生物医学中高维非均衡数据整合算法
2022-08-16肖枝洪王一超
肖枝洪,李 季,王一超
(1.重庆理工大学 理学院,重庆 400054;2.内蒙古赤峰市昭乌达中学,内蒙古 赤峰 024099)
0 引言
医疗行业中充斥着大量高维非均衡医疗数据。在数据分析国际研讨会议中将非平衡数据以及高维数据列为未来数据挖掘研究所面临的具有挑战性的十大问题之一[1]。高维数据指数据特征多,不仅表现在数据的规模大,而且定义的数据不再仅仅局限于数字,医疗病例的文本、图像、声音和传感器信息等一些可测量的信息都可数据化。这使得医疗数据的特征大大增加,数据结构更加复杂。非均衡数据指分类任务的数据来自不同类别的样本数目相差悬殊,又称样本比例失衡。在医疗领域中,正常数据是多数类,病理数据往往是少数类。人们通常更加关注于少数类,且将少数类误判为多数类的代价通常会更大。因此为了训练出适合不平衡数据的分类模型,对不平衡数据进行处理显得格外重要。
对于高维数据的分类,通常都是先对数据进行降维处理,也就是通过对训练数据集进行特征提取,获得能够对样本进行较好分类的少量具有代表性特征。具体处理方法如低方差滤波、高相关滤波、向前特征选择、向后特征提取、主成分分析、K-means指标聚类、特征提取转化等,都具有一定的局限性。低方差滤波是对一些指标变化较小的指标进行删除,但是这种方法不具备广泛性,譬如一些医疗指标即使变化很低,但是可能病症就有很大的差别[2];高相关滤波与主成分分析适合数据集中存在高度相关的变量集情况,且有可能造成重要指标被删除的损失;向前特征选择与向后特征提取2种方法耗时较久,计算成本都很高;K-means指标聚类是以指标之间的相似系数作为聚类标准,对离群点太敏感,并且相似系数的阈值也需要人为确定。此时随机森林(RF)机器学习模型体现了优势,RF具有准确率高、鲁棒性好、易于使用、一般不需要繁琐的步骤、适用于各种类型数据的优点。该算法被广泛应用到诸如生命科学领域中对基因序列的分类和预测回归[3-5]、金融经济领域中对企业和客户信用的分析和反欺诈识别[6-8],以及人工智能AI等领域中的人脸识别[9],但是RF在指标提取中有2种指标重要度评价体系,往往得出的重要指标排序不一致。对此用所提出的MAG算法进行特征提取,寻找出具有代表性的特征,达到降维目的,并在选择重要特征数量时对传统的“剃须法”进行改进,缩短算法运算时间。
对于非均衡问题,经典的算法莫过于C’Hawla等[10]提出的SMOTE过采样技术,该方法属于一种人工合成少数类样本的过采样技术,根据过抽样率,从少数类的一个样本的K个最近邻样本中随机选出若干个,在该样本和被选的近邻样本之间插值合成新的样本。该算法原理简单,运行速度快,但是SMOTE算法也有明显的不足,不能有效解决非均衡边界混合数据。Liu等[11]提出了SMOTE和Boost相结合的SVM算法,通过对高维空间的非线性变换将分类问题转换为二次寻优解,其实验表明此方法在非平衡数据集上取得了较好的分类效果,但算法采用欠采样与过采样结合,不能保证数据的整体性。王超学等[12]提出了GA-SMOTE算法,将3个算子引入到SMOTE中,首先用选择算子实现对少数类样本有区别的选择,再使用交叉算子和变异算子实现对合成样本质量的控制。然而此算法中的选择算子仍然没考虑边界混合的样本,而是以适应度函数来确定,恰恰将混合区域数据视为重要样本。尽管对于非均衡混合问题后续也有相关学者研究,如钟龙申等[13]提出了用基于K-means聚类算法改进SMOTE算法来解决非均衡数据问题,但此算法没有摆脱K-means聚类严重依赖于初始点的缺点。冯宏伟等[14]针对非均衡数据分类效果不佳的问题,提出了基于边界混合采样的非均衡数据处理方法(BMS)。该方法通过引进“变异系数”寻觅样本的边界域与非边界域,然后对边界域中的少数类样本进行过采样,对非边界域中的多数类样本进行随机欠采样,从而达到训练数据基本平衡的目标,但是忽略边界区域往往存在离群点的缺点。赵清华等[15]针对非均衡数据提出了三角质心与最远距离法改进传统的SMOTE算法,改善了边界混合插值困难的问题。虽然此算法在解决边界混合时体现了一些优良性,但计算的步骤与运算量也增加了数倍之多,算法准确率提升过小。张喜莲[16]提出了一种鲁棒的半监督降维算法,得到了更精确的数据结构,但是此算法中对正则化参数λ的要求十分苛刻,通常难以满足。丁长兴等[17]介绍了最重要最基础的梯度下降算法进行了高维非均衡数据挖掘的研究,指出随机梯度下降算法已成为机器学习特别是深度学习研究的焦点,但也存在迭代复杂性和时间效率没有很好解决的问题。
医疗领域目前对于此类数据的研究,仅从高维或者非均衡的单一角度出发来解决问题,两者兼顾的整合算法几乎没有涉及。例如,陈旭等[2]针对医疗领域往往存在着样本数据集非均衡的问题,采用从多数类样本中抽取部分样本,与少数类样本组成平衡数据集后再构建模型,同时提出了一种新的基于迭代提升欠采样的集成分类方法,但是破坏了数据的完整性,而且对于存在的高维问题也没有提出解决方法;龚彦等[18]针对医疗行业中的高维数据问题,使用模糊神经网络分类器进行数据整合分析处理,将人工神经网络与模糊系统相结合,采用神经网络对数据进行特征选择,用模糊系统中的隶属度函数对数据进行分类,但是此方法没有对非均衡数据进行均衡处理;王星等[19]提出了一种基于基因互作网络正则化的双聚类算法,对癌症亚型进行分类,其中聚类方法虽然通过正则化方式将高维问题解决,但是依旧对非均衡状况没有考虑;胡满满等[20]发现了不同疾病发病率的差异性导致医学样本具有不均衡、小样本的特点,并且引入动态采样技术以构造均衡数据集,利用模型在不同样本上的预测结果来动态更新样本采样概率,目的是确保模型可以更多地关注错误分类样本和分类置信度不高的样本,从而提高预测模型的效果,但是对于医疗中的高维问题没有提出解决方法。
根据对上述文献的分析探究,针对医疗中高维非均衡数据的整合问题拟提出MAG算法和PDSSD-SMOTE方法相结合的整合算法,并基于帕金森氏病分类数据集[21]和常规结肠镜检查中的胃肠道病变数据集[22]进行实验分析。首先采用MAG算法对高维数据非均衡进行降维;降维后,采用动态离差平方和(PDSSD)机器学习方法,改进K-means机器学习方法对初始点的依赖性,将少数类也就是负类数据样本进行区域合理划分;再利用少数类中高纯度样本区域重心点与近邻间进行插值来改进SMOTE算法,让具有边界混合的负类样本数据通过插值趋近于高纯度样本,从而提升非均衡数据取样时的纯度。然后在实验中应用最小二乘支持向量机(LSSVM)与RF对运用MAG算法和PDSSD-SMOTE方法整合后的数据进行数据分类,以分析该方法分类的准确性和精确性。
主要贡献在于:① 改进RF提取重要特征的准则,提出了用组合标准的MAG算法来提取特征重要度信息;同时剔除相关性较大的特征,对用于重要指标选取的“剃须法”进行改进,缩短了运算时间。② 采用PDSSD机器学习对负类样本数据集进行区域划分,对区域中心与样本间插值的SMOTE算法进行改进,使样本数据均衡更加合理。
1 相关算法理论
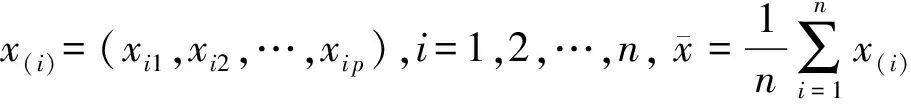

表1 P个指标n个样本
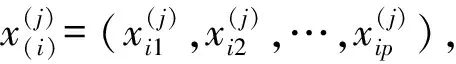
(1)
也称其为此类的质心,i=1,2,…,nj,j=1,2,…,k。
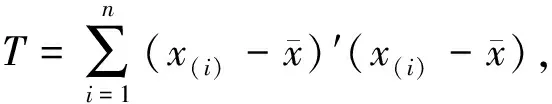
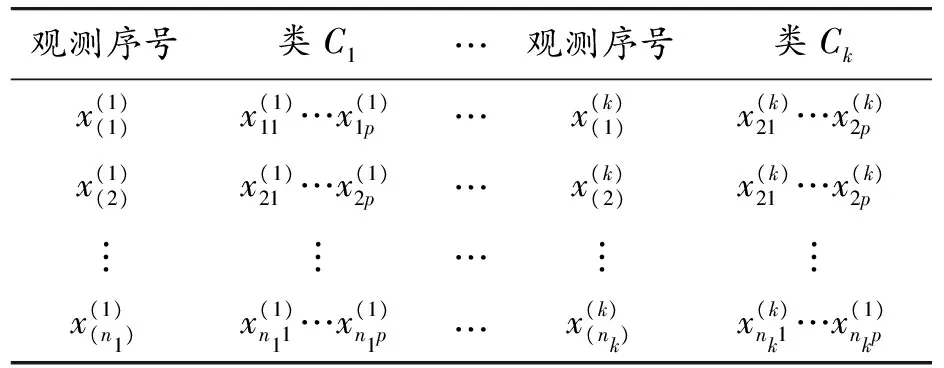
表2 所属各类的观测
1.1 RF算法
RF是决策树的集合,通过投票方式进行分类模拟,决策树算法应用广泛,有ID3、C4.5[23-24]、CART 3种,CART树是二叉树[25],而ID3和C4.5可以是多叉树。对于RF分叉的好坏有2个重要指标评价指标:基尼系数节点纯度估计与袋外数据(OOB)精度估计。但是往往根据2种标准对特征提取的结果不完全相同。为了使高维数据的特征提取没有偏颇,将以MAG算法作为标准来进行高维数据的特征提取。
1.1.1基尼系数
对于以基尼系数作为分叉标准的计算如下:
假设有K个类,样本点x属于第l个类的概率为Pl,则概率分布的基尼系数为:

如果样本集合D根据特征F是否取某一可能值a被分割成D1与D2两部分,即:
D1={x∈D|F(x)=a},D2=D-D1
则在特征F的条件下,集合D的基尼系数定义为:
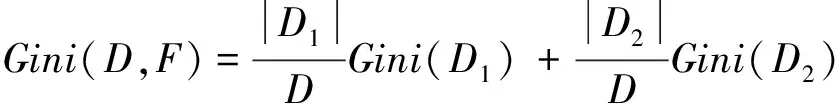
(2)
将D中所有特征的基尼系数进行排序,其最大值意味着对应的特征最具代表性。然后对D1和D2按照上述方法挑选下一个特征,直到到达事先规定的叶节点为止,从而获得相应的具有代表性的一系列特征,这种方法数值型特征和字符型特征都可以适用。
1.1.2OOB精度
RF有一个重要的优点就是不必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。这是因为在构建每棵树时,对训练集使用了不同的bootstrap sample方法。对于每棵树(假设第k树)而言,若有训练实例没有参与到第k棵树的生成,则称该实例为第k棵树的OOB袋外样本。
OOB精度不仅可以利用OOB对模型性能进行评价,而且还可以用来判定特征的重要度。其原理是:对于某个特征变量,当把噪声信息加入到该特征后,RF的预测精度会显著降低,这就说明该特征重要程度很高;相反,若RF的预测精度没明显变化,则标志该特征重要程度很低。指标选取就是根据预测精度较少值确定的。
将在2.1节把基尼系数与OOB精度进行组合,得到新的评价标准,并用新的评价标准来对高维数据进行降维处理。
1.2 SMOTE算法
为了方便说明SMOTE算法原理,在表2中不妨取k=2。SMOTE算法原理为:样本数据集分为样本多数类(正类)C1与样本少数类(负类)C2两大类,根据欧几里得距离从C2类样本中挑选出距离第i个样本最近的m个样本;根据样本数据平衡需要再从此m个样本中随机挑选iN个样本并记为集合Yi,Yi={yi1,yi2,…,yiN}表示第i个样本挑选的最近样本集合,i=1,2,…,n2。然后在第i个样本与其最近的iN个样本之间进行随机插值,其值记为:

(3)

2 高维非均衡边界混合数据优化处理
2.1 高维数据降维优化算法
针对1.1节的问题,本节通过整合2种对特征提取的标准而提出MAG算法。其思想就是将基尼系数节点纯度与OOB确定变量重要度估计值二者综合取平均值,然后依据该值重新对特征重要性进行排序。MAG算法如下:
步骤1 对表1中的数据建立RF模型H。记ntree为RF中分类树的个数,mtry为RF中决策树的每次分支时所选择的变量个数。
步骤2 利用OOB数据,测试RF中所有的分类树,得到每棵树的OOB估计的准确率,并记ACCj为RF中第j棵分类树的准确率:
步骤3 随机打乱OOB样本数据中第i个特征的观测值,也就是对之随机重排。用此数据输入到第j棵分类树中进行预测,得到一个新准确率ACCji。
步骤4 计算每个分类树前后两次OOB数据准确率之差difji=|ACCj-ACCji|,计算第i个特征的重要程度:

(4)
依据式(4)计算每个特征的Difi并按从小到大顺序进行排列。
步骤5 根据式(2)计算各个特征基尼系数值Ginii,按从小到大顺序进行排列,并判断与步骤4的顺序是否一致,若不一致继续步骤6。
步骤6 计算第i个特征综合重要程度值:
(5)
依据式(5)计算所有指标重要度,并从大到小进行排序。记所有特征的综合重要程度值集合T={index*1,index*2,…,index*p},其中index*1>index*2>…>index*p。
在RF特征重要度排序之后,如何选取特征重要度阈值是一个难点,传统的RF剃须法[26]是常用的方法,其原理为将所有指标重要度从大到小排序,然后依次剔除重要值排名在后10%的特征。例如,假设有n个特征,不妨取n=100,剔除{indexn-9,…,indexn}所对应的特征,再用剩余的90个特征建立RF模型。然后根据此模型,计算每个特征的重要程度值和OOB误差。如此这般,一直到事先约定为止。这样就得到一系列特征集合和OOB误差,选择OOB误差最小且数据特征最少的特征集,但是这个剃须法在确定剔除比例时具有主观性,不能根据特征集重要值进行具体划分,而且特征较多时运算过于费时,为此提出了分段式的剃须法(segmentation shaving),根据第一次建立的RF得到的特征重要值进行分段计算,分段的准则依据实际特征重要值的均值与方差来确定,均值与方差计算方法如下式:
根据以上分段确定选取的特征数,分别建立5个RF模型,选取OOB误差最小且特征数最少的数据特征集。
得到最少特征数p1的数据特征集M后,计算特征的相关系数矩阵,给定阈值λ,将相关系数大于阈值的进行相关性检验,剔除相关性较大的特征,将数据特征集进一步优化。
2.2 非均衡边界混合数据优化算法
针对1.2节的问题,本节假设表2中数据集C只有2 类:多数类样本集C1和少数类样本集C2。并假设C2潜在地可划分为区域C21、C22和C23,如图1所示。其中C21为C1和C2边界混合附近的数据集;C22为C2中高纯度数据集;C23为C2中离群点数据集。

图1 少数类样本集数据分布图
为了使数据均衡,使用SMOTE算法对C2进行过采样。同时也为了避免过多地抽到边界混合数据集C21中的数据,采用文献[27]中的PDSSD准则下的机器学习方法对C2进行划分。动态离差平和准则下的机器学习是根据总体离差平方和不变,依次调整样本的类别,使类内样本离差平方和最小,类间离差平方和最大,能够保证机器学习减少对初始点的依赖度。
首先,从C2中计算样本距离矩阵,随机选定这3个初始凝聚点,运用PDSSD机器学习法将C2划分为3类,仍然记为C21、C22和C23。
其次,根据式(1)计算C21、C22和C23样本集的质心分别为d21、d22和d23。再计算3个样本集的质心与最近多数类样本集质心的距离:
比较υ21与υ22、υ23的大小进行排序,如果υ21<υ22<υ23,则说明d22所在的数据集C22是高纯度少数类样本集,就选择C22进行中心SMOTE算法插值。
再次改进中心SMOTE算法:采用样本集质心与样本之间插值,即
(6)
将此算法叫做PDSSD机器学习中心插值法,简称为PDSSD-SMOTE算法。
3 实验
3.1 实验环境与医疗数据
本次实验采用R3.4.4与Matlab 6.0数据分析软件进行实验数据分析。
此实验数据来源于UCI(http://archive.ics.uci.edu/ml/index.php)机器学习数据库中的2个医疗数据集,数据集1:“Gastrointestinal Lesions in Regular Colonoscopy”;数据集2:“Voice Back”数据集。数据集1为二分类样本数据集,其中特征变量为698个,多数类(正类)样本量为55,少数类(负类)样本量为21;数据集2也为二分类样本数据集,其中特征变量为752个,多数类(正类)样本量为564,少数类(负类)样本量为192,2个医疗数据集显然都为高维非均衡数据,如表3所示。数据集1和2的特征变量均为数值变量。
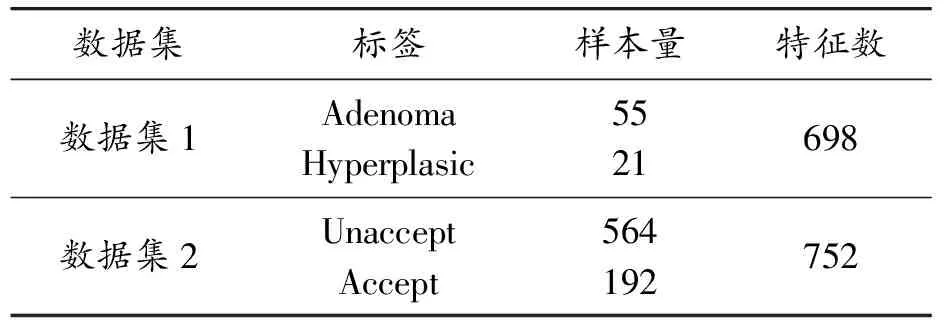
表3 数据样本集矩阵
采用F-value、G-mean值和Accuracy值作为分类器的评价标准,其中TP和TN分别表示分类中正类和负类样本正确分类的样本数量;FN和FP分别表示为正类与负类被错分的样本数量。
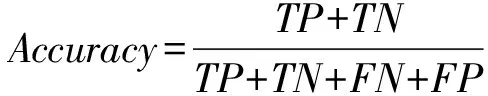
(7)
(8)
(9)
3.2 基于MAG算法对医疗数据降维实验
RF对于特征重要度评价有2种体系,验证2种体系得出的特征重要度排名是否一致,根据式(2)与式(4)分别计算得到各个特征的基尼系数与OOB估计重要度。因为特征变量过多,在此仅展示前30个特征变量的基尼系数与OOB估计值,2个数据集的结果分别如图2与图3所示。
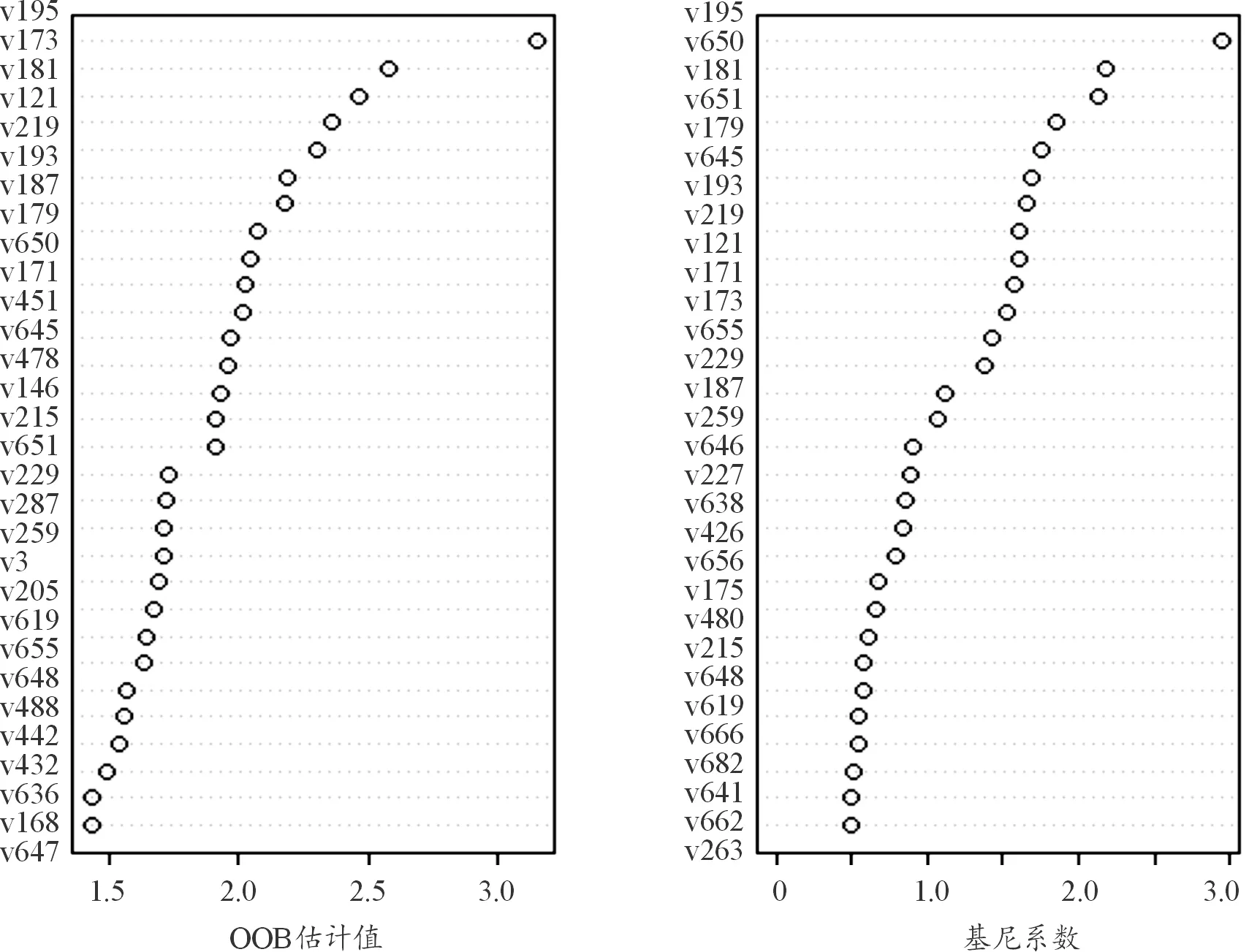
图2 数据集1基于OOB估计值与基尼系数指标重要度排名

图3 数据集2基于OOB估计值与基尼系数指标重要度排名
从图2、图3可以看出2种指标评价体系在指标重要程度排名上是不相同的,所以有必要运用MAG优化算法,再次对指标重要度进行排序。
根据MAG算法式(5)计算得到所有特征变量重要度值,其中重要度大于0的指标为167个,表示数据样本中698个指标只有167个为有效指标。再将167个有效指标根据分段剃须法选取出35个特征,作为数据降维后的特征,特征重要度数值如表4和表5所示。
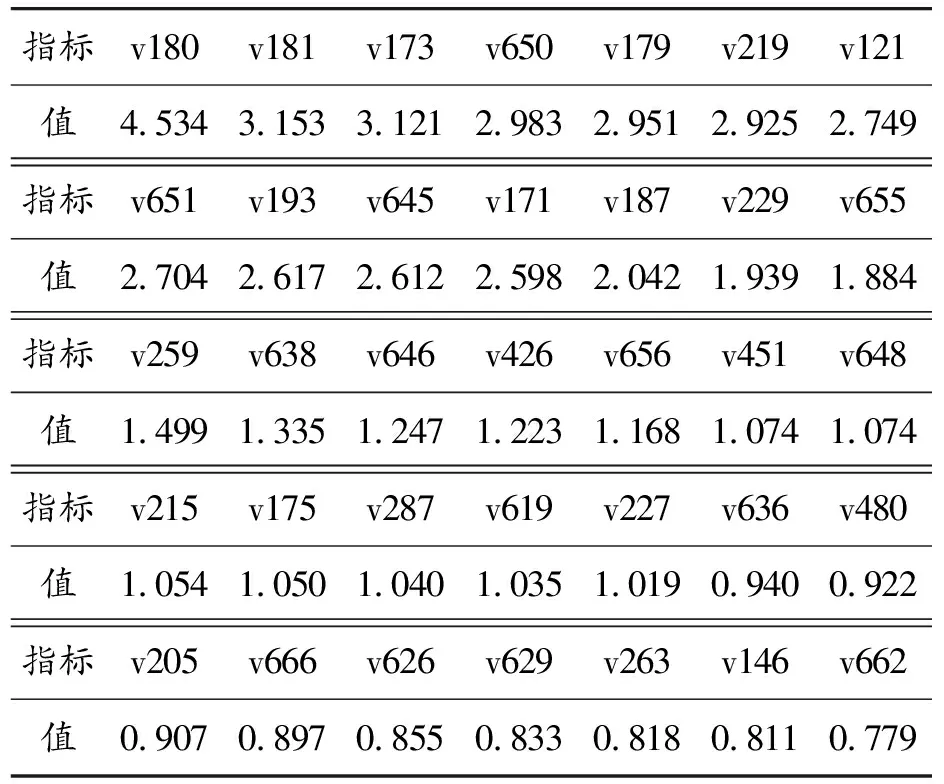
表4 数据集1在MAG算法下得到特征重要度数值
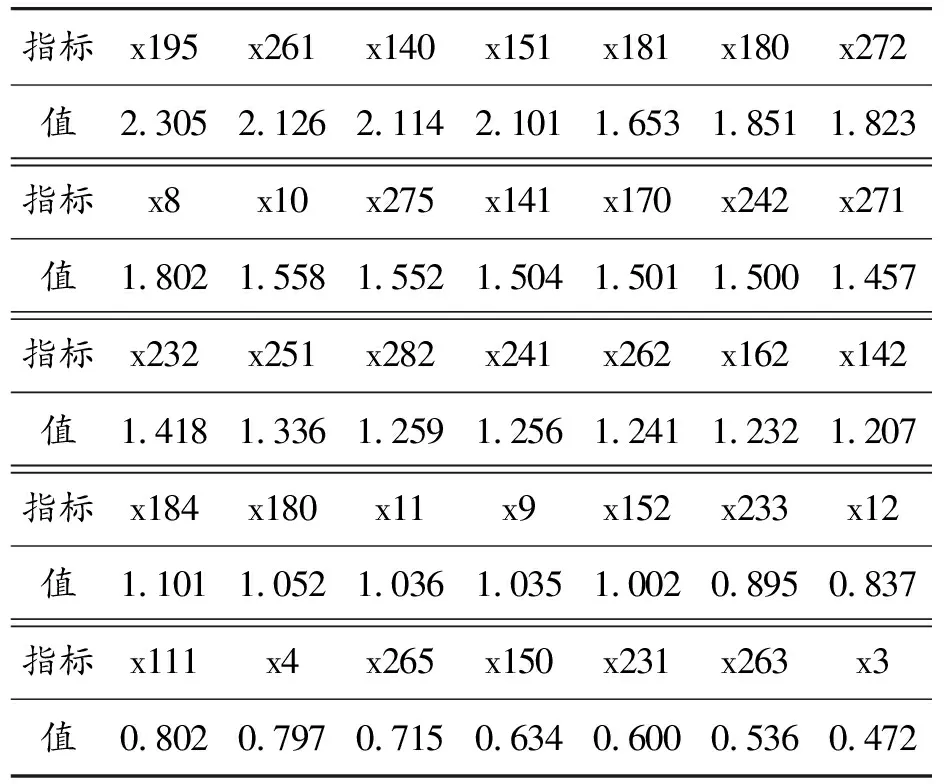
表5 数据集2在MAG算法下得到特征重要度数值
对上述MAG算法得到的特征集计算相关系数矩阵,设定阈值λ为0.9,并对大于阈值的特征进行相关性检验,得到相关性较弱的重要度高的最优特征集,如表6和表7所示。

表6 数据集1特征相关性检验筛选后得到特征集

表7 数据集2特征相关性检验筛选后得到特征集
3.3 基于PDSSD-SMOTE算法对医疗数据平衡实验
为验证数据集是否存在混合情况,运用PDSSD算法将数据集1和2在PDSSD准则下分别进行第一次聚类,其实验结果如表8所示。

表8 数据集1和2的PDSSD算法第一次聚类结果

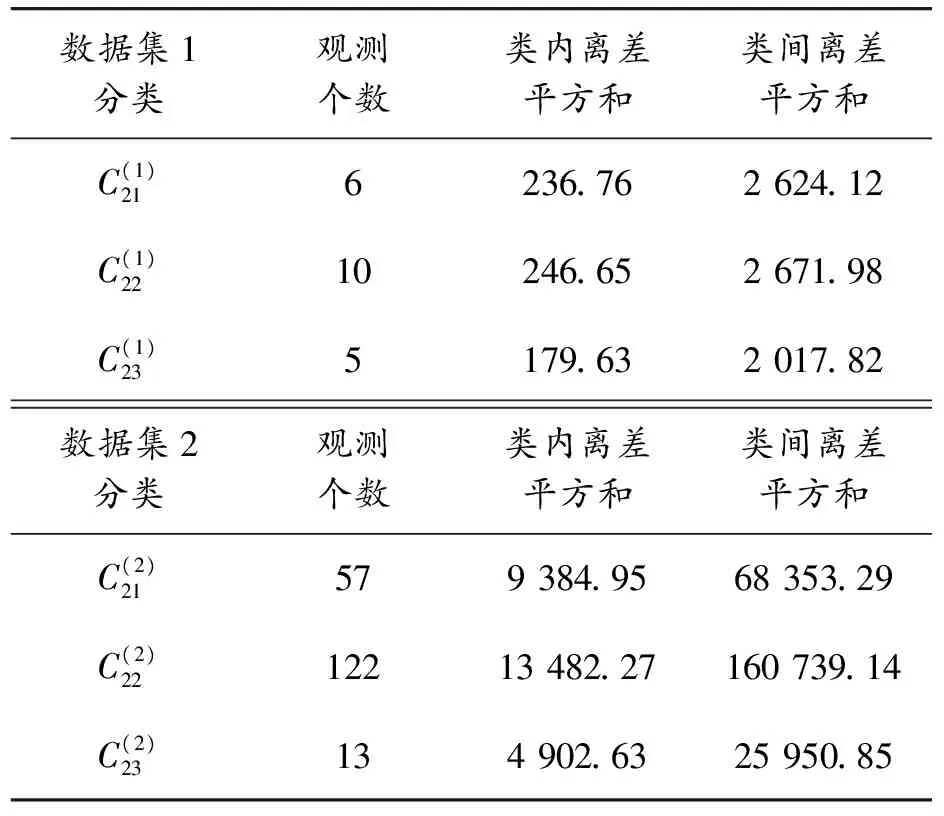
表9 数据集1和2的负类样本集PDSSD算法第二次聚类结果


表10 数据集1合成前后负类样本

表11 数据集2合成前后负类样本
3.4 MAG-PDSSD-SMOTE算法与传统方法对高维非均衡医疗数据整合的有效性比较

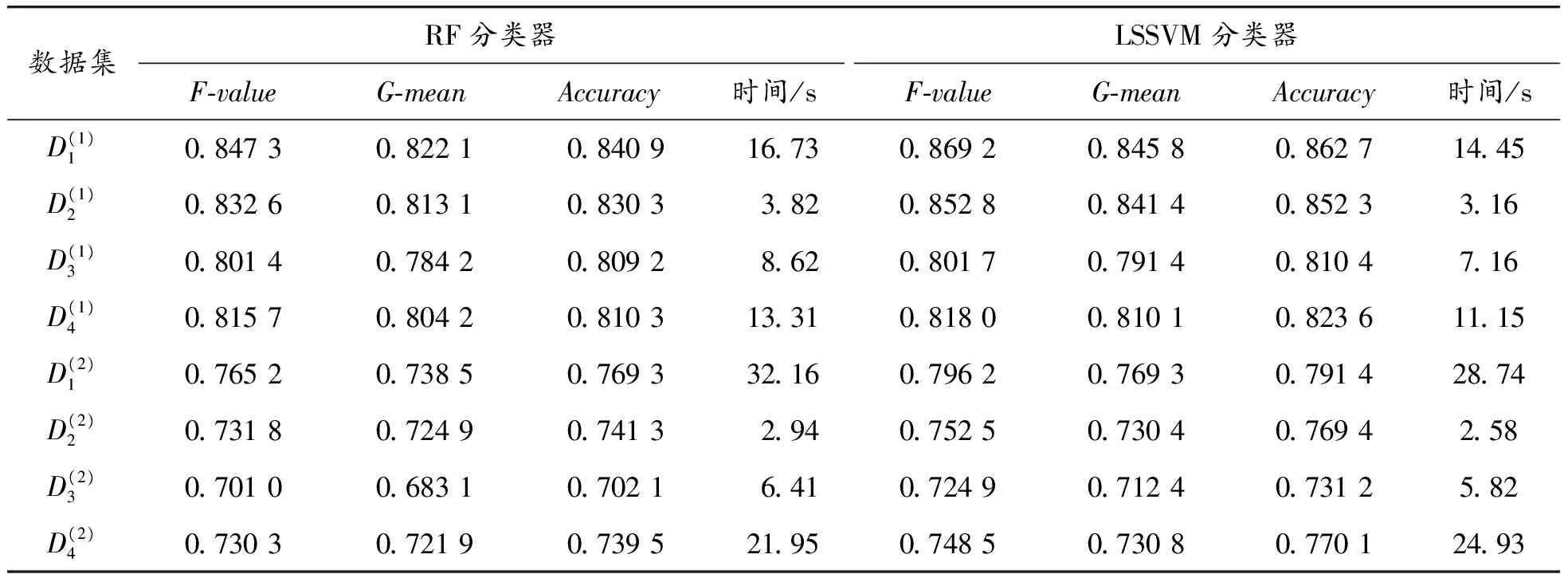
表12 不同方法降维后的数据集1和2在2种分类器下分类效率

表13 不同方法整合后的数据集1和2在2种分类器下的分类效率

为验证提出的算法具有优势,将提出的算法与处理非均衡高维数据的主流算法BP神经网络与随机梯度下降的支持向量机算法相比较,分类效率如表13和表14所示。

表14 数据集1和2在不同算法下的分类效率
从表13和表14可以看出,2种算法分别对数据集1和2的3个分类评价值都低于提出的MAG-PDSSD-SMOTE算法的数据集的分类评价值。因为BP神经网络算法和随机梯度下降支持向量机算法没有对数据进行整合,所以运算时间比MAG算法与PDSSD-SMOTE算法相结合的算法运行时间要短。
实验表明,在疾病的辅助预诊中,越高的召回率和越好的F-value和G-mean具有更小的诊断风险,对疾病的辅助决策具有更重要的价值。所提出的MAG-PDSSD-SMOTE算法整合数据之后,模型对常规结肠镜检查中的胃肠道病变的分类效率和帕金森病的分类效率有了明显提升。这正是因为MAG-PDSSD-SMOTE算法能够更加关注医疗行业的少数类样本和预测过程中的易错样本,从而保证了模型预测准确性,提高了模型效率,使其具有更小的诊断风险。
4 结论
由于经典的SMOTE算法与RF算法对高维非均衡数据进行整合时存在不足,即RF在特征提取中有2种特征重要度评价体系,往往得出的重要指标排序不一致,且特征提取的“剃须法”过于耗时,SMOTE算法对混合非均衡状态数据均衡处理时,不能对边界混合数据进行识别而实现有区别插值。针对上述问题,首先提出了RF组合评价标准的MAG算法,对于特征提取标准提出了“分段剃须法”,从而有效地克服了RF的特征重要度双标准以及特征提取剃须法过于费时的弊端。对于少数类数据的均衡处理提出了可以进行区域划分的MAG-PDSSD-SMOTE算法,解决了SMOTE算法对边界混合的少数类数据纯度不高的问题,也避免了K-means-SMOTE算法对初始聚类点的依赖问题。实验中将各算法整合后的数据集进行分类比较,结果表明对于高维非均衡数据的分类所提出的算法有较为明显的优势。
RF和LSSVM两种分类器对上述数据集进行分类的情况都验证了对于高维非均衡边界混合数据,直接运用SMOTE算法不能有效均衡数据结构,所提出的MAG-PDSSD-SMOTE算法对传统SMOTE算法具有显著的改进效果,且优于经典的K-mean-SMOTE算法。但是从各个算法对数据集整合并分类的时间来看,所提出的MAG-PDSSD-SMOTE算法所用时间要逊于其他算法,这是算法的复杂性所造成的。
此外,在研究过程中也注意到:非均衡数据结构做均衡处理时,如果数据集中存在字符型数据时如何计算其距离的问题;SMOTE算法无法有效处理那些特征变量是定性变量的数据集,对定型变量进行SMOTE插值会使其数值失去实际意义;如何提升MAG-PDSSD-SMOTE算法运算速度等问题,将在今后的研究中继续探讨。
