基于时序区分子图的阿尔茨海默症辅助诊断方法
2022-08-12信俊昌郭恩铭张嘉正
信俊昌, 郭恩铭, 张嘉正
(东北大学 计算机科学与工程学院, 辽宁 沈阳 110169)
阿尔茨海默症(Alzheimer’s disease, AD)是一种严重的神经退化疾病,也是一场困扰全球的记忆危机.根据《中国阿尔茨海默症报告 2021》显示,60 岁及以上人群中有 1 507 万例痴呆患者,其中 AD患者高达983 万例.近年,功能磁共振成像(functional magnetic resonance imaging,fMRI)技术已经成为一种观察脑结构和功能的手段,并日趋成熟与完善.在fMRI图像中,人脑的不同脑区之间存在着连接与功能上的关联性,构建和分析脑网络可以更好地描述大脑的活动状态以及各个脑区之间的交互关系.生物标记物可在分子水平上为疾病提供敏感而稳定的诊断手段[1],通过寻找出两类具有特异性的标记物,用以阿尔茨海默症辅助诊断.
早期的阿尔茨海默症辅助诊断已被国内外广泛研究.在基于机器学习方法进行阿尔茨海默症诊断中,Jo等[2]采用深度学习方法构建卷积神经网络对从医学影像中提取的重要特征进行训练分类,从而进行诊断.Jie等[3]提出一种图核方法计算脑网络相似性从而实现疾病诊断;之后大量的新型图核不断被构建来优化算法[4].近几年,越来越多的研究将脑网络的纵向数据融入研究,通过从脑网络中提取重要特征(如脑体积、相应皮质区域面积等),再通过不同样例不同时间点取样的方法获取到脑网络的动态特征信息,然后进行基于神经网络模型的AD诊断.Nguyen等[5]提出使用minimalRNN模型进行时序信息填充,探究脑网络重要特征时序变化.Mansu等[6]提出可解释GNN模型,充分利用动态脑网络的纵向数据判断脑网络重要特征对辅助诊断的影响.
图论领域知识被引入到对脑功能网络的研究中,使得复杂的脑以一种抽象化的模型被不断深入研究.Cao等[7]就曾提出利用核磁共振脑网络的区分子图作为标记物诊断双相情感障碍问题.区分子图不仅能够反映脑网络的拓扑结构,还能够更容易地捕捉到病变区域网络内连接模式并反映正常人与患者之间的差异,可以作为阿尔茨海默症辅助诊断的生物学标记物.基于挖掘区分子图的算法也处于不断研发的进程中[8-9].尽管区分子图能够更好地反映脑网络的拓扑结构,还能够更容易地捕捉到病变区域网络内连接模式并反映正常人与患者之间的差异,可以作为神经精神疾病辅助诊断时的生物学标记物,但已有的研究成果主要基于提取静态脑网络的区分子图[10-11].静息态fMRI反映了被试者一段时间内的功能认知状态,构建静态脑网络往往会忽视时间维度上的信息,不能充分利用fMRI技术时间分辨率高的特点.相反,使用不同时间段构建的动态脑网络,能够表现大脑的动态连接变化,进而反映每一时间段大脑功能活动信息.为了更好地理解大脑功能活动需要充分利用时间信息,因此采用构建动态脑网络并且提出基于时序区分子图的方法进行阿尔茨海默症的辅助诊断.
综上所述,可以通过寻找一种可靠的生物标记物来进行早期的阿尔茨海默症的辅助诊断.不同于机器学习领域的思想方法,区分子图的思想更能够保留脑网络的拓扑结构,有效地寻找出病变区域的差异性.而本文提出的时序区分子图方法展现了脑网络的动态连接特性,能够有效提高阿尔茨海默症辅助诊断准确率.
1 时序区分子图在阿尔茨海默症辅助诊断中的应用
本文方法的整体技术路线一共分为五个步骤,包含动态脑网络构建、基于动态脑网络的频繁差异子图挖掘、基于频繁差异子图的频繁差异序列挖掘、频繁差异序列的筛选、基于时序区分子图的阿尔茨海默症辅助诊断.
1.1 动态脑网络的构建
首先进行数据预处理,从ADNI获得静息态fMRI数据之后,使用Freesurfer软件对数据进行预处理.数据预处理流程如图1所示.

图1 数据预处理流程图
在完成数据预处理的工作后,进行动态脑网络的构建.传统的脑功能网络多是基于标准模板而建立的脑区级功能网络.以自动解剖图集(anatomical automatic labeling,AAL)模板[12-13]为例,首先将经过预处理的fMRI图像与AAL模板匹配,将匹配结果中与小脑相关的26个区域去除,对剩余的90个脑区的时间序列采用滑动时间窗处理[14],将一个完整的时间序列划分为若干个窗口时间序列,采用皮尔逊偏相关系数度量[15]计算每个窗口中各个脑区之间的相关性,通过设定阈值得到多个时间段下的脑功能网络,由此构成了动态脑功能网络模型,如图2所示.
1.2 基于动态脑网络的频繁差异子图挖掘
通过AAL模板化之后,构成了90×90的矩阵,用0表示2个脑区之间没有连接,用1表示2个脑区之间存在连接.多张二值矩阵构成的连续图像可以代表动态脑网络.
首先需要构建差异图,将脑网络时序变化特征呈现出来,然后挖掘频繁出现的变化.将相邻2个矩阵做差,保留时间在后的矩阵与前一时刻矩阵的差值矩阵.1表示在下一时刻2个脑区间出现增边现象,-1表示出现减边现象,0表示在相邻的时间内边没有发生变化,经此处理能够使差异被放大,提高算法的效率.
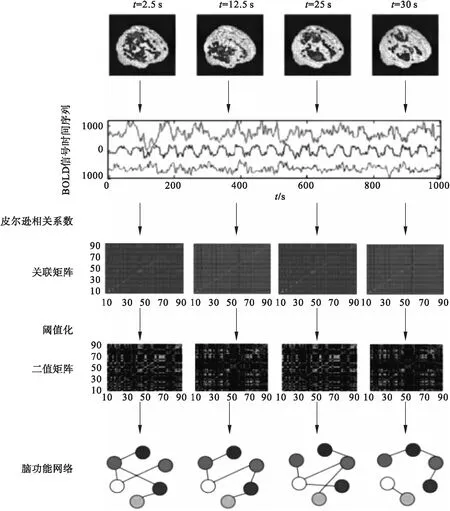
图2 脑网络的构建
随后,进行频繁差异子图的挖掘.该算法的目标是找出所有满足支持度要求的差异子图.在频繁差异子图挖掘过程中,最重要的是子图同构的判定问题,这将直接影响算法的时间复杂度.因此通过最小DFS(depth first search)序的方法进行剪枝(即提早排除那些与已被搜索过的子图同构的子图),极大地提高了算法的执行效率.
频繁差异子图挖掘的大体步骤是由频繁边不断扩展,最终得到符合设定阈值的子图,以下详细介绍了本算法的不同环节的核心步骤.
1.2.1 频繁边挖掘
频繁边是指在图集中累计出现次数高于阈值要求的边的集合.通过筛选频繁边,对部分不满足阈值要求的子图进行剪枝,减少频繁差异子图挖掘过程中的枚举数量,有效控制搜索空间的大小.
假设G表示n张脑网络图的集合,g1是寻找到的满足频繁差异子图阈值(η)的差异子图,其在图集中共出现m次,那么由频繁差异子图定义可知m≥η×n.又因为差异子图g1是由若干条边组成的,这些边在图集中出现的次数也应大于等于m,由此可得所有频繁差异子图都是由频繁边组成的.同时考虑到在阈值相同的情况下频繁边数量远大于频繁差异子图的数量,为了控制算法整体的时间复杂度,需要将频繁边阈值(θ)设置为略大于η的合理值.所以,在执行频繁差异子图挖掘算法前需要对数据进行预处理,将那些不满足θ要求的边删掉,提高挖掘算法的效率.具体挖掘算法如下所示:
算法1 频繁边挖掘算法
Input:图集G={g1[N][N],gn[N][N]},最小支持度θ
Output:频繁边集合g[N][N]
1. fori=1 toNdo
2. forj=1 toNdo
3. cnt=0;//计数变量
4. fork=1 tondo
5. ifgk[i][j]!=0
6. cnt=cnt+1;
7. if cnt>n×θ
8.g[i][j]=1;
9. else
10.g[i][j]=0;
11. Returng.
首先枚举图集中可能出现的所有边(第1~2行),然后分别对每条边统计其在图集中出现的次数(第3~6行),随后根据出现次数与最小支持度间的关系确定频繁边集合中是否加入该边(第7~10行),最后得到满足最小支持度要求的频繁边集合.
1.2.2 子图扩展算法
在进行频繁差异子图搜索过程中,需要构建子图搜索树来完整表示搜索空间,其中树上的每个节点存放1张全部由频繁边组成的联通子图,树的根节点表示空子图,即不含有任何一条边的子图,树中的孩子节点均是由其父亲节点扩展一条新边得到的.使用这种方法就可以不断对当前节点扩展新边来实现搜索树的生长,直至包含整个搜索空间.

算法2 子图扩展算法
Input:频繁边集合g[N][N],待扩展子图g1(V1,E1);R为最后结点下标序号
Output:扩展成功标志,扩展生成子图g2(V2,E2)
1.g2=g1;
2. fori=1 to (R-1) do
3. ifg[vR][vi]=1
4.g2←E(vR,vi);
5. Return(True,g2);
6. fori=1 tokdo
7. forj=1 toNdo
8. ifvjnot ing1andg[vj][vi]=1
9.g2←E(vj,vi);
10. Return(True,g2);
11. Return(False,g2).
首先将扩展生成子图赋值为待扩展子图(第1行);然后对于最右路径上的非最右节点,观察是否存在从最右节点连向该节点的频繁边,若存在则将该边加入生成子图并返回,否则继续执行算法(第2~5行);随后对于最右路径上的每个顶点,判断是否存在从当前节点出发的后向边,若存在则扩展并返回,否则继续执行算法(第6~10行);若此时算法仍未返回则认为搜索树中当前节点不再存在新的后继节点,返回失败标志(第11行).这样就按照先前向边再后向边的顺序完成子图扩展.
1.2.3 频繁差异子图挖掘
频繁差异子图是图集中出现次数大于阈值限制的差异子图的集合.这里所采用的频繁差异子图挖掘算法基于gSpan算法并结合实际进行多种剪枝操作,使得总体的时间复杂度进一步降低,具体算法如下.
算法3 频繁差异子图挖掘算法
Input:频繁边集合g[N][N],待扩展子图g1(V1,E1).
Output:频繁差异子图搜索树
1. root=new node;
2. while extend_edge(g1)
3.g2=extend_edge(g1);
4. if check(g2)=False
5. continue;
6. root←create_tree(g2);
7. Return root.
该算法通过构建子图搜索树进行频繁差异子图的挖掘.其特征为:树中节点均代表1张满足频繁差异子图阈值要求的子图,树的根节点表示1张空子图,且对于树上任意2个相邻的节点,孩子节点都是父亲节点通过执行生长算法扩展一条边得到的.因此,频繁差异子图挖掘算法采用深度优先搜索的方法模拟搜索树的生长过程.首先,初始化根节点为空子图.然后,对于当前节点不断执行子图扩展算法.若扩展算法执行成功返回生长新边后得到的子图,则记录当前生长情况并将新得到的子图作为当前节点递归执行挖掘算法.直至子图扩展算法无法加入新边时停止搜索并返回.这样就可以得到包含完整搜索空间的子图搜索树.
为了进一步提高算法执行效率,对于gSpan进行一系列改进,以优化频繁差异子图搜索过程,引进如下三种剪枝策略:①对于树中任意2个相邻的节点,孩子节点都是在父亲节点的基础上扩展得到的,假设父亲节点所代表的子图在图集中出现的次数为nf,孩子节点为ns,显然存在nf≥ns.因此,可以在搜索树扩展过程中引入检查步骤,如果扩展得到了不满足约束的节点就执行剪枝操作,不再搜索它的孩子节点.②对于任意1张子图,它所对应的最小DFS序都是唯一确定的,根据子图扩展算法可以保证搜索树中存在一条从根节点出发按照最小DFS序进行扩展得到当前子图的路径.因此,对于从根节点到当前节点路径与其对应子图最小DFS序不一致的节点进行剪枝操作,不再进行扩展.③由于在构建子图搜索树时依次以每条频繁边作为根节点进行扩展,假设存在2条频繁边e1和e2(e1 首先创建当前子树根节点root用于继续向下搜索和作为返回值(第1行);然后不断调用子图扩展算法extend_edge对当前节点所含子图进行扩展并将结果保存(第2~3行);随后判断扩展得到的子图是否满足最小DFS序和频繁差异子图阈值η的约束,若不满足则不再对其进行扩展(第4~5行);接下来对满足约束的子图递归调用频繁差异子图挖掘算法create_tree并作为当前节点的孩子节点(第6行).这样就实现了频繁差异子图挖掘的过程(见图3). 图3 频繁差异子图挖掘过程 频繁差异序列保留了动态脑网络的特征,利用差异子图序列反映一段时间内脑网络连接模式的变化.之前的工作得到了所有满足支持度要求的频繁差异子图,为了进一步研究频繁差异序列,需要进行回溯标记. 在回溯标记的过程中,构建了match数组,其中match[i][j]表示的是第i张差异图中是否出现了第j张差异频繁子图,若出现则赋值为True,反之是False. 算法4为频繁差异序列挖掘算法.首先创建深度优先搜索树的根节点(第1行);然后针对每一个样本全部脑网络差异图搜寻所存在的频率差异子图,若当前脑网络差异图中包含该频繁差异子图,则以其作为搜索起点调用markCount算法递归扩展其孩子节点(第2~5行);待所有测试数据完成匹配后返回搜索树根节点(第6行).这样就实现了频繁差异序列的挖掘,后期可以使用深度优先搜索算法根据实际情况筛选出搜索树中满足频繁差异序列阈值(ζ)要求的节点,具体操作为枚举所有从根节点出发到树上其他节点的路径,若当前节点计数值cnt≥ζ×n(n为图集中脑网络数量),则将该路径加入到频繁差异序列挖掘结果中. 算法4 频繁差异序列挖掘算法 Input:图集与频繁差异子图匹配数组match[m][n] Output:频繁差异子图搜索树 1. root=new node; 2. fori=1 tomdo 3. forj=1 tondo 4. if match[i][j]=True 5. root←markCount(i+1,1); 6. Return root. 算法4中采用的递归匹配算法具体过程见算法5.首先判断若已将当前样本所有时序脑网络图匹配完成则结束递归并返回(第1行);然后若当前节点不存在则创建新节点,否则更新当前节点计数值,表示满足当前序列的样本数量加1(第2~3行);随后遍历当前差异图中所有频繁差异子图,分别将其作为序列的新增元素并递归判断该样本下一张差异图(第4~6行);最后返回根节点信息(第7行).这样就完成了所有可能的频繁差异子图序列挖掘,按照阈值进行筛选即可得到所需频繁差异序列. 算法5 递归匹配算法 Input:图集与频繁差异子图匹配数组match[m] [n],图集中起始位置i,递归层数c Output:频繁差异子图搜索树 1. if check(i)=False Return; 2. if root=null root=new node; 3. else if root!=null root←root+1; 4. fork=1 tondo 5. if match[i][k]=True 6. root←markCount(i+1,c+1); 7. Return root. 为了进行阿尔茨海默症的辅助诊断,需要找到患者或正常人所特有的频繁差异序列作为辅助诊断的标记物,这就要求将双方共有的频繁差异序列剔除.将频繁差异序列定义为一个n元组[x1,…,xn],其中xi(i∈n)代表一个频繁差异子图的编号,xi,xj(i∈n∩j∈n∩i 通过筛选出不具有区分性的频繁差异序列后,能够得到来自于AD患者和正常对照组(normal control,NC)的频繁差异序列集合S(AD序列集)和Q(NC序列集),其中a(a=[x1,…,xn])∈S, 代表任一AD患者序列集中序列元素,b(b=[y1,…,ym])∈Q,代表任一NC序列集中序列元素. 如算法6所示,频繁差异序列的筛选即需要排除掉出现在S,Q两个集合中的序列,还要设定区分阈值h,来满足具有较明显区分性的要求. 算法6 频繁差异序列筛选算法 Input:AD患者和NC组的频繁序列集合S,Q,t,s分别代表S,Q集中序列个数,p,q分别代表序列i在AD和NC中出现的次数,λi,μi分别是赋予序列i的两个权重. Output:AD和NC的频繁差异序列集合S,Q 1. sort(S);sort(Q); 2. point1=1;point2=1; 3. While point1≤tand point2 ≤s 4. ifS[point1]=Q[point2] 5.S=del(S[point1]); 6.Q=del(Q[point2]; 7. else ifS[point1] 8. point1←point1+1; 9. else 10. point2←point2+1; 11.S=S+Q; 12. foriinS 13. [p,q]=get_frequency(i); 14. foriinS 15. if |pi×λi-qi×μi| 16.S=del(i); 17. [S,Q]=split(S); 18. Return(S,Q). 将得到的频繁差异序列先进行排序(第1行),再进行去除出现在AD序列集和NC序列集中的公共部分(第2~10行).之后进行赋权优化区分序列的操作,使得到的频繁差异序列拥有更好的区分性(第11~16行).然后将总集中AD的区分序列和正常组的区分序列分离,得到具有区分性的检测标记物(第17~18行). 现有区分序列集合X={X1,X2,…,Xm},对于任一测试样例,需要进行与X的比对,为其AD检测赋权重WAD={∑Wsj|Xi∈S,Xi=Sj},为其NC检测赋权重WNC={∑WQj|Xi∈Q,Xi=Qj},最后判断,若WAD>WNC则预测为AD患者;若WAD 使用MATLAB R2021a进行实验中部分代码编写,其中包括实验分析图的绘制,功能性磁共振图像的预处理、AAL模板匹配.其余部分使用Visual Studio 2019编译器、C++语言完成,其中包括频繁差异子图的挖掘、频繁差异序列的挖掘、频繁差异序列的筛选、阿尔茨海默症辅助诊断. 实验数据来自ADNI公开数据集(http://adni.loni.usc.edu)的功能磁共振数据.ADNI数据库是由研究员 Weiner博士领导的一个非营利性组织,其主要目标是测试MRI、PET、其他生物标记物以及临床检验和神经心理学评估是否可以结合起来进行MCI和早期AD进展的测量.本实验获取了178例静息态功能性磁共振数据,其中包括89例患有阿尔茨海默症的病人和89例正常对照组,由于考虑了脑网络动态特征,选取了同一样本的5个TR时间内的扫描数据,以构成时序脑网络.对每个数据样本的一个TR时间内截取140层,且全部样本采用Philips3.0T扫描仪获取,具体信息如表1所示. 表1 ADNI数据集详情Table 1 Details of ADNI data set 在提出的基于时序区分子图的诊断方法中,存在4个可变参数:频繁边阈值θ、频繁差异子图阈值η、频繁差异序列阈值ζ、区分阈值h.其中频繁边阈值θ和频繁差异子图阈值η分别表示在进行频繁差异子图挖掘过程中可进行差异子图扩展的边满足的最小支持度,以及得到的频繁差异子图满足的最小支持度.频繁差异序列阈值ζ表示在进行频繁差异序列挖掘的过程中满足的最小支持度.区分阈值h表示挖掘出来的频繁差异序列经过赋权成为区分序列所需要满足的最小支持度.为了评价这些参数在AD的辅助诊断过程中对分类性能的影响,分别依次选用不同的参数值来计算每个参数对分类精度的影响. 测试使用频繁边阈值θ(θ=0.150,0.152,0.154,0.156,0.158,0.160)和频繁差异序列阈值ζ(ζ=3,4,5,6,7,8,9,10)取不同值时频繁差异子图阈值η(η=0.07,0.08,0.09,0.10)对AD和NC分类结果的影响,在实验过程中分别变化3个参数θ,ζ及η,在每一张图像中,保持θ不变,观察ζ和η对准确率的影响.判断两组数据集中参数η对AD诊断的分类精度影响如图4所示.由于区分阈值可通过权重的更改保持定值,这里h=1. 图4 参数对分类精度的影响 由于频繁边阈值θ、频繁差异子图阈值η、频繁差异序列阈值ζ控制着最后得到的区分序列的数量,如果将阈值设定的相对小,会导致结果中存在区分性过小的区分序列,这反而会干扰高区分性的区分序列对预测结果的影响程度;如果阈值设定过大,会导致找出的区分序列过少,同样影响分类精度.由图4可见,当ζ,h保持不变时,随着θ的变化分类精度变化不明显,当θ=0.160时会出现在ζ取值大于7的范围内区分性降低的问题.当保持θ,ζ不变时,可以发现η=0.07时分类精度效果最优,且在ζ=6或ζ=7时出现接近95%的分类精度,这说明在物理条件允许的前提下,频繁差异子图越多,组合而成的频繁差异序列也就越多,便于后续依据频繁序列的差异性进行筛选,从而提高预测准确性.由于受到数据测试集规模影响,相关参数的变化鲁棒性较低,在参数小浮动变化范围内,分类精度变化较为明显.该问题可通过大数据集解决. 为了测试基于时序区分子图方法在诊断阿尔茨海默症上的分类性能,本文选取基于静态区分子图[9]和动态脑网络分类器[15]方法进行对比.基于同一数据集,所有方法全都进行了参数调优,最终分类结果见表2. 由表2可知,时序区分子图方法在区分AD患者和正常人的性能上远远优于其他几种对比方法.基于时序区分子图的诊断方法最高的分类准确率为94.8%,而与之对比的最好的方法为动态脑网络分类器方法,最高分类准确率为82.1%.实验结果表明所提出的基于时序区分子图的方法可以在提取脑网络生物学标志物上得到更好的标志物,同时时序脑网络信息也能更好地反映AD患者和正常人间的差异,从而更好地进行AD患者的辅助诊断. 表2 不同方法的分类性能比较Table 2 Comparison of classification performance of different methods 针对已有基于区分子图的阿尔茨海默症诊断方法多是建立在静态区分子图上的,忽略了脑网络的动态连接结构变化,提出了基于时序区分子图的阿尔茨海默症辅助诊断,它既能够保留脑网络的时序信息以及拓扑结构信息,还能够通过彰显差异性的方式,降低图挖掘的复杂度,进而充分利用数据信息建立模型.通过大量实验证明,提出的时序区分子图方法能够更全面地保留大脑活动的信息,提高了对阿尔茨海默症患者辅助诊断的准确性.
1.3 基于频繁差异子图的频繁差异序列挖掘
1.4 频繁差异序列的筛选
1.5 基于时序区分子图的阿尔茨海默症诊断

2 实验结果与讨论
2.1 实验数据集

2.2 参数影响分析

2.3 分类性能比较

3 结 语
