基于知识图谱的网络威胁行为检测系统设计
2022-08-02狄跃斌许睿超
寿 增,狄跃斌,马 骁,许睿超,尹 隆
(1.国网辽宁省电力有限公司,辽宁 沈阳 110003;2.南瑞集团有限公司(国网电力科学研究院有限公司),江苏 南京 210061;3.北京科东电力控制系统有限责任公司,北京 100192;4.东北大学 软件学院,辽宁 沈阳 110169)
0 引言
传统的网络威胁检测系统,如入侵检测系统,主要使用关系型数据库进行建模分析,但表与表的关系复杂、不直观,不能表达出清晰的网络攻击路径。当前,网络攻击行为日新月异,网络威胁行为也趋于复杂化,传统的检测方式,例如特征码检测[1-2]、opcode[3-4]检测、虚拟执行法等只能对已知的威胁进行检测,不能检测出未知、复杂的网络威胁行为,检测速度慢、资源消耗,严重影响了系统的性能。
为了解决传统网络威胁检测技术不能应对复杂的网络攻击以及无法对网络攻击进行溯源[5-7]的问题,利用知识图谱[8-10]与图数据库Neo4j[11],本文设计并实现了可动态识别并学习新型网络攻击的网络威胁行为分析系统。利用知识图谱构建网络威胁行为库,对复杂的网络威胁行为以及这些行为直接的逻辑关系进行描述。在威胁识别方面,设计了知识图谱匹配算法将采集到的威胁事件发送至知识图谱与已有威胁知识图谱进行匹配。针对新的网络威胁,基于知识图谱的自学习能力,设计了网络威胁检测自学习方案,可对新出现的网络威胁事件进行学习,并更新已有知识图谱。利用Neo4j来实现知识图谱,采用Flume+Kafka+Storm的平台架构对网络威胁行为数据进行处理,提升知识图谱各节点之间的遍历搜索速度,加快网络威胁行为识别效率。区别于传统的检测方法,基于知识图谱的网络威胁行为检测不仅具有传统检测方法的优势,而且解决了传统检测方法速度慢、资源消耗大、无法描述复杂网络威胁行为攻击链等问题。
1 相关技术
1.1 知识图谱与Neo4j
知识图谱又称为科学知识图谱,是引文分析与数据、信息可视化相结合的产物。知识图谱本质上是一种基于图的数据结构,由节点和边组成。其中节点即实体,由一个全局唯一的ID标示,关系(也称属性)用于连接2个节点,通过知识图谱更加快捷地查找到所需要的内容,以及发现节点与节点之间的关系。
本系统采用Neo4j实现知识图谱,Neo4j是目前用的较多的图数据库,它基于Java的高性能、高可靠性、可扩展性强的开源图数据库[12],完全兼容ACID,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性 (Durability)。
Neo4j的数据存储形式主要是节点(Node)和边(Edge)来组织数据。Node可以代表知识图谱中的实体;Edge可以用来代表实体间的关系,关系可以有方向,两端对应开始节点和结束节点。另外,可以在Node上加一个或多个标签表示实体的分类,以及一个键值对集合来表示该实体除了关系属性之外的一些额外属性。关系也可以附带额外的属性。其使用的存储后端专门为图结构数据的存储和管理进行定制和优化,在图上互相关联的节点在数据库中的物理地址也指向彼此,因此更能发挥出图结构形式数据的优势。
1.2 消息采集模型Flume
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输系统。Flume在数据输入上支持:
① Avro:监听Avro端口,接受来自外部Avro客户端的事件流。利用Avro可以实现多级流动、扇出流和扇入流等效果。
② Spooling Directory:监视指定目录,读取新文件的内容作为数据源。
③ NetCat:监听一个指定的端口,并将接收到的数据的每一行转换为一个事件。
④ HTTP:基于http协议收集消息。
Flume允许复杂的数据流动模型,事务性的数据传递保证了数据的可靠性,并且Flume支持文件型Channel,提供了可恢复性。
1.3 消息中间件Kafka
Kafka[13]是由Apache软件基金会开发的一个开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。因此,本文选择Apache Kafka[14]作为事件收集与事件处理的中间件。Kafka可以是一台服务器,也可以是服务器集群,统称为broker。每条发布到broker上的消息都有一个类别,成为topic。而每个topic下对应了多个持久化的数据文件,即partition。每个topic在集群环境中有多个备份。
1.4 实时流处理平台Storm
Storm[15]是一个分布式的、容错的实时流计算系统,可以方便地在一个计算机集群中编写与扩展复杂的实时计算,其具有如下优势[16]:
① 低延迟与高性能:Storm集群主要由工作进程、线程和任务构成。每台主机上可运行多个工作进程,每个工作进程又可以创建多个线程,每个线程可以执行多任务,而任务是真正进行数据处理的实体。针对开发者创建的任务拓扑图,Storm能根据集群中各个主机的性能,恰当地分配任务。
② 高可靠与高容错:Storm可以保证接收的所有数据都能被完全处理,而如果数据在处理过程中出现异常,Storm会重新部署出错的处理单元,保证处理单元永远运行。
③ 流处理:批处理框架Hadoop[17]运行的是MapReduce job,当job结束后主机将会进入闲置状态。Storm上运行的是拓扑,可以不断根据拓扑分发任务到处理单元。
2 系统总体设计
2.1 系统架构
本文设计的系统由大数据平台、威胁事件分析与知识图谱构建模块、持久化存储与前端展示模块部分构成,如图1所示。
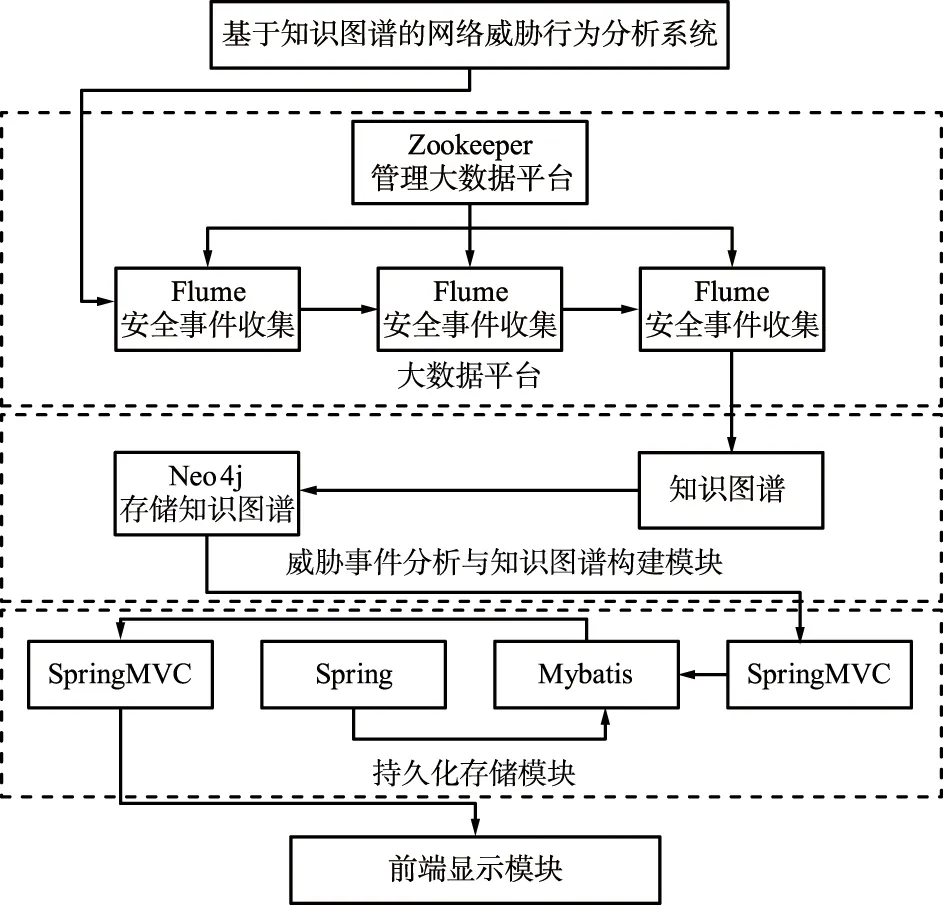
图1 系统架构Fig.1 System architecture
在实际网络环境中,系统采集来自网络中各个终端节点上的防火墙探针发送的网络威胁事件信息,将搜集到的各种网络威胁事件信息发送到Flume+Kafka+Storm构成的大数据平台,然后由大数据平台将网络威胁事件实时地发送至知识图谱学习识别,并通过Neo4j图数据库存储生成的知识图谱,最后将未识别成功的数据传到MySQL关系型数据库。然后通过Spring,SpringMVC和Mybatis框架进行数据处理并最终返回给前端,由前端将实时的攻击界面展示给用户。
(1) 数据采集
在事件采集阶段,使用Flume平台提供的接口,搜集已授权的终端节点上的各种网络威胁事件,再将这些网络威胁事件提交给Kafka平台进行缓冲处理,随后产生与消费速率相匹配的事件流发往Storm平台,由其产生实时的数据流发往Neo4j。
(2) 事件识别
在系统进行初始化的同时,系统同时访问图数据库Neo4j,从中提取现有的网络威胁事件的知识图谱,将其载入到内存中,运行的时候可以直接在内存中访问,避免在识别过程中多次对数据库访问,提高了系统的执行效率。当遇到网络威胁事件时,系统直接从内存中读取知识图谱与网络威胁事件比对。
(3) 威胁学习
当系统出现比对异常时,即发现了未知事件,就启动学习功能,触发威胁学习模块。系统通过学习此事件,将相关威胁事件信息加入知识图谱中,并更新内存中的知识图谱。
(4) 主机评估
系统根据识别模块已经统计的网络威胁行为数据,对此主机IP地址进行判断其威胁程度的高低,将威胁程度高的主机纳入黑名单中并进行广播处理。
(5) 数据统计
在知识图谱更新完成后,系统再统计并记录有关事件的攻击次数等信息,提供给统计算法,供其进行进一步的分析。
(6) 数据持久化
在知识图谱更新完成后,系统将这些数据进行持久化,将其存储到MySQL和Neo4j数据库中,防止数据丢失。
(7) 可视化处理
系统调用前端显示模块,将此网络威胁事件的信息实时更新到前端,给用户展示实时的安全情况。
2.2 系统软件架构
系统的软件架构如图2所示,主要分为应用层、接口层、逻辑层、网络层和存储层。
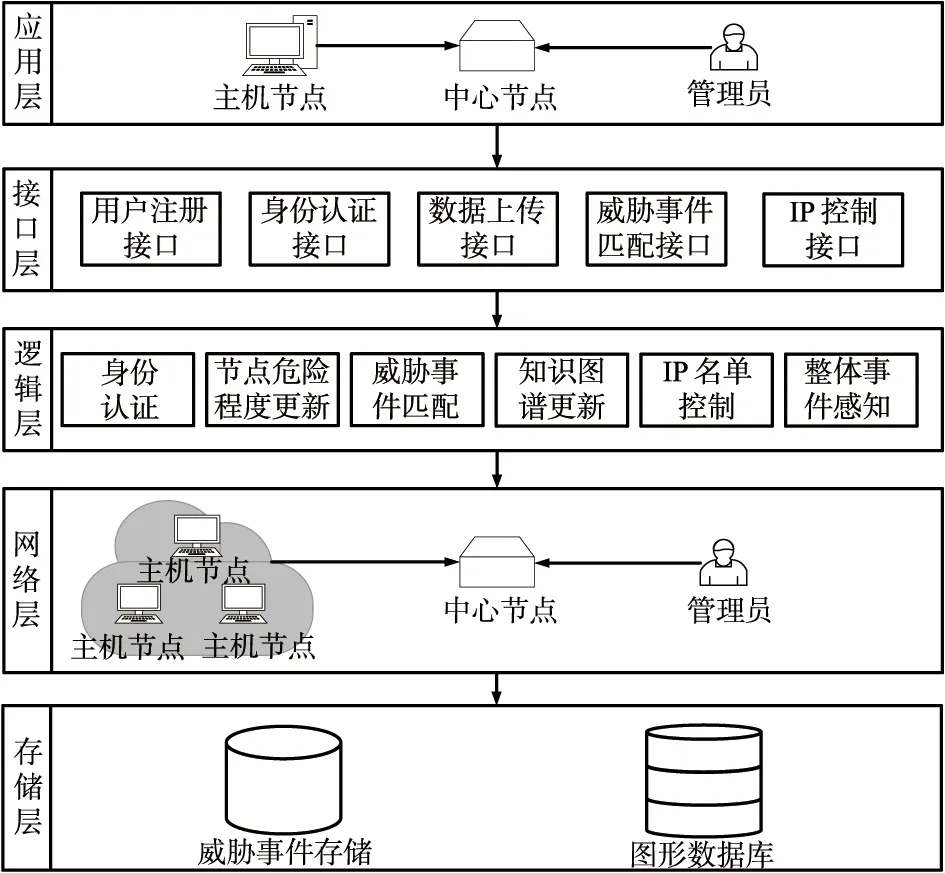
图2 系统软件架构Fig.2 System software architecture
① 应用层:用户首先进行注册,在通过认证后,进入整个系统进行全局管理。服务器集群中的每个节点将自己采集到的网络威胁事件分析处理后交给系统进行匹配和更新。
② 接口层:系统中包含用户注册接口、身份认证接口、数据上传接口、网络威胁事件匹配接口和IP控制接口。
③ 逻辑层:通过调用接口实现了身份认证、网络威胁事件匹配、网络威胁事件的知识图谱更新、节点危险程度更新、IP黑白名单控制和整体事态感知功能。
④ 网络层:主机集群通过大数据平台进行网络威胁数据的采集与分析。用户登录系统后,可以对服务器采集到的网络威胁事件数据进行管理。
⑤ 存储层:接收到新的网络威胁事件后,对知识图谱进行更新,新的事件、账户信息更新,存放到数据库中。
2.3 系统数据处理流程
在事件采集模块中,系统采用Flume+Kafka+Storm的数据采集处理框架,通过 Flume提供的接口,收集大量已授权网络发送的威胁事件,再将收集到的威胁事件提交到消息中间件 Kafka,之后在Storm中进行数据的消费,传入到知识图谱中。系统的数据处理流程如图3所示。

图3 数据处理流程Fig.3 Data processing flow
3 功能模块设计与实现
系统包括6个模块:大数据实时处理模块、网络威胁行为识别模块、网络威胁自学习模块、黑名单策略模块、数据持久化模块和用户模块。系统功能组成如图4所示。
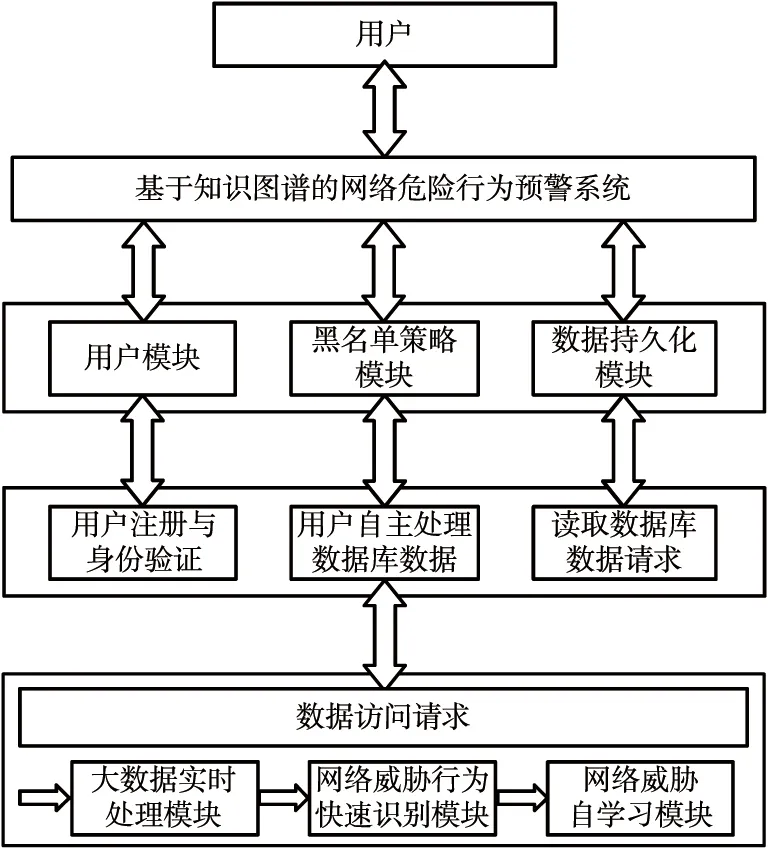
图4 系统功能模块Fig.4 System function modules
大数据实时处理模块负责搜集威胁事件并将其封装成实时事件流传输给网络威胁行为识别模块,由其进行识别处理,对于未能准确识别的事件交由网络威胁自学习模块进行处理;对于识别成功的事件交由黑名单策略模块进行分析处理;对于传播影响度较大的IP地址进行屏蔽处理,再将这些得到的信息交给数据持久化模块进行储存,并将实时的攻击信息交给用户模块呈现给用户。
3.1 数据实时处理模块
该模块负责搜集威胁事件,产生实时的数据传输流到威胁行为发现模块。在该模块中,Flume平台从所管理的计算机集群防火墙和监控软件中获取访问数据,作为生产者,将数据发送给消息队列处理系统Kafka;Kafka作为中间缓冲区,解决生产消费速率不匹配问题;Storm则充当消费者实时地处理数据,产生实时的数据流传输给威胁识别模块。该模块在终端防火墙部署,作为数据源,防火墙上记录有计算机与外界的各种访问记录,这些往来记录作为系统的数据。
数据实时处理流程如图5所示。从事件源获取数据后,Flume,Kafka和Storm三个大数据平台各自独立运行,通过事件流的顺序连接形成整体的大数据处理平台。
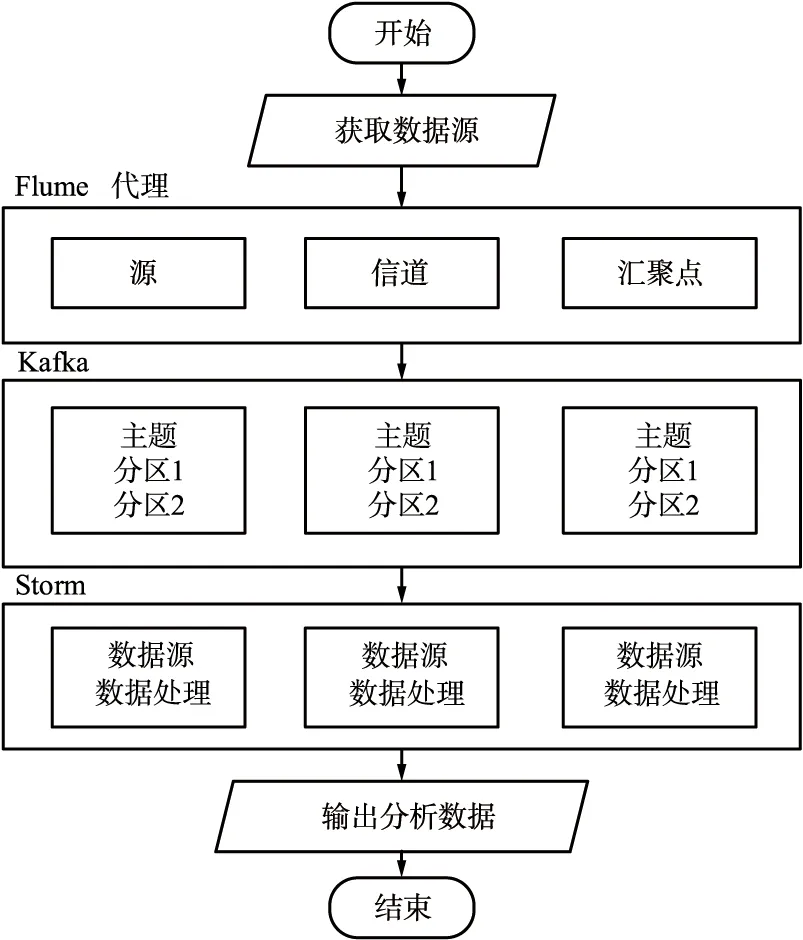
图5 数据实时处理流程Fig.5 Real-time data processing flow
每个Flume源从数据源中不断地获取数据,得到数据后将威胁事件的数据暂时存储在管道中,在汇聚点中将数据分为一条条的基本单位事件发向缓冲区Kafka集群中。
数据流分为许多事件类型,推向缓冲区Kafka后,根据不同的事件类型被分往不同的主题中,并储存在物理内存中。物理内存中以分区作为单位存储,等待Storm平台发送需求数据的请求,再按照请求发送相应规模的数据。传输时每条数据拥有自己的偏移量,并采用相应的机制来保证有序性和传输可靠性。
Storm平台从Kafka中得到消费数据后,其中的组件Nimbus模块则会根据当前系统的繁忙情况和可负载的数据量,将处理信息的任务分给相对空闲的数据处理组件进行处理。
3.2 网络威胁行为识别模块
该模块将知识图谱与Neo4j图数据库结合。在初始化阶段,系统根据威胁事件的各个属性来构建知识图谱,每一个节点表示一个威胁事件,节点之间的连线表示威胁事件之间的路径关系,用Neo4j来储存构建好的知识图谱,用于之后的威胁事件识别[18]。初始化完成后,从数据实时处理模块中获得实时的威胁事件流信息,比对威胁事件的各个属性以此来判断是否为相同事件,借助知识图谱的特性提高威胁事件的识别速度。
3.3 网络威胁行为自学习模块
该功能的实现主要依赖大数据平台的计算能力和知识图谱的扩展学习能力。当系统发现新的网络威胁行为,且在已有知识图谱无法识别该威胁,为此,可以对已获取的新的网络威胁行为的行为路径进行分析,与从其他终端节点上获取的此新网络威胁行为的行为特征进行比对。当系统比对一定数量后,系统便能对新的网络威胁行为的行为特征和路径准确掌握,用以更新知识图谱。
3.4 黑名单策略模块
传入威胁事件后,每次匹配成功,则将相应主机节点的威胁程度进行更新,在威胁程度超出一定范围后,认定其为被攻击者控制的傀儡计算机,自动将此主机IP加入到黑名单中,之后再广播通知集群中的各个主机节点,对此IP进行屏蔽,从而抑制由此IP发送的威胁事件的传播。
黑名单策略模块的业务流程如图6所示,当发现某台主机被攻击时,马上根据采集到的威胁事件的数据进行查询,即以该主机的IP为目的IP查询出威胁事件的源IP,并标记此源IP。判断此IP是否是所有威胁事件传播的起始IP,如果是,此源IP则为攻击者;若不是,用其他被感染主机的数据继续判断该IP是否被标记到达了一定次数N,若是则加入黑名单,并继续以此IP为目的IP进行查询,直到到达顶层,找到攻击者IP地址进行广播。
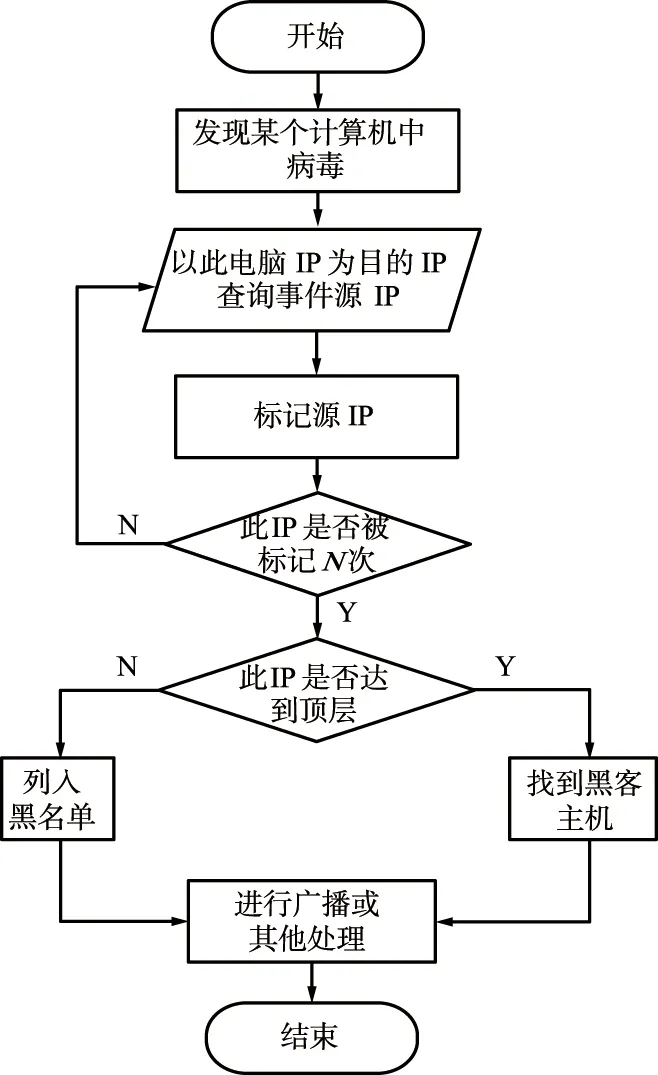
图6 黑名单策略模块流程Fig.6 Workflow of the blacklist policy module
3.5 数据持久化模块
该模块将从Neo4j图数据库中读取相关威胁事件信息,通过MySQL数据库对这些事件信息进行存储,然后再使用Mybatis,Spring和SpringMVC框架进行数据处理,最终将处理后的数据流返回给前端用户模块。数据全部用MySQL数据库进行持久化存储。由于sql写在xml文件中,Mybatis便于统一管理和优化,解除MySQL和程序代码的耦合。提供映射标签,支持对象和数据库orm字段关系的映射、对象关系映射标签和对象关系的组建。
3.6 用户模块
用户模块主要分为2个功能:注册功能和登录功能。系统会按照用户身份信息的不同将用户分为普通用户和管理员用户。普通用户即正常注册使用的用户,可以查看自己的主机遭受攻击的数据统计。管理员用户拥有高权限,可以看到所有用户的受攻击数据统计,并可以监视整个网络。
4 关键算法
4.1 基于知识图谱的网络威胁行为识别算法
基于知识图谱的网络威胁行为识别,其本质为搜集的威胁事件与知识图谱中的现有事件进行比较,具体流程如图7所示。
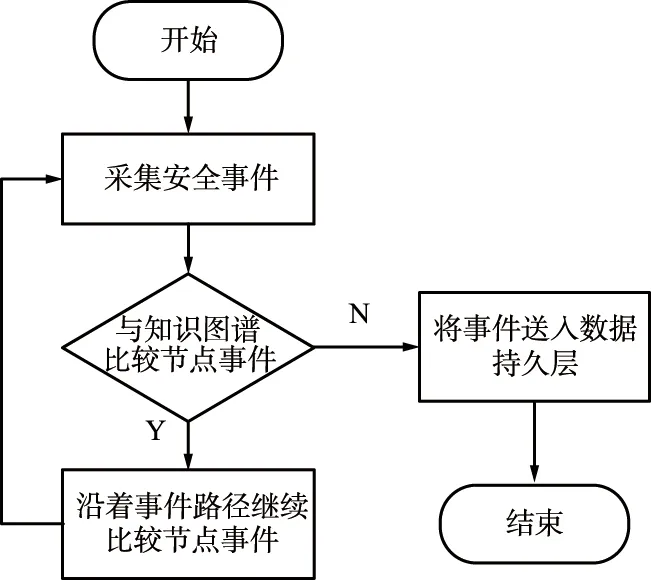
图7 基于知识图谱的网络威胁行为识别流程Fig.7 Network threat behavior identification process based on knowledge graph
在威胁识别模块接收到威胁事件时,利用知识图谱识别威胁事件[19]。将新的事件与知识图谱内已有的事件进行比较,如果与一个事件的各个属性都匹配上,则认定为2个事件相同,然后将后续威胁事件按照当前节点的路径相连的节点相比较,如此循环直到没有匹配上的,则此时威胁事件就达到了一个场景节点,然后将没有匹配上的事件传输到数据持久层供知识图谱学习。
算法1是对基于知识图谱的网络威胁行为识别过程的描述。在算法1中,安全事件作为基本事件类型,由上层的大数据平台传导,每一个事件包括不同的属性,例如源IP和目的IP等,通过对这些属性具体分析识别得到结果。

算法1:基于知识图谱的网络威胁行为识别算法Input E:Security incident M:Knowledge mapOutput E1:Not matching successfully security incidentBegin whileflag==True do Select event E from data platform if(E in M) then Continue comparison along node path Else Send events to data persistence layer End if End whileEnd
4.2 网络威胁行为学习算法
对于未能识别的网络威胁,需要通过网络威胁行为学习算法进行学习,并对已有知识图谱进行扩充[20]。网络威胁行为学习流程如图8所示。当有威胁事件被检测到时,开始判断是否为已知威胁事件,如果为是,则将攻击路径和攻击结果记录到数据持久层;如果为否,则根据攻击结果检索相同的攻击路径并计算相同路径的概率,判断概率是否大于系统设定的阈值,若大于则将此路径构建到网络威胁行为库中,若不大于则重新开始监听新的事件。
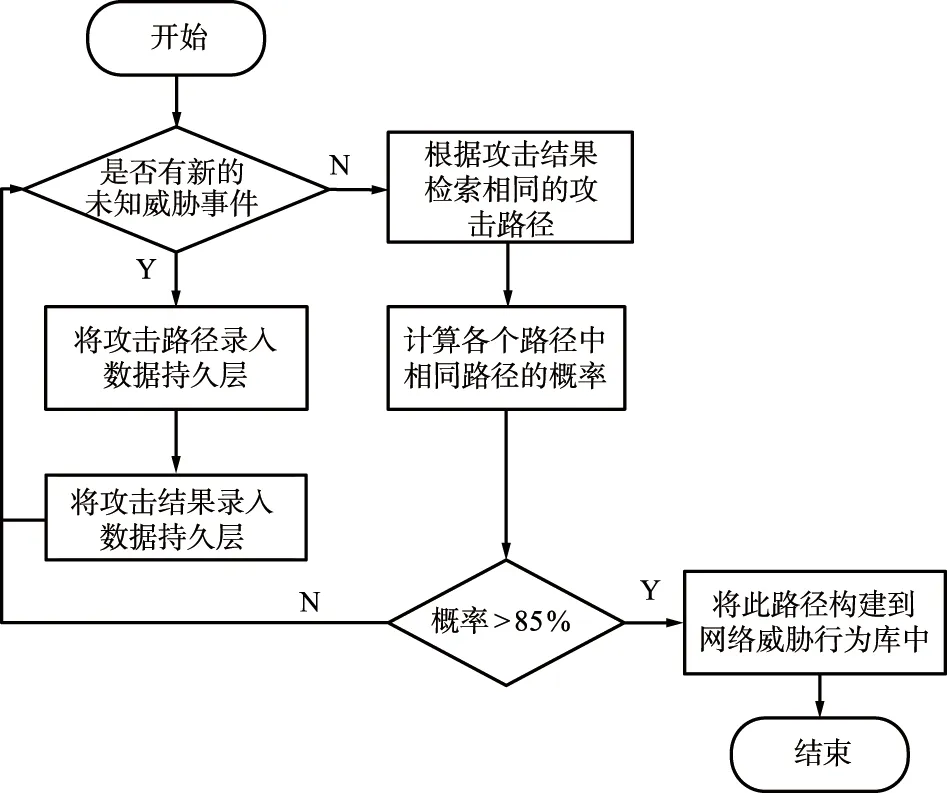
图8 网络威胁行为学习流程Fig.8 Network threat behavior learning process
算法2是对网络威胁行为学习过程的描述。

算法2:网络威胁行为学习算法Input E:Security incident D:Network dangerous behavior databaseOutput D1:Updated network dangerous behavior database Begin whileflag==True do if(E in D) then Record path into data persistence layer Record attack results into data persistence layer else Retrieve the same attack path according to the attack result Calculate the probability of the same path in each path ifprobability>85%then flag==False Build this path into the network dangerous behavior database End if End if End whileEnd
5 结束语
本文设计并实现了一个基于知识图谱的网络威胁行为分析系统。利用Flume + Kafka + Storm 构建的数据处理平台,保证大量网络威胁行为数据高效传输与处理。利用知识图谱描述网络威胁行为间的各种关系,并根据已有网络威胁行为来动态更新已有知识图谱,实现网络威胁行为的自学习。系统通过自学习、自生成的知识图谱和实时更新的自适应网络威胁行为检测方法,弥补了传统网络威胁检测方法难以检测未知、复杂的网络威胁行为的技术短板,并提升了检测效率。
