上市公司披露的社会责任信息“通俗易懂”吗?
2022-07-16段钊周红周辉
段钊 周红 周辉







摘 要:文本的“通俗易懂”是证券市场信息披露质量的前提与保证,为此提供了一个上市公司社会责任报告可读性质量评估的解决方案:首先,结合证券市场信息披露动机及阅读行为分析,提出了一个基于“阅读效率”与“适应水平”的两维度可读性质量评估模型;其次,设计并验证了一个基于机器学习的信息披露文本可读性质量评估的方法;最后,对我国上市公司2009-2017年发布的社会责任报告可读性质量水平进行了测度,并对全样本的总体与结构特征进行了数据分析。研究发现:我国上市公司社会责任报告可读性水平整体呈正态分布且逐年提升;不同行业与年份组间差异显著,行业异质性和外部政策变化可能是差异出现的主要原因。上述模型为信息披露质量评估提供了一个新的思路,评价方法有效减少了可读性质量评估中主观性干扰问题;同时研究结果为后续实证研究提供了一组新的量化数据,也为证券市场信息披露监管提供了新的启示。
关键词:信息披露;企业社会责任;机器学习;可读性
一、引 言
2020年10月,国务院印发了《关于进一步提高上市公司质量的意见》,明文要求“上市公司及其他信息披露义务人要充分披露投资者作出价值判断和投资决策所必需的信息,并做到简明清晰、通俗易懂”;同时,为了落实新证券法,完善信息披露制度,证监会在2021年5月开始实施的《上市公司信息披露管理办法》中,新增了信息披露中“通俗易懂”的原则性要求。显而易见,伴随注册制的推行与信息披露规则体系的完善,披露文本可读性不仅将成为我国证券市场监管的一个重要对象,也成为衡量信息披露质量的重要指标之一,有必要对其开展系统与深入的研究,实现对“通俗易懂”水平的客观、准确与量化评估。
作为信息披露质量的保证与前提(Chen,2020;张秀敏等,2017),披露文本的可读性对于降低市场不确定性、提升沟通效率、保护投资者,以及信用评级、分析师预测等方面具有重要影响(Bonsall,2017;Luo,2018;Ahsan,2018;Hassan,2019;Muslu,2019;Seifzadeh,2020)。近年来,相关的实证研究提出了一些中文披露信息可读性的评估方法:如有文献采用公式法针对深市B股公司年报采用公式法对其进行了可读性评估(阎达五等,2002),在此基础上有研究者借鉴Smith等(1992)的方法,设计完形填空测试,让具有会计专业背景被试者参与评估(孙蔓莉,2004);还有研究者以A股上市公司的年报为样本,选取平均单句词数以及难词的比例为指标衡量可读性,借助Python语言对全样本进行了可读性评估(叶勇等,2018);也有学者借鉴英文可读性中常用的Fog指數(Li,2008),并结合中文相关语言学研究成果,从分句平均字数、每句话中副词和连词比例以及前两者的简单算术平均这三个角度构建可读性评价指标(徐巍等,2021)。此外,有研究认为文本间的逻辑关系正是导致读者理解难度上升的主要因素,从文本逻辑和字词两方面构建了文本可读性评估变量(王克敏等,2018)。但总体来说,由于目前缺乏权威性的标准,披露文本可读性评估研究中仍存在依赖评价者的主观经验,随意性较强,以及信息接受者需求导向不明确等问题。
另一方面,现有研究大部分基于内容与格式有明确规定的年报或董事会报告展开,针对更容易进行语义操纵和实施印象管理的企业社会责任(CSR)报告较为少见。而CSR报告作为非财务信息披露的主要形式,向市场传递着企业可持续发展能力的信号(段钊等,2017),对利益相关者的决策发挥着越来越重要的影响(Ben A.,2018;刘媛媛等,2019;唐国平等,2019)。相对于年报而言,CSR报告具有更高的自主性、灵活性、多样性与不确定性;并且通常由专业人员进行编制,有着篇幅长、议题丰富、表述相对正式、专业词汇使用较多、语义相对固定,逻辑复杂度高等特征,在其可读性质量评估中需要有针对性地设计。虽然有文献通过对CSR报告的封面色彩、平均句长、页数与图片数量进行标准化处理得到可读性指数(吉利等,2016),但是,类似的变量设计考虑更多的是“易读性”问题,注重披露信息的外在形态,而未涉及文本表意的明确与否,对“通俗易懂”的内涵表达尚不够充分。
针对现有研究中的主要问题,本文首先结合信息披露动机及阅读行为分析,构建了一个基于效率与适应水平的两维度可读性质量评估模型,给出了一个基于时间数据的CSR报告可读性质量评估的思路;设计并验证了一个基于机器学习的披露文本可读性质量评估的方法,并对我国2009-2017年上市公司发布的CSR报告的全样本进行了测度;最后,对上市公司整体、各行业、各年份以及不同产权性质下的CSR报告可读性的总体以及结构与分布特征进行了分析与讨论。本文可能的边际贡献在于:第一,本文提出的CSR报告可读性质量评估模型紧扣“通俗易懂”这一信息披露质量要求,在评估方法上相较于以往的评价主观性强、缺乏可比性等问题,具有客观性强、标准统一、可量化对比、有效可靠与自适应的特点,并可以为相关场景的应用提供借鉴;第二,通过全样本、横纵向分析,得到了一组全新的、系统与可量化的上市公司信息披露质量的特征数据,为相关理论与应用研究提供了重要的基础;第三,在实践中,有助于“印象管理”与市场操纵行为的识别,为信息披露质量评估与监管提供了一个新的工具。
二、文献回顾与CSR信息披露中的可读性
(一)可读性质量评估模型
“通俗易懂”的内涵并不复杂,即更多的人更容易理解信息传递的内容,但如何有效衡量与测度却并不容易。受到阅读者的知识背景、兴趣爱好、阅读动机、阅读策略与认知能力等因素的影响(李广建,1989),不同的阅读者对于相同文本评估结果会有很大的差异,情境因素也会对阅读者的感受产生干扰。显而易见,根据专家或者实验被试者的阅读感受,直接得出定性或定量结论,这种“以己度人”的方式很难消除主观性与标准不一致的问题;虽然,一些研究通过问卷调查、回答问题与完形填空等方式(Taylor,1953),力求建立一个相对客观的判断标准,但也会面临抽样与样本完整性的挑战(张秀敏等,2017),针对特定人群的小样本评估效果可能有一定的效果,而在多主体、大样本的评估在实践中往往很难开展。此外,根据披露文本中的专业术语密度、次常用字密度、句法复杂度与句子结构等(Lu,2010;Flor,2013;陈银娥等,2017;任宏达等,2018)等指标来量化,不仅在特征变量选择、模型构建上易受到研究者知识、经验和偏好的影响,在指标的赋权上也会存在缺乏依据的情况,从而导致统计值与真实值之间的偏差(孙文章等,2019)。总体来说,语言的模糊性与认知的主观性和复杂性,造成披露文本可读性评估往往是“知易行难”。从实践目的出发,解决问题的关键需要紧扣 “通俗易懂”这一信息披露政策要求,基于CSR信息披露者与阅读者目的与行为特征,以及证券市场信息披露情境,重新理解与界定“可读性”。
基于信号传递理论,信息披露的主要目的是降低信息发送者与接收者之间的信息不对称程度(Li,2008),减少对利益相关者带来的困惑和犹豫。上市公司在编制CSR报告时,能否将信息清晰地、实质性地传递出去,满足合规性的要求,理论上是其首先考虑的因素;而文采是否优美和在陈述与修辞上进行修饰以达成契合与共鸣等,通常并不是报告编写中的主要出发点。在这样的披露动机下,披露的信息并不是要达到“一千个读者眼中有一千个哈姆雷特”的效果,而是要尽可能地让不同信息接收者达成对报告理解的一致性状态,这种一致性包含两个方面:与信息发送方所表达含义一致,以及不同信息接收者之间在理解上的一致。然而,由于语言的模糊性,现实中披露方在编制文本时一般拥有很大的策略空间,从自利的考虑出发,一些情况下,上市公司会刻意操纵可读性水平,如设置一些特定的逻辑关系,采用抽象描述或特定语法结构等,以达到文本操纵与印象管理的目的(田利辉等,2017;Bacha,2019;Ben A和Belgacem,2018;Loughran,2020),从而造成披露方意图表达的信息与实质信息往往存在差异。因而,站在质量评估与监管的立场,CSR信息披露是否“通俗易懂”,意味着是否能够适应信息接收者不同认知水平,容易达成对实质信息理解上的趋同。即不同的人在阅读同一信息达成正确判断时,其认知成本差异较小,达成一致性正确判断所花的代价较低。我们将这一可读性质量评估维度称为“适应水平”。
对信息接收方而言,CSR报告的读者一般为利益相关方,阅读目的通常是想从公开信息中发现企业可持续发展能力的特定信号以提高决策效率。即使在现阶段参与者以中小投资者为主的我国证券市场,也有证据显示,投资者仍然具有强烈的投资理性和获得各类信息的动机,以便资产价值能够在投机干扰下回归理性(赵子夜等,2019)。因而,一般情况下,在阅读的过程中,他们在主观上会保持一种理性与谨慎的态度;因为一旦存在理解上的偏差,阅读者可能会承受相应的经济与社会行为后果。但是,与财务指标为主的内控信息不同,CSR报告阅读的过程中,相关决策知识的形成往往来自于利益相关者对搜寻到的信息的再加工,并不容易从文本中直接获得。基于此,从信息接收方的目的与行为方式出发,应主要考虑阅读者对文本中的有效信息搜寻与编码的效率,即信息接收者越容易找到对其决策有帮助的内容,并做出正确的判断,CSR报告越是“通俗易懂”,反之亦然。我們将这一评估维度称为“阅读效率”。
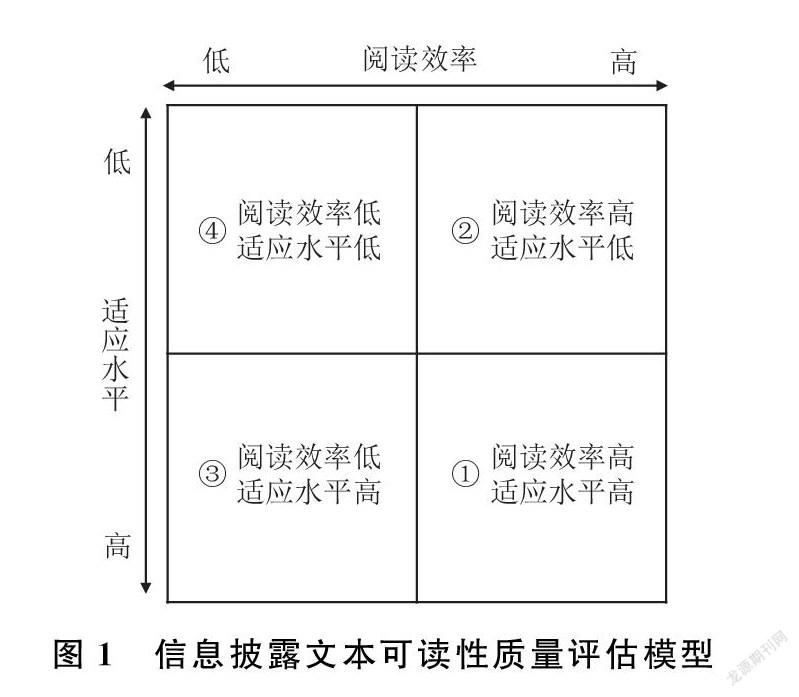
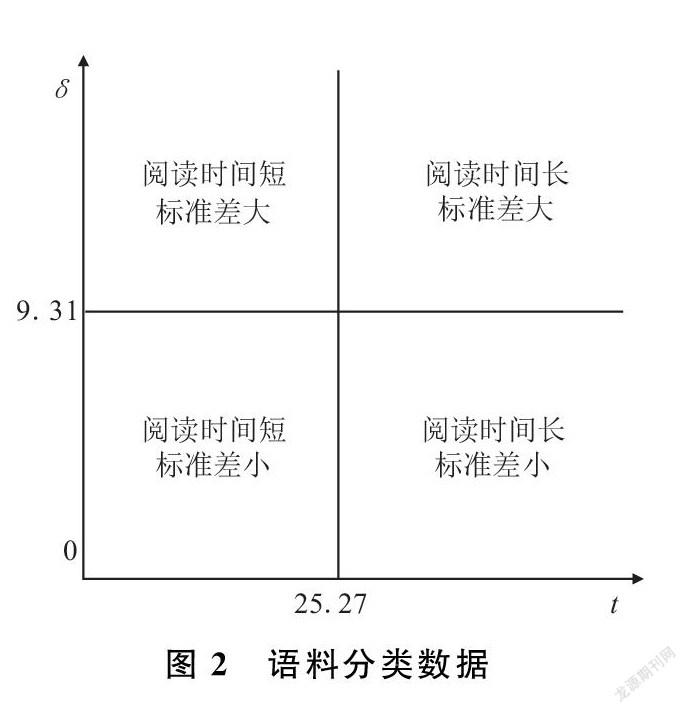
根据上述两个维度,从考察是否能实现有效信息传递以达到“通俗易懂”,我们将CSR信息披露文本可读性分为四种不同类型,如图1所示。其中,第1种类型阅读者信息搜寻与再加工的效率最高,且容易与他人形成一致的正确理解。第2种与第3种类型可读性处于中间水平,代表“易懂不通俗”和“通俗不易懂”的两种情况,这也是文本操纵与印象管理中最常见的方式。“易懂不通俗”指阅读者从披露文本中搜寻到有效信息的难度并不大,但不同类型的阅读者据此形成的知识具有差异,常见的情况是在框定效应的作用下(Hellmann,2017;Chung,2019),专业知识的欠缺和信息的弱势的阅读者会被披露方所“误导”;而“通俗不易懂”指披露文本一般歧义较少,但其中存在大量冗余信息,找到关键信息并形成决策知识并不容易,阅读者要花费较大的信息搜寻与编码成本。
(二)可读性的测度
对披露文本的阅读效率与适应水平进行系统、可量化的测度,是实现可读性质量评估的关键。从现有可读性测度技术路线来看,可大致分为两类:一类是基于公式计量的方式,一类是基于机器学习的方式。公式计量源于美国学者Lively等(1923),1923年他们通过对初中英文教材词汇难度进行的考察,构建了第一个英文文本可读性评估公式;此后Vogel等(1928)在1928年提出了Winnetka公式,通过使用回归方程的方法,将词汇和语法等文本特征纳入可读性公式来评估儿童文本的理解程度;伴随着研究的深入,一些研究者从不同角度对可读性公式进行改进,比较有影响的如Flesch与Dale-Chall(Flesch,1948;Dale,1948)以及近年来使用频繁的Fog指数(Li,2008)和Bog指数(Bonsall,2017)等测量公式。中文文本可读性的评估起步相对较晚,早期研究多集中于教育领域,主要借鉴国外可读性公式设计思路,结合具体的应用场景,提出中文文本可读性测量公式(Yang,1970;孙刚,2015;荊溪昱,1995;宋曜廷等,2013):如有文献(张宁志,2000)对29部常用教材的语料进行分析,设计了中文可读性公式的雏形;还有研究者(王蕾,2017)基于对外汉语教学的分析,提出了一个衡量记叙性文本的难易度的可读性公式。伴随着信息技术的发展,研究者开始将机器学习技术应用于该问题,通过人工标注语料库,学习不同难度级别语料特征,构建分类器或比较器模型,对目标文本进行可读性难度级别分析。如Si(2001)将一元词串隶属度模型引入可读性研究,首次将文本可读性分析与机器学习联系起来;Collins-Thompson(Colins,2004)等在Si的研究基础上加大了训练模型,采用Good-Turing平滑算法,提高了文本可读性预测的准确性。近年来,机器学习的方法在一些领域显示出较好的应用前景(Kate,2010;Kim,2012;McNamara,2015;Nandhini,2016;Jin,2018)。
从目前的研究进展来看,由于中文与英文在语言特征上存在差异(顾曰国,1992;孟庆涛,2009),基于中文字、词、句长度与音节等结构性特征构建的公式,其有效性还有待进一步验证;同时,CSR报告作为一种规范性的信息披露文本在陈述方式上往往非常相似,结构特征差异并不明显,采用公式计量的方式,用一把通用的“尺子”,很难将结构类似文本的可读性有效区分开来。而在机器学习研究中,语料库通常需要进行人工标注,除成本高外,也难以排除标注过程中的主观性干扰,涉及大规模标注时,标准的一致性又难以保证,存在分类的可靠性与稳定性问题。相对而言,如果能解决语料库构建的问题,基于机器学习构建分类器的方式,在中文披露文本的可读性测度上会更具有优势。
可读性本质上源于个体主观感受,我们可能都会认同某一文本的确“通俗易懂”,但不同的人从不同的经验出发,往往会做出不同程度的判断。而这些没有量纲的描述,通常是不可以直接进行比较的。例如,在给定相同的语料与标注说明的情况下,不同的标注者往往会达成相同的意见,但却给出不同的评估绝对值;虽然可以运用排序方法得到文本的两两相对难度关系(Schlkopf,2006;Tanaka-Ishii,2010),但一般只能做到文档的相互比较,难以达到段落或篇章水平两两比较,且大规模标注的成本很高。提高客观性与评估标准的一致性是本文测度方法设计的主要考虑。从“通俗易懂”原则出发,我们认为阅读效率与适应水平两个可读性质量评估维度,涉及个体和群体信息搜寻成本,而信息搜寻成本可以通过时间这一客观指标,转化为阅读者行为特征来进行有效测量。基于此,本文用同一语料多个阅读者的耗费时间均值来测度阅读效率;由同一语料多个阅读者的耗费时间标准差来测度适应水平。这样,不仅很好地满足了两维度测量的构念效度,也可以有效解决语料标注中的主观性问题,保证了可读性质量评估结果的可靠性。
三、CSR信息披露可读性质量评估方法
(一)CSR报告语料采集
目前尚未有专门针对CSR报告的人工标注语料库,需要研究者进行自行设计与构建。除满足语料库構建中的一般性原则外,CSR报告可读性语料还需从文本特殊性出发,考虑提供真实的数据资源和深层次的语言信息的功能。文本抽样是一个关键性问题,如果所抽取的样本存在较大的系统性偏差或代表性偏差,将直接影响机器学习的有效性。在抽样数量有限的约束下,若通过随机抽样,样本结构与总体结构存在差异的可能性会很大,如果代表性偏差不能很好控制,那就意味着,语料库可能只适用于某一话语特征文本的评价。与之相对应,CSR报告同一文本中上下文表述类型差异较小,因而通过人工控制进行分层抽样,可以有效提取出更多类型的文本,且保证系统性偏差的可控。另外,CSR报告总体上数量并不大,且人工标注成本较高,分层抽样也有利于提升机器学习的效率。
我们对所收集的报告按类型随机抽样、文本分割、主题合并、分层抽样的流程,尽可能控制了抽样偏差的出现,并结合阅读者的习惯,对提取的语料进行了人工编辑,以保证将各种话语类型包含在语料样本中,提高自动评估的效果。具体分为五个步骤:第一步,根据报告陈述模式的类型与主题篇幅分布,将所有报告分为四个类型:质性均匀、质性不均匀、混合均匀与混合不均匀;第二步,在样本库中按行业和年份比重,进行类型随机,由两名研究人员同时进行初步研读,在意见一致的前提下进行人工分类,意见无法形成一致的样本作为第五类,直至抽取各类型报告数量至少达到20份,总量达到200份;第三步,综合国际、国内和行业各类编制指南与标准,按照6个信息披露主题对报告文本进行内容分割,并在同一主题下进行文本合并,得到6个一级子类,这6个主题分别是:公司概况、股东、客户和消费者、供应商、员工、环境社区公益;第四步,对于每一子类中的报告片段,按叙事型、阐述型与混合型修辞方式进行分层,段落中句子多以人物、事件或地点作为起点,使用放射型推进方式的为叙事型,若在逻辑上与上文保持联系,或者是对上文某个部分的扩展或依附为阐述性型,两者兼有为混合型,并最终得到18个层;第五步,按“总字数占比”在18个层中分别随机抽取段落片段,经人工比对合并、调整与编辑,控制字数在300字左右(±3%),最终得到600个语料片段。
语料抽取后,首先针对每一个片段,经过至少2人的仔细判读,提取其中可能会影响决策的有效信息;在达成共识的基础上,按照统一的句子长度、语法结构、难易水平设计两道判断题,最终得到包含300字左右文本片段和两道判断题在内的600个数据集;接着,根据采集的语料,本文设计开发了一个可读性标注平台,通过网页答题的方式提供给标注者,600个语料片段被随机分成24组标注数据集,每组标注数据集包含25个语料与50道判断题;最后,通过预实验对语料进行完善,并测算出每组语料正常标注的总耗时应不低于25分钟。
(二)CSR报告可读性评估数据集构建
利用众包方式构建语料库,已成为研究者解决数据集不足问题的一条常见的途径(Schumacher,2016;Vajjala,2017),基于可读性标注平台,我们设计了一个众包实验来记录被试的阅读时间特征,阅读过程本身就是标注。保证过程可控与结果可靠是实验设计的主要出发点:第一,选择了与现实中CSR报告阅读者认知特征相似的被试,不事先告知研究的真实目的,避免实验者偏差和偶然减员;第二,进行有效的启动,通过目标激励与分心物抑制,保证被试阅读过程中的持续专注;第三,注意避免选择性偏差,同一语料随机分配给多个阅读者,以记录均值与方差;第四,注意过程控制,被试在阅读完语料后,会进入下一页面回答两道判断题,测试其对语料中关键信息搜寻的效果,如果答题错误,将自动返回语料页面,被试再次阅读后答题,重复过程直至答案全部正确,并只记录在语料页面停留的合计时间;第五,保证测量的一致性,根据语料中关键信息编写的判断题,在句子长度、语法结构、难易水平上等方面基本一致;第六,保证标注数据的可靠性,对于每段语料对应的多个被试阅读的时间数据,在去除极值与异常值后计算阅读时间均值与标准差。
参与众包标注实验的被试主要由高校经管专业本科与研究生、企业管理人员与政府部门工作人员构成,总计483人。我们提前通知他们将进行专业知识测试,结果与考核或奖励有关,并要求其预留好时间。实验中,每组标注数据集在线并行发放给了15个以上的被试,当系统后台收到18个正常返回结果(总耗时大于25分钟)后,将自动停止发放该组数据。剔除返回的组异常结果与组数据缩尾处理后,共获得600个语料对应的9000个时间数据。进一步针对单个语料对应的15个时间数据进行第二次缩尾处理,最终得到6000个时间标注数据。根据两维度评估模型,我们计算了每条语料的10个有效阅读时间均值和标准差,并按这两个指标的中位数,对600个语料进行了分类,在两个维度上各得到高低水平的不同的300条标注结果,为分类器的构建提供了基础,实验数据如图2所示。
(三)CSR报告可读性分类器构建
由于标注的成本较大的原因,完全依赖标注数据集进行有监督学习的实现难度较大,因此,在大多数情况下,我们所面临的只是少量数据或者少量标注数据的情况。同时,弱监督学习作为机器学习领域的研究热点之一,不少学者也在不断尝试将弱监督学习应用到小数据集机器学习中(Wang,2016;Wang,2018;Boney,2018)。目前常用的一种方式是在一个大数据集上对模型进行预训练,并在特定任务上对其进行微调,以控制过拟合的情况。2018年Bert模型的推出为弱监督学习应用提供了重要的基础,近年来在文本分类、问答系统,情感分析,垃圾邮件过滤,命名实体识别等任务有了较广泛的应用,现有的一些研究也表明,基于Bert模型预训练,在小数据集的情况下也能实现显著的分类效果。基于此,本研究借助Howard(2018)提出的方法,构建了基于阅读效率(阅读时间)和适应水平(标准差)的两维度的分类器,然后通过对两个维度学习速率的变化来微调语言模型,让模型更快地在小样本数据集上收敛。
在预训练的基础上,如何利用有限的标注数据提高分类准确性是一个关键问题。由于CSR信息披露文本的特殊性,相对于数据增强,从语文教育等相关领域进行知识结构迁移存在较大不确定性。因而,按照常见的机器学习方法,我们首先加载了Bert中文模型,进行了无监督的预训练;在此基础上用标注好的数据进行了微调。由于进行有监督微调的标注数据集中只有600条语料,为避免过拟合的情况,我们设置了阅读时间和标准差两个分类器模型(核心代码详见附录1),以减少特征维度提高特征数据集重复利用率。同时,由于小数据集的本质问题在于数据量过少,从而造成分类准确率偏低,我们采用了早期针对数据增强的方法,对数据应用了一组变换来增加样本量,并且考虑到采用同义词替换、回译、随机插入与删除等方式,可能会改变文本可读性水平,相比而言中文阅读习惯性下,句子和词的顺序不会对理解有太大影响,故采用了打乱句与词顺序的方式,进行了数据增强,并经人工逐条阅读进行了确认。
数据增强后,按照9∶1的比例将标注数据集划分为训练集和测试集。完成训练后,经过测试发现,对平均分类准确率达到了85.3%。我们也选取了其他几种分类算法对CSR报告的分类准确性进行了对比(如表1所示)。结果表明,基于Bert模型预训练的可读性分类效果较好,基本满足对CSR报告文本进行可读性质量评估的要求。
(四)CSR报告可读性综合评估
相对于文学作品而言,CSR报告在整体上层次较为清晰,情感倾向不明显,长句多,上下文通常和总分、顺接、转折、例证、因果与对照等关系直接相关,阅读过程中句与段落在信息传递与搜寻功能上的独立性较强。针对这一特征,本文采用了对CSR报告进行分段处理;以段落为粒度进行自动分类;并进行无量纲赋权与数据降维的方法;最终计算出篇章和整个文档的可读性程度。
首先,在扎根的基础上,我们结合中国人基本阅读速度,将报告中的段落按句号为准,按300字左右整合为一段,据此计算出单个报告的总段数;接着应用阅读时间与适应水平分类器,对报告进行可读性类别自动判断,得到每个类别的段落数;然后计算每个分类类别段落数占总段落数的比例,可以得到阅读效率高低与适应水平高低两两结合类型段落数占总段落数的比例四个指标;最后,我们借鉴了郭亚军(2011,2017)等人的研究,提出了一个基于主客观信息綜合判断的拉开档次法,对数据进行降维处理,尽可能拉大被评价指标间整体差异的同时,并兼顾考虑到专家主观信息及各个指标本身的相对重要程度,最终得到披露文本篇章和文档级的可读性质量评估数据。
四个评价指标分别为阅读时间短标准差小x1、阅读时间短标准差大x2、阅读时间长标准差小 x3、阅读时间长标准差大x4,指标均为极大型指标。具体计算步骤如下:
记xij为被评价对象i在评价指标j下的观测值,其中i=1,2,…,n;j=1,2,…,m,x*ij表示经过无量纲化后处理的指标值,不失一般性,记无量纲化处理后的数值仍为xij。
(1)对原始指标数据进行无量纲化处理。本文采用极值处理法对原始数据进行无量纲化处理,即x*ij=(xij-xminj)/(xmaxj-xminj)。
(2)非线性因子的选取。记评价指标xj关于n个被评价对象取值的方差为 D(xj),各被评价对象间整体离散程度的贡献率为μj,则μj=D(xj)∑mj=1D(xj)。根据该公式计算可读性各评价指标关于CSR报告间整体离散程度的贡献率μj,计算结果为(0.274,0.304,0.270,0.152),结合专家的相关建议,事先确定给定的指标离散程度对各被评价对象间差异影响的贡献率的阈值α为0.29,由于μ2=0.304>0.29,因此指标x2为非线性因子。
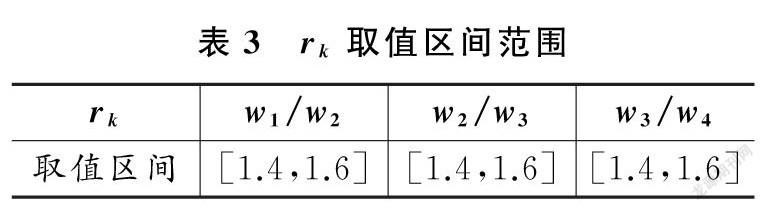
(3)评价指标序关系的判断。邀请5位相关领域专家结合自身的知识经验对本研究中确定的可读性评价指标的重要程度进行排序,排序结果为x1>x2>x3>x4。设根据主观判断给出的评价指标xk-1与 xk的重要程度之比为rk=wk-1/wk(k=m,m-1,…,2),wk表示指标相应权重,rk的取值如表2所示。由于专家根据主观信息很难准确地给出rk的确定值,最终,结合几个专家的一致意见确定排序后相邻两个评价指标重要程度的比值rk的取值范围,如表3所示。
(4)确定评价指标权重。为了使各被评价对象间的差异尽可能地拉大,各被评价对象间的整体差异可以用各被评价对象综合评价值的方差进行衡量。即
s2=1n∑ni=1(yi-y-)2=(yi)Tyin-(y-)2(1)
因此为了使各被评价对象间的差异最大,就是使式(1)的方差最大,因此按如下规划求解来计算评价指标权重:
max(s2)=max(yi)Tyin-(y-)2
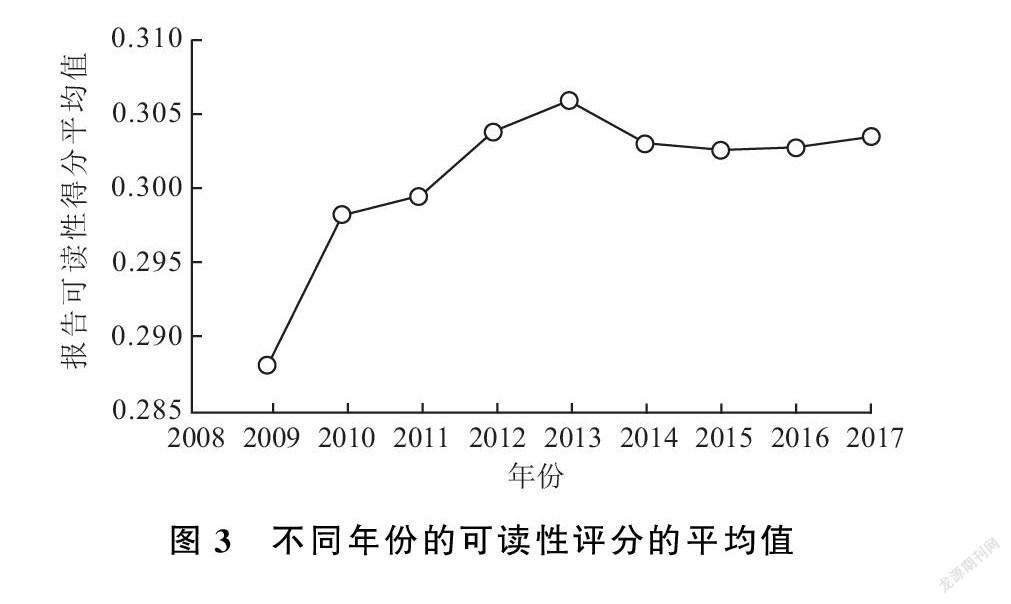
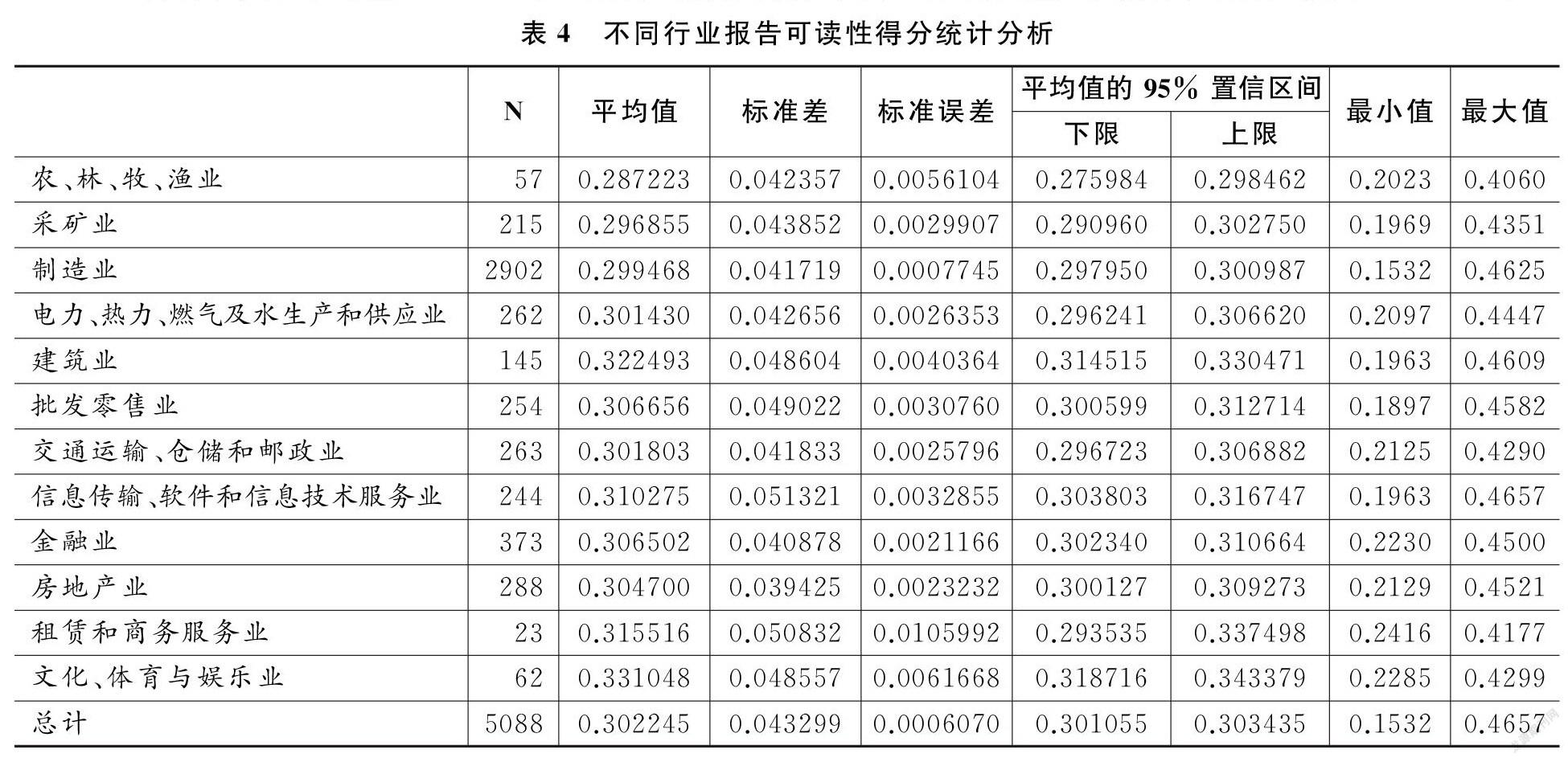
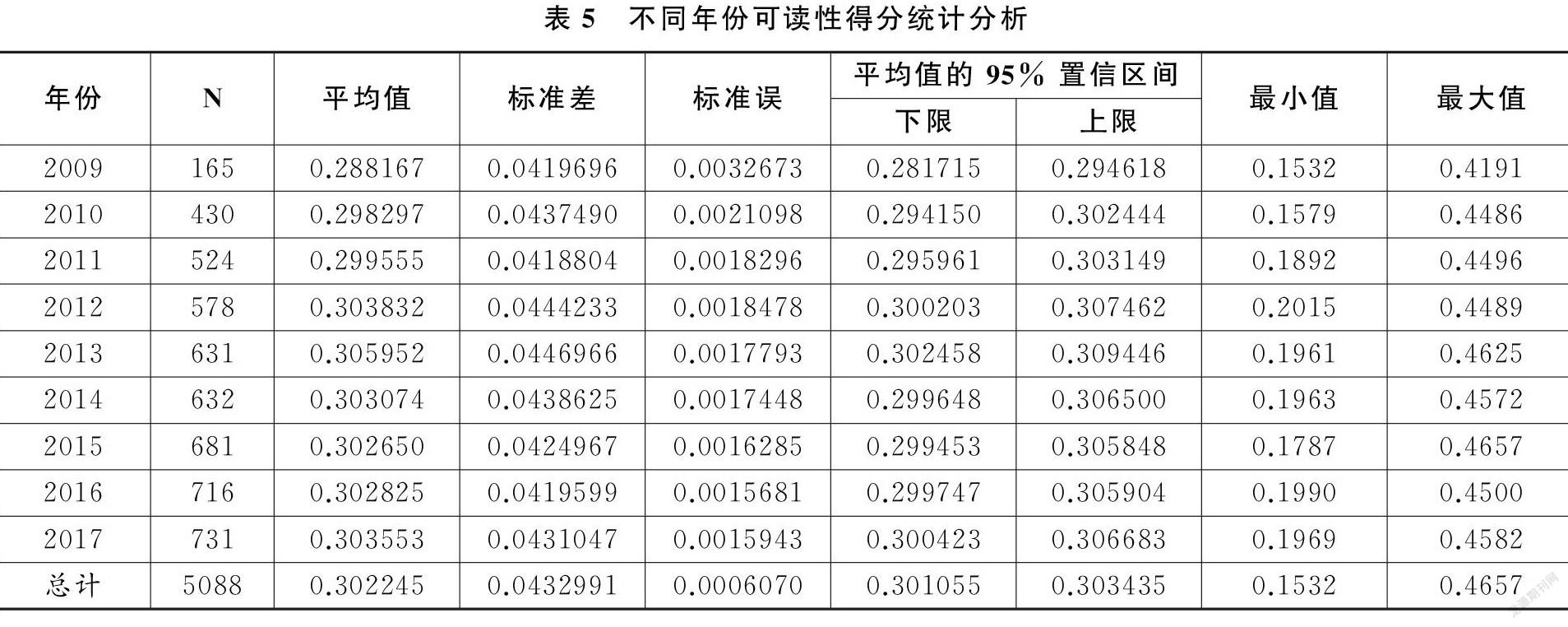
s.t.r-k≤wk-1wk≤r+k0 根据规划模型中计算得到的指标权重,按式(3)计算各被评价对象最终的评价值yi,本文评价指标数据xij均大于等于0。 yi=∑mj=1j≠k0xijwj+(xk0)2wk0,xij均大于(小于)等于0时∑mj=1j≠k0xijwj+(xk0)3wk0,其他情形(3) 根据式(1)及规划模型(2)计算可读性各评价指标的权重系数,本文运用Python软件进行编码计算(核心代码见附录2),计算得出w1,w2,w3,w4分别为0.443,0.277,0.173,0.107。 (5)将计算得出的评价指标权重系数wj带入式(3)中,即可计算出各被评价对象最终的综合评价结果,得到上市公司CSR报告样本的最终可读性评价得分分值。 四、数据分析与结果讨论 (一)样本选取 我们从企业社会责任中国网等上市公司信息披露官方网站收集了2009-2017年的CSR报告全样本共5183篇。以2009年为样本起点进行研究分析,除2009年前样本量很少外,缺乏披露指南,样本质量参差不齐也是一个重要因素。上市公司一般是在次年初中期才会发布上一年度的社会责任报告,而本研究样本收集截止时间到2019年3月,只有小部分企业发布了2018年的CSR报告,因此目前只对2009-2017年的数据进行了分析研究。本文使用的企业财务信息主要从国泰安和锐思数据库获得;行业分类主要来源于国家统计局发布的分类标准。同时,对于存在修订公告以及样本量过少的行业,本文均予以剔除,最终得到2009-2017年涉及12个行业的5088个有效样本。 (二)描述性统计 不同行业报告的可读性数据统计情况见表4。从表中可以看出,制造业披露的CSR报告数量最多,样本数量为2902篇,占总体样本的57.04%;其次是金融业,样本数量为373篇,占样本总数的7.33%;而样本量最少的行业为租赁和商务服务业,其样本数量为23篇,仅占总样本的0.45%。可读性得分均值最高的是文化、体育与娱乐业,达到了0.331048,其次是建筑业,它的可读性得分均值达到了0.322493,都高于样本均值0.302245。可读性最低的行业是农、林、牧、渔业其报告可读性仅为0.287223。 报告可读性均值按年份统计情况如表5、图3所示,从表5中可以看出,2009年企业发布的报告最少,仅为165篇,2017年发布的报告数量最多,达到了731篇,数量呈逐年上升趋势,其中2009年到2010年报告数量增长速度最快。从不同年份报告的可读性均值来看,分值最高的是2013年,其值为0.305952,高于总样本均值0.302245,报告可读性数据均值最低的年份是2009年,其值为0.288167,明显低于总样本均值。 由图3可以看到,整体上CSR报告可读性得分均值随年份变化比较明显,2009-2013年间发布的CSR报告可读得分均值快速上升,但在2014年可读性数据平均得分略有回调,并随后基本保持稳定。初步推断这一变化趋势与2009-2013年间信息披露规则体系逐步完善有关,由于报告编写有了相应的标准与指南,显现出较强的学习效应;而在2014年后报告可读性分数回调,可能是因为披露方在熟悉相关标准之后,在编写报告的过程中进行了策略优化,以保证披露信息的规范性与减少披露风险。 (三)数据分析 (1)正态检验 在描述性统计后,本文根据可读性数据,进行了全样本的正态分布检验,直方图检验如图4所示。从图中可以看出,大部分报告的可读性分值在0.20~0.40分之间,处于中间位置,而处于两端的可读性得分占样本总量较少。进一步检测数据的正态分布情况,如图5所示,由样本可读性实测值和预期的正态值组成的散点图基本上都落在直线附近,只有少部分两端的可读性极端值与直线的值相差较大。因此,可以推断出可读性分值基本上服从正态分布。 (2)方差分析 在对数据正态检验后,进一步对不同行业、不同年份、不同产权性质的可读性分值进行了方差齐性检验,结果显示除了按照不同行业进行分组后的可读性数据方差不齐外,其他两个组的数据符合方差齐性。首先,本文采用独立样本 Kruskal-Wallis 检验对不同行业的可读性分值进行分析。由表6可以看出,不同行业独立样本Kruskal-Wallis 检验结果显著性小于0.05,表明不同行业之间可读性评分存在显著差异,行业异质性是影响CSR信息可读性水平的重要因素。 结合已有的经验证据推断,在自身CSR行为与绩效的描述中,经营范畴的差异会对可读性产生相应的影响。例如,由于行业原因一些报告里面存在较多的专业术语,如果没有对其进行解释的话,那么报告的可读性就会大打折扣,而文化、体育与娱乐业,在经营内容上比较容易理解;此外,一些环境敏感型行业,为修饰其社会责任表现,可能会有意进行语义操纵。另一个原因则可能是行业样本分布不均匀所致(冼迪曦,2012)。 由于不同产权性下的报告可读性分值既服从正态分布又是等方差的,因此本文采取方差分析对不同产权性质下的CSR报告可读性分值进行了检验。检验结果如表7所示,表明产权特征并不是可读性高低的主要影响因素。 同样,本文采用方差分析对不同年份间的CSR报告可读性分值进行了检验,检验结果如表8中所示。从表8可以看出,不同年份的CSR报告可读性数据F值显著性水平低于5%,说明不同年份的可读性得分存在差异。 为了更准确地发现具体哪些年份的报告可读性得分存在差异,本文采用了LSD法,对可读性分值数据进行了多重比较,具体结果如表9所示。 从表9可以看出,2011-2017年中,每一年与其他年份可读性分值都没有显著性的差异,2009年与其他年份可读性分值均有顯著性的差异。结合政策研究可基本确定,这一现象是外部政策的结果,2009-2010年前后,相继发布了《社会责任绩效分类指引》、《社会责任指南》等标准,中国上市公司CSR报告的编写逐渐趋向标准化;除此之外,一些上市公司还积极与GRI等国际标准接轨,在报告的内容和形式等方面不断提升,大大增强了利益相关者的投资决策效率。 (3)异常值分析 为进一步发现报告可读性分值中存在的异常值,我们采用了箱型图的方式对可读性异常值进了描述分析。结果如图6所示。 由图6可以看到,仅有两个行业中没有存在异常值,表明文化体育与娱乐业、租赁和商务服务业报告可读性得分比较均匀。异常值最多的是制造业,其中编号为199的样本为2010年浙江某橡胶股份有限公司发布的报告,经查阅判断可读性水平相对较低,主要是由于这篇报告结构比较混乱,语言表述模糊,容易产生歧义。而得分比较高的3215号样本为2015年安徽某水泥股份有限公司发布的CSR报告,可读性强的原因是编制中逻辑清晰,描述中确定性程度高,歧义表达少。通过箱型图可以快速地发现样本可读性得分中的异常值,通过比对找出异常原因,为质量评估与市场监管提供依据。 (4)有效性检验 为明确本文提出的信息披露文本可读性质量评估方法在实际应用中的效果,我们采用了与专家评分对比实验的方法,来检验整体方案的实用性和稳定性。通常情况下,专家给出的是定性判断,需要对本文得到的数据进行离散化处理。由于可读性得分主要分布于0.20~0.45之间,因此采用五分量表法,把区间分为5等份,对应赋值区间分别为1~5分,分别代表:可读性非常低、可读性低、可读性一般、可读性高、可读性非常高。具体情况如表10所示。 根据实例分析中得到的结果,我们在每一个可读性得分区间分别随机抽取了一篇报告,分别为《600352浙江龙盛:2014年度社会责任报告》《601107四川成渝:2013年度社会责任报告》《600383金地集团:2016年度社会责任报告》《000883湖北能源:2016年度社会责任报告》《600372中航电子:2015年度社会责任报告》,可读性分值分别为0.238619、0.261585、0.338352、0.391487、0.423627,分别对应5分法中的1~5分值。 我们联系了非财务信息披露评价专业机构中的5位专家,明确告知其评价对象为样本整体上阅读和理解的容易程度,并请他们对抽样的5篇报告按照5分量表进行分别评分。结果如表11所示,对于同一份CSR报告来说,不同专家之间的可读性评分具有一致性。同时,我们计算了5位专家评估的平均值,通过对比分析可得,专家法得到的平均值和本文研究结果基本一致,从而在一定程度上验证了本文提出的方法在实际应用中具有良好的评估效果,以及实例分析结果的可靠性与有效性。 五、研究结论与不足 信息披露的可读性自动评估,作为一种预测性的手段,具有客观性和经济性的优点(吴思远等,2018)。由于人类语言和认知的复杂性,面向通用领域的自动评估往往具有很大的难度;特定应用场景下的研究,由于可以结合情境、文本特征、作者心理与阅读者行为等因素,进行更具体和有针对性的分析,而展现出较好的研究前景和应用价值。过去十多年来,伴随着机器学习技术的发展,可读性评估方法与实践有了很大的进展,但如何控制标注过程中因人的主观性差异所带来的标准不同,目的不同和结果不一致,仍然是一个尚待解决的问题。在文本阅读过程中,相对于心理与认知层面的测量,对人的行为特征的观察会更直接与准确,解决问题的关键在于找到一个能够合理联系阅读行为特征与文本可读性的理论框架及有效测量方法。 从这一研究目的出发,本文从评估“通俗易懂”的质量评估与监管要求出发,针对CSR信息披露中的特点,在信息披露方与接收方的动机与行为分析的基础上,构建了一个基于阅读效率与适应水平的两维度评估模型,提出了一个从信息搜寻的效率与达成理解一致性的成本进行评估的思路。这一模型的重要意义在于,将特定场景下的阅读行为特征与报告可读性联系起来,并可以根据同一披露报告不同人阅读时间均值与标准差,客观区分不同文本可读性之间的差异。根据这一认识,本文进一步设计了一个完整有效的方法,结合我国2009-2017年A股上市公司披露的CSR报告,采集了CSR报告语料,并采用众包实验对语料进行人工标注,同时结合机器学习和改进的拉开档次法,最终得到了篇章级CSR信息披露可读性数据;同时在此基础上,我们对所得到数据根据不同行业、年份、产权性质进行了分析,结构显示我国CSR报告的可读性水平整体上服从正态分布;产权性质对CSR信息披露可读性影响不大,而不同行业与年份可读性分值差异较为显著;行业异质性和外部政策的变化可能是差异性形成的主要原因。 同时,本文也存在一定的局限性:第一,信息披露文本可读性质量评估的两维度理论模型的提出,主要基于“通俗易懂”的非财务信息披露质量评估与监管的政策要求,能否满足其他场景的要求还有待进一步检验;第二,CSR報告的可读性语料库的规模仍较小,虽然进行了基于Bert模型的预训练和数据增强,但仍然可能存在过拟合的情况;第三,众包标注实验采用了在线方式,虽然通过数据处理进行了误差控制,对被试行为的监测仍然相对较弱,尚不能完全排除标注过程中环境因素的影响;第四,本文从“通俗易懂”的政策要求出发,主要针对的是信息披露文本的可读性质量,虽然我们对抽象图片内容进行了文字识别,而CSR报告中常见的实景图片也可能在利益相关者查阅报告时对其产生影响,从而造成可读性程度的偏差,对于这些存在的问题,我们将会在未来研究中进行有针对性地优化和改进,并在更大范围对研究结果进行检验。 参考文献: [1] 陈银娥、江媛,2017:《管理层权力、制度环境与董事会报告可读性—— 来自我国上市公司的经验证据》,《珞珈管理评论》 第3期。 [2] 段钊、何雅娟、钟原,2017:《企业社会责任信息披露是否客观——基于文本挖掘的我国上市公司实证研究》,《南开管理评论》 第4期。 [3] 顾曰国,1992:《礼貌、语用与文化》,《外语教学与研究:外国语文双月刊》 第4期。 [4] 郭亚军、马凤妹、董庆兴,2011:《无量纲化方法对拉开档次法的影响分析》,《管理科学学报》 第5期。 [5] 郭亚军、阮泰学、宫诚举,2017:《基于主客观信息综合判断的非线性拉开档次法》,《运筹与管理》 第6期。 [6] 吉利、张丽、田静,2016:《我国上市公司社会责任信息披露可读性研究——基于管理层权力与约束机制的视角》,《会计与经济研究》 第1期。 [7] 荊溪昱,1995:《中文国文教材的适读性研究:适读年级值的推估》,《教育研究资讯》 第5期。 [8] 李广建,1989:《略论阅读能力》,《图书馆建设》 第3期。 [9] 刘媛媛、田言,2019:《财务报表误述、误述风险与自愿性信息披露——基于企业社会责任报告的证据》,《会计研究》 第4期。 [10] 孟庆涛,2009:《英汉語用礼貌原则跨文化交际运用探析》,《现代语文(语言研究版)》 第2期。 [11] 任宏达、王琨,2018:《社会关系与企业信息披露质量——基于中国上市公司年报的文本分析》,《南开管理评论》 第5期。 [12] 宋曜廷、陈茹玲、李宜宪, 等,2013:《中文文本可读性探讨:指标选取、模型建立与效度验证》,《中华心理学刊》 第1期。 [13] 孙刚,2015:《基于线性回归的中文文本可读性预测方法研究》,南京大学。 [14] 孙蔓莉,2004:《论上市公司信息披露中的印象管理行为》,《会计研究》 第3期。 [15] 孙文章、李延喜、朱佳玮,2019:《基于MC-AHP与灰色关联度的企业中文年度报告可读性综合评价体系及实证检验研究》,《当代会计评论》 第1期。 [16] 唐国平、刘忠全,2019:《环境保护税法》 对企业环境信息披露质量的影响——基于湖北省上市公司的经验证据》,《湖北大学学报(哲学社会科学版)》 第1期。 [17] 田利辉、王可第,2017:《社会责任信息披露的“掩饰效应”和上市公司崩盘风险——来自中国股票市场的DID-PSM分析》,《管理世界》 第11期。 [18] 王克敏、王华杰、李栋栋, 等,2018:《年报文本信息复杂性与管理者自利——来自中国上市公司的证据》,《管理世界》 第12期。 [19] 王蕾,2017:《初中级日韩学习者汉语文本可读性公式研究》,《语言教学与研究》 第5期。 [20] 吴思远、蔡建永、于东, 等,2018:《文本可读性的自动分析研究综述》,《中文信息学报》 第12期。 [21] 冼迪曦,2012:《基于会计视角的企业社会责任报告研究》,广东工业大学。 [22] 徐巍、姚振晔、陈冬华,2021:《中文年报可读性:衡量与检验》,《会计研究》 第3期。 [23] 阎达五、孙蔓莉,2002:《深市B股发行公司年度报告可读性特征研究》,《会计研究》 第5期。 [24] 叶勇、王涵,2018:《盈余管理对企业年度报告可读性的影响研究》,《四川理工学院学报(社会科学版)》 第6期。 [25] 张宁志,2000:《汉语教材语料难度的定量分析》,《世界汉语教学》 第3期。 [26] 张秀敏、刘星辰、汪瑾,2017:《阅读难易程度与信息披露质量——基于易读衡量和关联因素视角的分析》,《当代经济管理》 第6期。 [27] 赵子夜、杨庆、杨楠,2019:《言多必失?管理层报告的样板化及其经济后果》,《管理科学学报》 第3期。 [28] Ahsan, H. and Mostafa, M. H.,2018,Business strategies and annual report readability, Accounting & Finance,60 (3). [29] Bacha, S. and Ajina, A.,2019,CSR performance and annual report readability: evidence from France, Corporate Governance: The International Journal of Business in Society,20 (2):201-215. [30] Ben A, W. and Belgacem, I.,2018,Do socially responsible firms provide more readable disclosures in annual reports? Corporate Social Responsibility and Environmental Management,25(5):1009-1018. [31] Boney, R. and Ilin, A. Semi-supervised few-shot learning with MAMLl.in: Proc. of the ICLR (Workshop), 2018. [32] Bonsall, S. B. and Miller, B. P.,2017,The impact of narrative disclosure readability on bond ratings and the cost of debt, Review of Accounting Studies,22 (2):608-643. [33] Bonsall, S. B.,Leone, A. J. and Miller, B. P., et al,2017,A Plain English Measure of Financial Reporting Readability, Journal of Accounting and Economics,63 (2-3):329-357. [34] Chen, T. K. and Tseng, Y. J.,2020,Readability of Notes to Consolidated Financial Statements and Corporate Bond Yield Spread, The European accounting review,1-31. [35] Chung, S. W. and Lee, S. Y.,2019,Visual CSR Messages and the Effects of Emotional Valence and Arousal on Perceived CSR Motives, Attitude, and Behavioral Intentions, Communication Research,46 (7):926-947. [36] Colins, T. K. and Callan, J.,2004,A Language Modeling Approach to Predicting Reading Difficulty,Human Language Technologies: the 2004 Conference of the North American Chapter of the Association for Computational Linguistics.,Association for Computational Linguistics,193-200. [37] Dale, E. and Chall, J.,1948,A Formula for Predicting Readability: Instructions, Educational Research Bulletin,27 (2). [38] Flesch, R.,1948,A New Readability Yardstick, Journal of Applied Psychology,32 (3):221-233. [39] Flor, M.,Klebanov, B. B. and Sheehan, K. M.,2013,Lexical Tightness and Text Complexity,Workshop of Natural Language Processing for Improving Textual Accessibility, [40] Hassan, M. K.,Abu Abbas, B. and Garas, S. N.,2019,Readability, governance and performance: a test of the obfuscation hypothesis in Qatari listed firms, Corporate Governance: The International Journal of Business in Society,19 (2):270-298. [41] Hellmann, A.,Yeow, C. and De Mello, L.,2017,The influence of textual presentation order and graphical presentation on the judgements of non-professional investors, Accounting and business research,47 (4):455-470. [42] Howard, J. and Ruder, S.,2018,Universal Language Model Fine-tuning for Text Classification,Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics,328-339. [43] Jin, T. and Lu, X.,2018,A Data-Driven Approach to Text Adaptation in Teaching Material Preparation: Design, Implementation, and Teacher Professional Development, TESOL Quarterly,52 (2):457-467. [44] Kate, R. J.,Luo, X. and Siddharth, P., et al,2010,Learning to Predict Readability using Diverse Linguistic Features,23rd International Conference on Computational Linguistics,546-554. [45] Kim, J. Y.,Kevyn, C. T. and Bennett, P., et al,2012,Characterizing web content, user interests, and search behavior by reading level and topic,ACM International Conference on Web Search and Data Mining,ACM,213-222. [46] Li, F.,2008,Annual report readability, current earnings, and earnings persistence, Journal of Accounting and Economics,45 (2-3):221-247. [47] Lively, B. A. and Pressey, S. L.,1923,A Method for Measuring the “vocabulary Burden” of Textbooks, Educational administration and supervision,(9):298-389. [48] Loughran, Tim and McDonald, Bill,2020,Textual Analysis in Finance, Annual Review of Financial Economics,(12): 357-375. [49] Lu, X. F.,2010,Automatic analysis of syntactic complexity in second language writing, International Journal of Corpus Linguistics,15 (4):474-496. [50] Luo, J.,Li, X. and Chen, H.,2018,Annual report readability and corporate agency costs, China Journal of Accounting Research,11 (3):187-212. [51] McNamara, D. S.,Crossley, S. A. and Roscoe, R. D., et al,2015,A hierarchical classification approach to automated essay scoring, Assessing Writing,(23):35-59. [52] Muslu, V.,Mutlu, S. and Radhakrishnan, S., et al,2019,Corporate Social Responsibility Report Narratives and Analyst Forecast Accuracy, Journal of Business Ethics,154 (4):1119-1142. [53] Nandhini, K. and Balasundaram, S. R.,2016,Improving Readability through Individualized Summary Extraction, Using Interactive Genetic Algorithm, Applied Artificial Intelligence,30 (7):635-661. [54] Schlkopf, B.,John, P. and Hofmann, T.,2006,TrueSkillTM: A Bayesian Skill Rating System,Advances in Neural Information Processing Systems 19: Proceedings of the 2006 Conference,MITP,569-576. [55] Schumacher, E.,Eskenazi, M. and Frishkoff, G., et al,2016,Predicting the Relative Difficulty of Single Sentences With and Without Surrounding Context,Proceedings of Conference on Empirical Methods in Natural Language Processing,1871-1881. [56] Seifzadeh, M.,Salehi, M. and Abedini, B., et al,2020,The relationship between management characteristics and financial statement readability, EuroMed Journal of Business. [57] Si, L. and Callan, J.,2001,A statistical model for scientific readability,Proceedings of the 2001 ACM CIKM International Conference on Information and Knowledge Management,ACM,574-576. [58] Smith, M. and Taffler, R.,1992,Readability and Understandability: Different Measures of the Textual Complexity of Accounting Narrative, Accounting, Auditing & Accountability Journal,5 (4):84-98. [59] Tanaka-Ishii, K.,Tezuka, S. and Terada, H.,2010,Sorting Texts by Readability, Computational Linguistics,36 (2):203-227. [60] Taylor,1953,“Cloze Procedure”: A New Tool For Measuring Readability, The Journalism Quarterly,30 (4):415-433. [61] Vajjala, S.,2017,Automated Assessment of Non-Native Learner Essays: Investigating the Role of Linguistic Features, International Journal of Artificial Intelligence in Education,28 (1):79-105. [62] Vogel, M. and Washburne, C.,1928,An Objective Method of Determining Grade Placement of Children’s Reading Material, The Elementary School Journal,28 (5):373-381. [63] Wang, Y X and Hebert, M. Learning from small sample sets by combining unsupervised meta-training with CNNs. in: Advances in Neural Information Processing Systems, 2016. [64] Wang, Y X,Girshick, R. and M, Hebert. Low-shot learning from imaginary data. in: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, 2018. [65] Yang, S.,1970,A Readability Formula for Chinese Language,University of Wisconsin-Madison. Is the Social Responsibility Information Disclosed By Listed Companies ‘Easy to Understand’? —Readability Quality Assessment and Empirical Research Based on Machine Learning Duan Zhao1,2, Zhou Hong1,2, and Zhou Hui1 (1.School of Information Management, Central China Normal University;2. Center for Corporate Social Responsibility, Central China Normal University) Abstract:Text readability is the premise and guarantee for the quality of information disclosure in the securities market. This paper attempts to provide a solution to the evaluation of the readability and quality of social responsibility reports released by the listed companies. Firstly, combined with the analysis of the motivation of information disclosure and reading behavior in the securities market, a two-dimension readability evaluation model based on the efficiency and adaptability level is proposed. Then, a method for assessing the readability of information disclosure text based on machine learning is designed and validated. And finally, the readability level of the full sample of social responsibility reports released by the Chinese listed companies from 2009 to 2017 is measured, while the overall and structural characteristics of the samples are analyzed. The results show that the readability level of social responsibility reports released by the listed companies in China is normally distributed and it increases year by year. The readability level of samples in different industries and years is significantly different, and the industry heterogeneity and external policy changes may be the main reasons for the differences. The model proposed in this paper provides a new way of thinking for the evaluation of the quality of information disclosure, and the evaluation method can effectively reduce the subjective interference in readability evaluation. At the same time, the research results provide a new set of quantitative data for the follow-up empirical research, and also provide new guidance for the supervision of information disclosure in the securities market. Key Words:information disclosure; corporate social responsibility report; machine learning; readability 責任编辑 郝 伟
