。其中,为了真实模拟工程情况,将仿真时刻t按比例映射到第2章所生成的随机运营时间样本空间中,得到运营时长T;模型中传感器(IMU、位置传感器)均为独立的三个冗余架构,并根据传统三余度表决算法选择正确信号输出;每一组别的最大运营时长即为该组别的寿命值,可用于计算RUL标签。

表2 某型号横侧向飞控系统退化数据集Table 2 Degradation dataset of a lateral flight control system
为证明本文所生成的数据集在RUL预测方面的有效性,将其与航空发动机退化仿真C-MAPSS 的第一个数据集FD001 进行对比,该数据集在数据驱动的RUL预测领域受到了广泛研究与应用。如表3所示,两个数据集在构成上具有一致性,工况数和组别数相同,不过由于飞控系统和发动机系统本身存在差异性,且两者冗余程度和安全性等级的设计要求不一致,两个数据集之间也存在一些差异。

表3 飞控系统数据集与C-MAPSS数据集对比Table 3 Comparison between flight control system dataset and C-MAPSS dataset
(1)两者相同之处在于:在C-MAPSS 仿真数据集中,发动机系统关键部件的单一故障模式持续扩散并传播造成系统失效,对关键参数提取特征,能够反映出此故障在系统中的传播趋势并进行RUL 预测;在飞控系统退化数据集中,某些突发故障或多种故障接连发生后根据故障判据可判断系统失效。图7 为单一故障下系统发生失效的滚转角响应曲线。系统失效可以产生寿命标签,失效可反映在状态参数的变化中,通过提取状态参数的变化特征即可进行RUL预测。

图7 单一故障下系统发生失效的滚转角响应曲线Fig.7 Roll angle response curve of system failure under certain single fault
(2)飞控系统失效数据集的特殊性在于:
①由于飞控系统为双通道(两台主飞控计算机、两组执行机构作动器)三余度(三冗余传感器)架构,有一部分故障发生时,系统并未失效,因此其退化模型的可同时发生故障模式数较多,基于这类退化数据集的RUL预测更注重冗余架构下部件退化对系统剩余能力的影响。
②飞控失效数据集中的随机性来源于故障模式的组合以及发生故障的时间不同;而C-MAPSS 数据集中的随机性来源于发动机系统的初始磨损及各部件发生故障的程度不同。
(3)与公开数据集对比,飞控失效数据集的改进在于将仿真时刻t按比例映射到随机运营时间样本空间中,得到运营时长T。相比于C-MAPSS数据集利用仿真时间(cycle)来表示寿命,本文给出了仿真时间及更直观的运营时间来表示寿命,符合工程实际。通过失效率的调整,可以使得时间T更加符合真实情况。
(4)实际应用上,更多的工程信息可以提高模型的仿真精度,从而提高仿真数据的真实性;部件的失效率越准确,仿真数据集与真实数据的差异也越小;采用系统设计模型来进行RUL预测有助于设计的改进。
综上所述,按照本文方法生成的失效数据集和公开数据集有统一结构,能反映系统的随机退化趋势,包括数据驱动RUL预测所需的传感器状态参数数据和对应的寿命标签。此外本文通过仿真时间到运营时间的映射,使得预测工作更贴合工程实际情况。因此,本文通过解决退化模型构建及其标签获取问题,为飞控系统的数据驱动RUL 预测提供了有效的数据基础,且这一方法可以推广到不同的航空复杂系统中。
3.3 基于1D-CNN-LSTM的RUL预测步骤
下面以公开数据集C-MAPSS 为例,基于1D-CNNLSTM方法进行RUL预测。主要步骤如下:
(1)筛选数据,选择相对变化幅值较大的特征维度,它们的变化更容易反映当前系统的健康状态。因此选择了“仿真时间cycle;工况设置1、2;传感器2、3、4、7、9、11、12、14、17、20”,共13维数据作为网络的输入。
(2)利用最大最小值归一化法对每一特征维度的数据进行预处理,标准化公式如式(10),式中x为样本,x*为归一化后的样本值:

(3)建立RUL 标签作为网络的输出,每一时刻的RUL 代表系统还可以继续运行的时间,一般认为其RUL是线性下降的,但由于数据集在随机运行一段时间后才会发生故障,其初始RUL 应当保持不变。因此其RUL标签应当为分段函数,图8为组别1#发动机的RUL函数,根据文献[19]对数据集的分析,选择130 cycle 作为所有组别系统的初始寿命。

图8 C-MAPSS数据集剩余寿命分段线性函数Fig.8 Piece-wise linear RUL function in C-MAPSS dataset
(4)利用滑动窗口提取多组训练数据集(train_FD001)样本输入网络,输出为窗口最末时刻的RUL 标签值,以窗口长度100 为例训练网络,网络参数设置如表4。选取的优化器为“rmsprop”,一次迭代的样本数量batch_size 为200,最大迭代批次epoch 为100,训练集与测试集的分割比例为0.95∶0.05,训练直至测试集的损失函数达到最小且连续在10 个批次不再减小,并保存最优模型,用于测试数据集(test_FD001)。在测试数据集中将每一组别的发动机数据与滑动窗口长度相等的最后一组样本输入最优模型,得到的输出值即为该组发动机的预测寿命。

表4 1D-CNN-LSTM网络参数Table 4 1D-CNN-LSTM network parameters
(5)为了评价预测算法的准确性,根据测试数据集(test_FD001)的预测RUL 和真实RUL(RUL_FD001)的差值计算预测算法的得分,得分越低,则预测误差越小,预测效果越好。式(11)为该数据集的官方评价指标[11]。对N组发动机系统的误差计算得分并求和后可得到整个数据集的总得分,相比于低估RUL,高估RUL可能造成的风险更大,因此误差大于0的惩罚系数比误差小于0时高。

3.4 预测结果与讨论
由于不同滑动窗口的值会影响输入数据的维度,从而影响预测效果,选择了不同长度滑动窗口及网络架构(LSTM网络为双层,分别为32节点和64节点)[21]进行预测,结果如表5 所示。其中,由于测试集的组别数据会在随机时间结束,其最小周次数据为31 cycle(见表3),存在滑动窗口长度大于某些组别数据长度的情况,而训练模型的输入维度等于窗口长度,这些组别的数据为不可测试单元。因此,表5给出了不同滑动窗口长度下的可测试单元数(最多100组),预测总得分以及平均得分。
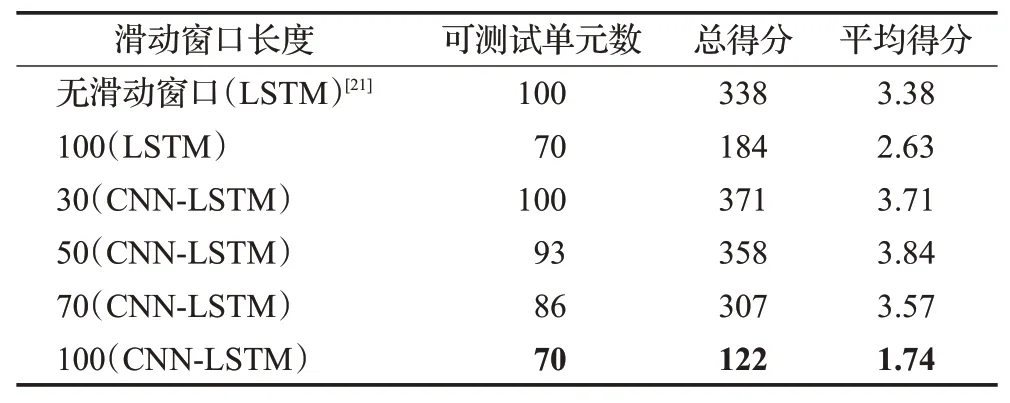
表5 不同窗口长度下的RUL预测结果Table 5 RUL prediction results with different window lengths
由表5可以做出以下分析:
(1)在相同的网络架构下,添加滑动窗口可以减小预测误差,由于利用滑动窗口法增加了训练数据样本,使得LSTM网络获取到更多的故障信息。
(2)滑动窗口的长度越长,平均得分越低,这是由于较长的输入维度为LSTM网络提供了更多的长期记忆,且长序列相比短序列包含的故障信息更多,短序列更加难以预测到未来的退化趋势和RUL。
(3)在相同的滑动窗口长度下,添加了1D-CNN 的网络比单独的LSTM 网络预测误差更小,这证明了1DCNN 网络可以有效地提取传感器之间的关联信息,提高预测准确性。
图9为滑动窗口长度均为100 的LSTM 网络和1DCNN-LSTM 网络在测试集上的预测效果,横坐标为测试集组别号,纵坐标为降序排列的剩余寿命,分别为同一组别剩余寿命的真实值和预测值。图10为两个网络的预测误差分布图。分析可知,当RUL 越接近0 时,预测误差越小;加了1D-CNN 的LSTM 网络预测误差更小,误差接近0 的比例更高,证明了1D-CNN-LSTM 网络比LSTM网络有更高的预测准确性。

图9 两种网络架构下的RUL预测误差Fig.9 RUL prediction error under two different networks

图10 两种网络架构下的预测误差分布Fig.10 Prediction error distribution under two networks
将本文预测结果与其他相关RUL预测方法在该数据集的预测结果进行了对比,如表6所示。与多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)相比,LSTM 网络对RUL 的预测误差明显更小;与另外两种既考虑了时间又考虑了空间的GCN-TCN 方法和将CNN 和LSTM 网络展平后并联的DAG 方法相比,本文的预测平均误差更低。上述实验证明本文所提出的滑动窗口法和1D-CNN-LSTM网络平均误差很小,对较长的时间序列预测准确性明显优于其他方法。

表6 不同方法RUL预测结果对比Table 6 RUL prediction results with different methods
4 结束语
本文提出了一种模型和数据混合驱动的RUL预测方法。首先,针对系统退化仿真数据集的生成问题,给出了模型驱动的失效数据集生成流程,利用蒙特卡罗仿真解决了剩余寿命标签的获取问题,为数据驱动的RUL预测提供了数据基础;其次,针对LSTM算法在RUL预测上空间特征提取不充分的问题,提出了滑动窗口法和1D-CNN-LSTM算法,提高了算法的预测准确率;最后,以某型号飞机的横侧向飞行控制系统为例,利用模型方法生成了仿真失效数据集,与C-MAPSS 公开数据集对比,证明了本文所提出的数据集生成方法有效;基于本文提出的深度学习预测算法在公开数据集上进行RUL预测实验,且与已有预测方法进行了对比,结果表明本文的预测算法准确度较高。因此,本文结合了模型和数据驱动的RUL 预测的综合优势,为不同系统的RUL 预测提供了新的研究思路,工程上将对维修策略的制定有很大帮助。
