基于Apriori 算法的关联规则挖掘在人工智能+个性化学习系统中的实践与研究
2022-08-19浦慧忠
浦慧忠
(无锡城市职业技术学院 江苏 无锡 214153)
0 引言
一个真实案例是尿不湿和啤酒在美国大型连锁超市沃尔玛一起销售,但结果是销量双双增加。分析这一现象的原因:在美国,有些年轻的爸爸常常会在工作之后跑到超级市场购买婴儿的尿片,而30%~40%的爸爸则会购买自己的饮料。这是一个关于“尿片和啤酒”的关联案例。关联规则是形如X→Y的蕴涵式,最早用于消费者购物篮分析,通过研究消费者放置在“购物篮”中的各种物品的相关性,它可以帮助企业更好地了解消费者同时购买哪些产品,进而制定相应的市场战略。
在日常生活中,个性化学习系统存在大量的学生学习资料,其中包括了他们的个人资料和学习习惯,但他们的实际应用还远远没有被发掘和开发。而运用关联法则来进行学生的学习行为记录,挖掘其中隐含的规律,是十分值得我们研究的课题。
1 研究背景与现状
1.1 个性化学习的现状与趋势
2017年美国国家教育技术计划《重塑技术的教育角色》中提到:“在移动数据收集工具和在线协作平台的支持下,能够为所有学生获得个性化学习服务提供机遇;在领导力部分指出:个性化学生学习将作为有效领导力的核心关注领域之一,技术能够为学生提供个性化学习路径;在测评部分指出:形成性和总结性评价数据的收集和整合,能支持学生生成个性化数字学习体验,以及教师制定教学干预和决策。”同年我国国务院发布的《新一代人工智能发展规划》明确提出:“利用智能技术加快推动人才培养模式、教学方法改革,构建包含智能学习、交互式学习的新型教育体系。”可以看出,收集和整合大量的、不同源的数据支持实现个性化学习是必然趋势,而人工智能技术的出现及应用将是实现这些数据价值最大化的关键。
目前,个性化学习的研究主要集中在以下3 个方面:(1)个性化特征分析及其对网络学习行为研究;(2)个性化学习教学模式与服务策略研究;(3)个性化网络学习系统与平台设计研究。因此,将人工智能系统应用于学校,整合教育人工智能和数据挖掘技术,跟踪学生行为数据,预测学习成绩,支持个性化学习已成必然趋势。
1.2 关联规则的概念与现状
假设I={I1,I2,…,Im}是项的集合。给定一个数据库D,其中每个事务(Transaction)T是I的非空子集,即每一个交易都与一个唯一的标识符TID(Transaction ID)对应。关联规则在D中的支持度(support)是D 中事务同时包含X、Y的百分比,也称概率;置信度(confidence)是D 中事务已经包含X的情况下包含Y的百分比,也称条件概率。如果满足最小支持度阈值和最小置信度阈值,则认为关联规则是有趣的。这些阈值是根据挖掘需要人为设定[1]。
一个简单的关联规则实例:表1 是客户购买记录的数据库D,包括6 笔交易。项集I={网球拍、网球、运动鞋、羽毛球}。考虑关联规则(频繁二项集):网球拍与网球,事务1、2、3、4、6 包含网球拍,事务1、2、6 同时包含网球拍和网球,X^Y=3,D=6,支持度(X^Y)/D=0.5;X=5,置信度(X^Y)/X=0.6。若给定最小支持度α=0.5,最小置信度β=0.6,则可认为购买网球拍和购买网球之间存在关联。
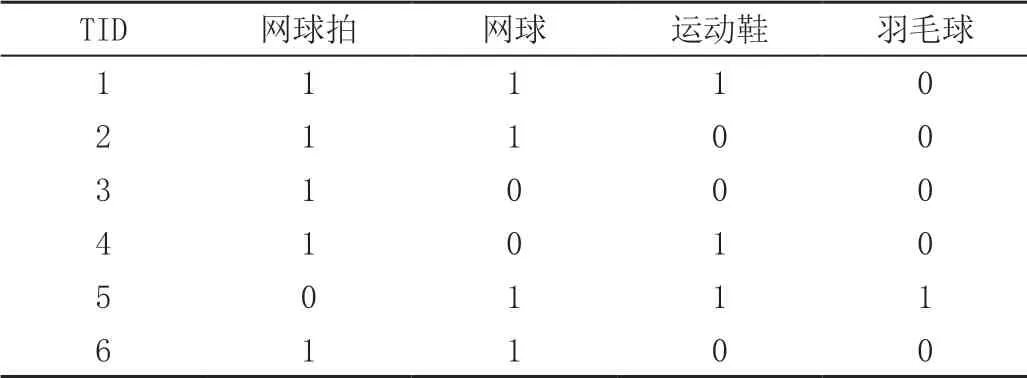
表1 关联规则实例
关联规则挖掘最早由Agrawal 等人提出。当时初衷是为了在事务数据库中找到各种产品的关联规则,从而分析客户的购买行为,指导商家科学安排进货、库存以及货架设计等。目前的研究主要集中在提高挖掘规则算法的效率、适应性、可用性以及应用推广等方面,如多循环方式挖掘算法(层次挖掘算法)、增量式更新算法、分布、并行式挖掘算法、多层关联规则的挖掘算法、多值关联规则的挖掘算法、基于概念格的关联规则挖掘算法等。
2 算法的原理与优缺点
Apriori 算法是第一个关联规则挖掘算法,也是最经典的算法[2]。它通过频繁项集挖掘关联规则,不仅可以发现频繁项集,还可以挖掘项之间的关联规则。Apriori 算法使用支持度和置信度分别量化频繁项集和关联规则,其核心思想是通过候选集生成和向下封闭检验检测两个阶段来挖掘频繁项集[3]。
2.1 Apriori 算法原理
Apriori 算法采用逐层搜索的迭代方法,属于一维、单层分类,图1 是Apiori 算法示例。基本步骤是:首先找出数据库中项集之间的关系,形成规则,其过程主要包括连接(类矩阵运算)和剪枝(去掉那些没必要的中间结果)两个步骤。
所有支持度大于最小支持度的项集称为频繁项集,简称频集[4]。具体来说:先找到一个频繁项集L1,然后用L1找到两个频繁项集L2,再用L2找到L3,直到找不到k个频繁项集为止。当出现这种情况时,需要通过数据库扫描找到每个LK。
2.2 Apriori 算法的优缺点
Apriori 算法的优点是:(1)简单易于理解与实现,因此应用很广泛;(2)它的关联规则是基于频繁项集生成的,可以保证这些规则的支持度达到规定的水平,具有普遍性和说服力。
但它存在难以克服的缺点:(1)对数据库的扫描次数过多;(2)会产生大量的中间项集;(3)采用唯一支持度;(4)算法的适应面窄等[5]。其中最大缺点是每次计算项集支持度时,对数据库中的所有数据进行扫描和比较,I/O负载很大,尤其面对大型数据库时其效率堪忧[6]。
3 改进方法
目前关于Apriori 算法的优化方法有很多,比如动态项集计数[7]。动态计数就是在不同的项目集中添加候选点,如果候选项集满足最低支持度,则可以直接将其添加到频繁项集,而无需进一步扫描、比较和计算。
具体做法如下。
(1)简单统计所有含一个元素的项目出现的频率,找到大于等于最小支持度的项集,并生成一维频繁项集Lt。
(2)循环,直到不再生成更高维度的频繁项集为止。比如,在步骤k中,根据在步骤k-1 中生成的k-1 维频繁项集生成k维候选项集。
(3)Apriori 算法用于检查新k维频繁项集的所有k-1 维项集是否已包含在计算出的k-1 维频繁项集中,并删除未包含的组合,以获得真正的k维频繁项集。
(4)扫描数据库D的每个事务TID。若它至少包含一个候选项集CK,则保留。否则,将事务记录与数据库末尾没有删除标记的事务记录交换,并将其标记为删除[8]。
扫描完整个数据库后,它将成为一个新的事务数据库D’,具体过程见图2 和图3。
改进算法与Apriori算法基本相似,但又有不同之处[9],主要为:(1)对参与组合的元素进行计数,根据结果排除不符合条件的元素,减少组合的可能性,进而减少循环判断的次数;(2)数据库扫描后的再生,新数据库的扫描次数随着循环次数的增加而逐渐减少。
4 实验结果验证及分析
通过某职业技术学院19 级计算机系学生的《数据库原理》课程中的学生学习行为记录库,提取章节与章节之间可能相关性,进而得出知识点和测试成绩之间的函数关系,最后利用关联规则挖掘算法发现学生所学课程知识点与测试成绩之间的关系,具体关联规则生成见图4。
主要流程如下。
Step 1 对学生的学习行为数据进行清理,生成结果放到学习成果数据库中。
Step 2 从学习成果数据库中提取数据挖掘对象,进行编码,并将关系表转化为事务数据库。
Step 3 在事务数据库中,根据给定的最小支持度生成频繁项集,再结合给定的最小置信度生成关联规则。
4.1 数据预处理
数据挖掘主要根据学习记录数据库中的代码表(表2)和简化关系表(表3)中提供的对象,含有学生人数、学习时间、课程内容、考试结果、学习方法等数据。

表2 代码表

表3 关系表
4.2 事务数据库的生成
将关系表转换为相应的事务数据库并编写代码。例如,选择一部分学生的《数据库原理》作为事务数据库(表4),通过代码表将成绩优异的章节转换成相应的项目。

表4 事务数据库D
4.3 频繁项集的生成
生成事务数据库D后,|D|=9,K={K01,K02,K03,K04,K05,K06,K07,K08,K09}。假设给定的最小支持度为0.25,利用Apriori 算法求D 的所有频繁项集,具体步骤见表5。

表5 频繁项集生成过程
4.4 关联规则的生成
生成频繁项集后,对于任意K个频繁项集,找出所有可能的真子集,并计算相应规则的置信度。当大于给定的最小置信度时,则输出规则,直到最终连接到k-1项的子集。从上一节中的频繁项集中选择的一些关联规则见表6。

表6 事务数据库生成的关联规则
当最小置信阈值设置为0.75时,规则为 K01∧K08→K03。具体来说在学习《数据库原理》课程时,如果学生在“绪论”和“数据库编程”章节中取得好成绩,“关系数据库标准语言SQL”章节的成绩也会更好,所以在个性化学习系统中就可以考虑将“数据库编程”放在“关系数据库标准语言SQL”之前,或者当学生在选择学习“关系数据库标准语言SQL”时,个性化学习系统会建议学生先复习巩固“绪论”和“数据库编程”这两章内容。比如具有“学术型”学习风格的学生在学习“关系数据理论”这一章节时,更多使用理论文本材料进行学习,绝大多数的学生学习成绩优秀。相反具有“操作型”学习风格的学生在学习“关系数据库标准语言SQL”这一章节时,更多使用视频动画进行实践学习,大多数的学生学习成绩也优秀。因此,当“学术型”学习风格的学生选择学习内容时,个性化学习系统将优先为学生推荐呈现理论文本为主的学习材料。当“操作型”学习风格的学生选择学习内容时,系统将优先为学生呈现视频动画为主的学习材料。
因此,关联规则分析不仅可以挖掘隐藏在课程内容之间相互的关系,还可以发现不同学习风格的学生使用哪些学习策略能更有效地学习。实验结果表明,改进的Apriori 算法大大提高了运算效率,挖掘出的规则也能有效地辅助教师进行学习监督和指导。
5 结语
随着人工智能技术在信息化领域的不断深入,学习过程中数据源的大量涌现,关联规则作为一种常见的无监督学习方法,在个性化学习系统中有着广阔的应用前景。本文从经典的Apriori 算法出发,探索并发现了一种更高效、稳定的关联规则分析方法,该方法在个性化化学学习系统中进行了充分的实践,取得了一定的应用效果,为后续研究积累了相关经验。
