跨境邮寄物风险源监测预警技术研究
2022-08-02罗琴涛张宗平罗宇平胡琳子梁军峰梁志明
罗琴涛 张宗平 罗宇平 胡琳子 梁军峰 梁志明
(1.广州海关信息中心 广东 广州 510623;2.中国电子口岸数据中心广州分公司;3.佛山海关综合技术服务中心)
1 前言
跨境电商类商品不同于一般贸易商品,因其申报数据的自主性,进出境邮件具有数量多、来源复杂及溯源信息少等特点,易存在货证不相符的问题,给海关日常监管带来严峻挑战。本文尝试构建“跨境邮寄物预警模型”,对跨境风险进出境邮件进行有效监控,以帮助相关人员甄别进出境风险邮寄物,降低开箱检查的人工和时间成本,切实提高口岸的监管能力。
2 研究模型设计思路
本文将进出境邮件的数量、重量、价值、税额、寄递渠道、收寄件局、收寄件人信息作为风险预警模型的参考变量,以信息化为依托,以邮寄用户申报数据、互联网采集数据、海关平台数据为基础,通过核对、比较、分析进出境邮件的特征和指标,及时发现异常,寻找风险点,从多方面识别邮寄风险情况。
风险预警模型的建立分为3步[1]:(1)对数据进行科学化地预处理。收集进出境邮件安全风险源数据、综合管理平台源数据、个人相关信用数据、全球疫情数据;整合不同系统的信息,分析形成各类有价值的数据情报,并筛选重要影响因素作为变量。(2)建立风险预警模型。根据预处理得到的变量及其对应的数据进行模型演练,寻找数据的规律和特征,选择合适的模型;该模型涉及的机器学习模型是区分于回归的二分类模型,常用的二分类机器学习算法[2]有逻辑回归模型、邻近模型。(3)对已建好的模型进行风险评估。比对逻辑回归模型[3]和邻近模型[4]的分类报告,对2种不同的模型预测结果进行分析,得出准确度较高的模型,并选择该模型作为预测的最终决策。
3 模型分析与构建
3.1 模型变量筛选
本文通过对进出境邮件数据进行分析,分析进出境邮件的风险特征与“人、路、物”这三者相关,“人”即收件人信息和寄件人信息;“路”即邮件寄件的境外地区和收件的境内地区;“物”即邮件的特征。在模型方面的思路确定需要训练的变量,进出境邮件的寄递渠道、收寄件局、收寄件人姓名、进出境邮件重量、进出境邮件税额、进出境邮件价值、进出境邮件数量、验放指令。并且通过逐步的模型筛选最终得出采用邮件种类、邮件总重量、申报人民币总价、邮件人民币的总价值、行邮税税率、完税价格。
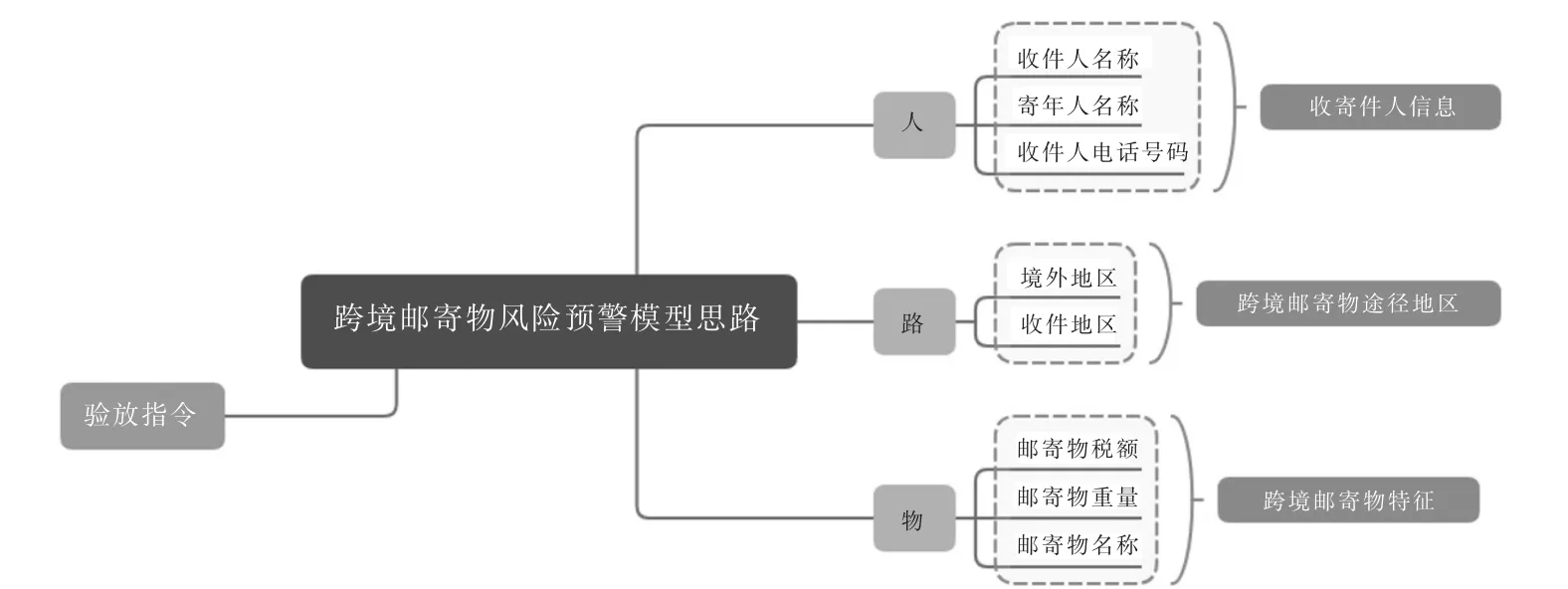
图1 跨境邮寄物风险预警模型思路
3.2 模型建模过程分析
根据实际情况,建立跨境进出境邮件风险预警模型需要进行样本不均匀处理、数据清洗、数据分析、建立逻辑回归模型、建立邻近模型、模型结果比对优化等过程。
在源数据方面,需要通过数据处理将邮件名称和收件地址翻译成中文,并对省、市、区县进行排列,以便提取相关字段,这2个变量需要较多的人工清洗和数据处理。
通过可视化库,可以先简单地对历史情况进行汇总,进出境邮件势可分为有风险和无风险这2类。因为只有极少数进出境邮件是有风险的,分析得到的风险进出境邮件占比5%~10%,见图2。出现样本不均衡,会导致样本量少的分类所包含的特征过少,很难从中提取规律,即使得到分类模型,也容易产生因过度依赖于有限的数量样本而导致过拟合问题[4]。

图2 跨境邮寄物查验结果情况
在机器学习中,当原始数据的分类极不均衡时,需要对其进行处理,下采样是处理方法之一,即从多数类中随机抽取样本以减少多数类样本的数量,使数据达到平衡。因此,为解决样本不均衡的问题,应采用下采样5,并通过下采样后达到样本均匀,见图3。

图3 跨境邮寄物查验结果下采样处理
3.3 逻辑回归模型的实证结果分析
逻辑回归是用于处理因变量为分类变量的回归问题,属于一种分类方法,常见的是二分类或二项分布问题,也可以处理多分类问题。二分类问题的概率与自变量之间的关系图形通常为S型曲线,见图4,采用Sigmoid函数[5]实现。
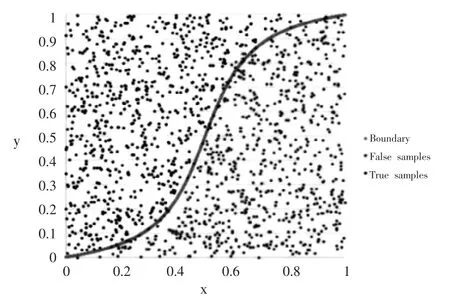
图4 二分类问题的概率与自变量之间的关系
逻辑回归模型定义为:

在逻辑回归算法中,逻辑回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤为:(1)导入模型。调用逻辑回归Logistic Regression()函数。(2)fit()训练。调用fit(x,y)方法训练模型,x为数据属性,y为所属类型。(3)predict()预测。利用训练得到的模型,对数据集进行预测,返回预测结果。
处理样本数据后,随机抽取50 000条数据进行逻辑回归建模,调取sklearn机器学习数据包,根据自变量对最终预测结果的关联性及采集数据的可行性,自变量需采用可量化的定量数据。采用回归分析,得出邮件种类、邮件总重量、申报人民币总价、邮件人民币的总价值、行邮税税率、完税价格为模型的自变量,验放指令为因变量。
由表1可知,逻辑回归预测的整体准确率为96.1%,该模型的准确度主要集中于无风险进出境邮件的预测,在风险进出境邮件的预测方面,误判1 929个,正确判断11个。

表1 逻辑回归预测分类表
由表2可知,逻辑回归方程为:

表2 逻辑回归方程中的变量
logit(p)=1.9144×邮件种类+0.0562×邮件总重量-0.0002×申报人民币总价+0.0008×邮件人民币的总价值+4.4249×行邮税税率-0.0020×完税价格-4.2162
自变量的系数显著性均<0.05,变量通过假设性检验,模型可用。
3.4 邻近模型的实证结果分析
KNN(K-Nearest Neighbor)法即K最邻近法,最初由Cover和Hart于1968年提出,是最简单的机器学习算法之一,思路简单直观:若一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,即在定类决策方面,只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN分类算法包括4个步骤:(1)准备数据,对数据进行预处理。(2)计算测试样本点(即待分类点)至其他每个样本点的距离。(3)对每个距离进行排序后,选出距离最小的K个点。(4)对K个点所属的类别进行比较,根据少数服从多数原则,将测试样本点归入在K个点中占比最高的一类。
KNN算法的优势是依据k个对象中占优的类别进行决策,且KNN将对象间距离作为各个对象之间的非相似性指标,避免对象之间的匹配问题,计算距离通常使用欧氏距离或曼哈顿距离:
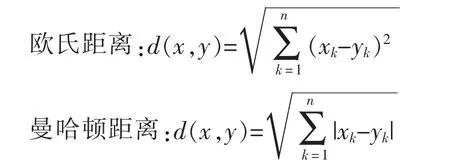
结合本次跨境进出境邮件风险预测情况,建立风险预测KNN模型,由于数据量较大,故随机抽取50 000条数据进行建模。调取sklearn机器学习数据包,采用回归分析,得出邮件种类、邮件总重量、申报人民币总价、邮件人民币的总价值、行邮税税率、完税价格为自变量,验放指令为因变量。
KNN模型在6个自变量形成的6个维度空间的预测点及其分类情况见图5,可知在6个维度上,根据数据模型的演练可判断进出境邮件的风险分类。

图5 KNN模型在6个自变量形成的6个维度空间的预测点及其分类情况
邻近模型预测的整体准确率相对于逻辑回归的准确度较低,该模型准确度主要集中于无风险进出境邮件的预测,在风险进出境邮件的预测上,误判1 934个,正确判断6个,见表3。
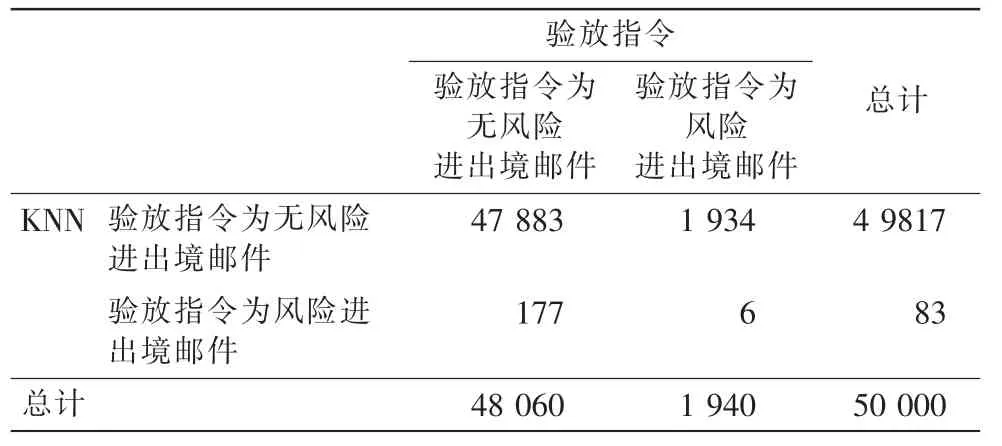
表3 KNN模型预测分类表
4 结论
本文通过对逻辑回归模型和邻近模型的结果进行比较分析,发现逻辑回归模型的拟合效果较好,且准确度和命中率较高。探索研究跨境邮寄风险模型是一个复杂的系统性工作,需结合相关人员和专家的意见选择计算方法模型,尽可能涵盖各种特殊场景,可运用大数据机器学习进行建模并评估其准确性。
今后会持续对跨境邮寄风险模型进行绩效评价,定时抽查分析预警数据的准确度、验证模型的适用性,及时发现和反馈需要调整或修正的事项。对预测结果与实际结果存在较大差异的信息开展专项审核,分析模型的不足之处,持续修正及优化,以适应复杂业务场景的需求。
