引入改进蝠鲼觅食优化算法的水下无人航行器三维路径规划
2022-07-19黄鹤李潇磊杨澜王会峰茹锋
黄鹤,李潇磊,杨澜,王会峰,茹锋
(1.长安大学电子与控制工程学院,710064,西安;2.长安大学西安市智慧高速公路信息融合与控制重点实验室,710064,西安;3.长安大学信息工程学院,710064,西安)
水下无人航行器(unmanned underwater vehicle,UUV)可用于水下侦查敌情、海域巡逻、反击敌方潜艇等[1-2]。在UUV的研究中,路径规划问题非常重要,其目的是完成从航程起点到终点的规划,躲避障碍物和威胁物,同时尽量选择行驶路径短的路线。近年来关于UUV的路径规划问题,各国学者做了大量的研究工作,提出了很多UUV路径规划的算法,经典算法有人工势场法[3]、A*算法[4]和D*算法[5]等。王健等[6]提出了一种基于混合势场法的UUV路径规化方法,用于UUV航向保持和避障,但是所设计的虚拟力比较难实现。相对于经典算法,智能算法收敛速度快,鲁棒性强,尤其采用群体智能优化算法求解UUV路径规划问题是目前的研究热点,常用的智能算法有粒子群算法[7]、遗传算法[8]、蚁群算法[9]、灰狼算法(grey wolf optimizer,GWO)[10]等。徐炜翔等[11]针对静态的地形和复杂环境下UUV的路径规划问题,提出了基于飞蛾扑火算法的UUV三维全局路径规划,但是搜索时间过长。张汝波等[12]针对水下可能存在不同等级的威胁源,提出了一种基于改进蚁群算法的UUV航路避障任务规划方法,但是搜索范围过大,搜索耗时较长。以上研究虽然能够实现UUV的路径规划,但是改进效果有待于进一步提高。在三维UUV路径规划中,地形和威胁的信息量比较大,更使得群体智能优化算法寻求最优路径时复杂程度会呈现指数上升[13]。蝠鲼觅食优化算法(manta ray foraging optimization algorithm,MRFO)[14]是2020年提出的一种新型群体智能优化算法,该算法模仿蝠鲼在海洋中觅食的过程,针对蝠鲼的链式觅食、螺旋觅食以及翻滚觅食进行相应的数学建模,描述了蝠鲼个体位置更新方式,具有收敛速度快,寻优能力强等特点。MRFO算法因具有寻优能力强,收敛速度快等特点[15],在复杂环境下也可以保持良好的寻优能力,适用于三维UUV的路径规划,但是MRFO算法有时会陷入局部最优,需要进一步改进。因此,本文结合蝠鲼的海洋生物特性,提出了一种改进的蝠鲼觅食优化算法,并应用于UUV三维路径规划中,可以避免陷入局部最优,提高UUV寻优精度,有效避开水下威胁物和障碍物,快速获得最优路径。
1 水下无人航行器三维路径规划环境建模
1.1 地形约束
水下海拔为负数,但是为了计算方便,这里仿照同类研究文献[16],将水下海拔都以海底为0开始按正数赋值,根据水下海拔的不同,可以将水下地形分为多种地区。这里面影响比较大的因素是山峰。首先,水下山峰建模如下式
(1)
式中:(X,Y)为水底平面以上山峰对应的坐标;(X0,Y0)为山峰中心点对应的坐标;h为高度参数;m1和m2为山峰的陡峭程度。规划的路径用航迹点来表示。第i个航迹点对应的地形威胁代价表示为
(2)
式中:Kz为地形威胁系数;hi为第i个航迹点对应的海拔高度;Zi为第i个航迹点距离海底的垂直高度。此外,UUV路径规划需考虑下潜的深度,下潜的深度必须处于最大和最小下潜深度之间,即为深度约束,第i个航迹点对应的深度威胁代价函数表示为
(3)
式中:hmin和hmax分别表示UUV相对海底的最小高度和最大高度;Kw表示深度威胁系数。
1.2 威胁模型约束
(1)声呐威胁。声呐通过声波探测敌方目标的距离、速度和相对位置等信息,UUV路径规划过程中必须避开其探测范围。声呐威胁区近似由一个椭球形表示,在三维平面上表示的范围如下
Sth=
(4)
式中:Sth表示声呐威胁区;X、Y、Z分别指三维平面的X轴、Y轴和Z轴;X1、Y1、Z1为对应的球心坐标;a、b分别为椭球体的长半径和短半径;R为相应的球体的半径。
(2)洋流威胁。UUV在水下航行时,要尽量避免航线经过强洋流地带。本文强洋流地带可以用下式表示
So=
(5)
式中:So表示洋流威胁区。
(3)水雷威胁。敌方水雷的威胁范围内被称作禁游区,可以近似为一个半球体,表示为
PM=PvPk/v
(6)
(7)
式中:Pk/v表示UUV在禁游区半径内被摧毁的概率,是常数;K0为比例系数;RS为水雷威胁中心与UUV之间的斜距;θ为视线俯视角。则
PM=K0sinθ·Pk/v
(8)
在三维模型创建的过程中,威胁源半径比较大,因此可以将所有的威胁源等效为圆柱地形处理。威胁代价表示如下
(9)
式中:KTj为威胁源j的威胁系数;rij为第i个航迹点到威胁源j的直线距离;RTj表示的是威胁源的威胁半径。
1.3 UUV自身物理约束
UUV航行过程中会受到自身转弯角α0和爬升角β0的约束。同时,还有自身的燃油代价,可以用路程来表示。设最大转弯角为αmax,最大爬升角为βmax。转弯角、爬升角物理约束分别表示如下
(10)
(11)
式中:Kh和Kv分别为转弯角和爬升角威胁系数;Ja和Jv为第i个航迹点对应α0和β0的代价函数。综合各代价函数,可得出第i个航迹点的UUV物理约束代价函数为
fJi=Ja+Jv+JLi
(12)
路程代价物理约束为
(13)
1.4 航迹代价函数
将所有地形约束、深度代价、威胁模型约束以及UUV的自身物理约束加权综合起来,构成最终UUV的代价函数,如下式
(14)
式中:F(R)就是整条航迹的代价;ω1、ω2、ω3、ω4为各代价的权重。
2 改进的蝠鲼觅食算法
2.1 经典MRFO算法
2.1.1 链式觅食[17]
链式觅食更新方式的数学模型如下
(15)
(16)

2.1.2 螺旋觅食[18]
螺旋觅食更新方式的数学模型如下。
(1)当t/T>r时,蝠鲼螺旋觅食方程为
(17)
(18)
式中:T为总迭代次数;t为当前迭代次数;r和r1都表示在[0,1]上的随机数。
(2)当t/T≤r时,蝠鲼螺旋觅食方程为
(19)
(20)
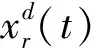
2.1.3 翻滚觅食
翻滚觅食时,蝠鲼个体会以当前最优解的位置作为翻滚的支点,数学表达式如下
i=1,2,…,N
(21)
S=2
(22)
式中:r2和r3都是在[0,1]上的随机数;S为翻滚因子;N为个体的数量。
2.2 改进的蝠鲼觅食优化算法
2.2.1 局部反向学习
反向学习是一种群体智能的改进策略,随机初始化所生成的种群可能位置不够好,不利于全局搜索。因此,初始化过程中需加入反向解搜索[19],增加种群的多样性,有利于寻找全局最优解。

(23)
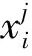
在实际搜索过程中,如果对所有初始化的种群都生成其反向解,会增加迭代搜索的时间,因此在经典反向学习的基础上,本文设计了一种局部反向学习方法,只对初始化位置较差的一半种群进行反向学习,其余的保持不变。
局部反向学习策略的具体公式为
(24)
(25)
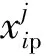
局部反向学习策略的具体步骤为:
(2)计算所生成种群的适应度;
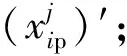
这样相比于经典的反向学习,提出的局部反向学习不仅能够获得位置较优的种群,提高全局搜索能力。同时,只对适应度较差的一半种群进行反向求解,使得搜索时间更短,提高了寻优速度。
2.2.2 自适应翻滚
MRFO算法中翻滚觅食是一个比较频繁的动作,可以提高蝠鲼的觅食效率。在其数学模型中有一个翻滚因子S,决定了翻滚的距离。在传统的MRFO算法中S一般取2,但是因为翻滚因子S在蝠鲼的迭代更新过程中不会发生变化,所以搜索过程中易陷入局部最优。因此,本文提出一种新的自适应翻滚方式,根据每次迭代后种群的适应度不同,在翻滚因子中加入一个变化的翻滚系数ρ,翻滚系数ρ随着蝠鲼种群位置的适应度变化而变化,使得翻滚因子S能够随着种群适应度的变化而做出动态调整,有效地扩大了搜索范围,有利于跳出局部最优。加入ρ后蝠鲼种群的变化方式变得更灵活,有利于寻求全局最优,提升寻优精度。翻滚系数的更新方式如下式
(26)
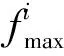
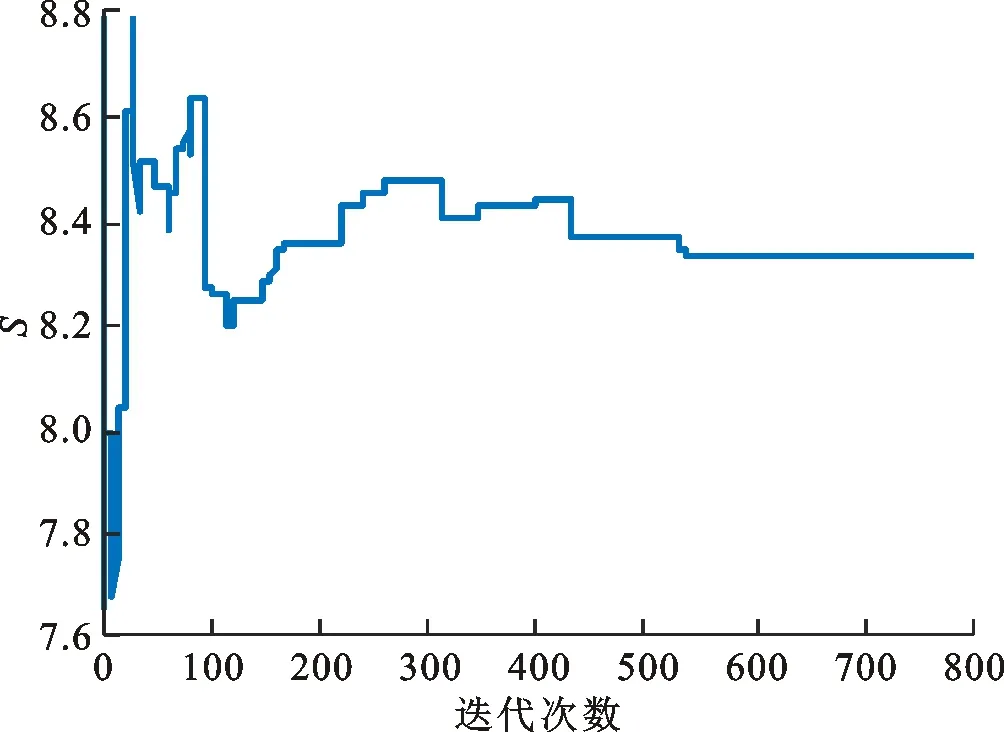
图1 翻滚因子S的变化
从图1可以看出,翻滚因子S随着迭代的进行不断变化,在迭代前期、中期,因种群个体适应度与最优种群适应度差异较大,赋予翻滚系数ρ一个变化较大的值,导致翻滚因子S波动剧烈,扩大了蝠鲼种群的翻滚幅度,可以使蝠鲼种群在下一次迭代过程中位置多样性增强,有利于寻找全局最优。随着迭代的进行,蝠鲼种群逐渐搜索到最优解,这样适应度的变化幅度也相应减小,S也逐渐趋于稳定,蝠鲼聚集在最优解周围增强了局部的搜索能力。加入翻滚系数ρ后蝠鲼翻滚觅食的更新方式转换为
i=1,2,…,N
(27)
2.2.3 融合莱维飞行-柯西变异策略
本文提出一种融合莱维飞行-柯西变异的策略,首先在蝠鲼的螺旋觅食中加入莱维飞行策略,增加了种群位置的多样性,扩大了搜索范围。莱维飞行是一种随机游走策略[20-21],结合长距离游走和短距离游走。执行过程中,通过长距离游走扩大搜索范围,跳出局部最优;通过短距离搜索加快收敛速度。这样,在蝠鲼的螺旋觅食中加入莱维飞行,可以扩大搜索范围,同时也加快了收敛速度。相较于其他的改进方法,莱维飞行的随机游走性更强[22]。同时在翻滚觅食后,对当前蝠鲼的最优位置进行柯西变异,柯西函数因为其分布范围广,可以进一步提升蝠鲼的全局搜索能力。莱维飞行的具体描述如下
(28)
式中:δ=1.5;μ和ν则服从正态分布
(29)
(30)
(31)
式中:Γ(·)为伽马函数;σν=1。
增加莱维飞行后,式(17)和(19)可转换为
(32)
(33)
采用的柯西分布[23]和变异函数如下式
(34)
xnewbest=xbest+Cauchy(x0)xbest
(35)
式中:xnewbest为更新后蝠鲼的位置;xbest为更新前蝠鲼的位置;柯西函数中x0取值为0~1的随机数。柯西分布函数的中间峰值比较小而两边分布的范围比较广,可以使蝠鲼在当前范围产生较大的扰动,帮助跳出局部最优。
2.2.4 本文算法流程
本文算法流程如图2所示。
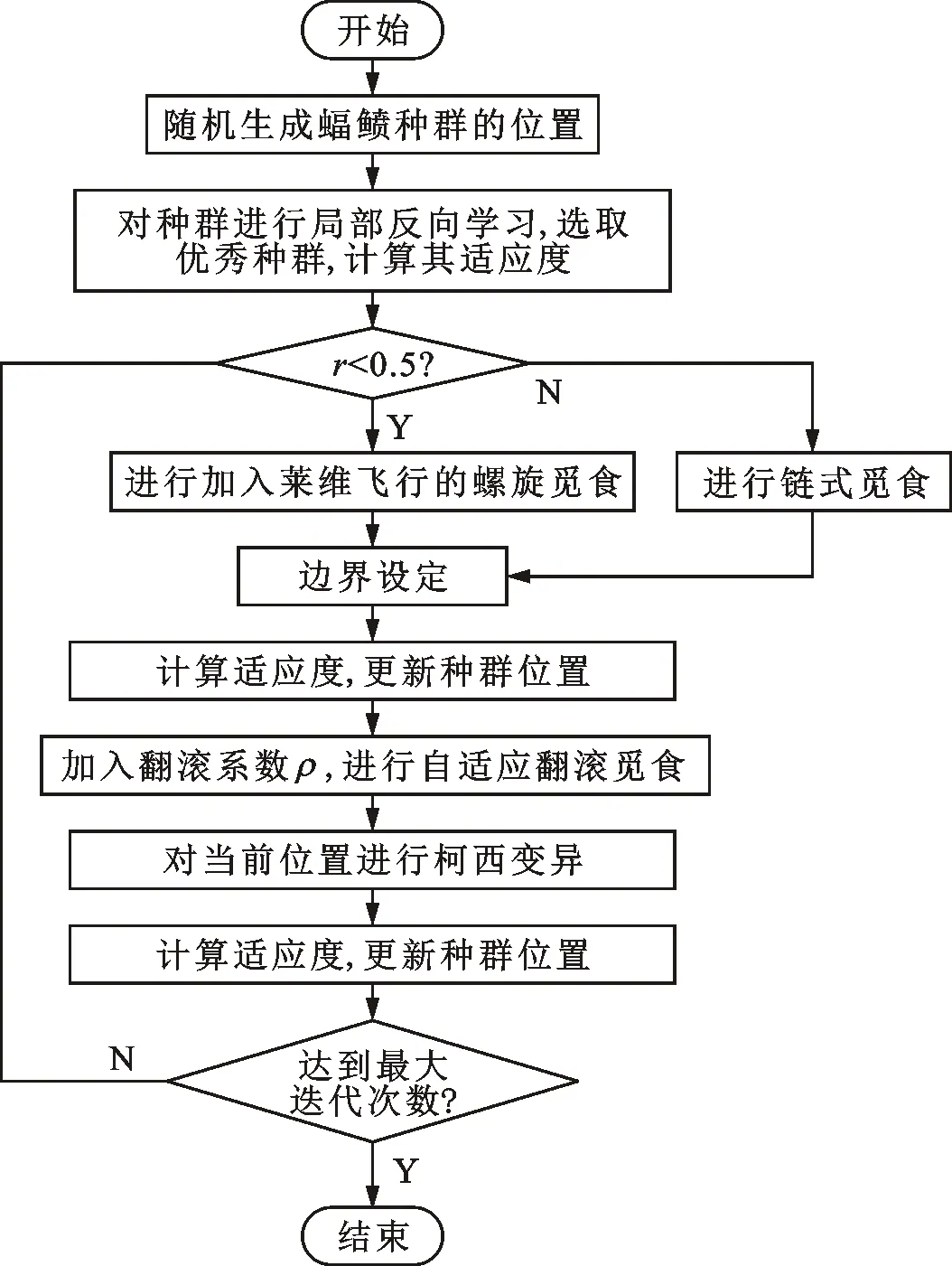
图2 本文算法流程图
2.3 性能仿真实验
2.3.1 测试函数
根据路径规划需要,利用测试函数对本文算法的性能进行分析比较。其中,单峰值函数可以测试算法的收敛精度,多峰值函数可以测试算法的寻优能力。分别选取3个单峰值函数和3个多峰值函数进行测试。
(1)Schwefel 1.2函数表达式为
(36)
式中:n=30;xj∈[-100,100];全局最小值为0。
(2)Schwefel 2.21函数表达式为
f(x)=maxi{|xi|,1≤i≤n}
(37)
式中:n=30;xi∈[-100,100];全局最小值为0。
(3)Step函数表达式为
(38)
式中:n=30;xi∈[-100,100];全局最小值为0。
(4)Ackley函数表达式为
(39)
式中:n=30;xi∈[-32,32];全局最小值为0。
(5)Griewank函数表达式为
f(x)=
(40)
式中:n=30;xi∈[-600,600];全局最小值为0。
(6)Shekel 10函数表达式为
(41)
式中:xki为矩阵Xk中第i行的向量;aki为矩阵Ak中第i行的向量;cki为向量Ck的第i个元素;矩阵Xk和矩阵Ak均为10行4列的矩阵;xki∈[0,10];aki∈[0,10];cki∈[0,1];该函数的全局最小值为-10.53。
2.3.2 实验验证
采用上述测试函数评估MRFO算法、GWO算法[24]及本文算法的寻优性能。其中,种群规模为100,迭代次数为800。图3为各函数的三维参数空间以及各算法在不同测试函数上的适应度曲线,表1为经过30次测试的适应度均值和最优值。

(a)Schwefel 1.2函数
由图3和表1可知,在Schwefel 1.2函数和Schwefel 2.21函数中,MRFO算法的收敛精度不如GWO算法,但是本文算法收敛精度却是最好的,强于GWO算法。在Step函数中MRFO算法的收敛精度优于GWO算法,本文算法在MRFO算法基础上有了一定提升。在Ackley函数中,本文算法寻优能力和速度都优于GWO和MRFO算法。说明本文算法可以有效地跳出局部最优,寻找全局最优。在Griewank函数中,GWO和本文算法寻优能力大致相同,但是寻优速度不如本文算法。在Griewank函数中,GWO算法的寻优能力和寻优速度都不如MRFO算法,本文算法最高。总体来说改进后的本文算法可以提高MRFO算法的寻优精度、寻优能力以及寻优的速度,有利于跳出局部最优。
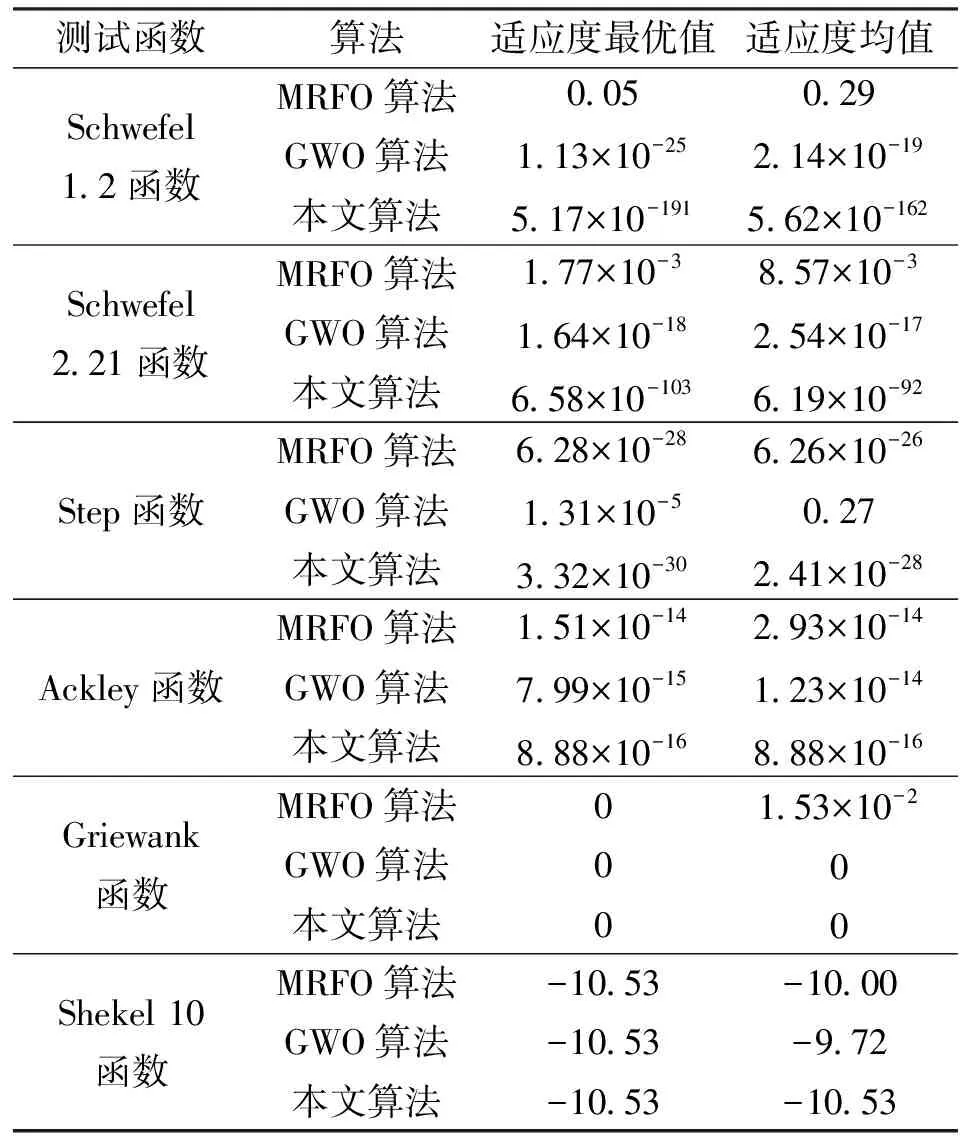
表1 3种算法在测试函数上的实验对比
3 引入改进蝠鲼觅食优化算法的UUV三维路径规划

航迹点数n对于UUV的路径规划很重要,相关研究表明,路径的精度随着n的增加变得更精确,但是如果n的数量过多,不仅会提高计算复杂度,还影响路径优化的效率[25]。本文设置了航迹点数分别为5、10、15、20,结合本文提出的改进蝠鲼觅食优化算法对路径进行预先规划,以确定合适的航迹点数。图4为不同航迹点下利用改进蝠鲼觅食优化算法所规划的路径。
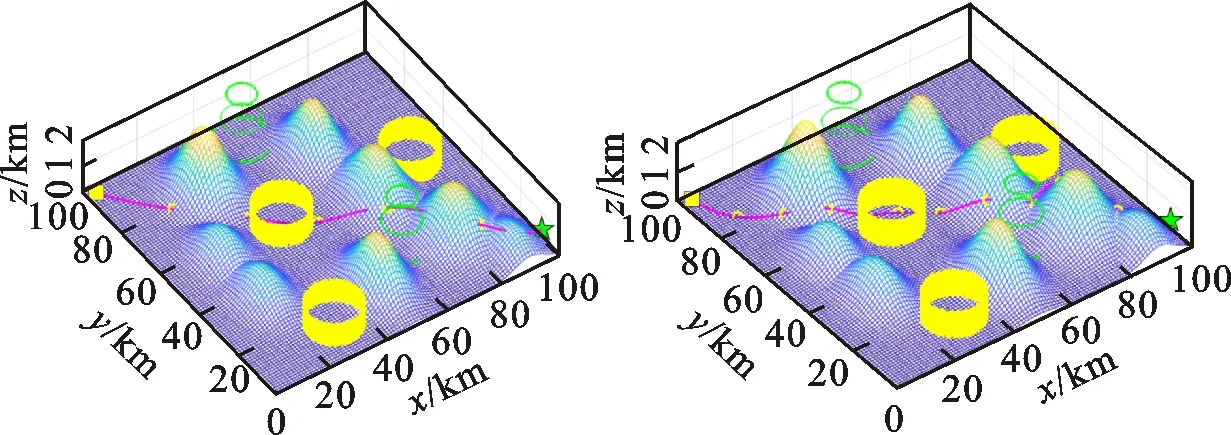
(a)航迹点为5 (b)航迹点为10
从图4中可以看出,当航迹点为5时,规划路径不能有效规避水下山脉等障碍物,与理想路径有较大差距。当航迹点为10时,比航迹点为5时规划的路径避障能力更强,但是精度仍然不够,不能规避所有障碍物。航迹点为15时,规划的路径准确,可以较好地实现水下避障,寻找较短的路径,实现较理想的路径规划。航迹点为20时,规划路径效果相比于航迹点为15时规划的路径并没有明显的提升,但是耗时增加很多,因此综合比较可以看出,选择航迹点为15、可以在耗时较少的情况下,规划出精准的路径。
4 路径规划仿真实验及分析
仿真环境中采用CPU为Intel Core i7-10750H CPU 2.60 GHz、内存为16 GB的计算机,操作系统为Windows10,编译软件为Matlab R2018b。为了测试本文算法在UUV路径规划中的效果,采用两种不同的地形。地形1中地形区域大小为100 km×100 km,测试中UUV距离海底的最大高度为4 km。UUV的起始点与终止点分别为(1,3,0.5) km及(99,98,0.5) km,敌方水雷距离中心为(20,13.5,0) km、(85,60,0) km、(40,59,0) km,分布在半径为9 km的区域。声呐距离中心为(65,30,0) km、(50,90,0) km,作用半径为9 km。路径规划过程中的主要参数如表2所示。地形1中UUV路径轨迹、代价曲线分别如图5和图6所示,UUV的航程和最优代价如表3所示。地形2中区域大小和地形1相同,UUV的起始点为(1,93,0.5) km,终止点为(99,8,0.5) km。水下水雷的位置为(30,13.5,0) km、(85,55,0) km、(40,55,0) km。声呐的位置为(65,30,0) km、(50,90,0) km。用正方形、星号和圆圈分别表示MRFO、GWO和本文算法求得3条UUV路径的航迹点。在实验模拟中各算法种群数设为100,最大迭代次数为800次。地形2中UUV的路径轨迹、代价曲线分别如图7和图8所示,UUV的航程和最优代价如表4所示。
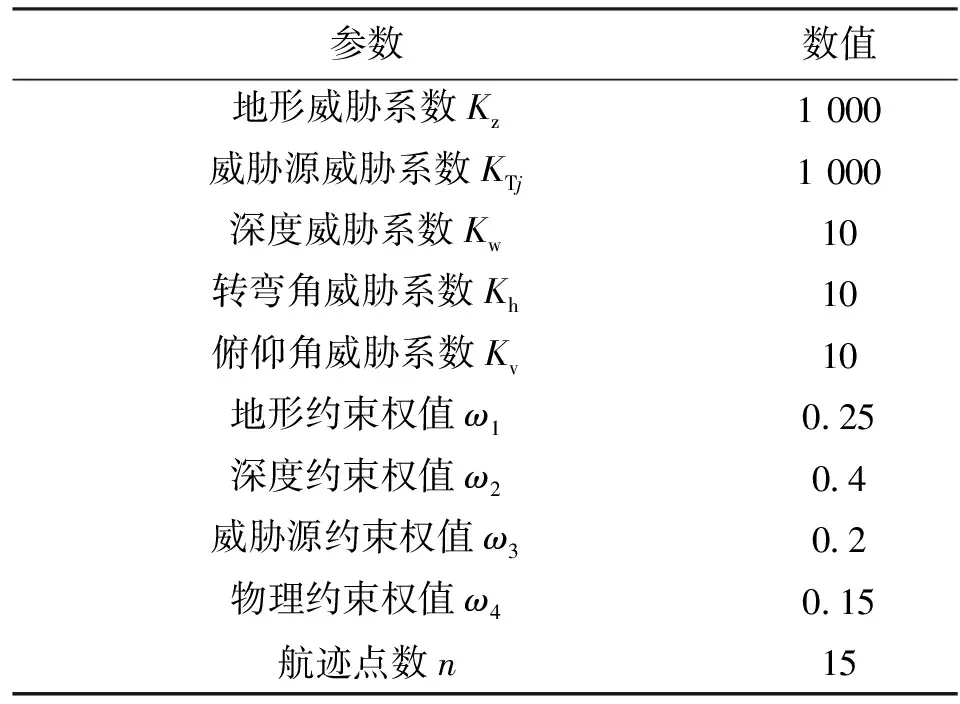
表2 路径规划过程中的主要参数
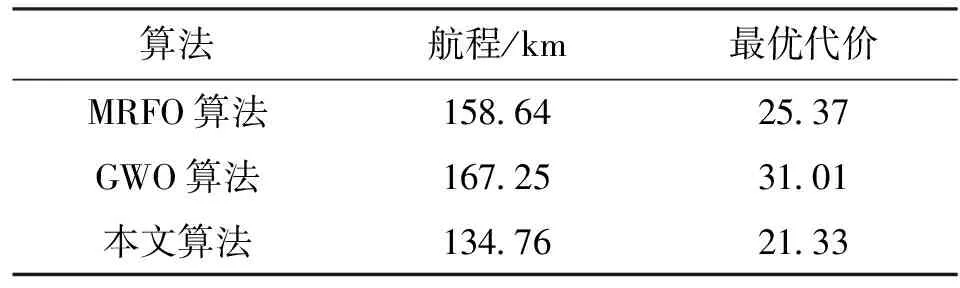
表3 地形1中UUV的航程及最优代价
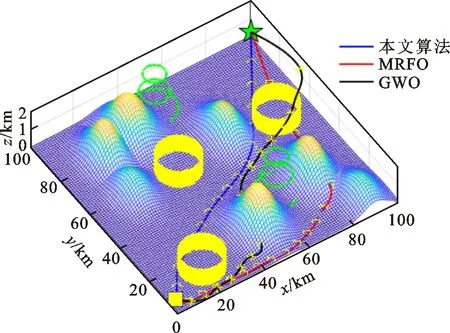
图5 地形1中UUV的路径轨迹

图6 地形1中最优路线代价变化
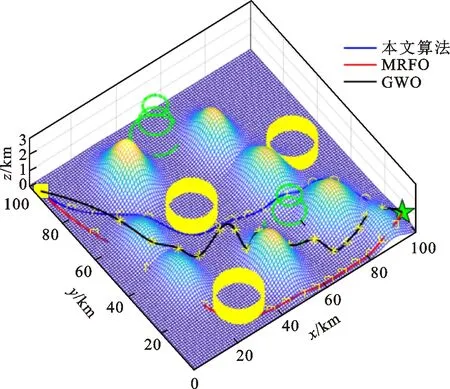
图7 地形2中UUV的路径轨迹
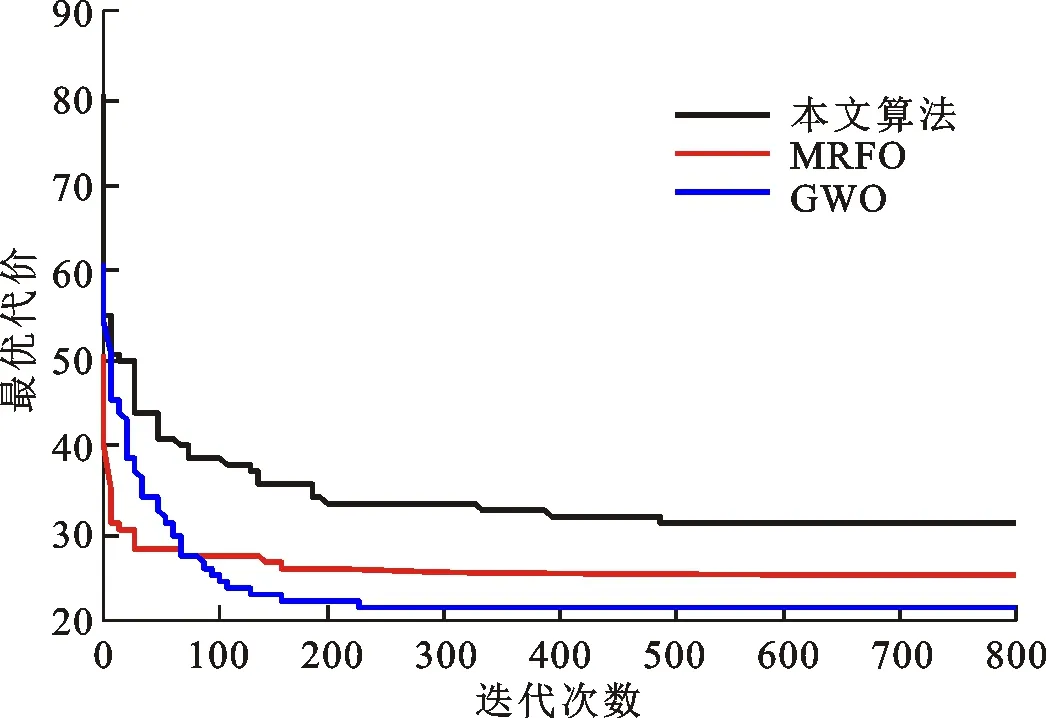
图8 地形2中最优路线代价变化

表4 地形2中UUV的航程及最优代价
在图5和图7中,两种地形中各有相应的威胁源和障碍物。根据航迹代价函数式(14)可知,UUV路径规划时,需要对各地形及水雷、洋流等威胁源同步规避,而最终路径取决于航迹代价函数及优化算法的寻优能力。如果优化算法寻优能力较弱,路径点易陷入局部最优,导致UUV进入威胁区或者与障碍物发生碰撞。从图5可以看出,地形1中GWO算法的规划路径会与水下的山脉相撞;MRFO算法的规划路径在迭代初期可以绕过山脉,但是迭代过程中无法跳过威胁区寻到一条更优的路径,而且后续路径还是会与山脉相撞,这是因为MRFO算法寻优能力不足所导致的。本文算法的路径可以有效地避开水下声呐、水雷等威胁区域,同时也能避开水下山脉等障碍物,主要原因是本文算法的寻优能力更强。相对于GWO和MRFO算法,本文算法规划的路线最优。由表3可以看出,GWO算法的航程最长,代价最大,MRFO算法相对有所减小,而本文算法的航程和代价最小。相对于GWO和MRFO算法,本文算法航程分别减少了32.49 km和23.88 km,代价损失分别减小了9.68和4.04。由图7可知,UUV按照GWO和MRFO算法在地形2中规划的路径会与水下山脉相撞,同时不能规避声呐和水雷威胁,而采用本文算法所规划的路径则可以有效规避障碍物和水下威胁,不会与山脉等相撞。由表4可以看出,地形2中本文算法的航程最短,相对于GWO和MRFO算法所规划的航程分别减少了20.83 km和29.95 km,代价损失分别减小了10.14和3.18。同时,由图6和图8还可以看出,GWO和MRFO算法收敛过快,易陷入局部最优,本文算法则可以有效地跳出局部最优,寻优能力更强。这是由于本文算法采用自适应翻滚和莱维飞行-柯西变异策略,面对复杂地形时各路径点寻优能力较强,在威胁源中或者发生碰撞前,可迅速规避并寻得最优路径。
5 结 论
针对UUV的路径规划问题,构建了相关的水下地形、威胁以及自身约束组成的三维模型;提出了一种改进的蝠鲼觅食优化算法,解决了MRFO算法容易陷入局部最优,收敛精度低的问题;将改进的蝠鲼觅食优化算法应用到UUV三维路径规划中,可以有效地减小UUV路径规划的航程和代价,躲避水下障碍物和威胁,选择最优路径。
