基于决策树模型的分布式存储数据纠删码修复
2022-07-20沈洪敏周功建
沈洪敏,周功建
(厦门大学嘉庚学院,福建 漳州 363105)
1 引言
随着信息、网络、电子技术的迅速发展,以及大数据时代的来临,不断催生信息数据越来越呈现爆炸性的增长,同时数据规模也呈现指数级上升的现象[1]。与此同时,使得当前信息技术的发展方向越来越变为以数据存储为核心的计算机信息技术发展。基于分布式的数据存储系统作为当前数据存储的主要应用技术之一,充分结合了数据存储系统、计算机技术、集成电路技术以及计算机网络技术发展的结晶。同时,构建基于分布式的数据存储系统其目的就在于充分利用当前相对廉价的数据存储软硬件资源、网络软硬件资源,从而构建超大规模、可靠性高以及具有强扩展性的数据存储与应用系统。然而,当前随着数据获取方式不断增多、数据类型日趋复杂、以及数据增长方式呈现前所未有的数据变化,从而造成数据在进行分布式存储的过程中,呈现存储节点数量逐步上升、节点的分散性高、异构性以及易失效性等问题,给传统的数据存储方式以及数据存储过程中的可靠性带来严峻的挑战[2][3]。
因此,在进行分布式数据存储系统研究的过程中,如何进一步提高系统的可靠性、容错性以及数据恢复精度等内容,同时进一步降低软硬件数据修复开销成为当前分布式数据存储系统的研究热点。
通常来讲,分布式存系统在进行提高数据容错的方法主要从以下两个方面进行研究,即多副本数据存储技术以及数据存储纠删码技术[4]。顾名思义,多副本数据存储技术就是将需要保护的原始数据以多个数据副本存储在不同的数据节点上,在进行数据恢复的过程中出现无效节点时,可以将其它未失效的节点副本数据复制覆盖掉失效节点上,从而实现对失效节点上的数据进行恢复。很明显,多副本数据存储技术在进行数据存储与恢复的过程中修复原理简单直观,而且更有利于实现,因此该方法是目前应用最为广泛的数据存储与容错技术。很明显可以看出,轻量级数据采用此方法极为有利[5]。但是,当遇到海量数据存储与修复的过程中,为了保证数据的可靠性和容错性,需要消耗大量存储空间,会极大的耗费人力物力和财力。
为了解决多副本容错技术带来的缺点,数据纠删码技术应运而生,该方法通过将原始存储数据按照一定编码规则对原始数据进行编码,将编码得到的具有冗余信息的冗余数据按照一定规则一并存储到对应的数据节点上,从而达到存储数据容错的目的[6]。在进行数据恢复的过程中,如果数据出现异常,通过对剩余有效数据进行读取,然后按照数据存储过程中的数据编码规则,采用对应的译码算法完成对异常故障节点的数据进行恢复。由于该方法无论在存储资源消耗、数据存储节点结构等方面很多优势,因此该方法越来越成为当前分布式数据存储与纠删技术的研究热点。其中比较典型的数据纠删码算法有,EvenOdd纠删码算法,Free Codes,RDP算法以及HRCSD等纠删码数据容错算法。同时在此算法的基础上,很多研究学者提出了新的数据纠删容错算法。其中,文献[7]根据EvenOdd算法的特点,提出了同时针对多列误码的G-EvenOdd数据纠删算法。与此同时,文献[8]同样基于EvenOdd基础算法,提出了基于扩展EvenOdd的存储数据纠删模型,该模型描述了一种新的星形编码方案,用于纠正三重存储节点故障(擦除)。星型码是双纠擦偶奇码的扩展,是广义三纠擦偶奇码的改进,然后详细介绍了星型码解码算法,同时应用于纠正各种三节点故障。最后通过实验表明,该方法在针对任意三点故障星型码的有效性,验证了该模型在应对需要更高可靠性的存储系统具有很好的实际意义。文献[9]在研究纠删码的过程中,作者将网络编码的思想引入其中,同时结合网络中的信息流图来进行对存储数据的修复问题进行数学建模,通过分析没此修复数据的修复带宽的大小来进行评判该方法的优越性。文献[10]提出采用建立在可用带宽的存储数据修复模型,这种模型通过分析优化对应的线性网络编码的数据修复速度。从实际使用角度可已看出,该方法的局限性主要在于除了要维护现有的数据,同时还可以有效维护大量的节点信息,很难解决整个系统的负载均衡问题。于此同时,文献[11]于2005年经由IBM实验室提出了关于针对多磁盘故障的纠删算法,比如HoVer码以及R5X0码等方法。
综合以上可以看出,在关于纠删码算法的研究过程中,主要集中于纠删码的以下的问题。首先,纠删算法的冗余度问题,即系统在满足一定纠删性能的情况下产生多少冗余编码才可以满足整个系统的性能;其次,纠删算法编码的复杂度问题;因为纠删算法的复杂度不仅直接影响文件的存储时间,同时也是衡量纠删算法优劣的一个性能指标;最后,纠删算法的译码复杂度问题,该问题类似于是编码算法逆,同时也直接影响整个数据块文件重构的修复速度,因此在研究纠删算法时,必须考虑以上三个问题。同时,还要关注整个纠删算法的数据修复的成功率问题以及数据结构、节点的优化问题。
因此,本论文利用决策树模型在数据决策时的优越性,建立了基于决策树模型的分布式存储数据纠删码修复算法。该方法通过采用决策树模型对原始数据进行分类编码,同时将得到的决策树模型带来的冗余数据存储于模型中不同节点上,从而满足超大规模数据并行存储与修复的需求。
2 纠删码算法原理
纠删码算法作为当前比较典型的数据存储与修复算法,由于其占用资源少、可靠性高以及修复速度快的优点引起了国内外众多研究学者进行算法研究。在进行研究纠删码之前,首先对以下几个基本概念进行解释;首先,将数据块定义为分布式数据存储的过程中,将数据按照设定大小形式来进行存储;其次,在进行编码存储的过程中将存储冗余信息(校验信息)所占用的存储块成为冗余块,同时在进行纠删码存储的过程中也将该内容称为校验块;然后将存放数据块的节点以及校验数据的节点分别成为数据节点和校验节点。典型纠删码技术的基本原理如图1所示。
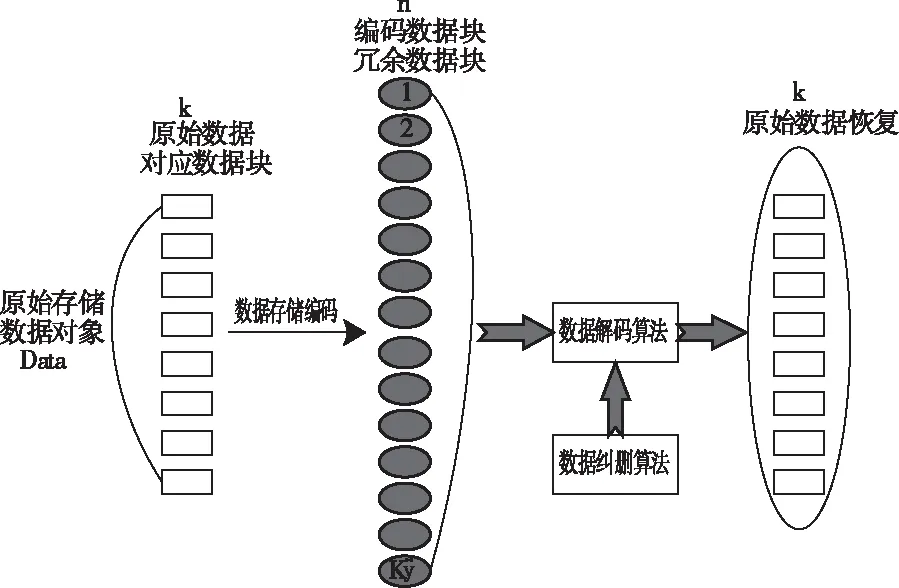
图1 纠删码原理结构示意图
如图1所示可以看出,假设利用经典的三元组数据(n,k,k′)来表述纠删码。首先,将原始的存储数据Data,分别存储与对应的分解为大小恒定的k个数据块中。因此,可以得到需要的数据块个数为
Nblock=Size(Data)/k
(1)
在对原始数据进行编码的过程中,一般都会采用特定的数据编码算法,对所有k个数据块进行编码,然后可以得到Nblock数据块。在对Nblock个编码数据块进行存储的过程中,分别将Nblock数据块存储在N个不同的存储节点上,这些节点之间相互独立,在进行恢复数据的时候,如果其中某些节点出现问题或者丢失,可利用其它存活的节点来完成对数据的恢复。
由于本文主要描述纠删码在数据恢复中的作用,因此在进行数据恢复过程中,首先以4数据块与2冗余数据块为例,建立对应的数据编码方法:
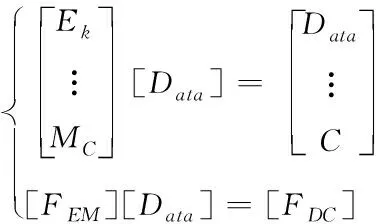
(2)
其中,MC表示编码系数矩阵,C为编码矩阵元素;Data需要存储的编码数据;Ek表示与存储数据行列数大小对应的单位阵。利用公式(2)完成对数据编码存储。在进行解码的过程中,如果对应的编码块节点出现错误,如公式(3)所示
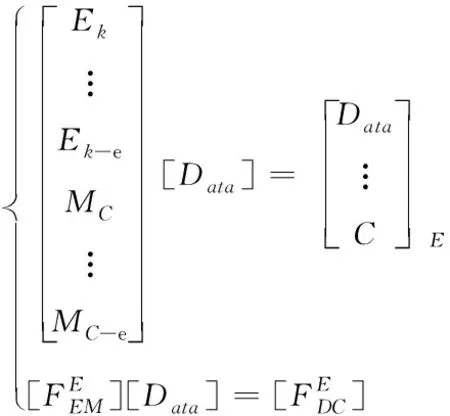
(3)
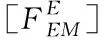
根据公式(2)和(3)可进行恢复损失的数据,在进行恢复的过程中首先构造对应的数据恢复矩阵
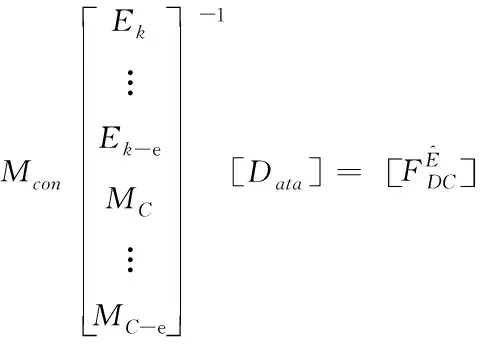
(4)
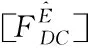
2.1 基于决策树模型的纠删码数据恢复算法
在进行数据存储恢复的过程中,虽然传统经典的纠删码数据恢复算法已经得到广泛的应用,但是依然存在数据恢复效率低,构建繁琐等处理问题。为了解决以上问题,本文集合决策树在数据处理中的应用,建立基于决策树模型的纠删码数据恢复算法。
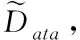
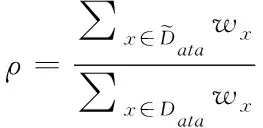
(5)
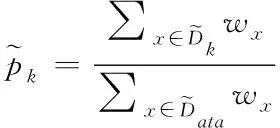
(6)
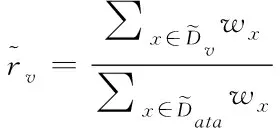
(7)
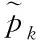
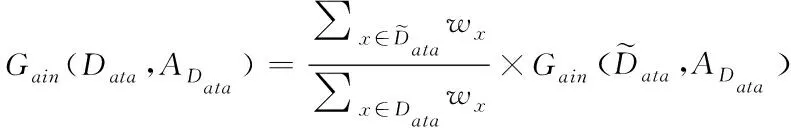
(8)
进一步得
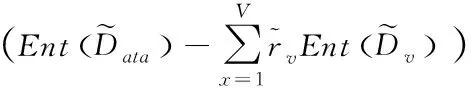
(9)
其次,为了描述确实节点数据的纯度,文章采用决策树模型中的基尼数值来进行描述。基尼值定义如下
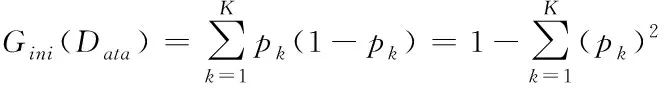
(10)
其中,K为描述存储数据的分类级别数;pk表示数据中的样本点属于第K阶分类的概率;可以清楚的发现,如果样本点数据属于上述定义的1类的概率p,这样可以得到对应的概率密度的基尼指数为
Gini(Data)=2p(1-p)
(11)
同时,对于节点数据AData的基尼指数为
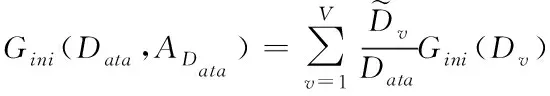
(12)
因此,结合公式(11)-(12)可以看出,在对确实数据进行分类的过程中Gini(Data)对的数值越小,则存储数据缺失的节点数据越小。
在结合纠删码建模的过程中,具体结构流程示意图如图2所示。其中,首先将对应的原始数据进行数据遍历,通过遍历获得对应的样本点数据,以及样本数据对应的存储节点集。在进行数据恢复的过程中不断去验证对应恢复数据的基尼指数,看是否基尼指数到达满意的程度。
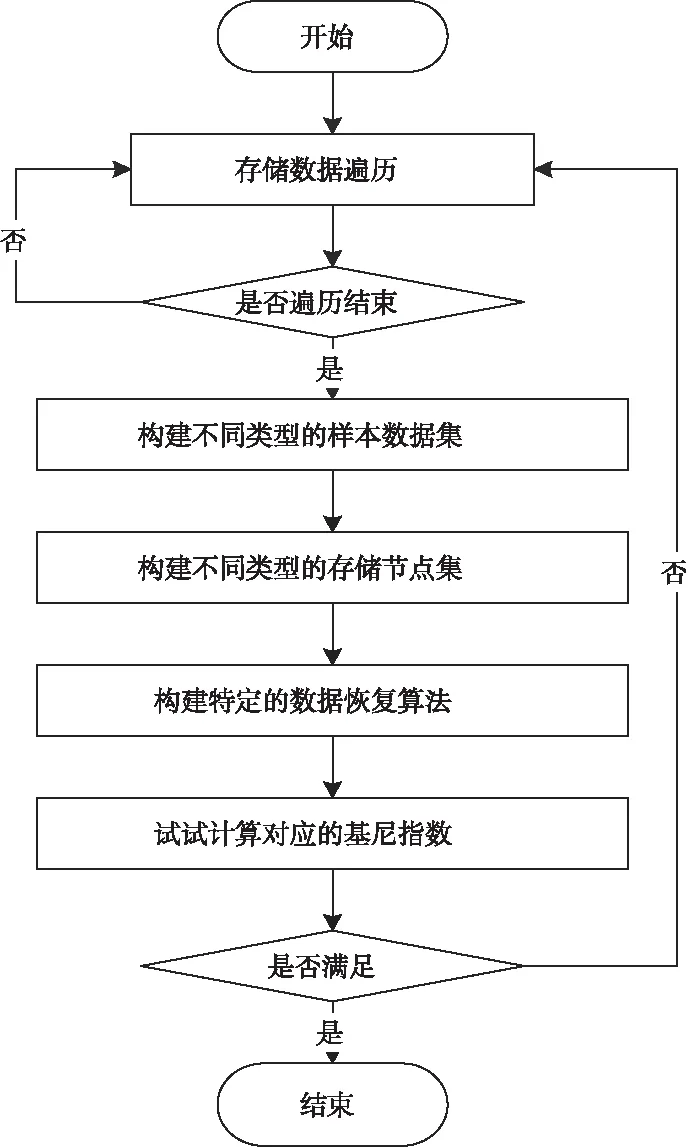
图2 决策树纠删流程示意图
3 数字仿真与数据分析
为了验证本文提出算法在数据恢复过程中的有效性,分别采用不同的方法来进行对比,同时在不同角度来进行分析本文算法的优越性。
首先,分析存储开销方面。在进行数据存储的过程中,数据存储的开销与数据效率通常定义为实际数据大小空间M与数据在存储系统中所占有的实际存储空间S的比值。为了说明本文有效性,本文将三副本技术、HRCSD码、S2-RAID码以及本文提出的方法分析存储开销。4种策略所占用的存储空间开销如图3所示。
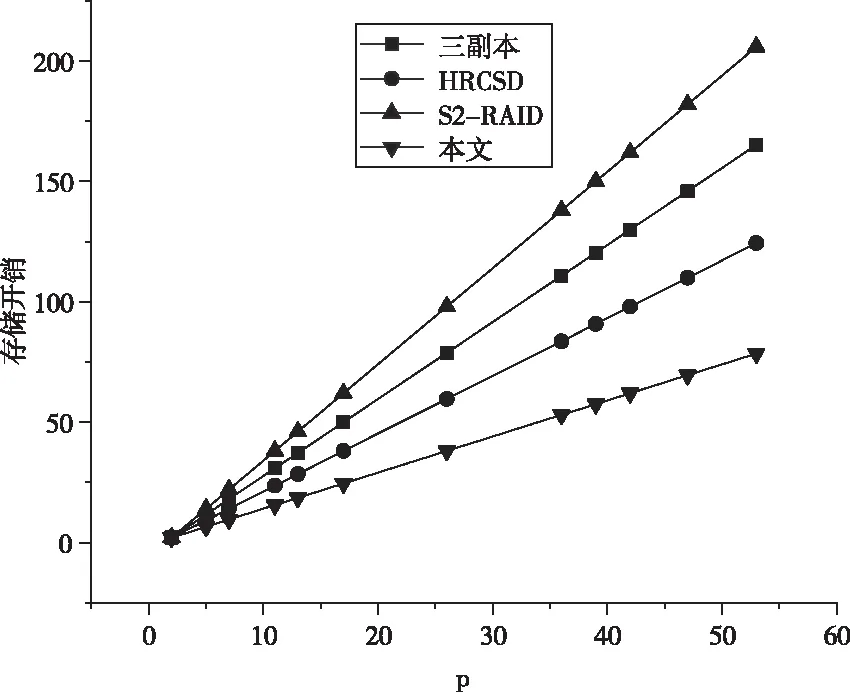
图3 存储数据开销对比
如图3所示,可以看出在对同类数据进行存储的过程中,本文提出的算法的存储开销相对较低,同时采用S2-RAID方法所占用的存储空间最大,另外两种方法分别处于两种方法的中间。所以采用本文提出的方法相对来说更好一些。
其次,在进行数据恢复过程中,数据恢复的效率是考核所有数据恢复算法重要的衡量指标。接下来通过不同的方法来对比数据恢复效率,恢复效率对比表格如表1所示。

表1 不同方法的数据恢复效率
如表1中的数据可以看,由于在进行建模的过程中引入了对应的决策树模型以及算法流程在基尼指数的介入,大大提高了数据修复的准确性。因此可以看出,在进行数据恢复的过程中,采用本文提出的数据恢复的方法数据恢复效率更高,这也就意味着在进行数据恢复的过程中恢复的数据精确度更高。
最后,分析采用不同方法进行数据恢复过程中修复时间变化。同样采用不同方法来对相同的存储数据量进行修复,修复时间曲线如图4所示。
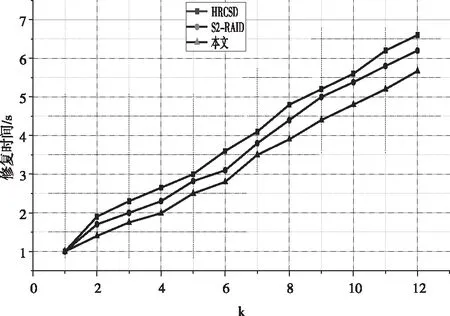
图4 不同方法下的数据修复时间
如图4所示,可以看出采用本文提出的方法在数据修复时所需要的修复时间相对较低,侧面反映出本文提出的方法可以有效缩短对应的数据修复时间。
4 结论
由于分布式数据存储系统作为经典数据容错技术,因此基于分布式存储数据纠删码技术研究一直是近些年数据修复过程中的研究热点。在进行数据备份与修复的过程中,纠删码技术以其数据存储过程中资源消耗低、可靠性高等优点在数据纠删存储领域得到了广泛应用。但是,随着应用数据的深入,以及大量数据在不断地更新产生,传统纠删码数据修复技术依然存在数据修复速度低、修复率低等缺点。因此,本文结合数据决策模型提出基于决策树模型的分布式数据纠删码修复算法,该算法通过引入决策树模型在数据决策上的优势,建立的基于决策树的分布式存储数据纠删码算法。最后,为了验证本文算法在存储效率,数据恢复效率以及对应的修复时间方面的优越性,本文给出了对应的数据仿真。通过对比仿真可以看出本文提出的方法在修复速度、数据修复率等方面有很好的提升。
