基于特征联合与多注意力的实体关系链接
2022-08-12付林,刘钊,邱晨,4,高峰,4
付 林,刘 钊,邱 晨,4,高 峰,4
(1.武汉科技大学计算机科学与技术学院,武汉 430065;2.湖北省智能信息处理与实时工业系统重点实验室,武汉 430065;3.武汉科技大学大数据科学与工程研究院,武汉 430065;4.国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室,北京 100083)
0 概述
近年来,随着知识图谱的发展与完善,基于知识图谱的问答系统成为当前的一个研究热点[1-3]。基于知识图谱的问答通常也称为知识库问答(Knowledge Base Question Answering,KBQA)[4],允许用户从知识库中直接获取自然语言问题的答案。KBQA 中的一个重要方向是语义解析(Semantic Parsing,SP),是指将自然语言问题转换成逻辑形式的查询。基于语义解析的问答系统包括3 个子任务[5]:实体链接,是指从自然语言问题中识别出实体提及并将其正确链接到知识库中对应的实体上;关系链接,是指从自然语言问题中抽取出关系关键字并将其映射到知识库中对应的关系上;查询构建,将实体链接和关系链接的结果相结合构建结构化查询语句,例如:SPARQL 查询语句最后执行查询语句,得到问题的答案。
现有的实体链接和关系链接工作存在以下问题:传统的实体链接和关系链接作为独立的任务执行,使得实体链接不能从关系链接中获得的信息中收益,关系链接也无法从实体链接中获得有益信息,忽略了两者链接中产生的信息间的相互影响,为充分利用两者链接过程中的信息,DUBEY 等[6]提出EARL 模型进行联合实体关系链接,该模型虽在链接精度上有所提升,但在处理疑问词上存在限制;目前的实体链接和关系链接过程忽略了问题本身带来的信息,通常只关注识别出来的关键词,未能充分考虑问题的整体信息,YU 等[7]利用神经网络模型学习问题的整体信息,将问题表示信息引入链接过程,文中将实体链接和关系检测作为依赖的顺序任务执行,并未充分考虑候选实体和候选关系的内在联系;KBQA 系统中的实体链接和关系链接方法在简单问题上表现效果较好,在包含多个关系词的复杂问题上就显得难以应对[8],但由于信息量的剧增,人们对于多关系问题的问答需求量也急剧上升。
针对上述问题,本文提出一个基于神经网络的利用特征联合和多注意力的联合实体关系链接方法。首先将实体链接和关系链接联合起来在同一阶段执行,并加入由实体-关系对信息组成的特征序列来联合表示实体词以及关系词,强化实体和关系之间的内在联系,提高链接精度。然后利用神经网络模型对问题、实体词以及关系词进行编码表示学习,充分挖掘深层语义信息,并添加多个注意力获取实体词和关系词在问题中的权重信息,加强相关候选词在问题中的特征表示以促进链接过程。
1 相关工作
知识图谱问答旨在通过外部的知识库回答自然语言问题。早期的KBQA 工作关注于简单问题。近年来,研究人员在回答复杂问题上的关注度逐渐提高[9-10]。复杂问题一般涉及多跳推理、约束关系、数值运算等[8]。通常来讲,复杂问题中包含不止一个实体词和关系词,当问题中存在多个实体词和关系词时,将问题中的实体词和关系词链接到知识库中对应的实体和关系上会变得困难[11]。基于上述问题,实体链接和关系链接作为基于语义解析的KBQA 系统的两大子任务被提出。
实体链接包括命名实体识别和消歧,指从自然语言问题中识别出实体提及并将其正确链接到知识库中对应的实体上。DBpedia Spotlight[12]基于实体的矢量空间表示,计算候选实体集与实体提及的余弦相似性。HOFFART 等[13]和HAN 等[14]都是先构建mention-entity图,前者使用密度子图算法进行实体链接消歧,而后者使用随机游走算法计算实体链接概率。Babelfy[15]使用随机游走算法和高一致性语义解释的最密集子图启发式算法将实体链接和词义歧义消除联合执行。FOX[16]基于集成学习的思想进行命名实体识别。然而,将这些算法应用到短文本实体链接时,性能会降低。考虑到自然语言问题简短性的特点,TagMe[17]基于维基百科知识,首先识别非结构化文本中已命名的实体并将其链接至Wikipedia中,然后使用页面数据集消除歧义。随着词嵌入在知识图上的迅速流行,一些研究开始将嵌入算法用于实体链接。YAMADA 等[18]使用知识图谱模型和锚框上下文模型扩展跳跃式模型,构建一个新颖的词嵌入方式,将单词和实体嵌入到相同的向量空间中计算相似性。NTEE[19]将文本的分布式表示和知识库中的实体进行联合学习,能较为容易地预测出文本中的实体。关系链接研究如何将问题中的关系词与知识图谱中的关系候选词进行匹配并消歧。SINGH等[20]提出基于语义类型关系模式的关系链接(SIBKB),检索PATTY[21]库扩充关系短语,基于动态索引计算关系词和知识库中谓词的语义相似性,排序候选关系。随着深度学习的发展,MULANG 等[22]将神经网络模型用于关系链接,对知识库属性及其底层短语建模,检索出整个知识图谱中的所有属性,形成一个属性池,计算属性池中的每一个谓词和问题中关系候选词的相似性,从而对候选词进行排序。YU 等[7]通过残差学习来提升层次RNN 网络的性能,进而进行关系检测排序候选关系。以上方法均将实体链接和关系链接作为独立的任务完成,忽略了问题中实体词和关系词的内在联系。
DUBEY 等[6]提出的EARL模型以及SAROR等[23]提出的Falcon 模型将实体链接和关系链接联合执行,实现联合实体关系链接。EARL 模型提出了两种不同的解决方案:1)将联合链接任务看作是广义旅行商问题(GTSP)的一个实例,且由于GTSP 是一个NP 难问题,文中采用近似算法求解;2)采用机器学习的方法学习知识图谱中节点的链接密度,并依赖3 个特征进行重新排名来预测知识图谱中的实体和关系。该模型虽在复杂问题上的性能优于现有方法,但在处理疑问词上存在限制。Falcon 模型使用轻量级语言学方法实现联合链接来扩展知识图,并利用英语形态学的几种基本原则来排序候选集。该模型由于引入了拓展知识图,在召回率上表现出色,但该模型忽略了问题本身带来的深层语义信息对链接 过程的 影响。ZAFAR 等[24]的MDP-Parser 模型通过基于强化学习的远距离监督学习框架来学习问题中的实体提及以及关系提及,提出一种更加准确的问题浅层解析方法。由于其更关注问题解析过程,在实体链接和关系链接上采取语义相似性和字符相似性的方法来进行消歧,但同样忽略了问题本身带来的深层语义信息对链接过程的影响。
本文提出一个基于神经网络的利用特征联合和多注意力的联合实体关系链接方法。该方法主要包含以下2 点:1)针对实体链接和关系链接作为独立的任务执行存在的问题,将实体链接和关系链接在同一阶段执行联合实体关系链接,强化实体和关系之间的内在联系,提高链接的精度;2)对于多关系复杂问题,运用深度学习的方法,采用神经网络模型将问题、实体词以及关系词转换成低维语义向量进行表示学习,加强相关候选词在问题中的特征表示促进链接的过程。
2 本文方法
为了提高实体链接和关系链接的精度,充分利用问题中实体词和关系词之间的联系,本文提出了一个基于实体-关系对信息的联合实体关系链接方法。本文方法框架如图1 所示,主要包含候选集生成模块和联合实体关系链接模块两个部分。以“where was the producer of Sherlock born”为例,通过候选集生成模块可得到实体候选词“Sherlock_(TV_series)”以及关候选词“producer”和“birthPlace”,将实体候选词和关系候选词组合起来得到的实体-关系对信息“Sherlock_(TV_series)#producer#birthPlace”与实体候选词以及关系候选词一并加入模型中进行训练,获取实体与关系的内在联系信息,最终链接到可信度较高的实体和关系。

图1 联合实体关系链接框架Fig.1 Framework of joint entity relation linking
2.1 候选集生成模块
给定一个自然语言问题,候选集生成模块包括关键词提取、实体/关系预测以及候选元素生成。
关键词提取:指从自然语言问题中提取出表示实体和关系的词语。常用的关键词提取工具是SENNA[25],它利用词向量来处理自然语言问题。例:where was the producer of Sherlock born,可用工具SENNA 提取到关键词“producer”、“Sherlock”、“born”。
实体/关系预测:指识别关键词中哪些是实体类型,哪些是关系类型。本文运用EARL[6]中的预训练模型来训练数据。模型的思路是使用知识图谱中的实体标签和关系标签来训练关键词,并采用硬参数共享的多任务学习方法处理OOV[26](Out-of-Vocabulary)单词以及编码网络模型中的知识图结构,从而提高该模型的泛化能力,减小参数大小。模型中自定义的损失函数如式(1)所示:

其中:εBCE表示某短语作为实体或关系的学习目标的二进制交叉熵损失;εED表示某短语的预测词嵌入和正确词嵌入之间的平方欧式距离;α是一个常量,通常设置为0.25。经预测模型可得:“Sherlock”为实体类型,“producer”和“born”为关系类型。
候选元素生成:对每一个识别出来的实体词和关系词都生成一个候选列表。本文采用ElasticSearch[27]索引字典来创建<元素,标签>索引,通过计算实体词或关系词和标签之间的余弦距离来表示两者之间的相似性。计算方法如式(2)所示:
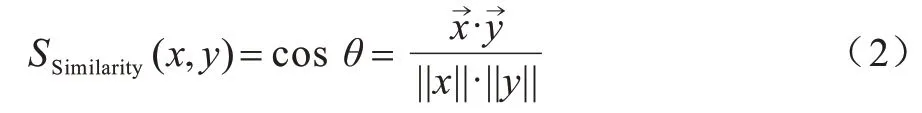
其中:x表示实体词或关系词;y表示元素的标签。为相似性设置一个阈值M,大于M的所有元素都会被当作实体词或关系词的候选元素。
例:where was the producer of Sherlock born,经过上述步骤后可得到3 个候选元素列表,如图2 所示。

图2 候选元素列表Fig.2 Lists of candidate elements
2.2 联合实体关系链接模块
在KBQA 系统中,实体链接和关系链接作为独立的任务执行。这样的执行方式使得实体链接不能从关系链接中获得的信息中收益,关系链接也无法从实体链接中获得有益信息,这在短文本自然语言问答中是不利于实体关系消歧的。基于上述问题,本文提出了联合实体关系链接的方法。
联合实体关系链接方法将实体链接和关系链接联合起来执行,充分考虑实体和关系的内在联系。通过神经网络模型以及注意力机制来训练模型,以此来学习问题与候选集的深层语义信息,从而选择实体与关系的最佳组合。如图3 所示,联合实体关系链接模块包括候选集表示、问题表示以及候选排序。

图3 基于特征联合及多注意力的实体关系链接框架Fig.3 Framework of entity and relation linking based on feature jointly and multi-attention
2.2.1 候选集表示
候选集表示将候选集中的元素映射到低维语义空间中进行语义表示,包括:关系表示,实体表示以及实体-关系对表示。通过这3 种表示可分别得到关系序列、实体序列以及特征序列。
关系表示是利用神经网络模型将关系候选词转换成低维语义向量,最终得到关系序列。将关系候选词分别从关系级别和单词级别输入词嵌入矩阵,获取其词向量表示,再通过一个双向LSTM 网络层,对结果执行最大池化操作,提取关系候选词的全局特征。
例:where was the producer of Sherlock born,经过候选集生成阶段得到关系候选词“producer”和“birthPlace”。对于关系候选词“producer”,其单词级别和关系级别的表示均为“producer”,而对于关系候选词“birthPlace”,在单词级别上可以表示为“birth”和“place”,在关系级别仍表示为“birthPlace”。将上述单词通过一个词嵌入矩阵输入双向LSTM 网络层,再通过最大池化层得到关系序列ri(i∊{1,2}),其中,r1表示候选关系r中的第1 个关系,r2表示候选关系r中的第2 个关系。
实体表示同样是利用神经网络模型将实体候选词转换成低维语义向量,最终得到实体序列。与关系表示不同的是,实体表示只是在单词级别上进行低维语义空间的嵌入。
例:where was the producer of Sherlock born,经过候选集生成阶段得到实体候选词“Sherlock_(TV_series)”,将其通过词嵌入矩阵得到向量表示。再将向量依次通过双向LSTM 网络层以及最大池化层得到实体序列e。
实体-关系对表示是将实体候选词与关系候选词组成的实体-关系对从单词级别输入词嵌入矩阵,得到向量表示,再通过一个双向LSTM 网络层,对输出结果执行最大池化操作,提取实体与关系联合表示的特征序列。
对于候选词“Sherlock_(TV_series)”、“producer”和“birthPlace”,它们在单词级别上的表示分别为“Sherlock_(TV_series)”、“producer”、“birth”、“place”。将它们通过一个词嵌入矩阵输入双向LSTM 网络层,再通过最大池化层得到实体与关系联合表示的特征序列f。
2.2.2 问题表示
问题表示是利用神经网络模型对问题进行编码得到深层语义向量,进而获取问题中的每个单词在整个句子中所占的比重来表示问题的整体特征。同时,由于问题中每个单词的关注点不同,单词在实体候选集或者关系候选集中出现的次数越多,其被关注的程度就越高,故而在问题表示中添加注意力机制来加强问题与实体词和关系词的匹配程度。融入不同注意力的问题表示分别如图4~图6 所示。图4~图6 的处理流程相同,区别在于融入不同的序列来表示问题,便于后文计算各自的相似度。

图4 融入关系序列的问题表示框架Fig.4 Framework of representation pattern incorporating relation sequence

图5 融入实体序列的问题表示框架Fig.5 Framework of question representation incorporating entity sequence

图6 融入特征序列的问题表示框架Fig.6 Framework of question representation incorporating feature sequence
问题q的表示形式为x={x1,x2,…,xL},其中:L表示问题q中单词的个数;xi表示问题q中第i个单词的位置。将q中的每个单词通过词嵌入矩阵获得向量表示w={w1,w2,…,wL}。将w输入双向LSTM网络层,得到其隐 藏层表 示hi=[h1,h2,…,hL],i∊[1,L],其 中hi∊,dhe表示隐藏层的维度。
此外,考虑到每个候选词在问题q中占据不同的权重且决定着问题如何被表示,故而在问题表示中添加注意力机制来加强问题与候选词的匹配层度。注意力的程度体现在问句中每个单词的权重上,因此,融入了不同注意力的问题表示。
1)将候选集表示中的关系序列融入问题表示中。对于关系的第i个部分ri,问题表示的计算公式如下:
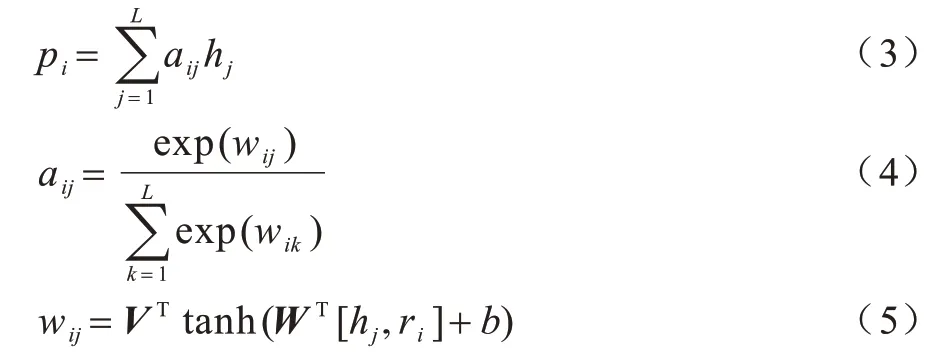
其中:i∊{1,2};pi指融入关系序列的问题表示;aij指在关系部分ri关注下问题中第j个单词的注意力权重,假设ri的维数为m;hj的维数为n,则W∊Rc×(m+n)和V∊R1×c分别是需要学习的参数(c为超参数);b为恒定参数。
2)将候选集表示中的实体序列融入问题表示中。对于实体部分e,问题表示的计算公式如下:

其中:pe指融入实体序列的问题表示;aj指在实体部分e关注下问题中第j个单词的注意力权重,假设e的维数为m,hj的维数为n,则W∊Rc×(m+n)和V∊R1×c分别是需要学习的参数(c为超参数);b为恒定参数。
3)将候选集表示中的实体-关系对组成的特征序列融入问题表示中。对于实体部分e,关系部分ri,i∊{1,2},问题表示的计算公式如下:

其中:pf指融入实体-关系对组成的特征序列的问题表示;a(f)j指在特征序列f关注问题中第j个单词的注意力权重,假设f的维数为m,hj的维数为n,则W∊Rc×(m+n)和V∊R1×c分别是需要学习的参数(c为超参数);b为恒定参数。
2.2.3 候选排序
将问题通过神经网络模型得到融入不同注意力的问题表示,然后结合问题表示从这些实体候选集和关系候选集中筛选出最适合的一组候选词作为结果返回。本文引入两种特征分数的计算结果来表示候选序列与问题表示之间的相似性:一种是联合的特征分数;另一种是独立的特征分数。联合的特征分数计算实体-关系对组成的特征序列与融入了特征序列的问题表示之间的相似性分数;独立的特征分数计算实体(或关系)序列与融入了实体(或关系)序列的问题表示之间的相似性分数。
对于融入特征序列的问题表示,问题表示与特征序列的相似性计算公式如下:

其中:⊗表示问题表示与特征序列之间的点积;S(P,f)表示问题表示与特征序列之间的相似性分数,采用sigmoid 函数将相似性分数映射到[0,1]之间。
在问题表示与特征序列的相似性分数下,关系链接计算公式如下:

其中:⊗表示问题表示与关系序列之间的点积;S(P,r)表示问题表示与候选关系之间的相似性分数;α和β是模型中训练的超参数。采用argmax 函数对结果求参数,最后得到关系Ssr。
在问题表示与特征序列的相似性分数下,实体链接计算公式如下:
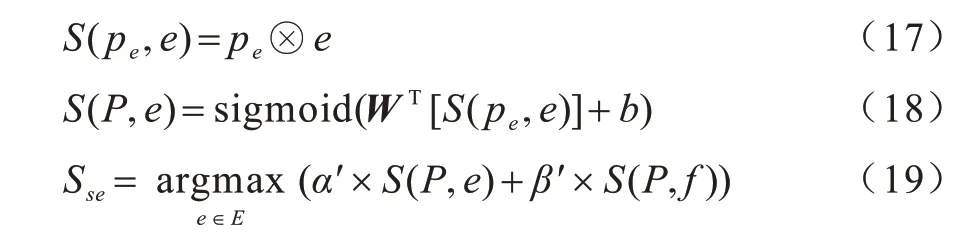
其中:⊗表示问题表示与实体序列之间的点积;S(P,e)表示问题表示与候选实体之间的相似性分数;α′和β′是模型中训练的超参数。采用argmax 函数对结果求参数,最后得到实体Sse。
上述模型经过排序损失训练来最大化候选集中正向实例和负向实例的比例。具体损失函数计算公式如下:

其中:Q表示问题集;E表示候选实体集;R表示候选关系集;γ设置为0.1。
3 实验
3.1 实验数据
实验采用两个标准的数据集LC-QuAD[28]和QALD-7[29]。LC-QuAD数据集中包含4 000个训练问题和1 000 个测试问题,QALD-7 数据集中包含215 个训练问题和50 个测试问题。LC-QuAD 数据集中大约有80%的复杂问题(此处复杂问题指问题中包含不止一个关系词),QALD-7 中复杂问题约占42%。
本文实验分别从两个数据集的训练集中提取问题、实体、关系以及实体-关系对作为训练数据,测试问题中提取的信息作为测试数据来验证本文提出的联合链接方法的有效性。
3.2 实验参数
本文实验的实验参数为关系候选词、实体候选词以及问题的最大输入长度在单词级别均设置为30,其中关系候选词在关系级别的输入长度设置为10,单词的词嵌入维度w为300,词向量在经过Bi-LSTM 层的输出维度d为200,最大池化层的窗口大小设置为400,实体、关系、问题的dropout 均为0.5,epoch 设置为10。嵌入层的词向量矩阵EW作为网络模型的参数,随整个模型一起训练更新。对于EW的初始化,本文实验使用预训练的词向量GloVe[30]初始化。在训练过程中,当验证数据集上的损失值在经过3 个epoch 没有下降时,说明模型性能没有提升,学习遇到瓶颈,此时学习率减小的动作会被触发,模型重新进行训练。
3.3 实验对比与结果分析
本文将近年来表现较好的实体链接和关系链接模型与本文方法进行了对比实验。其中最近的模型为文献[24]于2020 年提出的MDP-Parser 模型。本文选取MDP-Parser 模型中的评价标准作为对比参考,即选取实验中的精度(Accuracy)作为指标。
实体链接在两个标准数据集上的对比结果如表1所示。本文方法在LC-QuAD数据集上的精度值比MDPParser 模型提高了7 个百分点,在QALD-7 数据集上的精度值比MDP-Parser 模型提高了5 个百分点。由此可见,本文实体链接方法比MDP-Parser 模型具有更好的表现。

表1 实体链接在两个标准数据集上的精度对比结果Table 1 Comparison result of accuracy of entity linking on two benchmark datasets
关系链接在两个标准数据集上的对比结果如表2所示,其中N/A 表示不适用。本文方法在LC-QuAD 数据集上的精度值比MDP-Parser模型提高了1个百分点,在QALD-7 数据集上的精度值比MDP-Parser模型提高了17 个百分点。实验结果表明,仅依赖于语义相似性或者图算法不能获得更好的表现结果。
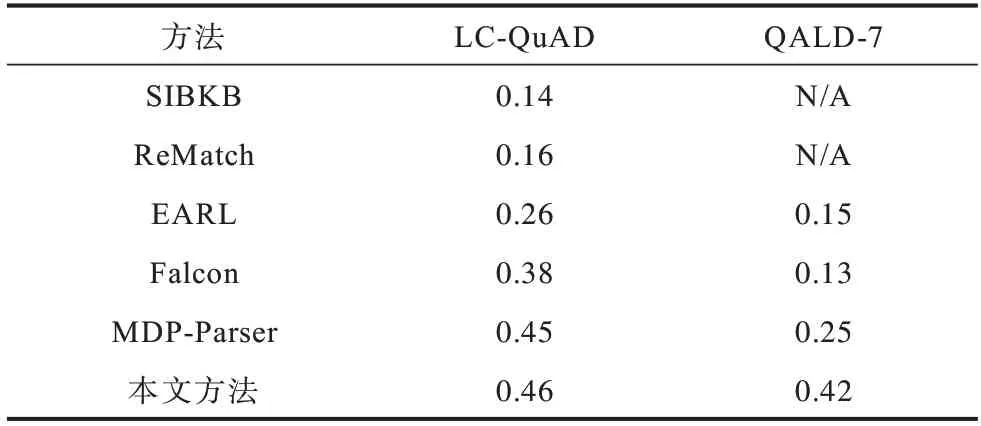
表2 关系链接在两个标准数据集上的精度对比结果Table 2 Comparison result of accuracy of relation linking on two benchmark datasets
LC-QuAD 数据集中约有80%的问题包含不止一个关系词,而QALD-7数据集中这样的问题大约占42%。对于关系链接来讲,QALD-7 数据集的问题中包含单个实体-关系对的问题数量较多,则更符合知识图谱中单个三元组的结构。在加入实体-关系对联合表示的特征序列进行向量表示学习时,实体与关系之间的联系更加紧密,且由于QALD-7 数据集中简单问题较多,更能提取到正确的关系提及,从而使得获取包含正确关系的关系候选集的概率增大,即本文方法在QALD-7数据集上的精度提升较大。
本文分别在两个数据集上通过消融实验来验证本文所添加的实体-关系对信息组成的特征序列对于实体链接和关系链接的有效性。如表3 所示,在实体链接中,当加入特征序列后,与不加特征序列相比精度明显提升,且在两个数据集上的结果优于SOTA 方法。由于在实体链接的相似性分数计算上加入了实体-关系对信息组成的特征序列与问题表示的相似性分数,因此可将实体词与关系词的内在联系中所包含的信息加入实体链接过程,提升实体链接的精度。如表4 所示,在关系链接的相似性计算过程中加入特征序列,可将实体-关系对中的内在联系信息加入关系链接过程,提升关系链接的精度。消融实验结果表明,在自然语言问题中,实体词和关系词之间存在联系以及相互促进的作用。

表3 特征序列在实体链接上的消融实验对比结果Table 3 Comparison result of ablation experiments of feature sequence on entity linking

表4 特征序列在关系链接上的消融实验对比结果Table 4 Comparison result of ablation experiments of feature sequence on relation linking
3.4 结果分析
本文通过分析发现,不能正确执行链接的原因主要有以下3 点:
1)当问题中的实体提及包含多个单词时,在提取关键词时不能得到完整的实体提及。例:What woman acted in the mating habits of earthbound humans and is often associated with Mams taylor,通常将“Mams taylor”作为一个实体提及识别出来,mating habits of earthbound humans 应当作为第2 个实体提及被提取出来,但由于单词数过多,在提取时将其分为“mating habits”和“earthbound humans”两个实体提及,这会导致实体候选集选取有误。
2)当问题中的实体提及是以它的缩写词形式或全称的部分形式出现时,生成相关的候选元素会变得困难。例:List the Sci-fi TV shows which theme music given by Ron Grainer,句中的“Sci-fi”会指向“Sci-fi”而不是“science fiction”。
3)复杂问题中关系的多样性也是造成错误的主要原因。例:What was the language of the single which came before To Know Him Is to Love Him,句中的隐式关系“before”无法被正确地识别为“previousWork”,从而导致关系链接错误。
4 结束语
随着知识图谱规模的日益增大,从知识图谱中充分挖掘出自然语言问题中的实体信息和关系信息有助于提升知识库问答系统的性能。本文利用深度学习的方法将问题、实体和关系在低维语义空间中进行向量表示学习,挖掘自然语言问题中的深层语义信息。通过在联合实体关系链接过程中添加实体-关系对信息组成的特征序列来联合表示实体词和关系词,强化两者间的内在联系,采用添加注意力机制的方法获取实体词和关系词在问题中的权重信息,以加强实体词和关系词在问题中的特征表示,从而提高链接的精度,改善KBQA 的中间环节。在两个标准数据集上的实验结果表明,与当前表现最好的Falcon 模型相比,本文链接精度均不低于1%,表明了本文方法的有效性。后续将加入推理规则来减少链接过程中由于隐式关系无法识别造成的链接错误,进一步提升本文方法的链接精度。
