基于位置和注意力联合表示的知识图谱问答
2022-08-12吴天波程军军何小海
吴天波,周 欣,,程军军,朱 晗,何小海
(1.四川大学 电子信息学院,成都 610065;2.中国信息安全测评中心,北京 100085)
0 概述
知识图谱问答的目标是针对输入的自然语言问题,系统自动地从知识图谱中找到答案,该答案是与问题最为匹配的实体或实体集合。若一个问题从主语实体出发,经过n条三元组到达答案所在的实体,就称该问题为n跳问题,对该问题进行回答的过程称为n跳问答。自动问答在发展初期主要针对较为简单的单跳问题,随着自然语言处理技术的不断发展,研究人员开始关注更加复杂的多跳问答。多跳问答中涉及的实体和关系数量较多,随着跳数的增加,搜索出正确关系路径的复杂程度呈几何倍数增长,如何匹配出多跳问题的正确答案是当前研究的热点与难点。
随着深度学习技术的不断成熟,基于表示学习的知识图谱问答方法越来越多。表示学习将三元组中的实体和关系表示为不同的向量,在向量空间中计算不同对象之间的相似度,进而完成知识图谱问答任务。许多学者对知识表示学习展开研究,构建出一系列具有代表性的翻译模型:BORDES 等[1]提出的TransE 将尾实体表示为头实体向量和关系向量之和;WANG 等[2]提出的TransH 把头实体和尾实体映射到关系所在的向量空间;LIN 等[3]提出的TransR将实体和关系映射到不同的向量空间进行处理。许多神经网络模型也被用于知识表示学习:ConvE[4]把头实体和关系拼接在一起,并用卷积层和隐藏层网络挖掘它们的特征;CapsE[5]采用胶囊网络,通过卷积层提取特征信息;K-BERT[6]基于BERT 模型,通过引入软位置和可见矩阵来限制知识噪声的影响。
基于表示学习进行知识图谱问答的主要思想是学习问题和知识库在低维空间的向量表示,并通过答案选择策略来与候选答案进行匹配,从而得出正确答案。DONG 等[7]利用多层卷积网络对问题和三元组学习低维空间的表示;YIH 等[8]定义一种查询图的方法,用深度卷积神经网络处理分阶段搜索问题,从而匹配问题和谓词;陈文杰等[9]构建一种基于TransE 的TransGraph模型,该模型同时学习三元组和知识图谱网络结构特征,以增强知识图谱的表示效果;DAI 等[10]基于条件聚焦的神经网络CFO,对大规模的实体信息表示进行泛化;SUN 等[11]提出“Pull”操作智能化扩充查询子图,进而分类判断正确答案;LAN 等[12]提出改进的分段查询图生成方法,利用该方法修改候选查询图,执行排名最高的查询图以获取答案实体;SAXENA 等[13]将问题嵌入到与三元组相同的表示空间中,通过相同的打分函数计算候选答案得分;金婧等[14]设计一种融合实体类别信息的类别增强知识图谱表示学习模型,其结合不同实体类别对于某种特定关系的重要程度及实体类别信息进行知识表示学习。
本文提出一种基于位置和注意力联合表示的知识图谱问答方法。结合复数域编码思路表示三元组的特征,通过基于向量融合表示的答案预测方法构建端到端的知识图谱问答模型,并在三元组分类和多跳问答的公开数据集上进行实验以验证该方法的分类性能。
1 相关工作
1.1 位置编码
自Google 提出Word2vec[15]模型 以来,出现了许多词嵌入模型,其中一个重要的上下文信息就是位置信息。复数域编码是一种能够让模型精准挖掘更复杂位置关系的相对位置编码方法,其通过在复数域计算位置编码以表征输入特征的上下文关系。TROUILLON 等[16]通过复数域的嵌入处理多种二元关系,SUN 等[17]在复数域构建旋转模型以对各种关系模式进行建模和推断,WANG 等[18]定义复数域的连续函数,将复数表示中的虚数与具体的物理意义联系起来。复数域编码使用关于位置的连续函数来表征一个词在某个位置的向量表示,例如在一段文本中,一个位置嵌入向量为Ppos的词ωj可以表示为实数域的函数f(j,Ppos),若将实数域看作复数域的子集,为不失一般性,定义此函数的值域在复数域中,则有:

其中:g为复数域的连续函数。当g满足一定条件时,可将其改写为指数形式:

其中:振幅rj只和词在词表中的索引有关,表示词的含义,和普通的词向量对应;相位ωj Ppos+θj既和词本身有关,也和词在文本中的位置有关,对应一个词的位置信息。
1.2 关系循环神经网络
关系循环神经网络[19]是SANTORO 等在2018 年提出的一种用于NLP 中特征提取的网络结构,其在提取特征的过程中引入记忆的交互,能够对序列进行关系推理,在处理实体与关系中涉及记忆间联系的任务时效果显著。网络通过引入多头注意力机制,构建与RNN 神经元类似的关系记忆核(Relational Memory Core),使模型能较好地运用于具有记忆交互的任务中。关系记忆核结构如图1 所示。

图1 关系记忆核结构Fig.1 Structure of relational memory core
关系记忆核的内部结构与LSTM、GRU 等类似,循环利用上一时间步的输出并作为记忆信息输入到网络中,通过门控单元控制当前时刻的输出状态,并利用注意力机制引入记忆间的交互。该结构维护一个记忆矩阵M,其行数为N,每一行代表一个记忆槽位。首先将当前时刻的输入和记忆信息共同送入多头点积注意力[20]模块中,将其与记忆矩阵M通过残差连接[21]得到的残差和送入多层感知机中,再次计算残差和,当前时刻的输出由MLP 的输出和记忆矩阵M共同决定。设当前时刻为t,用Mt表示当前时刻的记忆矩阵,其计算公式如下:


2 知识图谱问答模型
2.1 三元组表示
三元组的表示学习大致可以分为编码器网络和解码器网络2 个部分,编码器网络将三元组映射到表示学习空间中,解码器网络则从三元组编码中挖掘相关特征用于后续操作。本文参考复数域编码中振幅和相位的物理含义,提出一种基于位置-注意力联合编码的三元组表示模型Pos-Att-complex,其结构如图2 所示。编码器在复数域求解三元组注意力和位置特征的联合编码,得到三元组表示并送入解码器网络;解码器网络如图2 中上半部分虚线框中所示,用于提取来自编码器输出的三元组编码向量的相关特征。

图2 三元组表示总体模型结构Fig.2 Overall model structure of triple representation
解码器网络在得到三元组编码向量后,将向量分别经过关系循环神经网络层和卷积池化层,最后通过全连接层和Sigmoid 函数输出,得到范围为0~1的三元组得分。
Pos-Att-complex 编码器结构如图3 所示。在Batch Loader中,对正样本的补集随机生成与Batch大小相同、互不重复的头实体id 和尾实体id,以50%的概率随机替换正样本中的头实体或尾实体,得到和正样本与负样本等量的混合样本,同时输送到实数域链路和复数域链路,供三元组分类任务训练使用。
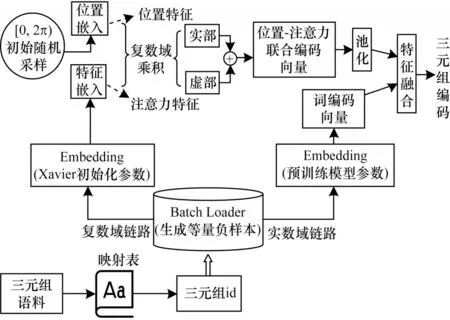
图3 Pos-Att-complex 编码器结构Fig.3 Stucture of Pos-Att-complex encoder
在实数域链路,三元组通过预训练模型得到词编码向量m1。在复数域链路,三元组id 通过Xavier[22]随机初始化参数做词嵌入,得到特征嵌入向量m2,其表征三元组的注意力特征。同时,对[0,2π)的区间进行初始均匀随机采样,得到位置嵌入向量Ppos,其表征三元组的位置特征。对特征嵌入向量与位置嵌入向量进行复数域乘积,分别得到复数域表示的实部Re和虚部Im:

将实部和虚部相加,得到位置-注意力联合编码向量m3:

在对实数域链路的词编码向量和复数域链路的位置-注意力编码向量进行特征融合之前,为缓解训练过程中由过拟合带来的泛化性能瓶颈问题,对位置-注意力编码向量采用池化策略。具体地,对一个Batch 上的向量做池化运算,然后与词编码向量进行特征融合,如下:

其中:pool 为池化函数,通常有最大池化(Max Pooling)和均值池化(Mean Pooling)2 种方式,分别取整个维度上的最大值和平均值作为输出为池化后的位置-注意力联合编码向量。
对复数域链路和实数域链路的三元组表示向量进行特征融合,通过加权和的方式得出最合适的三元组编码向量m:

其中:α为待训练的参数,其初始值设置为1。
2.2 知识图谱问答
图4 所示为多跳问答的总体流程,通过主语实体将问题与知识图谱进行匹配,定位出与问题相关的三元组路径。
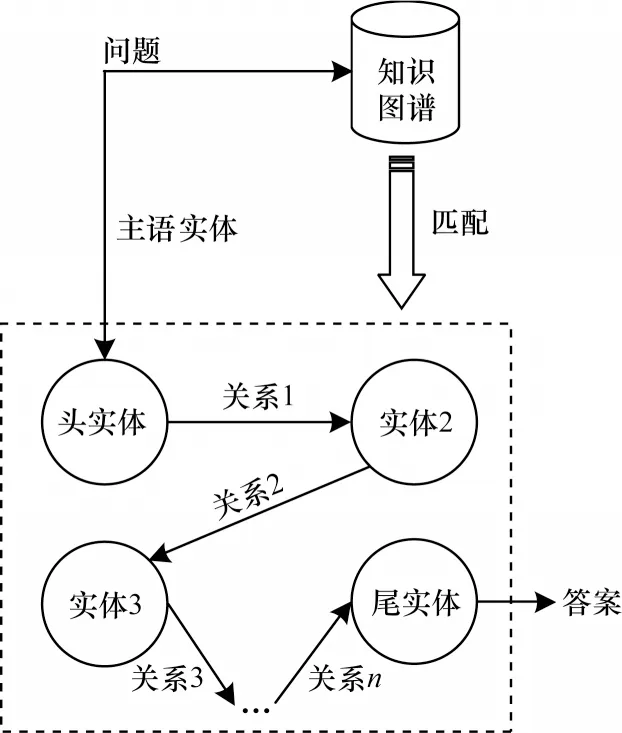
图4 多跳问答总体流程Fig.4 Overall procedure of multi-hop question-answering
结合三元组表示方法,本文构建一种基于向量融合表示的端到端知识图谱问答模型,如图5 所示。

图5 知识图谱问答模型结构Fig.5 Stucture of knowledge graph question-answering model
知识图谱问答模型分为问题嵌入、关系筛选、向量融合、答案预测4 个模块,通过各模块协同来完成知识图谱问答任务:
1)在问题嵌入模块中,问题q通过RoBERTa[23]做词嵌入,然后输入到N层的线性层中,进一步学习问题的表示,最后通过一层工厂层,将特征向量的维度转换为三元组嵌入的维度,得到问题嵌入向量vq。
2)关系筛选模块筛选出与输入的问题可能相关的所有关系,得到关系集合R,将其作为三元组编码器的输入之一,同时为向量融合模块提供支撑。关系筛选模块具体流程如图6所示,首先将问题q中的主语实体h送入查询图生成器中,查询图生成器对知识图谱中的所有关系进行初步筛选,生成关系候选集R0,生成步骤为:以h为中心节点,不限制跳数地遍历所有与h有关联的关系链,直到没有节点可以扩展出新的关系链,从而得到这些关系的集合R0。在得到R0后,对其做进一步筛选,使输出到后续模块的信息尽可能精确。一方面,针对R0中的每个关系r,计算问题q和r的语义相似度,将相似度分数s大于0.5 的关系构成一个集合,记为R1。在计算语义相似度时,将q通过RoBERTa 后得到q0,将其与r计算点积,然后通过Sigmoid 函数得出它们的相似度分数s,计算公式如下:
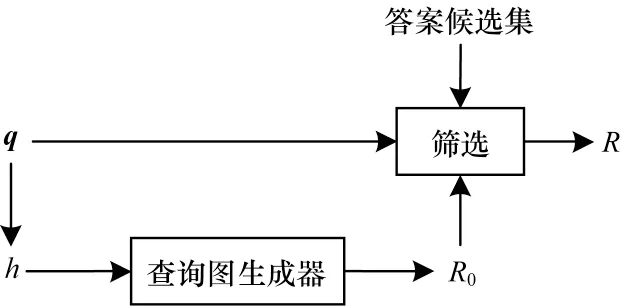
图6 关系筛选模块流程Fig.6 Procedure of relational filtering module

另一方面,针对知识图谱所有三元组答案实体ta,筛选主语实体h到ta之间的最短关系路径,将所有最短路径中包含的关系构成另一个集合,记为R2。综上,R1包含了与问题q可能有关的所有关系,R2包含了主语实体h到所有可能答案实体的最短路径中的关系。本轮问答最有可能涉及的关系应该处于上述两者的交集中,因此,对R1和R2进行交集运算,得到所需的关系集合R:

3)在向量融合模块中,首先对R中的每个关系进行编码,通过Pos-Att-complex 编码器得到关系向量的集合VR。为了表示关系集合中的向量并与问题向量较好地融合,对VR中的所有关系向量计算均值,然后将其与vq相加,实现关系和问题向量的融合表示。设R中关系的数量为nR,模块输出的融合表示向量为vr′,其计算公式如下:

4)答案预测模块通过计算答案预测的分数,输出得分最高的答案,得到候选答案向量集合VA,其中的每一个向量代表一条三元组中的尾实体向量。将VA中的每个向量与vh、vr′组合构成三元组编码,送入Pos-Att-complex 解码器,对三元组进行打分,得到的分数就代表问题与所输入答案的匹配程度。在解码器的输出中,记录vh、vr′与每个候选答案之间构成的三元组得分,即答案预测分数,取分数最高的三元组对应的尾实体,该尾实体即为预测的答案。
3 实验结果与分析
3.1 数据集与实验环境
WN11 和FB13[24]是用于评估基于知识图谱的三元组分类准确率的权威基准数据集,通过模型分类真假三元组的能力来衡量模型对三元组进行表示学习的效果。三元组分类数据集规模如表1 所示,2 个数据集分别拥有11 和13 类关系、万级的实体数量和十万级的三元组数量,其中,训练集中只有真实三元组,在训练时从Batch Loader 中生成错误三元组,验证集和测试集中同时拥有真实三元组和错误三元组,用于计算模型的分类准确率。

表1 三元组表示数据集规模Table 1 The size of triple representation datasets
MetaQA[25]是目前公开的一个大规模多跳知识图谱问答数据集,在通用语料的电影领域有超过40 万个问题,分为1 跳、2 跳和3 跳的问答对,同时提供一个包含约13.5 万条三元组、4.3 万个实体的知识图谱。MetaQA 问答数据集规模如表2 所示,在该数据集上,每个问题的主语实体都已经被标注出,模型可直接从中提取主语实体。

表2 MetaQA 数据集规模Table 2 The size of MetaQA dataset
本文模型训练所在的计算机环境为Ubuntu 16.04 操作系统,所用显卡为Nvidia GTX 1080Ti,深度学习框架为CUDA 10.0 和Pytorch 1.6.0,编程语言及版本为Python 3.6.10,使用的梯度下降优化器为Adam 优化器[26]。
3.2 三元组分类
在使用WN11 和FB13 数据集训练模型之前,需要选取模型的超参数和预训练的词嵌入模型。针对WN11 和FB13 数据集,本文分 别选取GloVe[27]和TransE[1]作为Pos-Att-complex 编码器中实数域链路的预训练词嵌入模型。WN11 和FB13 这2 个数据集的词嵌入维度都设置为50,学习率分别设置为1e−4和1e−6,总迭代轮次分别设置为50 和30。
模型每训练完一个轮次便计算一次当前参数下的验证集准确率,当且仅当验证集准确率比之前的轮次都要高时才保存并覆盖模型,最终得到验证集上效果最好的轮次下的参数,计算该参数下的模型在测试集上的准确率并作为测试结果,从而更加客观真实地反映模型的泛化性能。模型在编码器上进行池化时采用最大池化和均值池化2 种方式,WN11和FB13 上的测试结果如表3 所示。

表3 不同池化方式下的三元组分类结果Table 3 Triad classification results under different pooling methods %
从表3 可以看出,采用均值池化的模型测试准确率更高,分类效果更佳。本文模型Pos-Att-complex 采用均值池化的方法,表4 所示为该模型与近几年公开的主流模型之间的测试结果对比。

表4 5 种模型的测试结果对比Table 4 Comparison of test results of five models %
在表4 中,TransD[28]、TranSparse[29]和TransAt[30]为近年来效果较好的改进翻译模型,R-MeN[31]使用较新的关系循环神经网络来提取特征,本文Pos-Attcomplex 模型参考了其应用关系循环神经网络的方式,提出的位置-注意力联合表示方法使模型在WN11 上取得了更高的准确率,并且在2 个数据集上的测试结果平均值高于R-MeN 模型,但在FB13 上的结果还有一定提升空间。同时值得注意的是,本文在对复数域编码经典模型ComplEx[32]进行三元组分类的代码复现中发现,相对于WN11 数据集,学习率的设置对FB13 数据集的影响更大,不同的损失函数设置、归一化方法以及硬件算力都可能对实验结果产生影响。
3.3 知识图谱问答分析
知识图谱问答模型的问题嵌入模块通过4 层线性层挖掘问题特征。模型在每个数据集上至多训练200 个轮次,并设置早停等待轮次为12,当模型超过12 个迭代轮次后在验证集上仍未出现更高的准确率时就停止训练,同时保存在验证集上准确率最高的模型。在3 个数据集上完成训练后保存3 个模型,依次在各个测试集上计算问答的准确率,将本文模型的测试结果与近几年公开的模型进行对比,如表5所示。
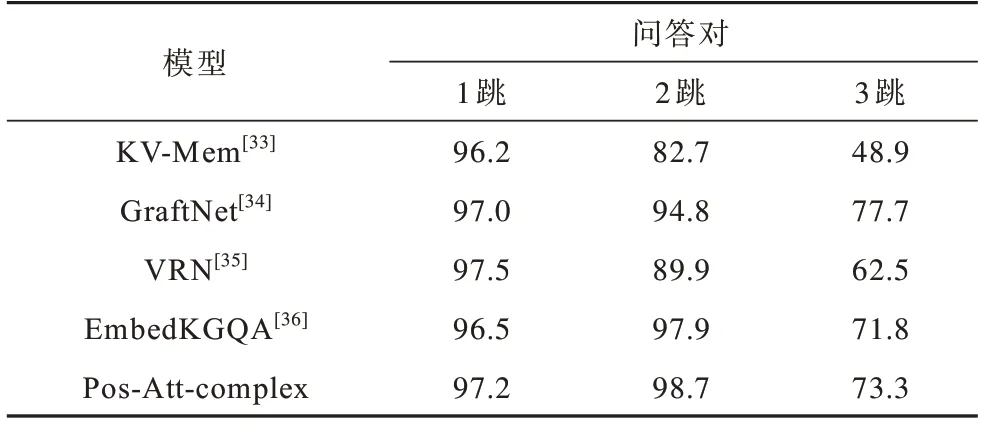
表5 5 种模型的问答结果对比Table 5 Comparison of question-answering results of five models %
KV-Mem[33]是EMNLP 2016上提出的模型,其通过维护一个键值对形式的内存表进行问答对检索;GraftNet[34]是EMNLP 2018 上提出的模型,其使用启发式方法从文本语料库中创建特定的问题子图进行问答推理;VRN[35]是AAAI 2018 上提出的使用变分学习算法来处理多跳问答的模型;EmbedKGQA[36]是ACL 2020上提出的在表示学习空间求解知识图谱问答的模型,其将问题嵌入到与知识图谱相同的表示空间中,用复数域编码经典模型ComplEx[32]处理三元组的嵌入,并用相同的打分函数选取最优答案,为了对比改进效果,表中该行数据记录了本文在相同的实验环境下对该模型的复现结果。本文基于向量融合表示的答案预测方法结合三元组表示学习模型,通过关系筛选、向量融合等策略,对问题与三元组的匹配做出进一步约束,从表5可以看出,相对其余4 种模型,本文模型的准确率都有一定程度的提高,综合能力表现较优。
3.4 消融实验分析
为了验证本文所提三元组表示和知识图谱问答方法的有效性,对其分别进行消融实验。在三元组分类实验中,在不进行池化和不采用复数域链路编码的情况下训练模型,相同实验条件下模型的测试结果如表6 所示。
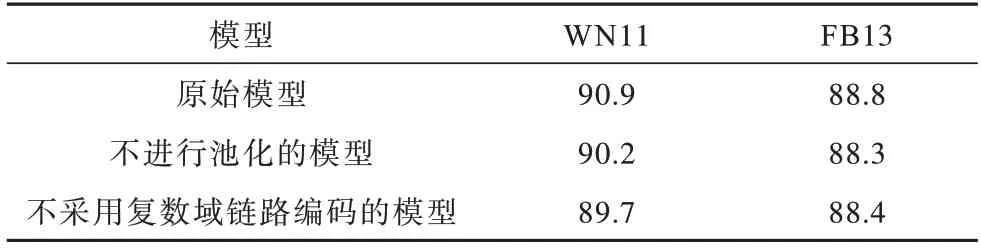
表6 三元组分类消融实验结果Table 6 Triple classification ablation experimental results %
从表6 可以看出,采用复数域编码和均值池化的原始模型测试准确率最高,不进行池化的模型的准确率在WN11 和FB13 上分别下降0.7 和0.5 个百分点,不采用复数域链路编码的模型的准确率分别下降1.2 和0.4 个百分点,因此,复数域编码对模型性能的影响较大。
在知识图谱问答的消融实验中,在其他条件不变的情况下取消向量融合,直接将问题嵌入向量vq当作vr′输入Pos-Att-complex 解码器,在相同实验环境下训练模型,测试结果如表7 所示。

表7 知识图谱问答消融实验结果Table 7 Knowledge graph question-answering ablation experimental results %
从表7 可以看出,当取消向量融合时,模型在1 跳~3 跳数据集上的准确率均出现了不同程度的下降,从而验证了向量融合策略的有效性。
4 结束语
本文构建一种基于位置和注意力联合表示的知识图谱问答模型。通过Pos-Att-complex 三元组表示模型将知识图谱中的三元组映射到表示学习的向量空间中,通过三元组分类任务对模型参数进行训练。在知识图谱问答模型中,基于已有知识表示学习模型提出基于向量融合表示的答案预测方法,以问题嵌入、关系筛选模块作为基础,向量融合模块作为核心,通过答案预测模块输出结果,从而实现端到端的知识图谱问答。该模型在三元组分类的权威基准数据集和多跳问答基准数据集上均取得了较好的测试结果,准确率相比近几年提出的公开模型均有一定提升,同时,对复数域编码和向量融合策略的消融实验结果验证了本文方法的有效性。但是,本文模型引入了较多的训练参数,使得三元组编解码器和知识图谱问答的模型训练耗时较长,间接导致三元组分类和知识图谱问答的周期延长,下一步将针对模型训练效率进行优化以解决上述问题。
