基于预训练的恶意软件分类方法
2022-07-25周安民
凌 祎,周安民,贾 鹏
(四川大学网络空间安全学院,成都 610065)
0 引言
恶意软件的规模和造成的经济损失逐年上涨,并且恶意软件的产业化现象明显,攻击方法变化多样,攻击的目的性越来越明显。近年来,恶意软件检测主要使用传统动静态检测方法提取恶意软件特征,包括利用控制流图及字节流等信息。随着深度学习的发展以及在恶意软件检测上的应用,研究者能够将更多维度的信息嵌入到代码的特征向量中,能够有效避免统计特征的局限性。受到近些年来自然语言处理发展的启发,在处理汇编语言时可以将汇编文本看作自然文本来进行特征提取,而随着经典的word2vec逐步向BERT等基于大量文本的预训练模型发展,基于汇编语言的恶意软件检测方法也可以采用类似的方法。虽然汇编语言可以看作自然语言来处理,但是其语法结构和含义与实际的自然语言还是存在一定的区别,因此在预训练部分需要自行进行训练并重新定义新的语法结构。
常见的基于深度学习的恶意软件检测方法,大多利用了统计特征,近几年逐步也有利用自然语言处理的特征提取方法出现,依据自身的上下文及语义信息来生成特征向量。针对传统自然语言处理和汇编语言的差别,本文提出了一种新的检测方法,该方法利用自建数据集WUFCG 对基础BERT 模型进行预训练,一定程度上弥补了自然语言和汇编语言在嵌入过程中的差别;针对程序运行的特点,不再仅仅把程序基本块相连而是在基本块的基础上再以函数作为图节点进行嵌入。
1 检测模型概述
本章节将介绍检测模型的整体概况和关键技术细节。
1.1 控制流图及函数调用图
基本块是程序运行的基本单元,由基本块构成的程序控制流图能够很准确地反映程序的特征,并且控制流图天然形成图结构=(,),基本块本身作为图顶点(),控制流关系形成边()。但在程序实际运行时,由基本块构成的函数结构也是客观存在的,仅仅只考虑基本块构成的图结构会存在信息损失,本文在控制流图(CFG)的基础上引入了函数调用图(FCG)结构,使得分类效果更加精确。
1.2 特征提取及BERT预训练
传统的基于深度学习的恶意软件检测特征提取大多基于指令数量的统计特征,例如统计常量代码、比较指令、调用指令、算数指令、MOV 指令等,近期也有一些基于经典自然语言处理的特征提取方法取得了相较于统计特征更好的效果。该方法采用BERT对汇编文本进行特征提取,相较于经典自然语言处理方法,针对恶意软件环境利用恶意软件数据集WUFCG 对BERT 进行预训练,并对BIG2015 数据集进行文本嵌入,如图1所示。
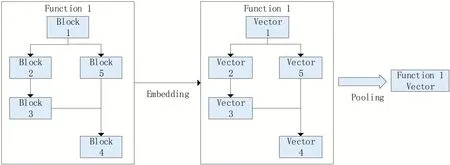
图1 函数的嵌入框架
1.2.1 数据预处理
第一部分为预训练阶段的数据预处理,利用WUFCG 中的恶意样本,首先将二进制文件进行逆向并对汇编文本预处理,在一个单独的基本块中,把基本块中冗余信息剔除,每一行代码内部使用短横线连接,每行代码之间使用空格隔开,每一行代码看作一个单词,一个基本块看作一个句子,在单个函数中,相连的基本块另起一行,函数与函数之间以空行间隔,这样单个函数则可以看作一段,如图2所示。

图2 文本预处理示意图
第二部分BIG2015 数据集的预处理,利用数据集中已逆向完成的汇编文本(.asm文件)。
1.2.2 预训练
汇编文本处理以后,再利用BERT预训练模型训练参数,在预训练环节中,使用WUFCG 来训练BERT。在后续的训练中,主要利用BERT的向量模式对BIG2015 数据集中的汇编文本进行嵌入,即将基本块汇编文本(单句)嵌入。BERT 模型本身不含任何参数信息,GOOGLE 团队在完成BERT算法后利用自身计算资源使用大量自然语言文本来预训练,而汇编语言的单词远没有自然语言丰富,直接利用官方参数不够精确。BERT 的预训练部分核心为两个任务,第一个任务为Masked Language Model,第二个任务为Next Sentence Prediction。Masked Language Model 旨在一个句子中随机选中若干token 用于在预训练中对其进行预测,被选中的词语有80%的概率被替换为[MASK],10%的概率被替换为其他token,10%的概率不被替换;Next Sentence Prediction(NSP)旨在预测两个句子(基本块)是否会相连,在本文的环境中即预测两个基本块是否会相连,在函数内部结构层面进行信息的提取,如图3所示。

图3 预训练框架
1.3 训练模型
本节将介绍整体的恶意软件分类模型。在上一节中获得了基本块的嵌入形式,为了利用FCG 进行图分类,还需要将整个函数中的基本块图池化,我们利用邻接矩阵将函数内部的信息进行两次传播,再通过平均池化获得函数的嵌入表达形式即带属性的FCG,公式(1)如下。


在图神经网络训练阶段,我们采用SAGPool来完成最终的图分类。在图神经网络中,图的节点的特征信息和图的结构信息都会对最后的分类结果产生影响,仅仅只关注某一方面的信息是不准确的,经典图的池化方法Set2Set、SortPool、DiffPool 均在考虑结构与节点信息方面有所欠缺,因此本文选用综合考虑了节点特征信息和图拓扑结构信息的SAGPool 来对最终的FCG进行池化分类。
SAGPool 采用了Self-Attention 机制,改写了GCN 经典结构,增加了自注意力参数,获得用于 池 化 的 自 注 意 力 得 分∈R,公 式(2)如下。



其中idx 为前「」 个节点索引,为特征注意力mask,更多细节请参考原文。
SAGPool有两种经典模型,全局池化结构和分层池化结构,全局池化结构相较于分层而言在小图上表现更加优异,而我们的样本以小图为主,因此选用全局池化结构,图神经网络结构如图4 所示,左为全局池化,右为分层池化,图中Graph Convolution层为标准的图卷积层。
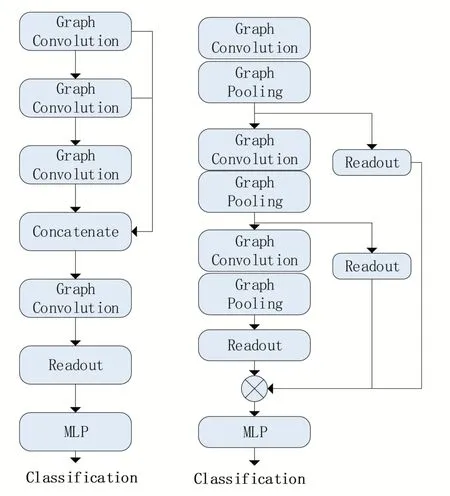
图4 SAGPool池化框架
2 实验及分析
本节将评估我们的恶意软件分类效果,实验所使用深度学习框架为pytorch,服务器操作系统为Ubuntu16.04,CPU 为Intel Core E5-2630 2.60 GHz,GPU为GTX 2080Ti,显存48 G。
2.1 数据集
实验部分使用了两个数据集,第一个数据集为自建数据集,是只含恶意样本的WUFCG,共含恶意样本33554 个,均为x86/i386 结构,恶意样本来自安全网站、安全厂商以及相关论坛,经过预处理后形成了60G 训练文本;第二个数据集为2015 年Kaggle 主办的微软恶意软件分类比赛中所使用的恶意软件数据集BIG2015,共包含9 个恶意软件家族,共10868 个样本,包含十六进制文件(不含PE 头)和IDA PRO 生产的汇编文件,但汇编文件中包含一些无效的文件(因加壳导致.asm 文件为乱码),数据集详情如表1所示。

表1 BIG2015样本
2.2 实验结果及分析
实验部分采用十折交叉验证,主要关注准确率、精确率、召回率以及1 值,实验结果如表2所示。

表2 实验结果对比
由于设备原因,实验部分BERT采用的参数为最小模式BERT-TINY。实验结果表明,在参数量最小的BERT模式下,其分类结果已明显优于传统方法。
3 结语
该方法基于BERT 和SAGPool 实现了对恶意软件家族分类,并取得了理想的效果。该方法不仅可以用在恶意软件家族分类上,在恶意软件检测、漏洞检测方面亦可有一定的拓展,具有实际意义,在后续的工作中可以考虑修改SAGPool 中的部分图卷积细节、增加BERT 参数量来提高最终的效果。
