基于混合属性的用户检索意图识别方法
2022-07-25邢小东
邢小东
(山西大同大学计算机与网络工程学院,大同 037009)
0 引言
知识检索是知识管理和知识共享的一种有效实现途径,是用户主动获取知识的典型应用。用户可以通过检索引擎找到多种类型的知识来满足不同的需求。检索行为是一种用户行为,每种检索行为都对应了用户的检索意图。准确识别用户检索意图是检索引擎优化的重要研究内容。它可以用来对检索结果进行排序,使检索引擎更加智能化。
检索意图识别就是让检索引擎知道用户“为什么”进行检索。不考虑用户检索意图的情况下,检索引擎依据用户输入的查询关键词与知识的索引进行匹配,从而确定检索结果。该过程采用基于匹配模型、排序算法以及语义分析等技术实现智能检索。这类模型和算法依赖于索引和查询关键词中的词频信息。但是,用户输入查询关键词是根据自身的检索意图,并不会考虑词频信息。在许多应用场景中,用户无法预知某个关键词在哪条或哪类知识中词频最高。例如,关键词“流程优化”对应两类知识,分别是论文和案例。技术研究人员可能想要找到论文,而生产销售人员可能想要找到案例。无论关键词“流程优化”在哪类知识中出现的词频更高,都不能同时满足不同用户的需求。
用户检索意图的相关信息包括两个部分,一部分是用户属性,例如用户的身份、职业、工作性质等,不同属性的用户,检索意图也不相同;另一部分是查询属性,即用户输入的查询关键词,每个查询关键词对应不同的知识类型,因此本文更关注词汇的范畴,而不是词汇本身,依据词汇的范畴,可以确定其对应的知识类型。本文综合考虑两部分信息,提出了一种基于混合属性的用户检索意图识别方法,该方法首先采用机器学习分别对用户属性对应的检索意图和查询属性对应的检索意图进行识别,然后采用回归分析将两种用户意图进行融合,获得最终的用户检索意图。
1 用户检索意图识别总体框架
本文将用户检索意图分为两类:用户属性对应的检索意图(User attribute Intention,UaI)和查询属性对应的检索意图(Query attribute Intention,QaI)。如图1所示,UaI的识别需要包含用户特征的样本数据,QaI的识别需要包含查询关键词范畴的样本数据。两类样本数据均可以通过检索日志文件获得,依据两类样本数据的数据类型,本文分别采用决策树学习和最大熵学习方法识别UaI 和QaI,然后采用二元线性回归分析方法将UaI 和QaI 进行融合,获得最终的混合属性对应的综合检索意图(Mixed attribute Intention,MaI)。
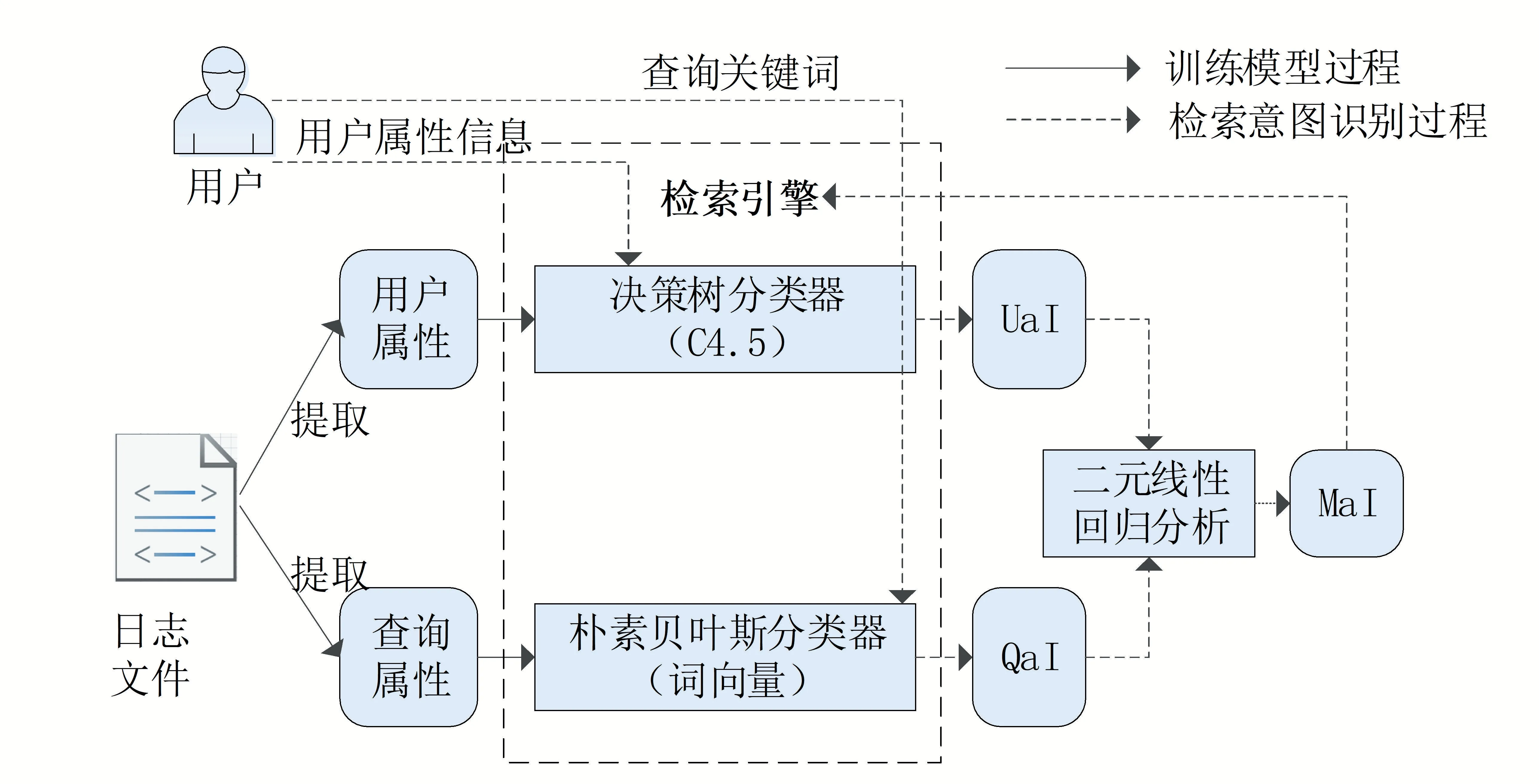
图1 用户检索意图识别总流程
2 训练样本准备
2.1 查询关键词向量
本文采用词向量描述每个查询关键词的特征。以某航天企业知识管理中的检索引擎为例,通过词向量学习及可视化分析,发现获得的结果中词汇被分为:人名、组织机构名称、地名、时间、专业术语。各类词汇数量统计如图2 所示,其中人名、组织机构名称、地名、时间都是通用词汇;专业术语是应用场景对应的专业领域中的特有词汇,在不同的专业领域,通过其知识库学习得到的词向量也不相同。
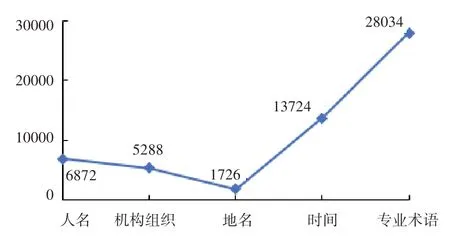
图2 关键词统计分析结果
2.2 检索意图分类
用户检索意图对应知识的类型,本文以某航天企业知识库为知识源,采用向量空间模型将知识表示为特征向量,采用DBScan 方法进行聚类分析和可视化分析,得到的聚类结果显示,知识被分为6个类别,各类知识的统计结果如图3所示,分别是链接类知识(URL.)、新闻类知识(New.)、概念解释类知识(Wik.)、制定的标准(Sta.)、技术报告(Tec.)、科技论文(Pap.)。每种类型的知识对应着不同的检索意图,如表1所示,本文梳理了用户检索意图与其知识类型的对应关系。

图3 知识聚类分析结果

表1 用户检索意图与知识类型对应表
3 用户检索意图学习
3.1 UaI学习
UaI是由用户的身份、职业、工作性质以及当前任务的类型等用户属性确定的,在UaI的学习过程中,输入和输出的特征与类别均为离散型数据,本文采用决策树学习对UaI的学习建立训练模型,采用C4.5 算法能够有效地对决策树进行剪枝,防止过拟合现象发生。UaI学习过程的伪代码如下:

获得决策树模型后,未来在用户进行检索时,检索引擎便能够从日志文件中获得用户属性的各项取值,进而便能够使用训练好的决策树模型进行预测,通过计算能够获得当前用户的UaI。
3.2 QaI学习
QaI是由查询关键词所属的范畴对应的检索意图,本文在前期已经训练好了关键词的词向量,词向量的每个维度可以看作关键词的一个特征,其取值均为数值型,维度之间相互独立,并且检索意图所对应的知识类型也仅有6 类(URL.,New.,Wik.,Sta.,Tec.,Pap.)。本文采用朴素贝叶斯分类器学习QaI,训练分类器的样本数据同样从日志文件中获取,QaI学习流程伪代码如下:
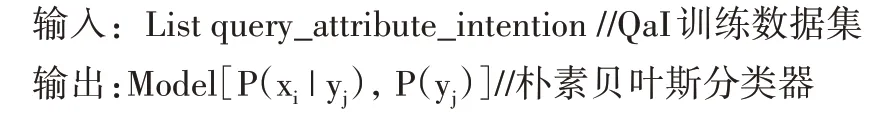

分类器训练完成后,当用户在检索时输入了查询关键词之后,便以查询关键词的词向量作为输入,通过分类器计算,获得查询关键词对应的检索意图。
3.3 MaI学习
用户检索意图的识别是将其对应的知识类型进行排序,将得分较高的类型的知识排在前面,以满足用户检索意图,通过UaI 和QaI 的学习,可以获得用户各项检索意图的得分,通过归一化处理,可得其对应的概率分布,如式(1)和式(2)所示,可将其表示为概率分布向量,概率值较大的项对应的检索意图即是得分较高的检索意图。

上文分别从用户属性和查询属性两个维度获得了用户意图得分,即UaI 和QaI,本文对两部分得分向量建立了二元线性模型,并通过二元线性回归分析,最终确定了各自的权重值和MaI的计算模型,如式(3)所示。
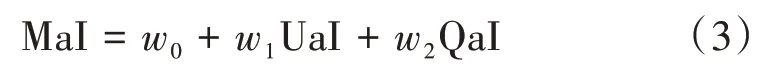
当给定了用户属性和查询关键词后,该模型便可以分别计算UaI 和QaI,最终计算MaI 的概率分布向量,用以指导检索结果的排序,实现对检索引擎的优化。
4 实例验证
本文以某航天企业知识库的检索为例开展验证,该知识库涉及工艺优化、工艺设计、结构设计、可靠性分析、可行性分析等方面的知识,在第2 部分,已经给出了数据准备的情况。本节将通过实验,与单一机器学习方法进行对比,并与传统的检索引擎进行对比。以用户知识包中的知识类型作为参考标准,对检索结果的准确率进行评价。
本文将检索意图分为用户属性对应的检索意图和查询属性对应的检索意图,相对于单一的检索意图而言,能够获得更高的准确率。单一检索意图是指将用户属性和查询属性看作整体,采用单一机器学习算法进行训练,如图4所示,可以看出本文区分不同属性对应的检索意图相比单一检索意图学习而言,准确率更高。

图4 混合属性与单一属性对比结果
除此之外,本文还与常用的检索引擎Lucene、Solr、Sphinx 进行了对比,如图5 所示,可以看出本文通过识别用户检索意图对检索引擎进行优化后,准确率相对有所提高。

图5 与其他检索引擎对比结果
5 结语
本文针对检索引擎的优化问题,提出了一种基于混合属性的用户检索意图识别方法,并应用于检索引擎中。该方法的主要优势是对不同类型的属性采用了不同的机器学习方法,以提高用户检索意图识别的准确率。对于离散型的用户属性,采用了决策树学习方法;对于数值型的查询关键词向量,采用了朴素贝叶斯分类器方法。本文以某航天企业知识库的检索为例,分别与单一属性的检索意图识别方法和目前常用的开源检索引擎进行了对比实验,实验结果表明,在准确率方面,本文方法均表现出了优势。
