基于CNN-DBN的小麦不完善粒识别技术研究
2022-07-12张庆辉田欣欣吕鹏涛
张庆辉,田欣欣,吕鹏涛,杨 彬
1.河南工业大学 信息科学与工程学院,河南 郑州 450001 2.郑州市科学技术情报研究所,河南 郑州 450000
小麦不完善粒检测是小麦质量检验工作中最为普遍的技术问题之一。不完善粒是判断小麦品质的重要指标,深入研究小麦不完善粒检测技术,对于准确判断小麦品质具有重要意义[1]。目前,有关小麦不完善粒识别的方法共有3种。1)人工提取小麦特征并输入分类模型进行识别。张玉荣等[2]将提取的颜色、形态和纹理特征输入BP神经网络中,对5类小麦进行识别。张博[3]提取小麦的颜色、形态和纹理特征,使用ResNet模型进行分类,取得了良好的效果。这些方法需要人工提取小麦特征,但是人工提取所获得的特征往往过于特殊[4],不能很好地反映小麦的本质特征,而且提取过程复杂,操作困难。2)对图像进行特殊处理。采集小麦的高光谱图像并进行预处理,然后输送至分类模型进行识别。董晶晶等[5]采集小麦的高光谱图像,并将光谱特征和图像特征进行融合,使识别率得到了提高。于重重等[6]通过高光谱成像系统拍摄小麦的高光谱图像,然后采用黑白标定的方法对高光谱数据进行降噪处理,实现了小麦不完善粒的无损检测。这两个试验的图像预处理方法复杂、耗时且实用性差。从经济方面考虑,高光谱成像设备价格昂贵,相配套的检测设备成本也很高。3)对经典分类网络直接进行优化。郝传铭等[7]分别采集小麦的高分辨率图像和高光谱图像,然后将2种图像进行配准、融合,最终得到预处理图像。同时,在VGG-16模型中加入特征金字塔,提高了小麦识别率。贺杰安等[8]将增强后的6类小麦图像输送至含有批正则化(Batch normalization,BN)层的CNN中,取得了不错的分类效果。曹婷翠等[9]对3类小麦进行双面采集,将采集到的图像输送至含有空间金字塔池化(SPP)的CNN模型中。这些方法需要从神经网络第一层开始训练权重,因为用于小麦不完善粒识别的数据集规模通常较小,所以尽管对经典分类模型进行了优化,但识别效果仍然不太理想。
作者引入迁移学习思想[10-13],将基于大型公开数据集ImageNet的3个预训练模型作为小麦特征提取器,并对其提取的小麦特征进行融合。融合后的特征包含的信息更丰富,能更客观、真实地反映小麦的本质特征[14-18]。然后采用DBN模型对融合后的小麦特征进行分类,进一步挖掘图像的高层特征,以取得更优的分类效果。
1 原料与仪器
1.1 原料
样品采用河南中储粮质量检测中心提供的不同贮存时间和不同品质的小麦,从中挑选出完善粒和不完善粒(病斑粒、生霉粒、出芽粒、虫蚀粒、破损粒)。
1.2 仪器
图像采集平台:自主设计;计算机:戴尔股份有限公司;MV-CE200-10GC工业相机:杭州海康威视数字技术股份有限公司。
2 图像采集与数据集制作
2.1 图像采集
所采用的数据集由完善粒和5类不完善粒组成。小麦图像的采集通过抖动式自动上料盘、透明载物板和一对高清工业相机构成的自动图像采集设备完成,获取小麦的高清RGB图像,6类小麦图像如图1所示。
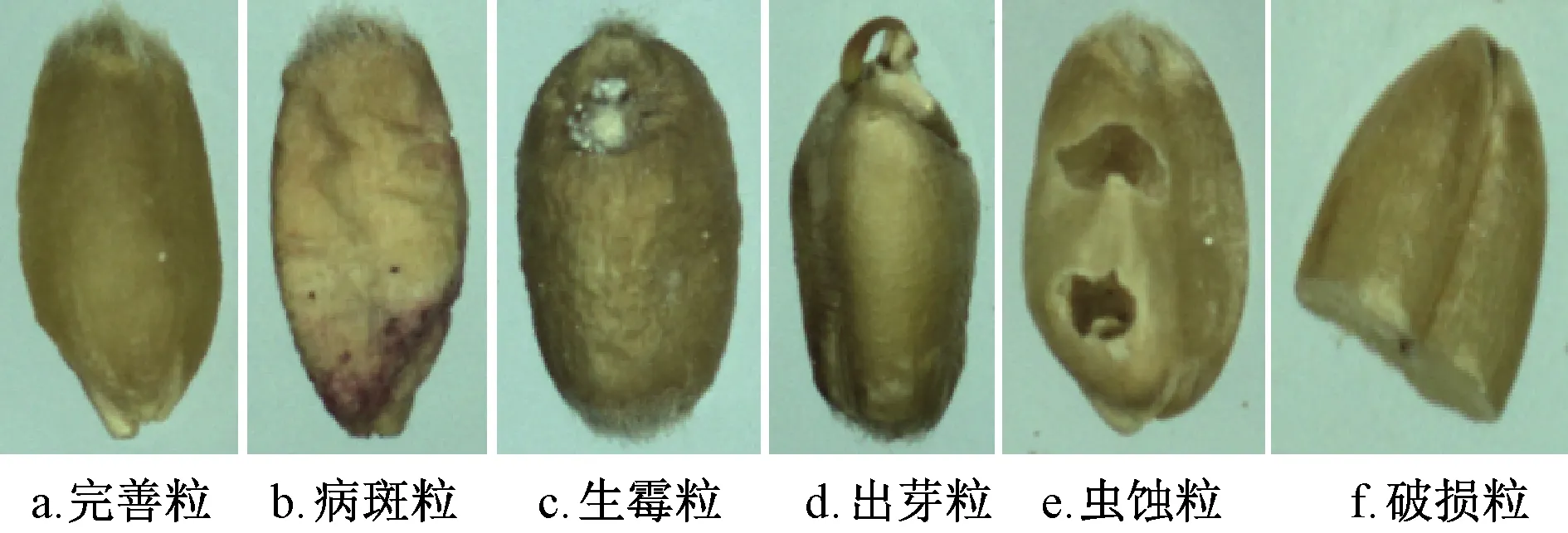
图1 6类小麦图像Fig.1 Images of six types of wheat
2.2 数据集制作
以彼此不粘连且平铺于一个平面中的多粒小麦为原始图像的采集对象,然后将原始图像分割为每张图片中仅有单粒小麦的图像。通过轮廓检测算法将多粒小麦图像分割为单粒小麦图像,以麦粒边缘所确定的矩形范围为界,向周边扩展3个像素后裁剪。
以分割后的单粒小麦图像为基础建立数据库。共采集6种小麦图像各2 782张,其中,2 000张作为训练集,400张作为验证集,382张作为测试集。
2.3 样本集扩展
实际应用中,因为采集图片时的光线效果无法保持绝对一致,所以难免会引入噪声。为此,通过改变亮度、引入高斯噪声的方法对单粒小麦的图像进行数据增强处理,图2是部分经过数据增强的小麦图像。每张随机选择1种数据增强方法将原图训练集由原来的每类2 000张扩展到每类4 000张。
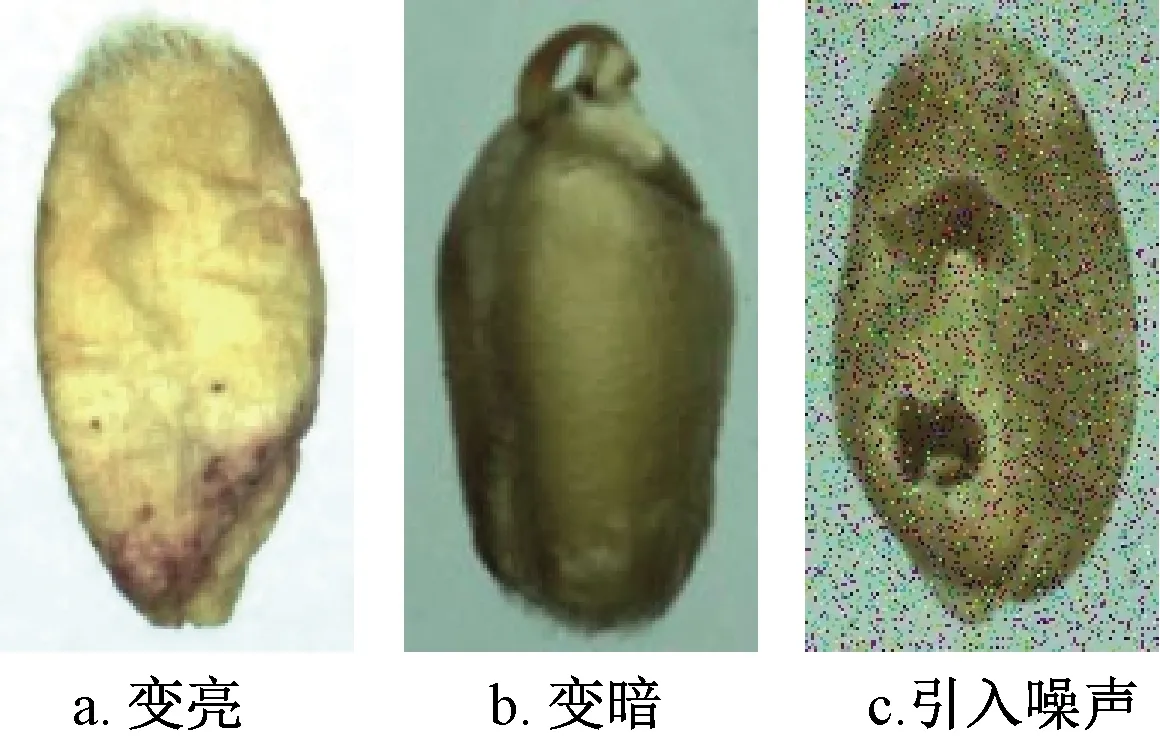
图2 数据增强后的小麦图像Fig.2 Wheat images with data enhancement
3 基于迁移学习的CNN-DBN模型
3.1 DBN神经网络
深度信念神经网络(Deep belief network,DBN)由Hinton等[19-20]于2006年提出,DBN是一个概率生成模型,由一系列的限制玻尔兹曼机 (Restricted boltzmann machine,RBM)堆叠组成。RBM 由可视层和隐藏层2层神经元组成,各层都包含若干个节点,层内节点之间没有连接,不同层之间的节点靠权值系数矩阵连接,可视层单元(v)和隐藏层单元(h)表示采用二进制:v∈{0,1}D和h∈{0,1}K,而D和K分别为可视层和隐藏层的单元序号。v和h的联合概率可表示:
(1)
式中:Z为一个归一化常量;RBM是一种能量模型;E(v,h)为一个能量方程,E(v,h)可表示:
(2)
式中:Wij为可视层节点vi和隐藏层节点hj之间的连接权重;I为可视层的神经元数目;J为隐藏层的神经元数目;ai,bj则分别为可视层、隐藏层的偏置值。
DBN由多个无监督的RBM和一个有监督的反向传播(Back propagation,BP)网络构成,如图3所示。其中,h(1)—h(3)代表隐藏层,W(1)—W(4)代表权重。

图3 DBN示意图Fig.3 Schematic diagram of DBN
3.2 Dropout算法
在参数过多而训练样本太少的情况下神经网络模型容易出现过拟合现象。为了防止过拟合,在模型中加入Dropout算法,它可以使一个神经元和随机筛选出来的其他神经元一起工作。深度神经网络的过拟合现象可以通过打破神经元的相互依赖而得到缓解。此方法减弱了神经元节点间的联合适应性,增强了泛化能力。未加入Dropout算法的神经网络的计算公式如(3)、(4)所示:
(3)
(4)

加入Dropout算法的神经网络的计算公式如式(5)—式(7)所示:
(5)
(6)
(7)
式中:r(l)为神经网络第l层的每个神经元所得到的值。
r(l)符合Bernoulli分布。加入Dropout算法的神经网络相当于在标准神经网络的每层中每个神经元的输出上乘以r。r=0时代表将此神经元断开连接,r=1时代表此神经元保持原有连接。公式(5)中引入Bernoulli函数,目的是以概率P随机生成一个0、1的向量。r=1的概率为P,r=0的概率为1-P。
在训练时,所有神经元都有可能以概率P被移除;因为在测试阶段每一个神经元都是存在的,所以权重参数W要乘以P,测试阶段的情况是:
(8)
3.3 加入Dropout算法的DBN模型
在训练的参数量较大但数据集规模并不大的情况下容易产生过拟合现象,从而造成模型的泛化性能不理想。为了避免过拟合现象出现,本文在靠近DBN尾端的输出层加入了Dropout算法,结果如图4所示。

注:虚线圆代表断开连接的神经元。图4 含有Dropout算法的深度信念网络Fig.4 Deep belief network with Dropout algorithm
3.4 CNN-DBN模型
在模型中引入了迁移学习算法,其实现流程是:保留基于大型公开数据集ImageNet的预训练模型的特征提取层,将原有的顶层去掉,替换为自主设计的顶层网络。在训练过程中,只训练自主设计的顶层网络。采用预训练模型进行小麦特征提取,并将所提取的特征输送至自主设计的顶层网络进行分类。
对小麦原图进行分割,CNN-DBN模型如图5所示。具体实现步骤:将含有多粒小麦的原图分割为只含有单粒小麦的单张图片,然后将单粒小麦图片输送至预训练好的VGG-16模型、VGG-19模型和ResNet50模型,VGG-16和VGG-19模型均提取出512维特征,ResNet50模型提取出2 048维特征;将3个模型提取出来的特征进行拼接,获得3 072维特征;将拼接后的特征输送至DBN中,调节DBN中的参数与结构使它的分类精度达到最优。
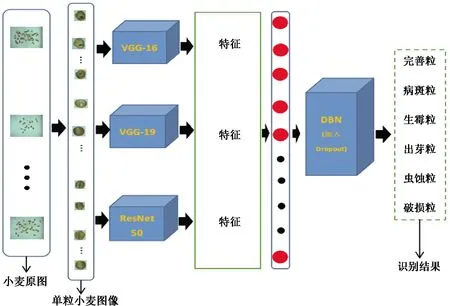
图5 CNN-DBN模型Fig.5 CNN-DBN model
4 试验设置及结果分析
4.1 试验设置
试验设计了非迁移学习模型、迁移学习单模型、双融合模型及三融合模型,采用14种神经网络模型进行分组试验,分类效果如表1所示。其中,前2组分别基于VGG-16和VGG-19模型;第3组和第4组对基于迁移学习的VGG-16神经网络模型进行试验,对比了隐藏层+softmax和DBN的分类效果;第5组和第6组对基于迁移学习的VGG-19神经网络模型进行试验,对比了隐藏层+softmax和DBN的分类效果;第7组和第8组将迁移学习模型VGG-16和VGG-19进行融合,对比了隐藏层+softmax和DBN的分类效果;第9组至第12组将迁移学习模型VGG-16和VGG-19以不同方式进行3个模型融合,对比了隐藏层+softmax和DBN的分类效果;第13组和第14组将迁移学习模型VGG-16、VGG-19和ResNet50进行融合,对比了隐藏层+softmax和DBN的分类效果。
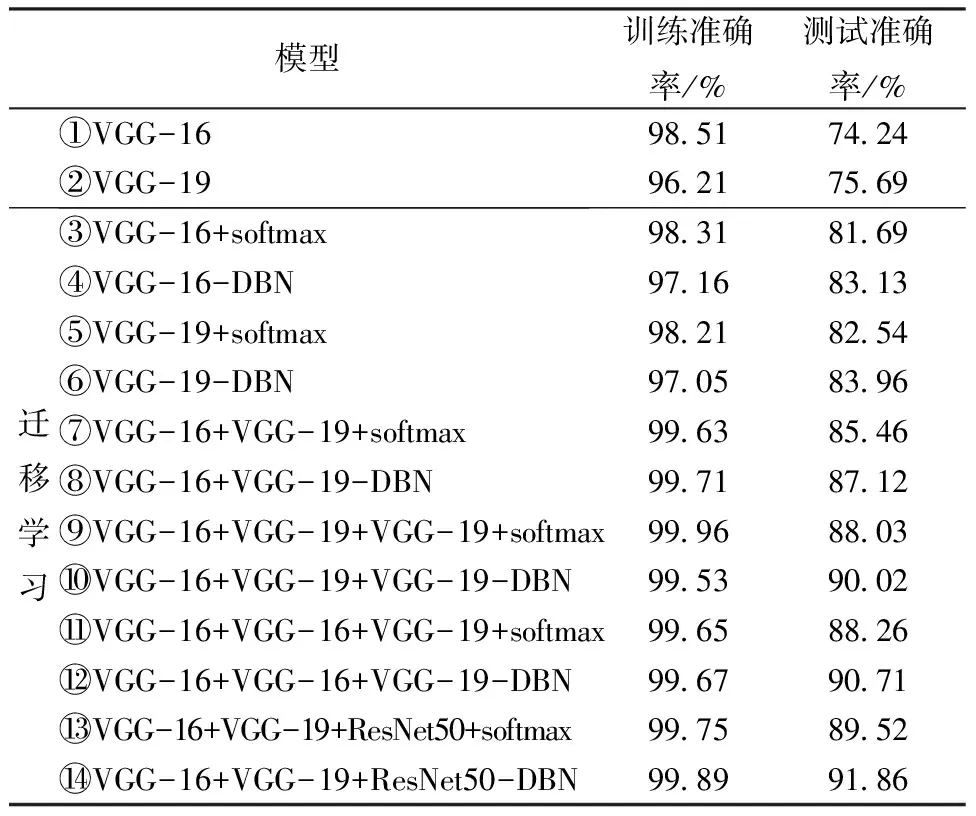
表1 14种分类试验效果Table 1 Fourteen groups of experiments
每种模型进行6次试验然后取平均值,均在具有64 GB RAM,Intel i7-6800 K CPU和NVIDIA TITAN Xp GPU的计算机上运行。试验基于Python语言,在Kareas框架下实现VGG-16、VGG-19和ResNet50。
DBN的隐藏层节点数为350-170-80,2个非迁移学习模型迭代50次,其他迁移学习模型试验均迭代30次,并设置Batch Size为16,Dropout为0.5,隐藏层的激活函数为sigmoid函数,输出层的激活函数为softmax函数,初始学习率为0.000 8,递减率为0.000 02。
因为迁移学习VGG-16+VGG-19+ResNet50-DBN 模型的识别效果最好,所以选择此模型执行本次任务,此模型迭代30次训练与验证的精度和损失变化如图6所示。
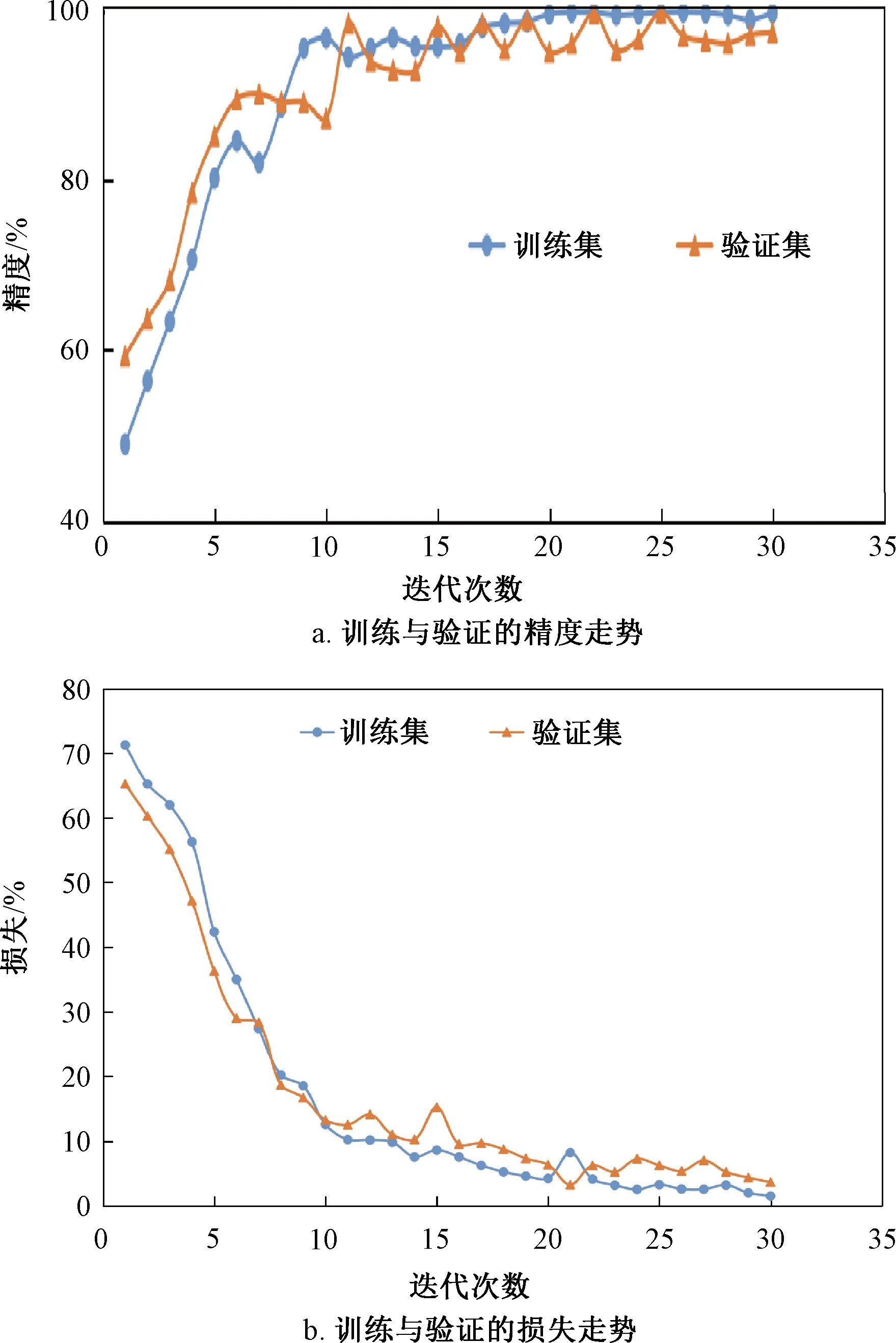
图6 迁移学习VGG-16+VGG-19+ResNet50- DBN 模型训练和验证的精度和损失Fig.6 Thirty iterations of transfer learning VGG-16+VGG-19+ResNet50-DBN model training and verification
4.2 结果分析
4.2.1 Dropout和softmax分类器的作用
选择Dropout为0.5,即训练时随机丢弃50%的神经元。Dropout算法虽然在避免过拟合方面有不错的效果,但是它的缺点是丢弃了一部分神经元而导致部分特征信息丢失。为了在缓解过拟合的同时尽可能避免丢失更多信息,在进行模型选择过程中,将2个相同模型进行了特征融合,如表1中第9组至第12组试验所示。此情况下使用Dropout算法既缓解了过拟合现象,又尽可能使保留下来的特征信息更多。因为2个相同模型提取的特征信息量是一个模型提取信息量的2倍,所以在随机丢弃50%的神经元之后,保留下来的小麦特征信息要比一个模型提取的特征信息更丰富。因此,两个相同模型进行特征融合得到的识别率更高。
若要将DBN应用在图像分类任务中,则需在网络的末层加入分类器。用softmax作为DBN神经网络最后一层的激活函数。softmax分类器需要处理的问题是:有一个训练样本集合X={x1,x2,……},样本xi表示为xi=(a1,a2,a3,……),样本集合X中的样本是类别C={c1,c2,c3, ……}中的一种,假设有一个测试样本x, 判断样本x属于哪种类别。softmax分类器将上一层的输出数据归一化,然后选取最大值所对应的结点作为预测结果。
4.2.2 不同模型对比
由表1可知,迁移学习模型比非迁移学习模型分类效果更好。迁移学习模型使用的是基于大型公开数据集ImageNet的预训练模型,其数据集规模较大,所以对此数据集之外的图片也有很好的泛化性能。迁移学习可以有效解决数据集规模小的问题。融合模型比非融合模型的分类效果更好。融合特征所包含的小麦特征信息更加丰富、全面。DBN的分类效果优于隐藏层+softmax。将融合后的特征通过DBN进行分类时,DBN可以进一步提取出小麦的深层特征。此外,DBN融合了无监督学习和有监督学习的长处,可以更好地挖掘小麦图像的规律,从而达到提高分类精度的目的。VGG-16+VGG-19+ResNet50-DBN融合了3种模型提取的小麦特征,分类效果优于双融合模型。3种模型提取比2种模型提取到特征信息更丰富,能更好地挖掘出小麦的本质特征。
4.2.3 P-R曲线(Precision-Recall Curve)分析
在实际应用中,精确率和召回率也是衡量小麦不完善粒识别模型性能的重要指标。将所有小麦分为完善粒和不完善粒两大类别,将阈值分别设定为0.0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0,在不同阈值下计算不完善粒的精确率(Precision)和召回率(Recall)。P-R曲线以召回率为横轴,以精确率为纵轴,6类模型的P-R曲线如图7所示。

图7 P-R曲线Fig.7 Precision-recall curve
由图7可知:迁移学习VGG-16+VGG-19+ResNet50-DBN模型在横轴和纵轴均为1的区域内,左下方面积最大,而且它将其他模型的曲线完全包裹住;与其他模型相比,在相同召回率的情况下,精确率高于其他模型;此模型在相同精确率的情况下,召回率高于其他模型。由此可见,迁移学习VGG-16+VGG-19+ResNet50-DBN模型相较于其他模型来说,能将更多的不完善粒识别出来。
5 结论
提出了一个基于迁移学习的CNN-DBN模型,以基于大型公开数据集ImageNet的预训练模型为特征提取器,然后将所提取特征进行融合并输入DBN网络实现了小麦不完善粒的识别。通过对比14种分类试验效果,发现迁移学习VGG-16+VGG-19+ResNet50-DBN模型比其他模型测试准确率更高,可达91.86%,能将6类小麦更准确地分类。另外,其P-R曲线均优于其他5类CNN-DBN模型,表明此模型能将更多的不完善粒挑选出来。因此,迁移学习VGG-16+VGG-19+ResNet50-DBN模型的性能最好。
这项研究共有3个意义:1)提出了CNN-DBN模型并引入了迁移学习方法。使用基于大型公开数据集的预训练模型作为小麦特征提取器,解决了因数据集规模小而导致小麦不完善粒识别率不理想的问题。2)所提方法简化了小麦预处理过程。现有小麦图像在输入分类器之前要经过复杂的图像预处理过程,如获取小麦的高光谱图像、人工提取特征等,这些方法不但步骤烦琐,而且实用性较差。而本文中小麦图像预处理过程只需增强数据。3)将有监督方法和无监督方法结合并运用到小麦不完善粒识别任务中,为小麦不完善粒识别的应用提供了一种新的技术途径。
