激光诱导击穿光谱技术与卷积神经网络相结合的中药材产地识别研究
2022-08-05梁西银钱恒礼李双豆苏茂根
梁西银,路 霄,钱恒礼,李双豆,苏茂根
(1.甘肃省智能信息技术与应用工程研究中心,西北师范大学 物理与电子工程学院,甘肃 兰州 730070; 2.甘肃省原子分子物理与功能材料重点实验室,西北师范大学 物理与电子工程学院,甘肃 兰州 730070)
中药材是中医治病防病的基础,特别是道地药材已成为我国传统优质中药材的代名词.道地药材被认为是历史悠久、产地适宜、品种优良、疗效突出、带有地域性特点的中药材[1].由于生产较为集中,栽培技术和采收加工等环节都有一定的讲究,因而相较于非道地产区的同种药材品质和疗效更佳.我国幅员辽阔,地理环境复杂多变,不同产区中药材质量存在巨大差异[2].以黄芪为例,山西恒山黄芪、甘肃陇西黄芪及内蒙地区的黄芪是医药行业公认的道地黄芪,质量优于其它产地.经中医临床验证及长期应用,也证实了药材的有效性及临床用药安全性与药材产地有密不可分的关系[3].然而,在当前药材市场流通过程中经常发现存在掺假、混用和冒充道地药材的现象,这严重损害了消费者利益,也给中药材质量监管带来了挑战.因此,开展中药材产地快速识别研究很有必要,将会对中药材产品产地管理、药材来源可追溯以及保障质量安全产生积极作用.
激光诱导击穿光谱(Laser induced breakdown spectroscopy, LIBS)技术是一种原子发射光谱分析方法,目前已成为一种新兴的元素定量检测和成分分析技术.LIBS技术具有原位分析、快速检测、无需复杂样品制备以及多元素联测等优点,已广泛应用于太空探索[4]、文物考古[5]、生物医学[6]等领域.近年来,LIBS技术与监督机器学习和化学计量学相结合在有效识别具有相似化学成分的材料方面表现出了巨大的潜力.张大成等[7]为了追溯银杏叶的地理起源,利用LIBS技术结合线性判别分析(Linear discriminant analysis,LDA)和支持向量机(Support vector machine, SVM)对8个不同地点的银杏叶进行了分类识别,LDA和SVM模型的准确识别率分别为 97.50% 和 96.25%.郑培超等[8]采用LIBS技术结合随机森林(Random forest, RF)算法对5个等级的石斛进行了分类,得到最佳准确识别率为96.46%.以上研究结果表明LIBS技术与传统机器学习方法相结合是一种在物质分类和产地溯源等领域很有应用前景的技术.然而,在元素组成相似度较高的样品识别中,分类效果仍有提升空间.卷积神经网络(Convolutional neural networks, CNN)作为深度学习的代表性算法之一,广泛应用于图像处理领域[9],目前在光谱分析领域的研究也有报道.Chen 等[10]将LIBS技术与CNN模型相结合用于识别5种岩石样品,CNN在验证集和测试集上的准确识别率分别为 98.77%和100%.孙淼等[11]利用LIBS技术结合CNN的方法对5种不同铅含量的土壤进行了分类,准确识别率达到99%以上.
综上,在同类样品中,由于相似的元素组成和复杂的基体效应[12],使得传统机器学习方法难以同时满足高效和准确的要求.为了进一步提高分类识别的准确率,文中基于LIBS光谱数据,采用CNN模型对药材产地进行快速识别,并在网络结构中加入了卷积块注意力模块(Convolutional block attention module, CBAM),对卷积计算后的重要特征进行关注,以期获得更高的分类准确率.为了验证所提方法的有效性,不仅与CNN基础模型进行了比较,还与粒子群优化支持向量机和粒子群优化随机森林等传统机器学习方法进行了比较.
1 实验部分
1.1 实验装置
实验装置如图1所示.Nd:YAG激光器产生波长为1 064 nm,脉宽为8 ns的脉冲激光,经透镜聚焦后作用在置于三维移动平台上的样品表面,对样品烧蚀产生等离子体,等离子体辐射经光纤传输至配有增强型电荷耦合器件(ICCD)探测器(PI-MAX4)的中阶梯光栅光谱仪(LTB,Aryelle200),可实现200~800 nm波段的光谱测量.数字脉冲延迟发生器(DG535)用于激光脉冲、探测器和三维移动平台间的时序控制.
1.2 样品制备
实验中的5种黄芪样品分别产自黑龙江大兴安岭地区、山西省浑源县、甘肃省定西市、内蒙古赤峰市和四川省理塘县.为了克服非均匀性对LIBS光谱的影响,实验前对样品进行简单预处理.利用研磨机将原始药材研磨至粉末,依次用30目和200目分析筛将研磨后的药材粉末按照颗粒大小进行过筛分离.对5种粉末样品,分别取3 g药材粉末利用压片机压制成直径为30 mm、厚度为2 mm的圆饼状实验样品.
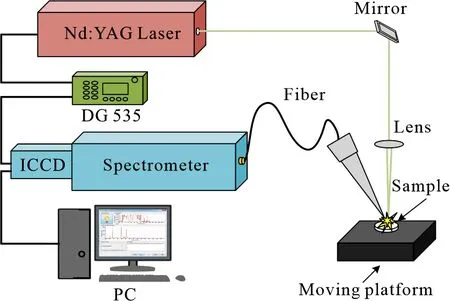
图1 LIBS实验装置示意图

表1 实验样品描述
1.3 数据获取与预处理
采用实验室搭建的LIBS系统对5种黄芪压饼样品进行测量,测量时激光能量为40 mJ,焦点位于靶表面下方 2 mm,延迟时间设为2 200 ns,该条件测量的LIBS光谱信号强度、信背比和光谱稳定性最优.实验中5种黄芪样品各采集200组光谱,每组光谱数据包含了42 841个“特征”,构成了大小为1 000×42 841的原始光谱数据集.获取原始数据之后,为了降低系统负荷和提高算法的速度,对光谱数据进行了预处理,采用最大最小值归一化法来改变光谱强度范围,将光谱强度缩放为0~1范围内.归一化的公式为
其中,y和y′分别为该波长点归一化前后的光谱强度值;ymax和ymin分别为一组光谱数据中强度最大值和最小值.
1.4 CNN-CBAM模型
利用卷积神经网络对LIBS光谱进行分类识别时,更希望网络去关注重要特征,忽视无用特征.LIBS光谱数据中存在连续背景或噪声等干扰信号,由于CNN模型中各网络层给每个输入分配的权重是相同的,无法对某些特定的输入进行关注,干扰信号也保留在原始通道上参与训练.注意力机制的引入在一定程度上可以解决CNN框架中存在的不足,通过调整权重可使网络更加关注重要的信息,从而达到优化模型的目的.CBAM 是一种为 CNN 设计的简单、有效的注意力模块,它结合了通道注意力模块(Channel attention module, CAM)和空间注意力模块(Spatial attention module, SAM)两个部分[13],对于输入的特征,CBAM 会从通道和空间两个维度计算出特征图的权重图,然后将权重图与输入的特征图相乘来提取关键特征.Woo等通过实验研究发现,先进行通道注意力机制,再对其结果施加空间注意力机制,这样的顺序会获得更好的效果,同时CBAM模块处于网络的不同位置也会产生性能差异[14].图2给出了CBAM模块的示意图.
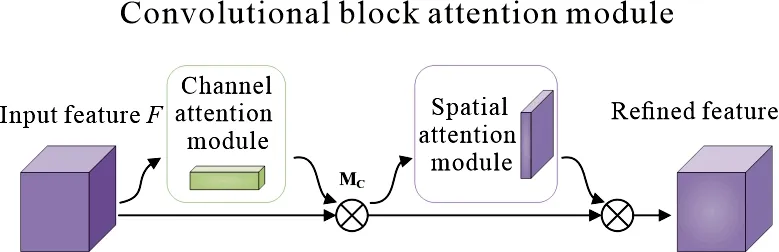
图2 卷积块注意力模块
通道注意力模块结构如图3所示,该模块对输入的特征图分别进行全局最大池化和全局平均池化,得到通道权值矩阵.之后将得到的两个权值矩阵输入到一个多层感知器中学习权值的优化,再对多层感知器两个输出部分逐元素相加,经过sigmoid激活函数将此值固定到[0,1],形成通道权重特征图Mc.将Mc与输入特征图F做逐元素相乘操作,生成空间注意力模块需要的输入特征F′.
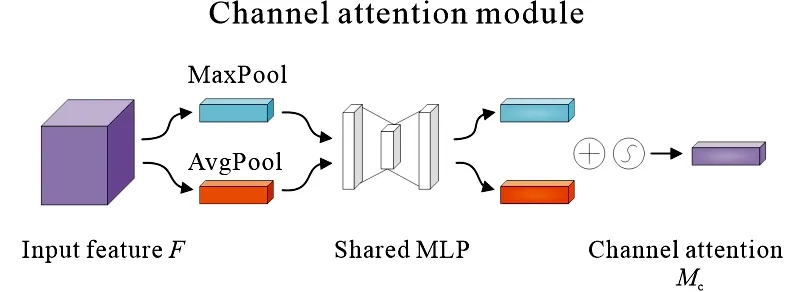
图3 通道注意力模块
空间注意力模块结构如图4所示.该模块沿通道轴来生成空间上的权重特征图Ms.对输入的特征图F′首先进行全局最大池化和全局平均池化,得到两个特征图,再对其进行卷积,卷积层的通道数是1,获得了高宽为1的特征层,利用sigmoid激活函数获得每一个的权重.然后将权重乘上输入的特征图F′,得到输出特征图F″.
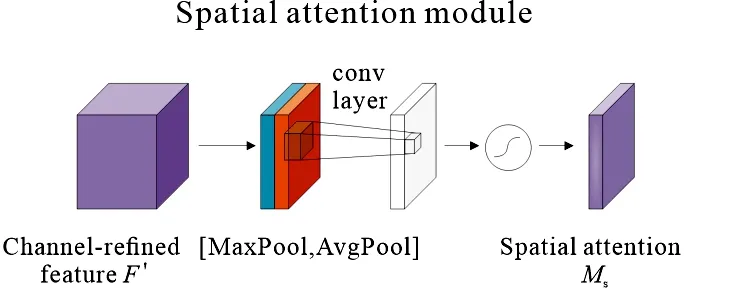
图4 空间注意力模块
文中提出的CNN-CBAM混合模型中,CNN框架为LeNet5结构.在输入层对LIBS光谱进行重构,将一维光谱数据转换为二维矩阵.采用先卷积(20个3×3卷积核,步长为1,无填充),再池化(2×2,步长为2的池化核),再卷积(20个3×3卷积核,步长为1,无填充),再池化(2×2,步长为2的池化核),全连接层1(128个神经元),全连接层2(5个神经元)的结构.在每个卷积层之后加入CBAM模块,对卷积计算后的重要特征进行关注.激活函数选用ReLU.CNN-CBAM模型结构如图5所示.
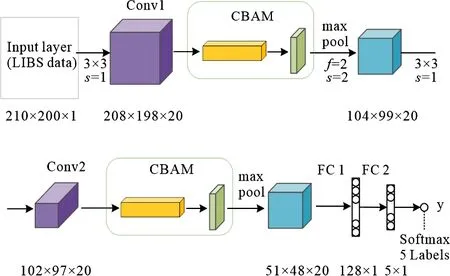
图5 CNN-CBAM混合模型网络结构
2 结果与分析
2.1 LIBS光谱分析
图6给出了5个不同产地黄芪在局部波段内的LIBS光谱图.从图中可以看出,不同产区黄芪所含同种元素的谱线强度不同.通过观察,发现四川理塘所产黄芪的发射谱线强度弱于其它产区,甘肃定西所产黄芪在279.55 nm和280.27 nm处具有更强的MgⅡ发射线,在393.36 nm和396.85 nm处具有更强的CaⅡ发射线,内蒙古赤峰所产的黄芪在588.99 nm和589.59 nm处具有更强的NaⅠ发射线.谱线强度与元素含量有关,这种差异为分类提供了依据.
图7给出了5个不同产地实验样品数据经过归一化处理后的LIBS光谱图,以美国国家标准与技术研究院(National institute of standards and technology, NIST)原子光谱数据库[15]为参考,对样品主要的元素特征谱线进行标定.通过发射光谱获取了黄芪的元素种类信息,元素组成包括常量元素(O,Si,Ti,Al,Fe,Mg,Ca,Na,K等)和微量元素(P,Mn,Cl,Cu,S,H,Rb,Sr等).元素类别及含量等信息可为理解道地药材成因以及分析药材有效成分与功效之间关系提供重要依据.
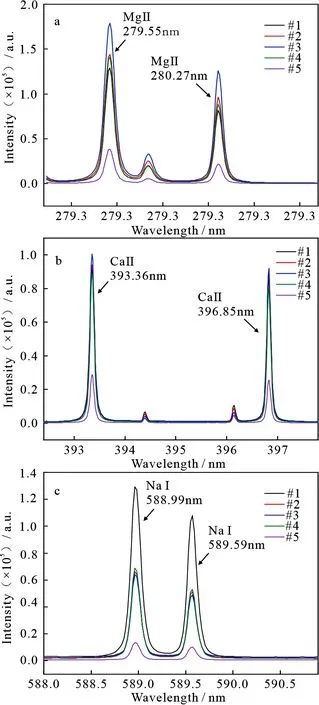
图6 5个不同产地黄芪的LIBS发射谱线在 不同波长处的光谱
2.2 CNN-CBAM模型
文中实验基于PyTorch深度学习框架,使用Python作为开发语言. 在模型输入层对每个光谱数据进行重构,将原始LIBS光谱(1行×42841列)转换为光谱矩阵(210行×200列).数据集按0.7和0.3的比例随机划分为训练集和测试集两部分.利用测试数据集确定最佳网络设计方案,通过多次训练,观察结果并确定该网络模型的结构和参数.最终将学习率设置为0.1,迭代次数设置为100,在实际训练时将所有数据分成多个batch,每次送入一部分数据,batch大小设置为50.数据需要多次反复迭代训练才能拟合和收敛.epoch 表示CNN网络模型完成了一次前向计算和反向传播的过程.CNN-CBAM模型在测试集上100个epoch的损失和准确率之间的关系如图8所示.
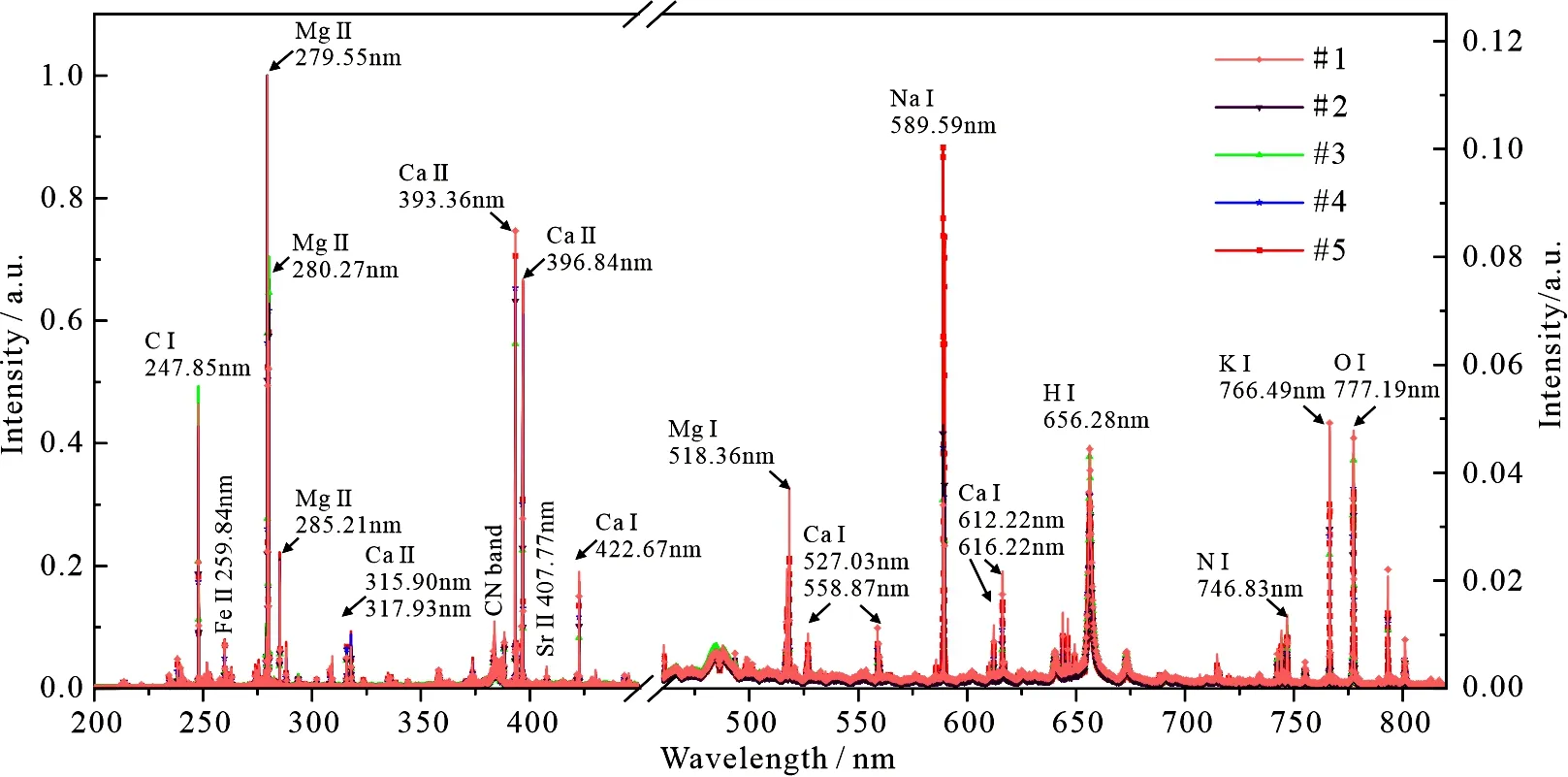
图7 5个不同产地黄芪的LIBS光谱
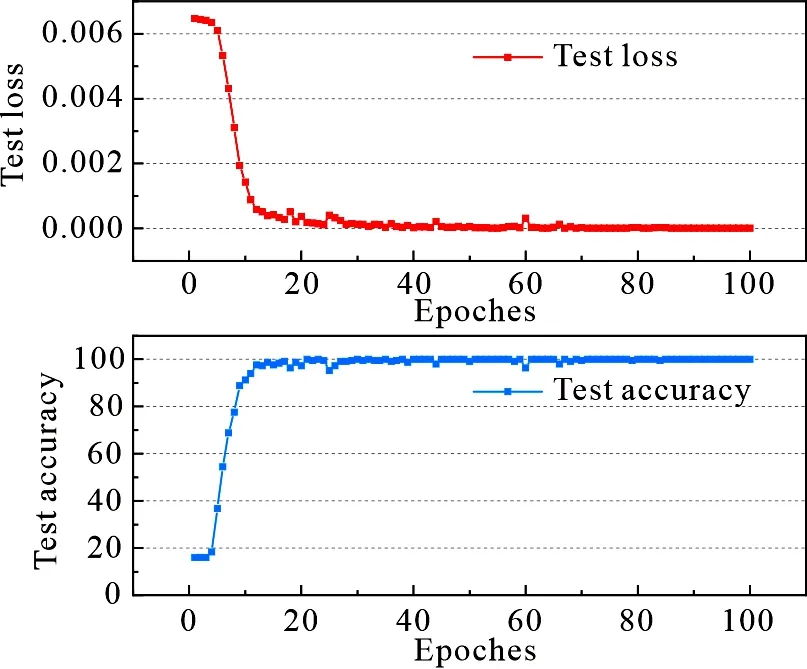
图8 CNN-CBAM模型损失值和准确率图
从图8中可以看出,模型经过20次迭代后,准确率和损失值逐渐趋于平稳.测试集上的损失值随着迭代次数的增加而减小,表明模型没有发生过拟合现象.经过足够的训练周期,训练损失降为0,准确率达到100%,说明模型从训练集中已经学习到较好的规则,表明所设计的模型是合理的.CNN-CBAM 模型的5次重复实验中,最高准确率均达到了100.00%.
2.3 与CNN基础模型的对比
在上文所提的加入注意力机制的 CNN-CBAM模型中,去除注意力机制部分后的模型称为CNN基础模型,为验证注意力机制是否能提高模型的性能,在相同的参数设置和数据集下进行了对比实验,5次重复实验的结果如表2和表3所示.可以看出添加CBAM模块后算法模型在分类准确率上确实有所提高.CNN基础模型虽然没有达到较高的识别精度,但是训练时间要比CNN-CBAM混合模型短,说明CBAM模块会带来计算损耗,但这种损耗并不大,因此可以认为CBAM模块可以提升网络性能.
2.4 与其他机器学习模型的比较
将提出的CBAM-CNN模型与常见的机器学习算法中的支持向量机和随机森林两种算法模型进行对比实验.由于原始数据量较大,全谱输入会导致模型难以收敛或训练时间过长,故采用主成分分析(Principal component analysis, PCA)方法[16]对原始数据进行降维处理.通过PCA分析,得到前10个主成分的累积贡献率达到99.83%,可以认为包含了原始黄芪 LIBS 光谱的大量信息.文中将经过PCA处理后的前10个主成分作为分类模型的输入.
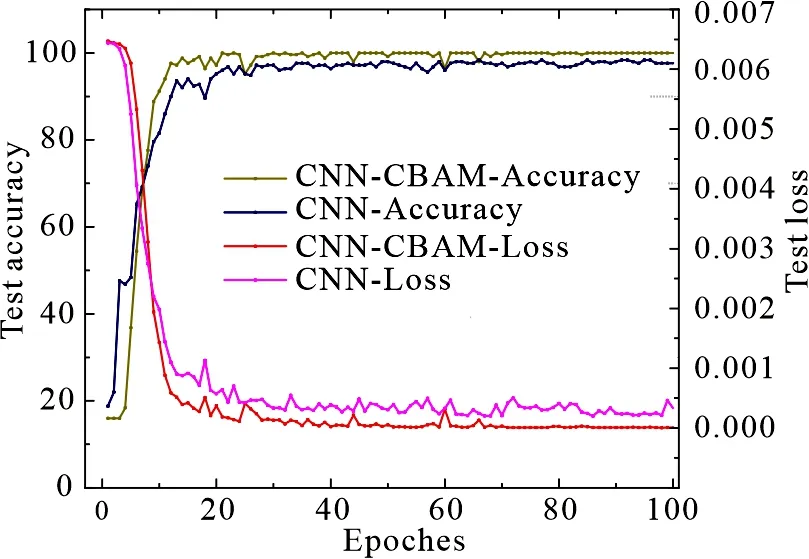
图9 CNN-CBAM和CNN性能比较
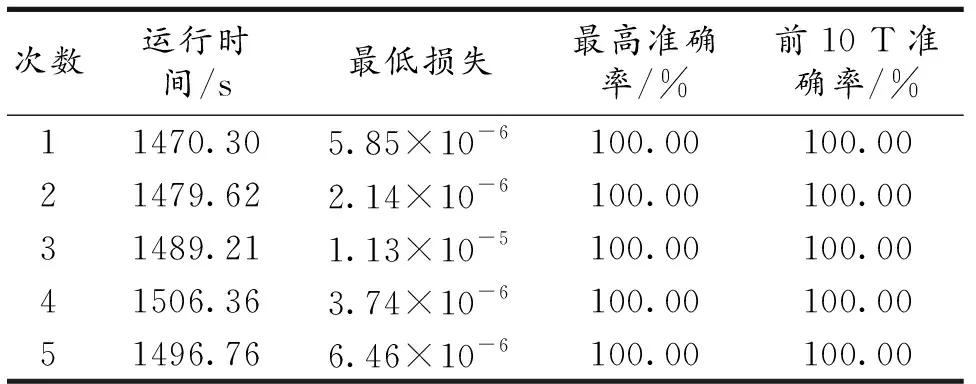
表2 CNN-CBAM模型5次重复实验的统计结果
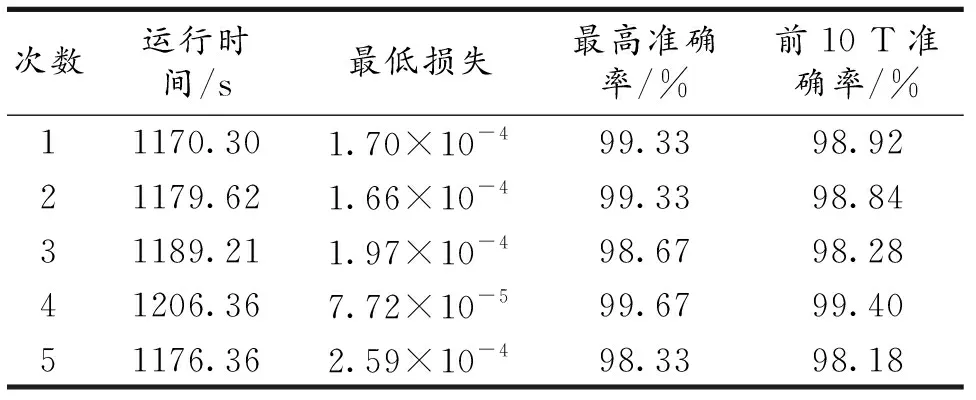
表3 CNN基础模型5次重复实验的统计结果
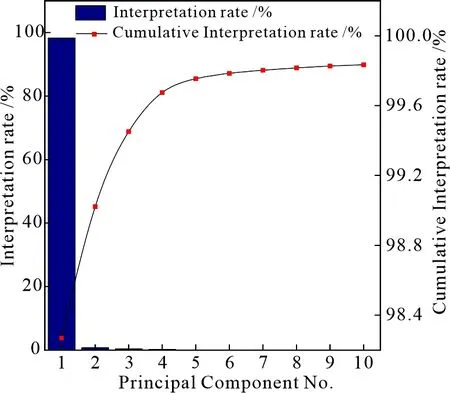
图10 各主成分得分和主成分累积得分
经过PCA分析后得到前3个主成分向量组成的三维散点图如图11所示,图中每个散点代表一个黄芪样本,可以看出相同产地黄芪样品在特定区域具有聚集现象,但仍存在部分重叠,故需要借助其他分类算法对经过 PCA 降维后的数据做进一步处理.
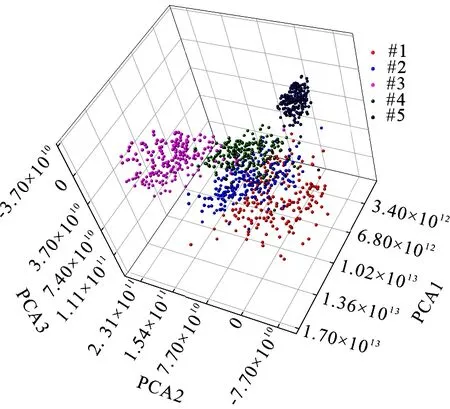
图11 前3个主成分的三维散点图
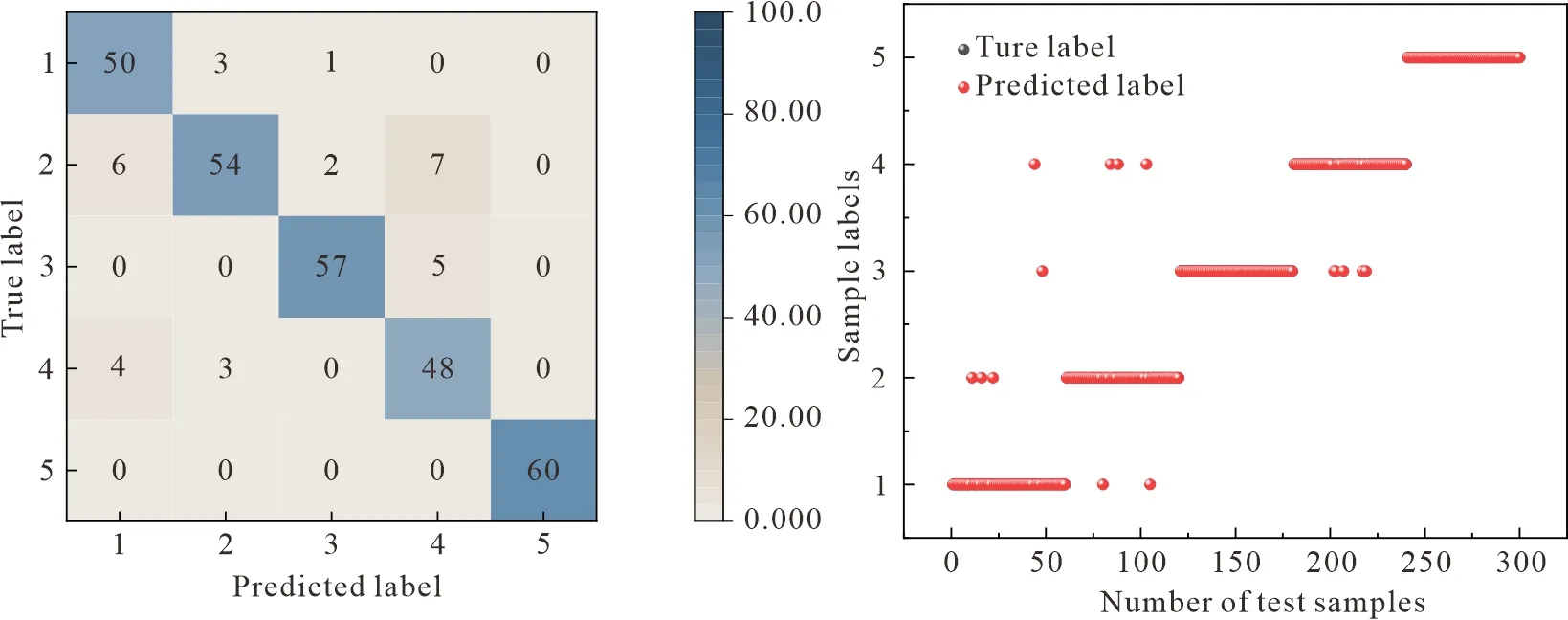
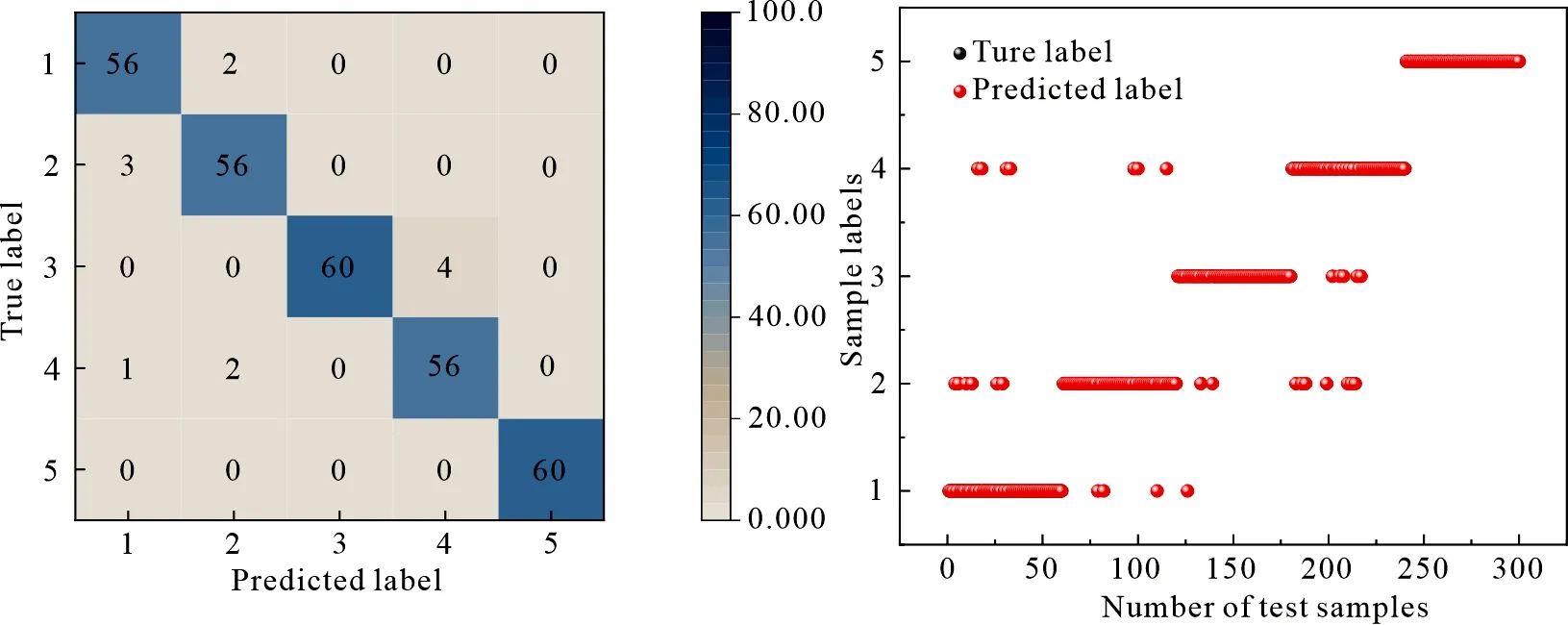
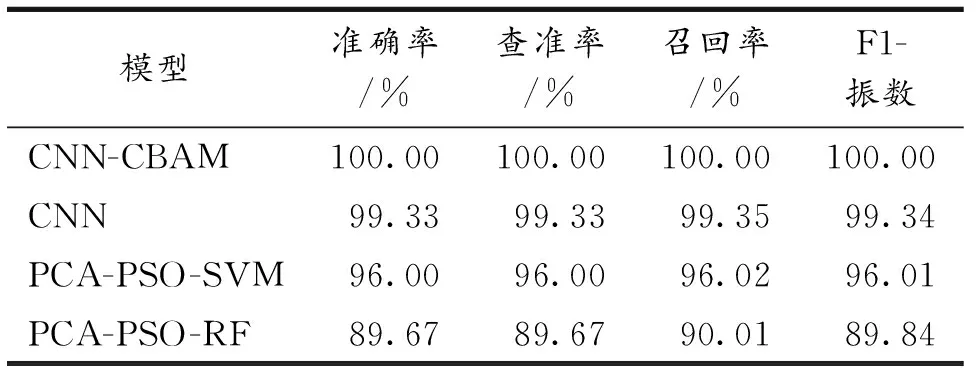
利用SVM对实验样品进行分类时,SVM性能受惩罚因子C与核参数影响.在实际实验中,采用粒子群优化(Particle swarm optimization, PSO)算法对这两个关键参数进行优化[17],从而使得SVM分类器获得最佳分类性能.实验中将PSO中的加速度因子c1与c2分别设置为0.6与0.7,粒子群规模设置为10,最大迭代次数设置为100;将SVM中的惩罚因子C搜索范围设置为0.01 利用随机森林(RF)进行产地识别的思想是将多棵决策树集成一个森林,将主成分分析降维后的特征数据输入到RF分类器中,RF是包含多个决策树的多分类器.在本实验中,同样使用PSO优化算法对RF中mtry和ntree两个参数进行优化,设置粒子群规模为 10,迭代次数为 100,最终得到了RF模型的关键参数取值,当mtry=210,ntree=17,利用RF对测试集进行分类实验得到结果如图13所示. 表4为不同模型得到的实验结果.与传统的机器学习算法对比,深度学习算法在LIBS光谱分析实验中准确率达到98%以上,远高于机器学习算法,这表明深度学习方法在LIBS光谱特征提取方面具有优越性.表中列出了各种算法的性能评价指标,包括准确率(Accuracy)、查准率(Precision)、召回率(Recall)和F1-score.从表中可以看出,CBAM-CNN 的各项指标均高于其他算法,说明CBAM-CNN具有较强的泛化能力. (a)混淆矩阵 (b)分类结果图 (a)混淆矩阵 (b)分类结果图 表4 不同算法模型实验结果对比 基于LIBS技术,提出了一种CNN-CBAM相结合的混合模型对5个不同产地黄芪进行了产地识别研究,实验采集了5类黄芪共1 000组LIBS光谱数据,每组光谱包含42 841个“特征”,利用最大-最小值法对光谱强度进行归一化预处理.采用卷积神经网络中的LeNet5模型,并加入CBAM注意力机制模块对LIBS光谱数据中重要的特征进行关注,最终识别准确率达到100%,而CNN基础模型、PCA-PSO-SVM和PCA-PSO-RF 3种分类模型的平均识别准确率分别为99.33%、96.00%、89.67%.结果表明,所提出的模型能够有效地对药材产地进行识别.相比于其他的传统机器学习方法,文中提出的模型准确率能够保持较高的水平,并且稳定性也优于其他模型,无需配合特征工程技术,可以大大简化机器学习的工作流程.结合注意力机制进行自适应特征细分是一种更加准确和高效的方法.2.5 结果对比分析
3 结束语
