基于数学模型的海量数据中用户信息提取方法
2022-08-19潘东阳
潘东阳
(信阳职业技术学院数学与计算机科学学院 河南 信阳 464000)
0 引言
互联网中数据数量较多,用户关系比较复杂,并且大部分数据信息都不够完整,因此在海量数据中提取用户信息具有较大的难度[1]。国内用户信息提取技术还不够成熟与完善,针对海量数据中用户提取问题所采用的方法主要以人工智能技术为主,利用人工智能技术对用户信息特征进行提取,并根据用户信息特征识别出海量数据中的用户信息,最后实现对用户信息的提取,虽然现有方法提取效率比较高,但是对于用户信息特征的计算不够准确,导致传统方法在实际应用中提取到的用户信息不够全面,提全率比较低,已经无法满足海量数据中用户信息提取需求,为此提出基于数学模型的海量数据中用户信息提取方法研究。
1 海量数据中用户信息提取方法
1.1 海量数据信息抓取
根据海量数据中用户信息提取需求,采用网络爬虫技术对互联网中海量数据进行采集。数据主要保存在互联网各个网页或者网站中,因此网络爬虫的爬取对象主要为互联网网页和网站。将用户数量较多且信息量较大的网址输入到网络爬虫上,网络爬虫根据输入的网络链接进入到网页,并且对网页属性信息进行学习,获取到网页中访问层数、数据节点位置、数据总量、数据类型等信息。根据信息生成爬取任务,对网页进行逐层访问和爬取,以用户信息作为爬取主题,使用ASFHAIG 标签对网络网页中不规则或者错误的标签进行统一修复,随机选取某一网页作为互联网爬取单元,建立网页信息标签树,网络爬虫利用网页的视觉信息对互联网网页进行分块,对网页信息进行逐块提取,根据爬取主题找到与其相关的网页文本文件,并将网页文本文件进行超文本标记,记录到一个URL 地址表中,对网络网页信息进行存储,当爬取到的信息量达到学习到的数据总量时停止该网页信息爬取,通过HTTP 网络协议将爬取到的数据信息自动下载,根据数据类型建立相应的数据文档[2]。为了方便后续分析和计算,对爬取的海量数据进行预处理,由于用户信息主要为文字信息,因此剔除掉海量数据中的图像数据、视频数据以及音频数据。然后利用TSIHD 标签对文字数据中不规则、格式错误的数据信息进行修复整理,将处理后的数据信息存储到TXXT 文档中,以此实现对海量数据信息的抓取。
1.2 挖掘用户关联海量数据
网络爬虫只是获取到网页数据信息,尽管在网页信息爬取过程中对海量数据进行了预处理,但是数据量仍旧比较大,网络爬虫爬取到的海量数据中存在没有任何意义的信息,因此在上述基础上对提取到的网页数据信息进行深度挖掘,分析网页中用户访问记录的历史行为。此次以统计法为理论依据,对网页的页面访问序列划分成用户会话的关联单元,剔除其中与用户无关的记录,得到网页中用户重要访问记录数据信息,比如用户浏览时间、页面用户访问次数、页面用户查询关键词、相关页面用户重复访问记录等,对这一类相关数据进行检测分析,获取到页面用户历史行为记录。首先读取到网络爬虫爬取的用户行为记录的文档内容,对网页文档信息的HTML 属性的字串符进行加载,根据网页用户行为记录文档信息的字串符匹配到用户的数字身份,并对网页页面用户行为记录文档信息进行分词,读取到能够代表用户行为的关键词,计算出不同代表用户行为的关键词的出现频率。假设爬取到的网页页面同一行为数据集合中,任意两个用户行为的关联度为K,其计算公式如下:
公式(1)中,a和b分别表示爬取到的网页页面同一行为数据集合中的两个用户行为;O(a)表示用户行为a集合;O(b)表示用户行为b集合;H(a)表示用户行为a的权重;H(b)表示用户行为b的权重。假设网页页面中共存在J个用户行为,则该网页页面中用户对行为a的兴趣度为:
公式(2)中,Ia表示网页页面中用户对行为a的兴趣度;Ib表示网页页面中用户对行为b的兴趣度。按照作用方向将网页页面中用户对某一种行为的兴趣度分为正负两种,对网页页面用户行为兴趣度进行标准化处理,其用公式表示如下:
公式(3)中,+表示网页页面中用户行为对用户兴趣的正向作用;−表示网页页面中用户行为对用户兴趣的负向作用;ui表示网页页面中第i条用户行为记录中某一行为的标准化值;Ii表示网页页面中第i条用户行为记录中某一行为的兴趣度值;min(Ii)表示网页页面中第i条用户行为记录中某一行为的最小兴趣度;max(Ii)表示网页页面中第i条用户行为记录中某一行为的最大兴趣度。利用上述公式对网页页面中用户行为兴趣度进行标准化处理,利用兴趣度来表述网页页面中用户行为,从网络爬虫爬取的网页页面信息中筛选出具有正向作用的用户行为信息,以此完成用户关联海量数据的挖掘。
1.3 海量数据中用户信息特征分析
以网络爬虫的历史数据库作为海量数据中用户信息特征分析数据源,假设待提取的海量数据集合为K,将网络爬虫历史数据库的接口与BP 神经网络连接[3]。利用OGU 软件将网络爬虫历史数据库中的数据导入到建立的神经网络输入层中,进行学习和训练,其训练向量的模式表示如下:
公式(4)中,x表示BP 神经网络训练向量。假设用户信息特征为s,利用以下公式定义BP 神经网络训练向量特征对数据样本类别判断的影响程度。
公式(5)中,E表示BP 神经网络训练向量特征对数据样本类别判断的影响程度;r表示BP 神经网络训练数据集的类别;p表示实际数量的数量;s表示在学习训练过程中出现次数最多的特征[4]。利用上述公式计算出BP神经网络训练向量特征对数据样本类别判断的影响程度,如果特征s在用户信息数据类别中出现的次数比较多,并且在非用户信息数据类别中出现的次数比较少,则判定该特征为用户信息数据特征,以此实现对海量数据中用户信息特征的提取。
1.4 基于数学模型自动提取海量数据中用户信息
在上文基础上,利用数学模型对海量数据中用户信息进行提取,不同类别数据之间的特征是不一致的,因此海量数据中用户信息与其他信息在特征表现上存在不一致,利用以下公式计算出海量数据的不一致率:
公式(6)中,P表示海量数据的不一致率;z表示用户信息数据特征与其他数据特征之间的离散值;m表示引起数据类别不同的临界点;d表示任意用户信息数据特征的属性值的离散区间对数据类别分辨能力;κ表示用户信息数据特征区间所对应的类别概率;ρ表示海量数据中用户信息数据特征区间划分特征属性的离散特性[5]。利用上述公式计算出海量数据中用户信息与其他信息不一致率,结合数据特征淘过滤规则,建立海量数据中用户信息提取数学模型,该模型用公式表示如下:
公式(7)中,N(K)表示海量数据集K中的用户信息;ϖ表示信息特征淘汰过滤规则;S表示最优特征子集;ν表示包含特征类别的数据数量;a表示用户信息特征区间的类别频数[6]。综上所述,在对海量数据中用户信息提取数学模型建立过程中,以原始数据中用户信息特征作为提取因子,根据不同类别数据不一致率,并结合信息特征淘汰过滤规则对海量数据中的信息进行详细分析和计算,根据给出用户信息特征淘汰特性与过滤的内在联系建立数学模型,利用以上数学模型对海量数据中的用户信息进行提取,以此实现了基于数学模型的海量数据中用户信息提取。
2 实验论证分析
实验数据集选取某网页消费信息数据,数据总量为700 GB,共分为35 类,该数据集中包含了用户个人信息、消费喜好信息、网页登录信息以及一些其他信息,将其作为实验对象,利用此次设计方法与传统方法对该数据集中用户信息进行提取。实验环境:1 台计算机,操作系统为Windows2010 操作系统,CPU 为INTER coer i8,内存为16 GB,主频为8.5 GHz,接入网下载速度为1 000 KB/s,硬盘为SATA 600 G。实验共选取UserAgent、Host、LAC、URI、用户手机号5 个相关字段,其中UserAgent 字段格式为字节流,实例为13 664;Host 字段格式为十六进制数字串,实例为Mozilla/5.62;LAC 字段格式为十进制数字串,实例为13266566556433;URI 字段格式为点分十进制,实例为12.X.X.2644;用户手机号字段格式为十六进制数字串,实例为1264xxxxx1365。按照上文对海量数据用户信息特征进行计算,将网络爬虫的网络爬取业务设定为百度、腾讯微博、京东、淘宝4 个业务,网页访问次数设定为50 次,爬取深度限制设定为5.5,下载线程数设定为15。以HTML 文件作为根节点,构造网页标签树,爬取到的网页文档共10 个,网络爬虫探索的网页网址共200 个,建立的网页数据集共200 M,爬取网页信息条数共2 万条。并将数学模型的迭代设置为10,提取到的用户信息情况见表1。
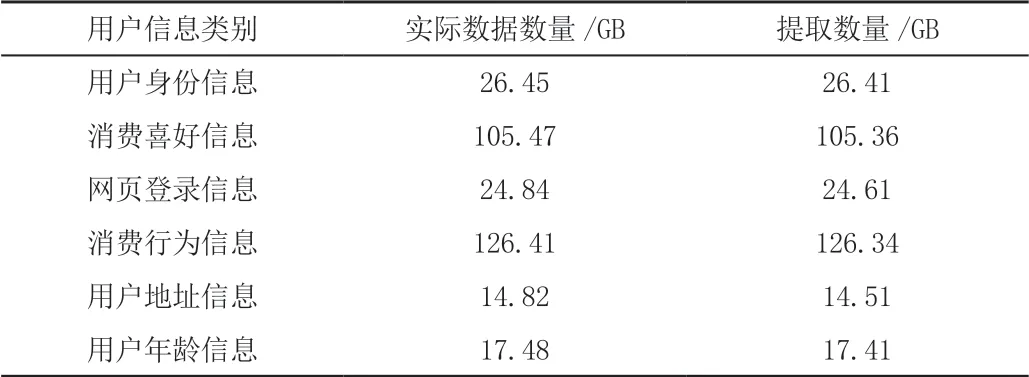
表1 海量数据中用户信息提取情况
实验将数据集分成7 份,使用两种方法对数据集中海量数据中的用户信息进行逐一提取,记录两种方法提取用户信息量大小,并利用UJKD 软件将其与实际用户信息量进行分析,计算出两种方法的提全率,提全率是检验信息提取方法有效性的关键指标,因此实验将其作为实验结果,对比两种方法提全率,见表2。

表2 两种方法提全率对比
从上表可以看出:设计方法能够有效提高提全率,该方面优于传统方法,能够全面提取到海量数据中用户信息。
3 结语
此次研究以数学模型为理论基础,在传统方法基础上采用了数学模型,设计了一套新的海量数据中用户信息提取方法,并通过实证分析验证了该方法具有良好的适用性和可靠性。此次研究对提高海量数据中用户信息提取精度具有一定的提升作用,同时还解决了海量数据中用户信息提取不够全面的问题,在海量数据中用户信息提取方面具有良好的参考价值和应用价值。由于此次设计的方法尚未经过大量实践应用,建立的数学模型可能存在一些不足,今后会对其优化和创新进行进一步研究。
