基于生成对抗网络的字体生成数据集差异性研究
2022-07-17王江江战国栋
李 昕,王江江 ,战国栋
(大连民族大学 a.计算机科学与工程学院;b.设计学院;c.大连市汉字计算机字库设计技术创新中心,辽宁 大连 116605)
文字是人们表达信息最直接的元素,也是交流沟通的重要工具。文字的出现对文明的发展提供了极大的帮助。与其它西方文字相比,汉字是地球上使用人数最多的一种文字,更是中华文化的载体。汉字是平面型方块体文字,符号繁多、结构复杂。每个字的造型、图形符号既是传达文字含义,也是一种特定的情感表达。
1 研究背景
然而,字体设计是一项消耗大量人力的工作。设计者可借助相关软件进行字体风格设计,但因其使用的处理方法都是将每个字符视为许多部首和笔画的组合,先通过几何建模再辅之以人工干预来完成,所以设计过程仍面临着艰巨的工作,需耗费大量的时间和精力[1]。随着人工智能的发展,人们开始探讨更有效的中文字体风格设计方法,以人工设计的少部分目标字体为基准,通过相关算法将其余字符直接转换成与目标字体相同风格的字体。这将极大地减少设计师的设计周期,使得创建个性化字体成为可能。
随着深度学习技术在图像风格迁移领域的成功应用,基于深度神经网络的字体风格迁移方法逐渐引起人们的关注,相关的研究也取得了一定的进展。Lyu等人[2]以生成中国书法风格字体为背景,提出了一种基于深度神经网络(deep neural networks, DNN)的模型,该模型将字体风格迁移问题作为一个图像到图像的翻译问题,可以端到端的将标准汉字图像迁移成特定风格的书法图像。Chang等人[3]以中文字体在排版中的风格转换为背景,提出了一个基于深度学习(deep learning,DL)的模型。该模型由一个全卷积网络(fully convolutional networks,FCN)和一个对抗性网络(generative adversarial networks, GAN)构成,目的是在保留结构信息和细节真实的情况下,将标准的印刷体汉字转换成其他各种风格的汉字。Zhang等人[4]以自动绘制可读的草书字体为背景,提出了一个基于条件递归神经网络(convolutional recurrent neural network,CRNN)模型。该模型用字符嵌入与生成模型联合训练,能够正确地写入数千个不同的字符,并且保证了在生成不同笔记样式时具有多样性。Danyang Sun[5]等人采用基于可变自动编码器的字体生成模型,采用一种新的交叉对优化方法,来分离汉字特征中内容相关和风格相关成分,较大地改善了中文字体的生成效果,有效的实现了中文字体风格的迁移。虽然这些方法都能够生成与目标字体样式相同的字体图像,但所有方法都处于有监督学习中,需要大量的成对字符数据(字体成对数据集:参考字体+目标字体)如图1。

图1 字体成对数据集示例
然而传统的网络模型输入的参考字体与目标字体直接联系,二者的差异越大,训练所需时间越长,生成的效果越差。本文将从生成对抗网络模型字体生成过程中参考字体差异性对于生成字体的不同进行实验分析。为了能够得出参考字体的选取范围,本文对于不同的参考字体在zi2zi与DC-Font等模型中进行了对比实验,通过实验结果将给出选取参考字体的范围。除此之外,本文通过结构相似性度量指标为字体研究学者提供适用的参考字体SSIM值。
2 中文字体风格迁移方法
2.1 基于计算机图形学的字体生成方法
在汉字字库的计算机辅助设计方法研究中, 孙星明等人[6]利用设计的笔画替换原有笔画的方式构建新汉字字库. 杨建等[7]提出一种动态调节贝塞尔曲线的汉字风格字体方法. 徐颂华等[8]通过轮廓匹配算法找出两个字体中相同笔划轮廓特征点的对应关系实现字体风格迁移 Daniel G等[9]从字形与结构出发, 以组合字的形式自动生成新字体. 熊晶等人提出了基于特征点抽象的汉字描述方法和基于字形骨架的汉字生成方法. 由于不同字体在笔画和结构都存在一定差异, 因此骨架扩展和组合汉字笔画的方法都很难满足规范严格的字库行业的标准。
2.2 基于深度学习的字体生成方法
最近的研究已经将图像翻译方法用于字体生成。“zi2zi”[10]和“Rewrite”[11]在GAN的基础上实现了字体生成,具有数千个字符对,用于强监督学习。之后,基于zi2zi提出了一系列模型来提高生成质量。 PEGAN建立了一个多尺度图像金字塔,通过细化连接传递信息。HAN通过设计分层损失和跳过连接来改进 zi2zi。 AEGG添加了一个额外的网络来改进训练过程。DC-Font引入了风格分类器以获得更好的风格表示。
然而,上述所有方法都处于监督学习中,需要大量的成对数据。在字体数据集较大的情况下,这种一对一的字体设计需要大量的时间成本,特别是一些结构复杂、笔画繁多的字体,设计起来更是耗时耗力。
2.3 本文实验网络模型
基于深度神经网络的字体风格迁移方法将字体生成任务看作是图像到图像的风格转换问题,通过字体风格转换器生成新款字体。风格转换器通过设计师提供的少量字形样本训练,就能自动学习分析该字体的笔画风格及间架结构间规则,然后再根据学习到的风格转换规则转换生成样本集中未出现过的文字字型。
字体风格转换器由两部分构成,第一部分为Encoder Network,将输入字符的风格信息压缩成潜在空间向量;第二部分为Decoder Network,将潜在空间向量还原为图像。字体风格转换器整体框架是基于生成式对抗网络的结构,由字体图像生成器和字体图像判别器组成。编码器与解码器构成了字体图像生成器,网络结构如图2。
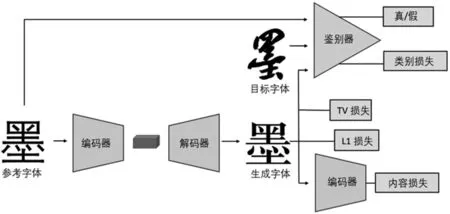
图2 本文实验选取网络模型
由于网络模型在训练过程中需要大量的训练样本,而目前还没有用于字体风格迁移实验的公开数据集,所以本文实验随机挑选了不同的手写风格和设计风格的20个中文字库。每一个中文字库通过Fontforge提取了9169张字体图像,实验所用数据集见表1。
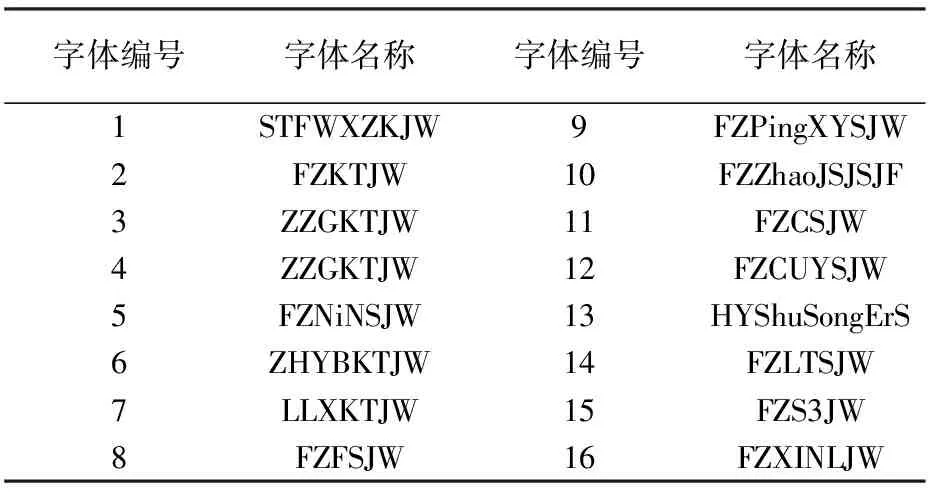
表1 实验数据集
本文以端到端地方式训练生成器G和鉴别器D。输入一对训练样本,该样本由同一字符的不同风格构成,标准字体图像为,目标字体图像为。最终目标如公式(1):
(1)
3 数据集及评价指标
3.1 数据集
由于网络模型在训练过程中需要大量的训练样本,而目前还没有用于字体风格迁移实验的公开数据集,所以本文实验随机挑选了不同的手写风格和设计风格的16个中文字库。每一个中文字库通过Fontforge提取了9 169张字体图像。
3.2 评价指标
为了量化评价字体风格迁移网络的生成字体质量,本文采用结构相似度量(structural similarity, SSIM)作为量化评判指标。其值越大表示图像相似度越高,SSIM会通过亮度(luminance)、对比度(contrast) 和结构(structure) 三个比较量进行衡量[11]。假设生成字体图像为x,真实目标字体图像为y,这两张图像的SSIM按公式(2)计算得出。

(2)
通过结构相似性作为一个衡量标准,本文的算法在不同字体生成上进行量化比较。
4 实 验
4.1 训练细节
在本文的实验中,均采用大小为256×256×3的字体图像作为输入,均采用Adam优化算法,批处理大小为16,初始学习率初始值设置为0.02。为16种不同风格的字体从GB2312字符集中选取了9 169个常用的中文字符,用于预训练整个网络。当需要生成特定的字体时,只需通过改变少量的字符来调整网络模型。
4.2 实验结果分析
由于传统的字体生成模型对于参考字体图像依赖性过大,生成字体图像的效果以及训练周期与参考字体之间存在直接关系。本文在相同目标字体、相同训练周期的情况下,参考字体的不同直接影响生成字体图像的效果如图3。

图3 参考字体对于生成字体图像的影响
由图3可以看出,不同参考字体所生成出的字体图像差异性较大,目标字体与参考字体的差异越大,生成的效果越差,所需周期越长。
本文采用10种字体作为原始字体,另外一种字体作为目标字体输入模型。每种风格字体选择700个输入字符集作为实验字符集。通过网络模型迭代200个周期后,最终在生成的目标字体中选取200个字体图像计算SSIM值,选取SSIM平均值作为该字体最终的SSIM值,在不同参考字体的相同周期的情况下,生成的字体图像SSIM值不同见表2。

表2 不同参考字体下生成字体的SSIM值
由表2可以看出,在参考字体不同的情况下,所生成的字体图像的SSIM值波动较为明显,由此也加大了研究学者对参考字体的选取难度。进而本文对于上述实验作了进一步补充,实验结果见表3。

表3 参考字体与目标字体的SSIM值以及生成字体的SSIM值
通过进一步实验,可以看出在参考字体与目标字体更接近的情况下,生成字体与目标字体的SSIM值更高。在实验数据集选取过程中,对于参考字体选取前与目标字体进行SSIM值分析,在SSIM值达到50%的情况下,生成的字体图像效果更好。
5 结 语
研究一种字体风格迁移算法,用于快速生成字体,或者用少量的字体风格生成同一风格的其他字符有着重要的研究意义。本文针对传统生成对抗网络的字体生成模型的数据集差异性进行研究。有监督学习采用匹配对数据进行训练,匹配对数据的差异性决定了生成字体的质量与周期长短,在相同目标字体、相同训练周期的情况下,参考字体的不同直接影响生成字体图像的效果。通过实验,本文将得出参考字体的选取范围。
