数据集压缩建模的研究*
2022-08-01王赫楠孙艳秋张柯欣
王赫楠 孙艳秋 张柯欣
(辽宁中医药大学信息工程学院 沈阳 110847)
1 引言
在统计学研究中,数据序列数据挖掘是研究的重点之一[1~3]。它的研究对象是事物在不同时刻变化情况所形成的数据值。目前,各行业都存在海量的数据集。比如:医疗、金融、农业等行业。通过对数据序列变化趋势的分析和预测,揭示事物的内在规律和关联,是当下数据集处理问题的主要方向。数据集的处理研究主要有以下几个方面:数据序列的拟合[4~6]、数据序列的划分[7~8]、数据序列的分类聚类[9~11]、数据序列的应用研究[12~14]、数据序列的可视化研究。
数据集的压缩以及奇异值点的识别是数据序列数据挖掘的研究重点。做好数据集的处理,是后续进行数据分析和预测的根基。本文在分析了典型数据集处理模型的前提下,提出了数据集压缩模型以及奇异值识别模型。数据集压缩模型使用了自定义函数,符合数据集的时间局部性原理,考虑了数据集的时间特性,并且支持实时数据的处理问题。奇异值识别模型在原有模型的基础上,对于一些关键奇异值数据的识别更具优势。
2 数据集压缩模型
数据集压缩是对数据结构进行优化的一种非常重要的手段。几年来,经过计算机、数学等各方面研究人员的不断探索,提出了很多消除数据冗余的方法,在数据处理、数据压缩等方面取得了非常大的进步。
原始数据集存放在一个n 维的向量中,数据集的数据量过大及维数过高,会对后期数据的整理及分析造成干扰。我们需要对数据进行压缩处理,既能用更少的数据来索引原始数据集,又能很好地反映原始数据集的趋势变化,从而挖掘出研究者需要的有价值的信息。本文在分析了两种典型的数据集压缩方法的前提下,提出了一种新的数据集压缩模型。
2.1 压缩模型(一)
压缩模型(一)将原始数据集划分成若干段,在限制分段误差的前提下,利用各段的均值来索引原始数据集,以此达到降维的目的。

这种方法作为数据降维的一种常用手段,非常的简单。我们可以快速地对数据进行压缩处理。压缩后的数据集是可以在一定程度上反映数据集的趋势变化规律。但是我们在使用数据进行挖掘有用价值信息的同时,还希望能对未来的趋势进行预测分析。并且数据集往往具有时间局部性,比如股票数据、生物医药数据、临床数据等。我们所获得的数据集中的数据,在分析当前数据以及预测未来数据的影响是不一样的。对于当前数据来说,时间上越靠近的数据对于当前数据的影响越大,时间上越远的数据对于当前数据的影响越小。对于预测未来数据的走向也是同样的原理。
2.2 压缩模型(二)
文献[15]在对数据进行压缩的同时,考虑到了数据序列的时间局部性原理。提出了时间影响因子的概念。模型同时使用均值和影响因子,来对数据进行压缩。

从上面计算均值时的变量设定可以看出,在进行建模时,不是将压缩起始点放在数据集的开始端点,而是放在了数据集的终端。这是因为如果把起始端放在数据集的开始端点,会导致在计算影响因子参数数值时,反复重复的计算过程。为了避免这个问题,该方法将压缩起始点放在了数据集的终端。此方法确实考虑了数据序列的时间局部性原理,但是由于压缩过程中,对数据集是采用自底向上的压缩方式,不利于处理动态增长的数据问题。
2.3 压缩模型(三)
针对于以上两种常见的数据压缩模型的优缺点,本文提出了压缩模型(三)。模型既考虑了数据的压缩要求,同时也兼顾了数据集的时间局部性原理。模型的关键在如何选取合适的函数,使得压缩的模型既能反应原始数据的形态特征,又能兼顾到时间局部性。
函数的选取:如图1 所示,所选取的函数,函数值应在(0~1)之间且是递增的。
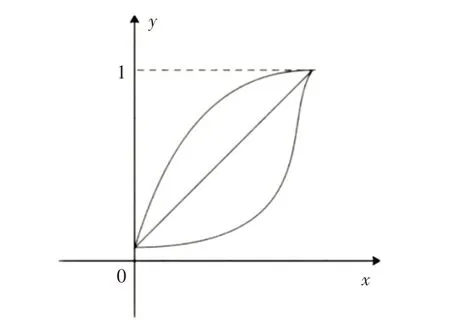
图1 可选函数模型
具体算法如下:

压缩模型(三)既可以从数据集的开始端点进行建模,也可以从数据集的尾端开始建模。可以实时在线进行建模原始数据集,方法简单易用。
2.4 实验结果
软件环境:Windows 操作系统,内存4G,64 位操作系统,JAVA语言。
数据来源:本实验使用“Time Series Classification Website”提供的数据集。

表1 数据集1

表2 数据集2

表3 数据集3
对于三种数据压缩模型,我们采用压缩后的两点数据距离与原始数据的距离差异来进行衡量,如压缩后的前后两点数据距离小于某一给定值,而原始数据两点间的距离却大于此值,对于此类情况统计后,作为三种模型压缩效果的比较。
计算公式:压缩出错统计=出错数/总查询量;在以上提到的标准数据集中的部分实验结果如图2所示。

图2 三种压缩模型出错统计图
从实验数据可以看出,压缩模型(三)在三类数据集的统计中,明显比其他两种模型出错量要小。而且相对于压缩模型(一),压缩模型(三)考虑了数据集的时间局部性原理,而对于压缩模型(二),压缩模型(三)还同时兼顾了数据序列的动态变化情况,对于实时的数据集能更好地进行处理。
3 奇异值识别模型
数据集中的数据千变万化,有些数据值频繁出现,表现了数据集的基本趋势变化,而有些数据虽然不频繁出现,但在数据的分类聚类、决策分析中更能提供有用的价值,这类数据我们称之为奇异值。如何能有效地挖掘出奇异值,对于数据集的处理和分析都有非常重要的意义。从于乐军[16]等发表相关数据序列奇异点数据识别以来,相关研究备受关注。两种典型的奇异点识别模型如下。
3.1 识别模型(一)
如图3所示数据序列:

图3 数据序列简化模型1
L((l1,t1),(l2,t2),(l3,t3),(l4,t4),(l5,t5),(l6,t6),(l7,t7),(l8,t8),(l9,t9),(l10,t10))。
识别模型(一)识别奇异点的规则如下。
如图3,L 共包含有10 个数据点的数据序列。若时间间隔相同,数据序列可记为L(l1,l2,l3,l4,l5,l6,l7,l8,l9,l10)。在10 个数据值中,l2<l3<l4,l8<l9<l10,则认为l3 和l9 为奇异值点保留。l3>l4>l5,l5>l6=l7,l7>l8>l9,则l4,l6,l8 不是奇异值。最终保留奇异值点L(l3,l9)。

以图3 为例,最终保留的奇异值点可以很好地反映数据集L 的走势变化,此方法简单易用。但随着数据量的不断增大,识别模型(一)不能有效地去除噪声。无法有效识别奇异值,滤掉冗余数据。为了更好地去掉一些噪声数据,可以对识别模型(一)进行改进,如图4所示。
图4 中,l2,l3,l4 按照识别模型(一),符合选取的奇异点条件。但是有些奇异点频繁出现,并不能表现数据集的主要特性,属于冗余数据。排除这类冗余数据可以考察该奇异点保持的时间(即该奇异点前后两个奇异点所占的时间段)与数据集总长度的比值,即T1/Length,T2/Length,若T1/Length <β(给定的阈值),删除奇异点l2,若T2/Length>β(给定的阈值),保留奇异点l3。阈值的设定需根据数据集的实际长度和所在知识领域进行设定,一般小于1。
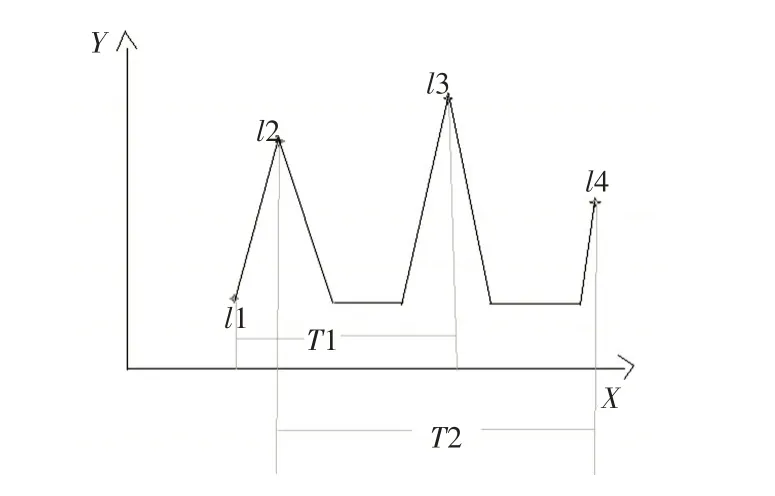
图4 数据序列简化模型2
改进的识别模型(一),可以有效地去除数据集中的噪音数据,但也容易忽略一些表现数据集主要特性的数据。
3.2 识别模型(二)
部分数据集中的数据,虽然不满足识别模型(一)的奇异值条件,但是也决定了数据集在某一时间段内的趋势变化,应该作为奇异值被识别,如图5所示。
l1,l2,l3分别为某数据集的三个连续时间点的数据。l1>l2>l3,按照识别模型(一),l2 不是奇异值数据点。但是按照整个数据形态的走向,从t2时刻的l2数据点开始,整个数据集不再按照原来趋势下降了,而是进入了一个缓慢下降区间。而这一变化正是从l2数据点开始的,那么l2数据点也应该是一个奇异点。杜奕等[17]提出,可以用距离来选取奇异值点。如图5 所示,若|d2-(d1+d3)/2|>λ(给定的阈值,根据实际情况调节),则l2被作为奇异值点。

图5 数据集的简化模型3

该方法综合了以上两种方法的优点,同时又考虑了奇异值点的特殊情况,在消除冗余数据的同时,也能抓住一些表现数据集关键特性的奇异值数据。这里λ阈值的设定需要根据实际情况考虑。
3.3 识别模型(三)
本文在综合了以上几种识别模型的基础上,提出了一种新的奇异值识别模型。如图6所示。
数据集L((l1,t1),(l2,t2),(l3,t3),(l4,t4),(l5,t5)),若时间间隔相同数据集可记为L(l1,l2,l3,l4,l5),根据识别模型(一),先选出符合条件的奇异值数据。但有些数据虽不满足模型(一),但是仍然反映了数据值的主要趋势变化,如何选取此类奇异值数据。本文提出以下方案,如图6中l2,以l2为基准做一条平行于x轴的直线,l2的前后临点l1,l3 位于横线的两侧,此时我们考察,若|(l3-l2)/(t3-t2)-(l2-l1)/(t2-t1)|>=ε,则l2作为奇异值数据点被识别;如图6 中l4,以l4 为基准做一条平行于x轴的直线,l4 的前后临点l3,l5 位于横线的同侧,此时我们考察,若|(l4-l3)/(t4-t3)|>=ε,或者|(l5-l4)/(t5-t4)|>=ε,则l4作为奇异值点被识别。

图6 数据集的简化模型4

本文提出的识别模型(三),在改进的识别模型(一)的基础上,对于特殊奇异值数据,提出了一种新的识别方法。该模型能更加有效地识别奇异值数据,并能更好地反映数据集的形态变化。
3.4 实验结果及分析
本实验所用数据集为2.4小节中所提供的数据集。

表4 数据集1

表5 数据集2

表6 数据集3
实验方案:选取的奇异值数量基本一致的情况下,比较奇异值模型与原数据集差异情况。
奇异值数量的变化使用压缩率进行衡量。例如,原数据集数据个数为α1,选取的奇异值数据个数为α2,压缩率=(1-α2/α1)*100%。

结果分析:
实验中使用了奇异值识别模型(一),改进的模型(一),识别模型(二)以及本文中提出的识别模型(三)进行实验。
如图7,四种模型在数据集1 上的差异情况比较结果,压缩率基本相近分别为91%,92%,92%,92%。

图7 四种模型与原数据集的差异比较图(数据集1)
如图8,四种模型在数据2 上的差异情况比较结果,压缩率基本相近分别为53%,65%,68%,70%。
图8 四种模型与原数据集的差异比较图(数据集2)
如图9,四种模型在数据集3 上的差异情况比较结果,压缩率基本相近分别为78%,92%,91%,92%。

图9 四种模型与原数据集的差异比较图(数据集3)
根据以上三个图的比较,在压缩率基本相近的情况下,差异情况的比较结果,模型(二)与模型(三)明显优于模型(一)以及改进的模型(一)。模型(二)与模型(三),在差异情况基本相近的情况下,模型(三)的压缩率要优于模型(二)。因此,根据实验结果可以得知,本文提出的模型(三)无论从压缩率还是差异情况的比较,都要优于其他三种识别模型。
4 结语
本文针对于目前各行业大数据背景,分析了数据集处理的现状。在分析了几种已有模型的基础上,提出两种数据处理模型,数据压缩模型(三)以及奇异值数据识别模型(三)。经实验证明,本文提出的两种模型,在数据压缩以及奇异值数据识别研究中是要优于已有的几种模型。但是,对于奇异值识别模型(三),如何选取合适的ε值,来优化压缩率以及差异值等指标,是今后需要研究的方向。
