基于改进GM(0,N)的舰船装备维修费预测模型*
2022-08-02何鹏翔孙胜祥
何鹏翔 孙胜祥
(1.海军工程大学管理工程与装备经济系 武汉 430033)(2.91306部队 上海 200000)
1 引言
随着新时代海军舰船装备建设的快速发展,各种大型舰船陆续服役,其中部分舰船也集中进入了修理期,在舰船装备维修经费总量有限的前提下,经费的供需矛盾日益突出。为了合理确定新型舰船计划修理费用,提高装备经费的使用效益,迫切需要对新型舰船的计划修理费用进行准确的预测。
传统装备费用估算方法主要有工程法、类比法、参数法等,文献[1~2]运用工程法、类比法和参数法等方法对于舰船装备和战斗飞机不同时期的费用进行了估算;文献[3~4]分别运用支持向量机和案例推理的方法对舰船装备维修费进行了预测,但模型的预测精度取决于样本数据的数量,数据的样本较少时,预测精度往往不高。大型舰船装备一般都是单舰或者小批量生产,样本数据较少,灰色预测方法作为灰色系统理论的主要成果,主要针对小样本、贫信息的不确定系统进行研究[5~7],对于舰船装备维修费预测有很强的适用性。文献[8]从扰动解大小的角度证明了GM(0,N)模型更加适用于小样本建模。但舰船装备和其他复杂装备相比,其维修费与建造费、排水量等因素有着更加紧密的关系,建造费相似的舰船其维修费往往也是更为接近的。而文献[8]中仅仅依据相似度对于样本进行重新排序,并不能充分显现相似程度更高的舰船装备对于待测样本维修费的影响。
本文拟在利用距离熵分析样本之间相似度的基础上,利用累积法代替传统GM(0,N)中的参数估计方法,从而赋予相似度较大的样本更大的权重,使相似度较小的样本占据更小的权重,从而达到提高舰船装备维修费预测精度的目的。
2 GM(0,N)模型的基本原理
GM(0,N)模型通过利用原始数据累加后的灰色数据序列进行建模,可以在一定程度上弱化原始数据的随机性,提高数据序列的规律性,其模型计算过程如下[7]:
1)计算原始数据序列的一阶累加生成序列;
2)构造数据矩阵;
3)利用最小二乘法求得参数估计列:
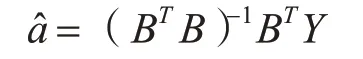
4)计算模型的预测值:
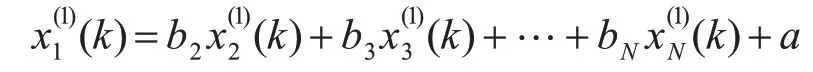
但由于舰船装备维修费影响因素众多[9],且会随着管理体制及相关政策的变化而变化,不确定性强,建造费、排水量等因素往往与维修费有着很强的正相关关系,根据支配原理,舰船装备维修费之间也必然存在着相似性,相似程度更高的样本对于维修费变化规律的影响也会更大,直接将原始数据依据累加法进行建模虽然可以弱化数据的随机性,但并没有考虑舰船装备的相似度对于待测样本的影响。
3 舰船装备维修费预测模型构建
考虑到舰船装备维修费与建造费、自身性能参数等因素紧密相关,基于“相似信息优先”原理对GM(0,N)模型运用累积法进行改进。
3.1 基于距离熵的相似度度量
熵作为一种衡量系统不确定状态的方法,与传统判断相似度的方法相比,可以利用现有信息推算出更多有价值的信息量,从而降低主观因素对于计算结果的影响[10]。如果将舰船装备看作一个复杂的系统,可以将信息熵用于判断不同舰船装备之间的相似度,系统的总熵值最小,包含的信息量也是最大的,舰船装备之间的相似度也最高。设舰船装备样本A0,A1,A2,…,An,每个样本又有m 个参数y1,y2,…,ym,xij则表示第i 个样本关于第j 个参数的指标数据。待测样本A0与Ai之间关于yj参数欧氏距离的比重vij为

则样本A0与Ai的距离熵为

其中i=1,2,…,n;j=1,2,…,m。
距离熵越小,则表示样本A0与Ai之间的性能参数信息越相似,在后续建立预测模型时,也应当赋予更多的权重。
3.2 基于相似信息优先累积的模型构建
在参数估计中,使用最多的方法是最小二乘法,该方法误差处理时需要基于误差平方和最小化的假设,但该假设是难以验证的,同时也容易造成模型估计与参数实际值相偏离。而累积法则不需要对于模型误差进行假设,该方法对样本数据进行加权和累加,进而估计模型参数,可以使预测的误差趋向于零[11~12]。但是,一般累积法可能会导致相似程度越低的信息占据更高的权重,而相似程度越高的信息却占据较低权重[13]的情况,从而使得模型的估计产生一定的偏差。
因此,本文提出一种基于相似信息优先的累积法。首先,通过对样本进行重新排序改变累积法的累积权重,使得相似程度越高的信息占据的权重越大,而与待测舰船装备越相似的样本数据也可以更好地反映维修费与各参数之间的关系。然后,使用该方法对GM(0,N)的参数进行估计,进而优化其预测结果。
假设相似信息优先累积算子的最高阶数为r,模型的参数为N。对于相似程度更高的样本,其数据累加的次数也越多。将相似信息优先的累积算子运用于GM(0,N)模型的方程式两边,可以得到下列方程组:

其中,x(1)
i(k)为重新排序后的原始数据序列的一阶累积生成序列,且

则方程组可以用矩阵形式表示为

在传统GM(0,N)模型的参数估计中,A矩阵的行数一般取决于模型中舰船样本的数量。当样本量n 小于舰船装备性能参数N 时,则无法用传统最小二乘法进行求解,还需要首先对装备的参数进行筛选,容易出现一些关键影响因素被剔除的问题。而在运用累积法计算时,A 矩阵的行数则取决于阶数r。因此,可以通过调整累积运算的阶数对于A矩阵的行数进行调整,令累加算子的阶数与舰船装备的输入参数相同,避免出现当样本量较少而相关参数较多模型无法计算的问题。
当r = N 时,只有矩阵A 中出现某一行的元素全部为0 或者任意两行(列)元素相等时,矩阵A 才为奇异矩阵。但是对于舰船装备而言,不同的舰船其输入参数及有关费用肯定是不可能完全一致的,同时也不存在数据为零的情况。因此,在累积GM(0,N)中,矩阵A的逆矩阵一定是存在的,对于参数的求解则可以直接表示为

则可求出舰船装备维修费预测GM(0,N)模型为

通过式(7)累减还原后,可以得到舰船装备维修费的预测值。
3.3 改进的GM(0,N)模型预测步骤
改进的GM(0,N)模型预测步骤如下。
Step 1:根据式(1)和式(2)计算原始数据样本与待测舰船装备之间的距离熵;
Step 2:依据距离熵的值,按照从大到小的顺序对样本重新排序并计算一阶累加生成序列;
Step 3:对于重新排序后的数据,利用累积法根据式(5)计算参数估计值a,b2,b3,…,bn;
Step 4:将模型参数估计值代入式(6)即可得到改进GM(0,N)模型,再通过式(7)累减还原即可得到待测舰船装备的维修费。
4 案例分析
本文通过调研所得数据见表1(相关数据已经进行过脱密处理),运用本文所提出的改进GM(0,N)模型对舰船装备维修费进行预测,以验证本文提出方法的可行性。

表1 舰船装备计划修理费用与性能参数原始数据表
首先,采用基于距离熵的相似度的计算方法,求得舰船装备样本F 与A、B、C、D、E 之间的距离熵分别为0.89、0.70、0.78、0.91、0.80;
1)将样本按照距离熵从小到大进行重新排序:B、C、E、A、D,并计算一阶累加生成序列;
2)计算模型参数:â=A-1*Y= [0.1136 -0.1720-0.1213 18.6993];
3)基于相似累积法GM(0,N)模型的预测公式为
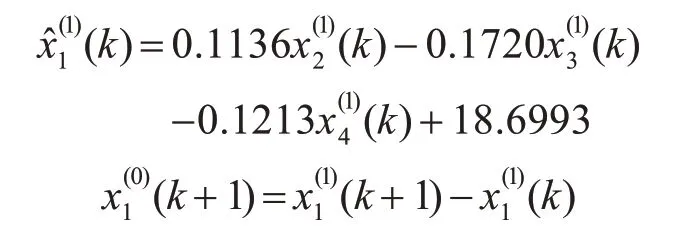
模型的拟合精度和预测精度分别如表2所示。

表2 拟合精度对比表
同时,本文采用文献[8]中的方法也进行了预测,结果见表2。从表2可以看出,本文提出的预测模型对于F 舰船装备维修费的预测值与实际值的相对误差为4.33%,优于文献[8]所提模型的相对误差8.74%;从图1 也可以直观地看到本文的模型在数据拟合时稳定性要比传统模型好,传统模型拟合的平均相对误差为3.85%、最大相对误差高达9.23%,而改进GM(0,N)模型平均相对误差仅为0.85%、最大相对误差只有1.90%。由此可见,与传统GM(0,N)模型相比,本文所提出的相似信息累积GM(0,N)模型可以更加充分地利用与待测样本相似程度更高的信息,有利于提高模型预测的稳定性和精度。

图1 两种模型的拟合误差比较
5 结语
随着大型舰船装备陆续进入修理期,对于维修费用计划的制定也提出了更高的要求,考虑到现有方法在处理小样本数据时的不足,本文提出一种基于相似优先累积的GM(0,N)模型。该方法在利用距离熵判断样本之间相似度的基础上对样本进行重新排序,再利用累积法代替最小二乘法对于参数进行估计,同时也解决了样本量较少时无法用最小二乘法对于模型参数进行估计的问题,更加充分发挥了灰色预测模型在处理小样本数据时的优势。对于新型舰船装备维修费用的估算有较强的实用性,也为利用参数法进行维修费估算从灰色理论的角度提供了新的解决方案。该方法实用性较强,也可以用于其他大型复杂装备的修理费用预测。
