基于层次聚类和划分聚类算法的BTS聚类算法研究
2022-07-26刘康明艾鸽张宇傅毓
◆刘康明 艾鸽 张宇 傅毓
基于层次聚类和划分聚类算法的BTS聚类算法研究
◆刘康明 艾鸽 张宇 傅毓
(深圳市国家保密科技测评中心 广东 518000)
BTS(Best Two Step)聚类算法是结合层次聚类和划分聚类算法的两步聚类算法。层次聚类算法类与类之间不可以对象交换,很容易造成聚类质量不高的结果。而划分聚类对于初始值的设定以及异常噪声数据都很敏感,所以我们研究提出了BTS算法,实验证明BTS算法可达到高质量的聚类效果。
BTS算法;层次聚类;划分聚类
1 引言
数据挖掘是很大的研究领域,本文主要针对离群数据挖掘[1]。离群数据挖掘工作一般分为两个部分:离群数据的检测[2]和离群数据的分析[3]。本文主要研究离群数据挖掘的关键部分:离群数据的检测。离群数据的检测近年来受到了很大的关注,出现了非常多的算法。层次聚类算法操作简单,能够细致地看出由小类聚成大类的过程,数据集之间的亲疏程度可以由合并过程中的水平距离看出,层次聚类也可以有效地找出异常值。但是层次聚类比较明显的不足是:无法回溯撤销,一旦一组数据对象合并,下一步的操作是在新合并成的类中进行,只要完成了一个步骤,它就无法撤销,类与类之间不可以对象交换,很容易造成聚类质量不高的结果。而划分聚类一般都是线性复杂度,很适合用于挖掘大规模数据,具有伸缩性好、高效性、简单易行的优点,但是对于初始值的设定以及异常噪声数据都很敏感,所以我们研究提出了BTS算法,结合NChameleon聚类算法和NK-means算法,两个算法互相弥补不足,达到高质量的聚类效果。
2 相关理论
2.1 NChameleon聚类算法思想
NChameleon算法主要思想是:第一阶段是形成小簇集的过程,第二个阶段是合并这些小聚簇形成最终的结果聚簇。为了保证结果的真实性,只有聚合之后的结果簇与组成这个结果簇的两个子簇之间相似时,这两个子簇才会被合并在一起,也是确保被合并的子簇是具有最相似性的。
NChameleon算法主要有三步:构造k-最近邻图、划分Gk图形成最初子簇、合并最初子簇形成结果簇。如图1所示
NChameleon算法为了确定最具有相似性的子簇对,不仅考虑了簇对之间的互连性,而且也加入了近似性特征的考量。该算法不受用户提供的静态模型的影响,它能够自适应内部特征属性,这些内部特征属性是合并簇之间的内部特征属性。为此,我们给出以下几个定义:
定义2.1:Gk-k最近邻图,对于数据对象p,如果数据对象o是p的k个最相似对象之前,则p与o之间有一条边,这样最后形成Gk.
定义2.2:簇P和簇O的相对互连性用RI{P,O}表示,表示簇P和簇O之间的内部互连性与每个簇的绝对互连性的相互联系,即:
其中,EC{P,O}表示内部互连性,簇P和簇O连接所用到的所有边的权值之和,EC{P}表示绝对互连性,簇P划分为两个近似大小的子簇时,连接簇内的各个数据对象的边的权值之和。
定义2.3:簇P和簇O的相对近似性用RC{P,O}表示,表示该簇对之间的内部近似度与每个簇的绝对近似度的相互联系,即:
其中,TC{P,O}表示内部近似度,簇P和簇O连接用到的所有边平均权值,TC{P}表示绝对近似度,簇P划分为两个近似大小的簇时,连接簇内的各个数据对象的边的平均权值。|P|与|O|分别代表簇P和簇O中包含的所有数据对象的数目。
定义2.4:F(V)是度量合并的相似度函数,动态建模确定簇与簇之间的相似度,同时考虑相对紧密度和相对互连度来合并最相似的簇对,选择合并是该函数值达到最大的簇对,即:
F(V)=RI(P,O)*RC(P,O)α(2.3)
其中,α是用户指定的参数,若α>1,则Chameleon算法更重视相对紧密度;若α<1,则相对互连性更重要。所以α=1时,相对互连性和相对紧密度同样重要。
2.2 NK_Means算法思想
定义2.5:噪声衡量指标V{S,H},噪声或者孤立点数据容易干扰聚类效果,因此加入噪声衡量指标来改进原始K_Means算法,即:
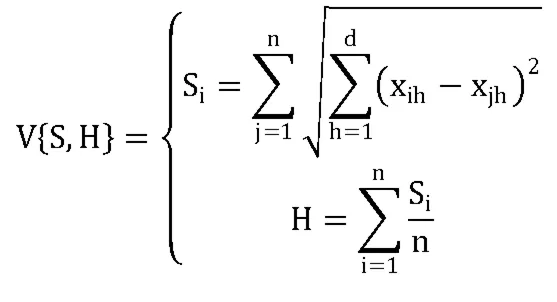
其中,n为样本数据集,d为数据维数。
NK_Means算法具体流程如下:
(1)针对聚类后的数据集,计算每一个数据对象的噪声衡量指标。
(2)对每一个数据对象P,如果Sp>H,将P作为数据集的孤立点。
(3)删除孤立点或者将孤立点导出到异常值列表中,获得新的数据集X。
(4)从数据集X中随机选取K个初始聚类中心C1,C2,…,Ck。
(5)依据初始聚类中心C1,C2,…,Ck对数据集进行划分,划分根据以下原则:若dij(xi,cj) (7)如果对∀ i∈{i=1,2,…,k},都有ci*=ci,那么算法结束,其中c1*,c2*,…,ck*表示最终形成的聚类,否则,另ci=ci*,返回到步骤(2)。设置一个迭代次数阀值,用来防止达不到终止条件时会出现无线循环。 (8)把聚类的结果输出。 BTS聚类是一种很高质量的有效的聚类算法,接下来将通过以下几个方面的对比进行验证:一个是分别和一趟聚类NChameleon、一趟聚类NK_Means作对比,一个是改进前的两阶段聚类作对比。全面分析验证BTS聚类算法的高质量性以及有效性。所采用的测试数据集是UCI数据集中的Pen-Based Recognition of Handwritten Digits数据集,该数据集总共有10992条记录,每条记录有16个数字属性。实验将从簇个数的变化实现精度的比较,是由于需要进行实验的聚类算法都需要手动指定K 值,BTS可以自动指定K值,BTS的实验将会从动态指定K值和自动生成K值两方面实验来发现自动指定K值的聚类稳定性以及高效性,对比实验数据如图2所示: 图2 聚类算法效果对比 从图2中可以发现,改进前的两阶段聚类比一趟聚类NChameleon与一趟聚类NK_Means有更好的聚类质量,说明两阶段聚类可以在一定程度改进一趟聚类的聚类质量,而BTS聚类的聚类质量比两阶段聚类更好,说明结合NChameleon算法和NK_Means算法能够弥补它们各自的不足以达到聚类质量的提高。 本文分析了传统的层次和划分聚类算法的不足,并针对一些不足进行了改进,得出了基于NChameleon和NK_Means算法的BTS聚类算法,大大提高了聚类质量。但聚类结果还是会存在异常数据点,如何对聚类数据集进行全面异常分析是我们下一步的研究目标。 [1]王茜,刘书志. 基于密度的局部离群数据挖掘方法的改进[J]. 计算机应用研究,2014(06): 1693-1696+1701. [2]汤俊,熊前兴. 基于时间序列相似度的离群模式检测模型[J]. 武汉大学学报(工学版),2006(03):111-114. [3]卢正鼎,王琼. 基于相似度的离群模式发现模型[J]. 华中科技大学学报(自然科学版),2005(01):22-24+27.3 实验验证

4 结束语
