基于协方差矩阵调整的多目标多任务优化算法
2022-08-12邱鸿辉刘海林
邱鸿辉,刘海林,陈 磊
(广东工业大学应用数学学院,广州 510520)
0 概述
进化算法是一类基于种群个体随机搜索的算法[1-2],由于其强大的搜索能力及简单易用的特性,在路径规划[3]、软件工程[4]等现实问题中被广泛的应用,并取得了良好的效果。
近年来,研究人员受到人类大脑能同时处理多个任务的启发,提出多任务进化(Evolutionary Multi-Tasking,EMT)[5-6]的研究方向,传统的进化搜索方法一次只能解决一个任务,然而EMT 方法一次运行能够同时解决多个任务。研究表明,与传统的单任务进化算法相比,由于EMT 方法利用了任务间潜在的协同作用,使其在解决优化问题时具有更好的性能[7]。EMT 包括单目标多任务优化(Single-Objective Multi-Tasking Optimization,STO)[8]和多目标多任务优化(Multi-Objective Multi-Tasking Optimization,MTO)。本文研究的是求解MTO 问题[9]的算法性能。
当前,求解MTO 问题的算法大致可以分为基于单个种群进化的算法和基于多个种群进化的算法。前者的典型代表是文献[9]提出的解决MTO 问题的MO-MFEA 算法,该算法通过采用单个种群来同时优化多个相关的任务,并以预先设定的概率决定是否要实施任务间的知识迁移。文献[10]在MO-MFEA 算法的基础上引入粒子群优化[11-12]和差分进化策略[13-14],提出解决MTO 问题的新算法。实验结果表明,上述多任务优化算法比其对应的单任务优化算法的性能更好。后者的典型代表是文献[15]提出的全新多种群多任务框架,使用多个子种群同时解决多个任务,每个子种群对应于解决单个任务。文献[16]在多个种群的条件下,采用一种高效的知识迁移策略来促进多个任务的同时优化。大量实验表明,多种群MTO 框架由于能在多个种群之间互相独立,可以灵活解决多个任务的优化问题,因此比单种群MTO 框架更具有优势。尽管当前解决MTO 问题的算法较多,但这些算法涉及到衡量任务间相似度的研究很少,有些算法虽然包含衡量任务间相似度的策略,但步骤较繁琐,计算量较大,难以推广应用。
本文提出一种多目标多任务优化算法,基于自适应协方差矩阵的进化策略,从某个正态分布中采样产生种群个体,使种群分布特征具有规律性,并采用任务间种群的分布特征差异和分布距离衡量任务间的相似程度。设计一种从相似任务中寻找有价值的解,进而实施知识迁移的方法,并基于迁移学习的思想,对相似任务中的解实施K 最近邻(K-Nearest Neighbor,KNN)分类,以筛选出对目标任务更有价值的解。
1 相关工作
1.1 多目标多任务优化算法
多目标多任务优化是进化计算领域的一个重要研究方向。但目前大部分的多目标多任务优化算法主要解决2 个待优化任务的问题,较少涉及到研究超多任务优化问题。文献[17]阐明了使用进化算法解决现实生活中超多任务优化问题的可行性,当待优化的任务数量超过2 个时,为避免过高的时间开销,对于某个给定的目标任务,从其余任务中选择一个与目标任务最相似的辅助任务,进而实施任务间的知识迁移,因此衡量任务间的相似性是解决超多任务优化问题的核心。文献[18]从最优解之间的距离、适应度等级的相关性和适应值函数范围分析3 个方面衡量任务间的相似性。文献[19]提出一个协同性度量指标量化不同任务间的联系,这一度量指标可以从侧面证明任务间的知识迁移能够同时促进多个待优化任务的收敛性能。
基于任务间的相似性,为求解超多任务优化问题,文献[20]采用轮盘赌的方法为目标任务选择一个合适的辅助任务,某个与目标任务最相似的任务有较大的概率被选为辅助任务,从而通过迁移有用的知识来减少负迁移的产生。文献[21]通过同时考虑任务间的相似性和进化过程中知识迁移的累积奖励值,提出一种自适应辅助任务选择机制,采用KL散度衡量任务间的相似性,并基于强化学习的思想,构建关于种群进化过程中任务间知识迁移的累积奖励系统,选择出合适的辅助任务,并通过交叉的方式实现知识迁移。文献[22]基于任务间种群概率分布的差异自适应地学习任务间的联系,并根据进化过程中求得的不同任务种群间的联系,自适应调整知识迁移的强度。文献[21]和文献[22]中的算法均采用高斯分布来近似模拟种群的真实概率分布,但实际上,种群的真实分布通常是随机且不可预测的,且算法花费大量的计算资源在衡量任务间的相似度上,导致最终运行的效率较低。
1.2 自适应协方差矩阵进化算法CMA-ES
CMA-ES 算法[23-24]是目前性能较好、应用较多的进化策略之一,在中等规模的复杂优化问题处理上具有良好的效果。CMA-ES 算法的核心思想是:每一代种群的所有个体均从某个正态分布群体中采样产生,并通过调整协方差矩阵Ct和步长参数σt,使产生的种群个体尽可能往产生好解的搜索方向搜索,从而增强算法的收敛速率。CMA-ES 算法的具体步骤如下:
1)采样产生新的种群个体。在CMA-ES 算法中,进化过程中的每一代种群均从产生进化的种群个体,个体xi更新的表达式如式(1)所示:

其中:yi通过协方差矩阵Ct的特征分解Ct=BD2BT得到,即:

其中:B为正交矩阵;D为对角矩阵且其对角元素值为矩阵Ct特征值的平方根;I为单位矩阵。
2)进化路径的更新。在CMA-ES 算法中,每一代种群的进化路径均通过如下的方式构造[24]:

其中:pt表示在第t代的进化路径;c表示进化路径更新的累积学习率;μw表示均值的有效选择质量。
式(3)描述了种群分布均值的移动方向,将每一代种群进化过程中的移动方向做加权平均,使得种群中每个个体相反的进化方向分量相互抵消,相同的进化方向分量相互叠加,从而保证种群沿着最优的方向搜索。
3)协方差矩阵的更新。通过增大沿历史成功搜索最优方向的方差,即增大沿这些最优搜索方向的采样概率,避免算法把搜索资源浪费在无效的区域上。协方差矩阵的更新原理如式(4)所示[24]:
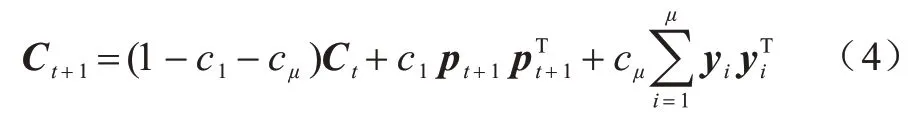
其中:yi表示当前种群中较优个体的搜索方向;c1和cμ表示协方差矩阵更新的学习率。
本文采用下述方法衡量任务间的相似度:基于CMA-ES 算法的思想,每一代种群在进化过程中,均从正态分布群体采样产生种群个体,即种群的均值和协方差矩阵可以反映当前种群的特征,因此通过种群的均值和协方差矩阵来表示任务之间的联系,从而为目标任务选择出一个最合适的辅助任务来实施知识迁移,加速目标任务的收敛进程。
2 本文算法
2.1 种群编码和解码
为便于在任务间高效地实施知识迁移,目前许多多任务优化算法采用统一空间表示法对不同任务的种群实施编码[9]。具体为,首先把所有任务的解集均编码到一个统一的搜索空间中。例如,给定K个待优化的任务{T1,T2,…,TK},将第i个任务决策空间的维度记为Di(i=1,2,…,K),定义所有任务统一的搜索空间维度为Dmax,且Dmax=maxi{Di},在种群进化的初始阶段,给所有任务种群中的每个个体都分配一个Dmax维的随机向量,该向量每个维度的变量范围为[0,1],通常把这个向量称为包含该个体所有遗传物质的染色体,该编码策略把所有任务中的种群都统一到共同的搜索空间中,以便于在不同的任务之间实施知识迁移。本文提出的衡量任务间相似度策略以及任务间知识迁移的方式均基于该编码策略,且均在统一的搜索空间中进行。
当要对某个特定的任务Ti中的个体实施评估时,必须把该个体的染色体解码为任务Ti对应问题的解。同时,对于任务Ti中的个体,只使用其对应染色体的前Di维变量。本文仅考虑连续优化的情形,例如对于任务Ti中某个解的第i维变量yi,其取值范围是[Li,Ui],若其染色体前Di维中对应的变量值为xi,则二者通过如式(5)所示的方式实现转换:

该解码策略把实际问题中的解与统一搜索空间中的染色体一一对应,通过在统一搜索空间中进行染色体间的杂交变异,从而在实际问题中增加每个任务最优解的多样性。
2.2 任务间相似度衡量
若有K个待优化的任务{T1,T2,…,TK},对于某个目标任务Tt,使用一个任务间的自适应相似度衡量策略来决定是否需要为目标任务Tt分配一个辅助任务,以实施知识迁移,促进目标任务的优化进程。该策略包含2 个部分:任务间种群分布特征差异的衡量及任务间种群分布距离的衡量。根据CMA-ES 算法的原理,每个任务的种群个体经过正态分布采样后,用种群的协方差矩阵表示种群的分布特征,用任务间种群均值之间的距离表示任务间的分布距离,从而衡量出任务间的相似性。
2.2.1 任务间种群分布特征差异
给定任务T1的种群P={P1,P2,…,Pn}以及任务T2的种群Q={Q1,Q2,…,Qn},他们分别从正态分布中采样而来。每个任务中种群的协方差矩阵可以近似看作种群沿着最优解搜索方向的集合,因此衡量任务间种群的协方差矩阵之间的差异可以度量任务间种群分布特征的差异(种群中的所有个体均沿着最优解方向搜索)。基于主成分分析(Principal Component Analysis,PCA)的思想衡量任务T1和任务T2中种群协方差矩阵之间的差异。
首先,对任务T1和任务T2中种群的协方差矩阵分别实施特征分解:

接着,分别从E1和E2中选出k个特征向量,这些特征向量对应C1和C2中最大的k个特征值,根据PCA 中的可解释方差比例指标,若保留的这k个主成分的累积方差贡献率大于等于95%,即选出的主成分至少能分别保留C1和C2中95%的信息,使用从E1和E2中选出的k个特征向量来构建种群P和Q的子空间Ps和Pt,即:

最后,由于Ps和Pt中的列向量均为单位向量,故对Ps和Pt中的列向量之间做内积,表示Ps和Pt中的列向量之间角度的余弦值。若Ps中的一个列向量为e1,从Pt中找到一个列向量f1,使e1和f1之间的余弦值最大(夹角最小),并记e1和f1之间的夹角为θ1。照此步骤执行k次,对应的夹角分别记为θ1,θ2,…,θk,采用这些夹角正弦值的平均值来表示任务间种群协方差矩阵之间的差异,即:
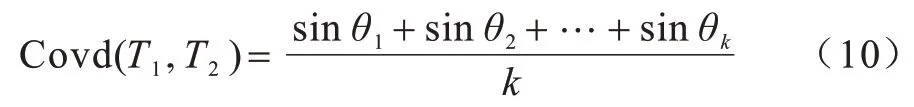
其中:Covd(T1,T2)的值越小,表明任务T1和任务T2中种群的分布特征越相似,即任务T1和任务T2中种群搜索最优解的方向越相似。
2.2.2 任务间种群分布距离
若任务T1的种群P和任务T2的种群Q分别从正态分布中采样产生,则任务T1和任务T2种群的均值可以分别看作任务T1和任务T2中种群的中心,因此任务间种群均值间的距离可以近似看作任务间种群的分布距离。
任务T1和任务T2之间的种群分布距离的表达式如式(11)所示:
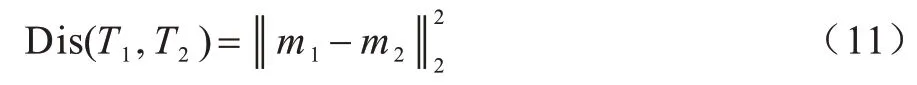
其中:任务T1和任务T2的种群均值间的距离(种群中心之间的距离)表示任务T1和任务T2的种群分布间的交叉程度。若任务T1和任务T2之间的种群分布距离较近,则在任务T1和任务T2之间实施知识迁移能够促进每个任务的优化进程。
2.2.3 任务间种群相似度衡量
基于CMA-ES 算法的思想,每个任务中的种群均通过正态分布采样产生,在种群进化的前期阶段,每个任务中的种群均朝着各自的最优解方向搜索,种群的协方差矩阵可以反映种群沿着最优解方向搜索时的分布特征,因此在种群进化的前期,任务间种群的相似度主要由任务间种群分布特征的差异决定。在种群进化的后期阶段,大部分任务中的种群已经收敛到了最优解,此时任务间种群的相似度主要由任务间种群分布的距离决定。采用式(12)来表达种群进化全过程中,任务T1和任务T2之间种群的相似度:

其中:λ表示任务间种群的分布特征差异和分布距离之间的权重值,令g表示当前的进化代数,m表示进化的最大代数。式(12)表示在种群进化的前期阶段,任务间种群的相似度主要由任务间种群分布特征的差异决定,在种群进化的后期阶段,任务间种群的相似度主要由任务间种群分布的距离决定。若Sim(T1,T2)的值较小,则表明任务T1和任务T2的Pareto 最优解的方向和位置较接近,在任务T1和任务T2之间实施知识迁移能够有效促进每个待优化任务的收敛进程。
2.3 任务间知识迁移策略
图1 所示为本文算法任务间知识迁移策略的具体流程图。可以看到,在种群进化的第g代,对于某个待优化的目标任务Tt,根据本文策略可以找到与目标任务Tt最相似的任务是Ta。依据迁移学习的思想,把目标任务Tt种群中的解分成两类,一类是非支配解,标记为“1”,另一类是支配解,标记为0,把这些解作为给任务Ta中解分类的源标签,本文采用K最近邻(KNN)分类,具体的分类方式为,对于任务Ta中的某个解P,找出目标任务Tt中距离解P最近的2 个解Q1和Q2,并记录他们的标签为La、Lb,若La+Lb=2,则把解P标记为“1”,否则记为“0”。接着,对于任务Ta中标记为“1”的解(近似目标任务中的非支配解),将他们迁移到目标任务Tt的种群中,从而促进目标任务的优化进程。若根据式(12)计算得到目标任务Tt与任务Ta的相似度在逐代降低,表明此时所有任务均与目标任务Tt不相似,为避免无效的迁移,应停止知识迁移,让目标任务Tt中的种群个体之间独立进化产生后代。
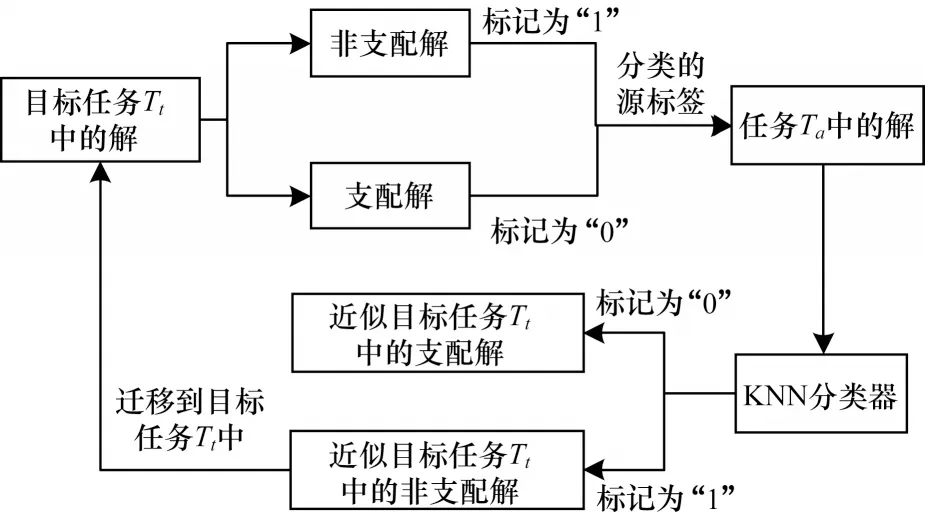
图1 任务间知识迁移策略流程Fig.1 Procedure of knowledge transfer strategy between tasks
2.4 算法整体框架
综合以上过程,本节给出解决多目标多任务优化问题的EMTSD 算法。若给定一个有K个任务的多目标多任务优化问题,EMTSD 算法通过进化K个独立的种群来同时优化这些任务。首先,EMTSD 算法初始化K个种群P1,P2,…,PK,并按照2.1 节中的策略将这K个种群中的所有个体均编码到一个统一的空间中,便于各个任务之间的知识实施互相迁移。然后,对于某个特定的目标任务Tt,按照2.2 节的过程,根据式(12)从其余K-1 个任务中找出当前与目标任务Tt最相似的任务Ta,并按照2.3 节的策略在目标任务Tt与任务Ta之间实施知识迁移,从而促进目标任务Tt的收敛进程。若在进化过程中发现目标任务Tt与其余任务的相似度降低,则停止知识迁移,让目标任务Tt种群内部中的个体独立产生后代。EMTSD 算法的具体框架如图2 所示。

图2 EMTSD 算法的整体框架Fig.2 Overall framework of the EMTSD algorithm
3 实验结果与分析
为验证本文算法EMTSD的性能,本文使用文献[25]提出的多目标多任务测试集,包括CIHS、CIMS、PIHS、PIMS 等,每个测试集由2个多目标优化问题(2个任务)构成。通过对这些测试集的Pareto Sets 进行旋转和平移,得到4 组新的多目标多任务测试集,分别记为MATP1~MATP4,这4 组测试集是基于任务间联系的先验知识创建的,任务间的联系通过多目标优化问题的Pareto Sets 重合程度来衡量。每个测试集包含5 个任务,这些测试问题的详细信息如表1 所示。

表1 多目标多任务测试问题信息Table 1 Information about multi-objective multi-tasking test problems
在上述4 组测试函数集的基础上,将本文算法EMTSD 与MO-MFEA-II[22]、MaTEA[21]、MO-MFEA[9]等多目标多任务算法进行比较。其中:MO-MFEA-II算法采用最小化任务间KL 散度的方式找出任务间的联系;MaTEA 算法采用KL 散度和自适应奖励策略的方式为目标任务选择一个最合适的辅助任务;MO-MFEA算法采用随机迁移的方式实施任务间的知识迁移。
3.1 实验参数设置
将实验中每个任务的种群规模设置为100,算法的最大进化代数为500代,算法的独立运行次数为20次。对于多目标多任务优化算法,多目标优化算法是NSGA-II。在DE算法中,令F=0.5、CCR=0.4。根据文献[24],CMA-ES算法中的步长参数σt=0.3,步长更新的阻尼参数dσ=1。根据文献[9],将MO-MFEA 算法中的随机交配概率值设置为0.3。根据文献[21],将MaTEA 算法中的知识迁移率设置为α=0.1,令精英集更新率UUR=0.2,精英集最大规模AAcS=300。MO-MFEA-II 算法中使用的概率模型为多元正态分布。
3.2 算法性能表征
本文采用反转世代距离(Inverted Generational Distance,IGD)来表征算法的性能。IGD 的原理是计算Pareto 最优解集中的点到算法最终得到的解之间的平均距离。IGD 的值越小,表明算法最终得到的解接近问题的Pareto 前沿界面且具有良好的分布性。IGD 值通过式(13)计算:

其中:dist(x,A)表示Pareto 前沿界面上的参考点x到算法最终求解得到的解之间的最小距离;P*表示Pareto 前沿界面上预设的参考点集合。
3.3 结果分析
表2 所示为EMTSD 算 法、MaTEA 算 法、MO-MFEA-II算法与MO-MFEA 算法在4 组多任务测试集下运行20 次得到的平均IGD 值,表中加粗数字表示该组数据最大值。

表2 不同算法在测试集下运行的平均IGD 值对比Table 2 Comparison of average IGD value of different algorithms running on the test suites
从表2 中可以看到,与其他算法相比,EMTSD 算法在大多数测试问题中均显示出卓越的性能,这是因为在每一代种群进化过程中,EMTSD 算法均从正态分布群体中采样产生新的种群个体,通过任务间种群的分布特征差异和分布距离找到任务间相似度,进而实施任务间的知识迁移,促进种群中解的多样性并加速目标任务的收敛。MaTEA 算法和MO-MFEA-II 算法均采用多元高斯分布来近似模拟种群的真实分布,然而这些算法中的种群个体通过杂交变异产生,并不像EMTSD 算法通过在多元高斯分布中采样产生种群个体,这样会导致真实的种群分布是随机且不可预测的,因此多元高斯分布通常很难准确近似为真实的种群分布。对于MO-MFEA 算法,由于缺乏衡量任务间相似度的步骤,因此在任务间随机进行知识迁移时,难以保证知识迁移会对目标任务起作用。然而,EMTSD算法在MATP2-T1、MATP2-T3、MATP2-T4、MATP2-T5、MATP3-T3、MATP3-T4、MATP4-T2这7 个任务中的性能比其他算法差。在实验中发现,测试问题集MATP2 和MATP3 中各个测试问题的Pareto Sets 之间较相似,因此在其他算法中,针对某个目标任务,从最相似的任务中随机选择解来实施知识迁移的策略,能够帮助目标任务跳出局部最优,找到更多分布性良好的最优解。
表3 所示为EMTSD 算 法、MaTEA 算 法、MO-MFEA-II 算法与MO-MFEA 算法在4 组多任务测试集下运行20 次的平均运行时间对比。由于EMTSD 算 法、MaTEA 算法和MO-MFEA-II 算法衡量任务间相似度的方式不同,因此每个算法在衡量任务间相似度方面花费的计算资差异直接影响了各个算法最终运行时间的差异。

表3 不同算法在测试集运行时的平均运行时间对比Table 3 Comparsion of average running time of different algorithms s
由表3可知,EMTSD 算法的运行时间比MaTaE 算法和MO-MFEA-II算法都要短,MO-MFEA-II算法运行的时间最长。这主要是因为MO-MFEA-II 算法需要构建概率模型来近似种群的真实分布,而求解该概率模型需要花费大量的计算资源。此外,EMTSD算法在4组多任务测试集下的平均运行时间比MaTEA 算法缩短约66.62%。尽管MO-MFEA 算法只需要很短的运行时间,但它缺乏衡量任务间相似度这一步骤,随机实施知识迁移的做法会导致算法的性能较差。
为验证EMTSD 算法在衡量任务间相似度方面的有效性,表4 和表5 分别列出了EMTSD 算法在MATP1和MATP2测试集中计算得到的任务间相似度,其中“—”表示忽略该栏的值。由表4 和表5 可知,在MATP1 测试集中,任务T1与任务T2较相似,任务T3与任务T4较相似,任务T5与其他任务之间的相似度较低。在MATP2 测试集中,任务T1与任务T2之间、任务T3与任务T4之间的相似程度均较高,任务T5与其他任务之间的相似度较低。实验得出的结果与事先已知的任务间相似度高度吻合,因此可以说明EMTSD 算法衡量任务间相似度的方法是有效的。

表4 EMTSD 算法在MATP1 测试集中得到的任务间相似度Table 4 Similarity between tasks in the MATP1 test set obtained by EMTSD algorithm

表5 EMTSD 算法在MATP2 测试集中得到的任务间相似度Table 5 Similarity between tasks in the MATP2 test set obtained by EMTSD algorithm
4 结束语
本文提出一种基于自适应协方差矩阵调整的多目标多任务优化算法,令所有任务中的种群个体均通过正态分布采样产生,并采用不同任务种群间的分布特征差异和分布距离得到任务间的相似度,从而找到与目标任务最相似的任务并实施知识迁移。采用种群的协方差矩阵反映种群的分布特征,使用不同种群均值之间的距离反映任务间种群的分布距离。实验结果表明,与EMTSD、MaTEA、MO-MFEA-II等多目标多任务优化算法相比,本文算法具有较好的收敛性能,平均运行效率提高了约66.62%。下一步将结合迁移学习中特征迁移的相关理论,使本文算法能应用于复杂的多目标多任务优化问题。
