基于深度神经网络的无人机路径决策的研究
2022-07-20周思达唐嘉宁
周思达,邱 爽,唐嘉宁,郭 川
(电气信息工程学院,云南 昆明 650000)
1 引言
随着无人机技术进入民用市场,无人机被广泛应用于军用和民用领域,在地貌探索,搜索救援,应急监测等方面发挥着日益重要的作用。
环境感知是无人机自主导航的关键,为了安全稳定的执行飞行任务,无人机在运动过程中必须实时对周围障碍物做出反应。近几年,国内外的专家学者已对无人机的自主导航飞行开展的大量研究,这些研究可分为两个方面:一方面是无人机在运动的过程中实时检测周围环境,探测周围障碍物从而实现避障;另一方面是利用路径规划算法在已知环境障碍物的情况下规划路径[1,2]。
基于路径图、人工势场、单元分解的规划算法[2]是在已知环境障碍物的情况下的三种飞行航迹规划方法。其中基于路径图的方法是要根据一些给定的方法把可以通行的没有障碍物的路径转变为一条条有向线段的合集,然后再在这些合集里寻找更符合的路径。对于人工势场法,要假设吸引力和排斥力,吸引力引导无人机靠近目标,排斥力阻止无人机靠近障碍物。对于单元分解的规划算法,要将飞行空间划分成大小相同的单元格,再用适合的算法搜索单元格,最后选出符合飞行的单元格序列。然而这三种航迹规划方法必须一定要在已知环境障碍物的情况下进行。
对于无人机实时的飞行探索,主要是依靠各类探测传感器及交互应答协议对障碍物进行避障处理,传感器主要包括光电、电磁等常用的传感器。对于长期技术研究阶段则采用光电、激光和雷达技术来实现。如2016年,Barry领导的团队就利用立体激光扫描器来感知周围环境,从而实现了每小时30英里的高速避障飞行[3]。因而,飞行探索传感器的灵敏度和精确度将直接决定飞行任务的成败。
但不管是依靠哪种路径规划的算法,在山野小路,湖泊丛林这样复杂多变的非结构化环境以及较为封闭的室内场所中往往会因为信息量巨大而导致无人机的飞行判断出现错误[4]。因此,无人机在这样的环境中识别路径并进行路径决策更具挑战性。
最近几年,深度学习已成为各种计算机视觉任务的强大工具,它的优势之一在于它的通用性:从海量的信息中直接提取特征而不需要算法设计师进行特征的选择和设计。将深度学习应用到无人机的自主导航上,让其直接从海量的环境信息中提取特征,从而为无人机的自主导航探索提供更为充分的依据。
文献[5]利用深度学习从输入图像中提取每个像素的特征向量,利用支持向量机在线进行自监督学习,通过训练后的分类器进行道路/非道路分类。为无人机沿着道路避障飞行提供了一定的参考。
Laddha等[6]利用GPS和惯性测量单元对道路上可飞行路径进行自动标注,利用卷积神经网络来进行训练完成路径识别。但预处理手段极其复杂,无人机飞行性能往往由复杂的计算和大量的训练数据决定。苏黎世大学Scaramuzza等[7]首次将路径导航转化为神经网络的分类问题,根据识别到的路径位置来判断无人机的位置方向,研究者通过头戴三个不同方向的摄像头,在山野,湖泊,荒原各种不同的环境中行走,组成了数据集IDSIA.利用神经网络判断所处环境中路径的位置,判断无人机实时的飞行方向,从而完成无人机的自主飞行。这种方法是深度学习在无人机航迹规划上的一次较为成功的尝试,识别成功率甚至能接近90%。
以往的无人机航迹规划方面的研究主要集中在传统的路径规划算法上,基于深度学习的无人机路径识别还较为少见,对于复杂环境下无人机的飞行探索,使用深度学习的方法利用端对端的的神经网络能直接对无人机的飞行路径进行识别,从而控制无人机的飞行。和传统的方法相比较,基于深度学习的方法具有鲁棒性高,适用范围广的特点。但由于现实环境多种多样,如在森林或是城市飞行时,参考物和特征(线、面、体)极不明确,环境是显著非结构化的,在这样的环境中,无人机的判断能力会显著下降,从而大大降低无人机飞行的安全性和稳定性。
本文搭建了一个深度残差网络模型,首先将相机获取的普通彩色RGB图作为输入,通过训练学习,得到能预测无人机三种飞行方向(左/中/右)的训练模型,再利用小觅深度摄像头D1000-IR-120采集不同建筑环境内的深度图片,利用神经网络迁移学习的原理,将包含深度信息的数据进行训练学习,大大提高了在各种不同环境下的飞行准确率。由于数据集包含了大量室外非结构化的环境,也包含了室内结构化的建筑场景,扩展了无人机路径识别飞行的适用范围,与传统卷积神经网络单单使用RGB图进行训练的方法相比,本文提出的方法提高了无人机飞行探索的安全性和稳定性。
2 基于深度残差网络的航迹决策方法
AlexNet、VGG、GoogLeNet等网络模型的出现将神经网络的发展带入了几十层的阶段,研究人员发现层数越深的网络泛化能力会越强[8]。但网络层数越来越深又会因为梯度弥散和梯度爆炸现象造成网络难以训练。2015年,微软亚洲研究院何凯明等人发表了基于Skip Connection 的深度残差网络(Residual Neural Network,简称ResNet)算法[9],其原理是在l输入和输出之间添加一条直接连接的Skip Connection可以让神经网络具有回退的能力,通过这种方式可以选择是否经过这层卷积层还是跳过卷积层选择Skip Connection,亦或是结合卷积层和Skip Connection的输出。
2.1 深度残差网络特点分析
本文采用残差结构的网络来解决网络退化的问题。假设将模块的的输入设为X,将在卷积层的映射设为F(X),模块的输出为H(X),因此模块的输出则可以表示为H(X)=F(X)+X。残差网络的越层连接将输入的信息跨越中间层传输到了后层,这样就保证了信息的完整性。残差结构有两层,输入X通过残差映射后输入到下一层,表达式如下
yl=F(xl,{Wl})+h(xl)
xl+1=f(yl)
(1)
其中,F(x)为残差函数,xl和xl+1分别为第l个残差单元的输入与输出,恒等映射的表达式为h(xl)=xl,ReLU激活函数为f(x)。从上式可推出从浅层l到深层L的学习特征为
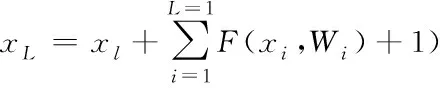
(2)
那么反向传播的梯度通过链式法则就可以求出

(3)
其中,∂loss/∂xl是损失函数到L层的梯度,括号中的前一项表示梯度经过了Wi层,1表示无损信息能够通过越层连接,所以即使残差的梯度较小,+1也能确保梯度不会消失。
2.2 RGB数据集的采集方法
本文利用的部分RGB数据是苏黎世大学Scaramuzza教授的研究组发布的IDSIA数据集。数据集是由头戴三个摄像头的徒步者沿着室外不同环境的路径迅速行走而采集。头戴的三个摄像头平行排列,中间的摄像头指向正前方,左边和右边的摄像头分别朝向道路两边。IDSIA数据集就由三个摄像头采集的图像序列组成。三个摄像头采集的数据就分成了三组标签,沿着道路左边边缘的数据由靠左的相机采集,则标签定位左转。中间摄像头采集的数据标签为直行,右边摄像头采集的数据标签为左转。

图1 F-RSENET网络架构
2.3 深度残差神经网络的结构
文章采用了深度残差神经网络来对图像进行分类处理,其主要架构基于resnet-18[10].为了提高网络训练的收敛速度,将每个残差块后批处理化的过程取消。于是其具体结构如图1所示。首先,将IDSIA数据集中的RGB图像裁剪成320×180大小的图片作为网络的输入。其中,网络的残差模块一共有四个,每一个残差模块包含两个基础块,每个基础块实现两个卷积层,因此卷积层的数量是4×2×2=16。这样再加上初始的卷积层和最后的全连接层,一共是18层的网络。其中第一个卷积核是7×7外,其余卷积核的大小都是3×3.部分层采用了步长为2的下采样,其余步长则都为1。池化层都采用平均池化的方法,最后输出三类结果,表示的是左转,直行,右转三个无人机飞行方向的概率。
3 深度图的制作及应用
3.1 深度图的原理
采用普通RGB彩色图进行训练,在道路边缘模糊或是周边较为空旷的场景下,网络的误判概率很高。这是由于RGB图在某些场景受环境光照和阴影的影响比较大,从而导致图像纹理信息不明显,网络无法通过图像特征将其区分开造成的[11]。如图2表示的就是网络判断错误的RGB图。基于这一事实,本文考虑到若是能获取到图像的深度信息,这一问题就迎刃而解了。

图2 误判的某些RGB图
传统的机器视觉是现实的三维环境投影成二维图像,再建立图像信息与环境特征的数学模型。RGB彩色图就是通过这一方法获得的,因而损失了深度等信息。与之相反,深度图像与环境光照和阴影没有关系,深度图像的每一个像素点都能够清楚的表达环境的表面几何形状。与RGB彩色图相比,深度图像处理对环境的几何形状和物理特征都没有任何限制,它能直接利用环境中的三维信息,从而能大大简化对三维环境的识别和定位问题[12]。
本文采用双目立体视觉理论来获取深度图,双目立体视觉理论的基础是人类对视觉系统的研究,通过对双目立体图像的处理,获取场景的三维信息。在双目立体视觉系统中,深度信息是分两步进行获得的:首先,在双目立体图像之间建立点与点之间的关系,求出对应点的视差图像,然后再根据对应点的视差计算出相应像素点的深度[13]。
作为基于视觉识别的3D传感器,本文采用了小觅双目摄像头作为深度信息的采集工具。双目摄像头对同一场景环境下的图像进行拍摄,运用立体匹配算法获取视差图,视差图表示了空间物体在水平方向上左视图与右视图的像素差值。那么,可通过公式推导出深度z与视差的关系为

(4)
其中,b为双目相机的基准线,f为相机的焦距(相机的焦距一般有fx和fy,但因为视差只在x方向,所以直接取fx即可),d的单位是像素pixel,XR和XT的单位是毫米。
3.2 深度图像数据集的采集与制作
本文采用的深度图片数据集的采集方法和IDSIA数据集的采集方法类似,由于没有三对双目摄像头,数据集的采集分为三个步骤依次完成。首先将双目摄像头指向正前方,与徒步者视角一致,沿着道路迅速行走并保持摄像头尽量稳定。然后将双目摄像头朝左偏移固定的角度,沿着同样的道路行走。最后,将双目摄像头朝右偏移固定角度,沿着道路迅速行走。这样,就用同一组双目摄像机采集了三组不同的图像序列。再经过双目视觉理论的处理之后,就得到了三组包含深度信息的深度图。其中指向正前方采集的图像标签为直行,朝左偏移的双目摄像头采集的图像标签为右转,朝右偏移的双目摄像头采集的图像标签则为左转。下图3是为进行可视化将采集到的深度图转换成伪彩色图的效果。

图3 深度图像分类标签
4 实验结果与分析
4.1 数据集处理
本文实验一共采用了两个数据集,首先采用的是室外数据集IDSIA对网络进行训练,IDSIA数据集包含多种多样的室外道路类型,不管是宽阔的森林平原还是狭窄的山谷小路。拍摄的环境有雨天,阴天甚至下雪。其次本文也采用了自己利用双目摄像头采集与制作的深度图像数据集,该数据集同样包含三组标签(左转,右转和直行),采集的数据集主要是校园室内,走廊等无人机能自由飞行的一些场景。这样无人机的室内室外环境都有所涉及,大大增强了网络预测的泛化能力。本文也采用了多种经典方法对数据集进行扩充增强,如随机翻转和旋转等。本文使用的软件平台为深度学习框架tensorflow2.0.
4.2 实验结果与分析
表1是无人机在IDSIA数据集和深度图像数据集下卷积神经网络CNN和本文采用的深度残差网络F-resnet的飞行识别准确率。从表中可以看出,使用深度残差网络模型要比普通网络模型的效果要好,传统卷积网络随着层数加深,学习效率反倒会变得很低,而残差网络内部残差块使用的跳跃连接的方式,大大缓解了普通卷积网络随着深度增加出现的梯度消失的问题,从而提升无人机的识别准确率。另外,相较于只利用RGB图训练或是只利用深度图像这种单一图像进行训练的方法,使用包含有深度信息的深度图片进行迁移学习能让无人机的判断准确度有所提升。可以看出的是,在道路边缘比较模糊,场景的环境较为空旷且光线过暗或过明时,普通RGB图的纹理特征和颜色特征很不明显,神经网络很难提取到特征信息。因此很难判断出准确的路径位置。如下图的某些场景。而深度图像的优势在于它的每个像素点都反映了场景中的物体到搭载在无人机上摄像头的实际距离。也就是说,神经网络获取到的图片实际上是包含了深度距离信息的矩阵,从而有效提高了路径位置的判断准确率。
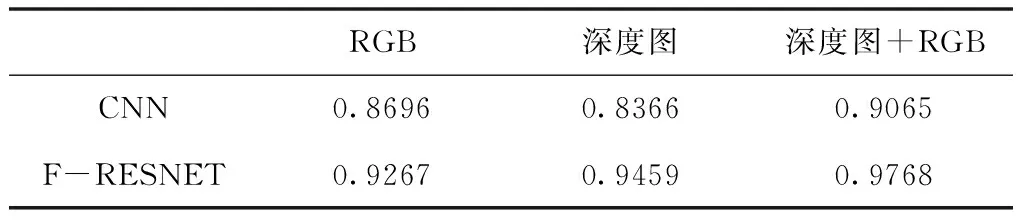
表1 无人机在IDSIA数据集和深度图像数据集下CNN和F-resnet飞行识别准确率
5 总结
本文提出了一种深度残差学习模型F-RESNET,使无人机能在室内室外的某一路径飞行时对飞行方向具有一定的判断能力。使用残差网络构建模型,利用越层连接的原理实现了对更深层次网络的训练,不仅提升网络的识别准确率,也提高了网络的收敛速度。其次,再利用RGB图获取颜色信息和纹理信息的同时,使用双目立体视觉理论获取了深度图像数据集,给网络训练增加了距离信息。最后的实验也表明,本文提出的网络模型提高了普通卷积模型的识别准确率,在无人机自主航迹规划方面具有一定的实际应用价值。
