基于LightGBM 的在线磁盘故障预测模型
2022-07-11田烜瑜汪旭杰史恩泽陈思奇
田烜瑜 汪旭杰 史恩泽 陈思奇
(1.中国民航大学计算机学院 天津市 300300 2.中国民航大学安全科学与工程学院 天津市 300300)
为了在互联网上传递、加速、展示、计算、存储数据信息,数据中心应运而生,并在全球蓬勃发展,而磁盘故障的出现对数据中心的可靠性和可用性造成了很大的影响,严重降低了存储系统的可靠性。对于这一问题,本文计划基于LightGBM 算法设计在线磁盘故障预测模型,预测未来一周至两周内将出现故障的磁盘,从而提醒用户提前备份危险磁盘上的数据,避免数据丢失。本文所提的故障预测模型具有较高的预测准确率,并适用于大规模数据中心。
本文重点解决了下述三个问题:
(1)在线样本标记问题。在离线学习过程中,由于已经充分了解到磁盘的状态(是否发生故障),可以很容易的对样本进行标记;而在线学习过程中,磁盘状态(是否会故障)很难确定,无法对新生成的样本进行实时标记。为此,我们提出一种自动的样本标记方法:首先将到来的磁盘样本数据暂存,并设定暂存时间窗口为t。在t 时间内如果有磁盘发生故障,则将之前暂存的该磁盘的样本都标记为负样本,对于t 时间内没有发生故障的磁盘,将其暂存的样本都标记为正样本,新标记的数据用于模型更新。
(2)样本不平衡问题。故障磁盘和正常磁盘之间存在着高度的不平衡,这是因为磁盘故障是一个相对罕见的事件,故障磁盘只占样本的很少一部分,而样本不平衡会造成分类模型产生很严重的偏向性。对此本文采用改变样本权重的方法来解决样本不平衡问题,通过增大正样本权重,从而间接降低负样本权重。
(3)在线学习问题。具体而言,模型的在线学习就是增量学习,增量学习指一个学习系统能不断地从新样本中学习新的知识,并能保存大部分以前已经学习到的知识。本文在当前决策树的基础上增加新的决策树,而原来的决策树保持不变,从而实现模型的增量更新。
1 相关工作
为了减少磁盘故障带来的损失,降低维护成本。目前,传统存储系统通常采用RAID 技术(即独立磁盘冗余阵列技术)或副本机制来避免由于磁盘故障而导致的服务中断。在发生设备故障时,系统利用冗余数据重构故障数据,使用这种“被动容错”机制保障系统和服务的可用性。然而随着存储系统规模的扩大,磁盘故障频率不断增加,这种“被动容错”机制无法很好地保障系统的可靠性。与之对比的是“主动容错”机制:SMART(Self-Monitoring, Analysis and Reporting Technology)技术通过在磁盘硬件内的检测指令对磁盘的硬件(如磁头、盘片、马达、电路)的运行情况进行监控、记录并与厂商所设定的安全值进行比较,若监控到运行情况将超出或已超出预设安全值的安全范围,就通过主机的监控硬件或软件自动向用户做出警告,并将危险磁盘上的数据提前迁移到其他健康磁盘,以保障磁盘数据的安全。这种方法简单易行,但是磁盘供应商为了保证低误报率,通常将阈值设置的比较严谨,导致故障检出率只有3%-10%,不能满足系统可靠性的要求。
为了进一步提高磁盘故障预测的精度,国内外科研人员基于大量磁盘SMART 数据和故障磁盘数据,采用统计分析和机器学习方法来训练磁盘故障预测模型。这些模型在故障磁盘预测方面表现出色,让用户可以对故障风险较大的磁盘进行提前更换,从而提高了系统的可靠性。早期Hamerly 和Elkan运用统计学中贝叶斯方法在来自昆腾公司的数据集上测试,得到 55%的故障检测率(Failure Detection Rate,FDR)和0.82%的故障误报率(False Alarm Rate,FAR)。Hughes等人提出两个改进的智能算法,他们利用秩和检验对磁盘故障进行预测。在来自两种不同公司提供的3744 个磁盘(36 个故障)上进行预测,结果表明他们的算法在0.5%误报率的情况下,故障检出率为60%。Zhu 和Wang等人探索了反向传播(BP)神经网络模型,开发了一个改进的支持向量机(SVM)模型,使用23395 个磁盘真实数据来验证模型,BP 神经网络模型在保持合理的低FAR 的同时,故障检出率明显提高,高达95%。国防科技大学胡维探索了利用机器学习理论预测磁盘故障的新方法,进一步提高预测的准确性,降低误报率,增强实用性。
随着对磁盘故障预测关注度和投入力度的深入和提高,基于磁盘故障预测的研究方法由传统的统计学习方法转变为机器学习方法。但上述方法都是在离线模型的方式下进行预测,虽然具有很好的预测性能,但是离线模型没有考虑到SMART 属性随着时间的动态变化,且不易于拓展到大数据场景,模型易老化,同时,由于离线模型对磁盘的预测与时间关系不够密切,可能会造成一个磁盘还有很长的寿命,但是因为被标记为故障磁盘而被替换,导致磁盘的利用率低,经济成本提高。本文基于LightGBM 算法对磁盘是否会发生故障进行在线预测,为磁盘维护提供决策参考。
2 LightGBM模型分析
梯度提升决策树(GBDT)是一种流行的机器学习算法,其主要思想是利用弱分类器迭代训练得到最优模型。基于此算法有许多有效的实现,如XGBoost 和pGBRT 等,这些工具虽然都是在GBDT的基础上进行优化,但是当特征维度高、数据规模大时,它们的效率和可伸缩性仍然不能令人满意。同时,作为GBDT 的代表模型,XGBoost 具有较大的时间开销,在遍历树中的每一个分割点的时候,都需要进行分裂增益的计算,消耗的计算代价和时间代价都比较大。
为了解决这个问题,2017 年微软发布了LightGBM 模型,提出两种新的技术来解决以上问题:单边梯度采样(GOSS)和互斥特征捆绑(EFB)。GOSS 区分具有不同梯度的实例,保留具有较大梯度的实例并对较小梯度采用随机采样的方式来减少计算量,从而达到提升效率的目的。EFB 通过采用特征捆绑的方式减少特征维度,来提升计算效率。
同时LightGBM 模型为了减少分裂点的数量,采用了基于直方图的算法,其基本思想如下:将连续的浮点特征值离散为k 个整数(即分桶bins),并根据特征所在的bin 对其进行梯度累加和个数统计;在遍历数据时,根据离散化的值索引寻找bin,累积数据;遍历一遍数据后,直方图积累了一定的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
在多个公共数据集上的实验表明,LightGBM 将传统GBDT 模型的训练速度提升了20 多倍,同时保持预测精度不变。
3 特征工程和特征选择
3.1 数据来源
本文所使用的数据来自于Backblaze 公司,包含了 2020年 1 月至 2021 年 12 月总共 8 个季度的磁盘运行记录。其中,2020 年1 月至2020 年12 月的数据用于离线模型的训练,2021 年1 月至2021 年6 月的数据用于在线模型的训练,2021 年7 月至2021 年12 月的数据用于模型的测试。上述数据集包含的信息有磁盘运行时间、磁盘序列号、磁盘型号、磁盘容量、故障标记和510 个SMART 属性特征值,其中SMART 的原始特征值有255 个,SMART 的标准特征值有255 个。由Backblaze 公司提供的磁盘年度故障表可知,ST12000NM0007 型号的磁盘数量总量和故障的磁盘数量最多,因此本文选择ST12000NM0007 型号的磁盘数据作为本文的实验数据。表1 对本文所采用的实验数据进行了说明。

表1:实验数据说明
3.2 数据处理
数据的预处理操作对于提高模型的预测性能至关重要,可以避免模型受到噪声、缺失值和不一致数据的侵扰。本文通过缺失值处理、数据提取和特征选择操作,构造出高质量的训练数据,提高了模型的预测性能。
3.2.1 缺失值处理
原始数据记录的SMART 属性共有510 个,但其中大部分属性的特征值为空值,示例如图1 所示。这些空值数据对磁盘故障的预测没有任何帮助,而且会增加磁盘故障预测的故障率和运行效率,因此本文剔除了全部为空值的SMART属性。剔除的SMART 属性为smart_2、smart_6、smart_8、smart_11、smart_13—smart_186、smart_189、smart_191、smart_196、smart_201—smart_239、smart_243—smart_255,共计131 个SMART 属性。另外,对于缺失值较少的属性,本文采用0 填补其缺失值。

图1:原始数据的SMART 特征属性示例
3.2.2 数据提取
此时样本数据还是分散的且存在一些混乱数据,对磁盘预测的准确率产生一定的负面影响。因此本文按照磁盘序列号提取数据,将正常磁盘和故障磁盘分别存储,同时将正常磁盘和故障磁盘中的混乱数据剔除。正常盘磁盘的混乱数据是指:最后一天的failure 值为0,而之前的样本中存在failure 值为1 的数据;故障磁盘的混乱数据是指:最后一天的failure值为1,而之前的样本中也存在failure值为1的数据。图2 为正常磁盘的混乱数据样例,虽然磁盘ZCH059KN 当前处于正常运行的状态,但是其在前期出现过故障标识(第五列的failure 值为1),所以将其从正常磁盘中剔除。

图2:正常磁盘的混乱数据示例
3.2.3 特征选择
在SMART 数据中,每一项都由两种数值形式予以展现,分别为normal value 和raw value。其中raw value 是该项记录的原始值,normal value 是把原始值经过标准的规整计算,得到的一组数值范围为0 到255 的一个数值。因为原始值可以更敏感的感知到磁盘状态的变化,所以本文在训练过程中更多地使用raw value。
目前,对于特征选择方面的研究主要包括三类:基于特征子集评价策略的特征选择算法、基于搜索策略的特征选择算法、和基于不同监督信息的特征选择方法。本文采用基于特征子集评价策略的特征选择算法中的嵌入式特征选择方法,嵌入式特征选择是将特征选择过程与学习模型的训练过程联系到一起,从训练结果中得到各个特征的权值系数,根据系数选择特征。LightGBM 算法采用两种计算特征重要性的方法:“gain”,表示 使用这些特征分割的总增益;“frequency”,表示使用该特征的次数。
本文结合“gain”和“frequency”两种方法来计算特征的重要性得分,同时参考特征的实际意义,进行特征属性的选择。通过“gain”计算方法,权值系数排在前二十的特征属性如图3 所示,通过“frequency”计算方法,权值系数排在前二十的特征属性如图4 所示。结合两种计算方法和特征的实际意义,本文最终选取了12 个特征属性,如表2 所示。
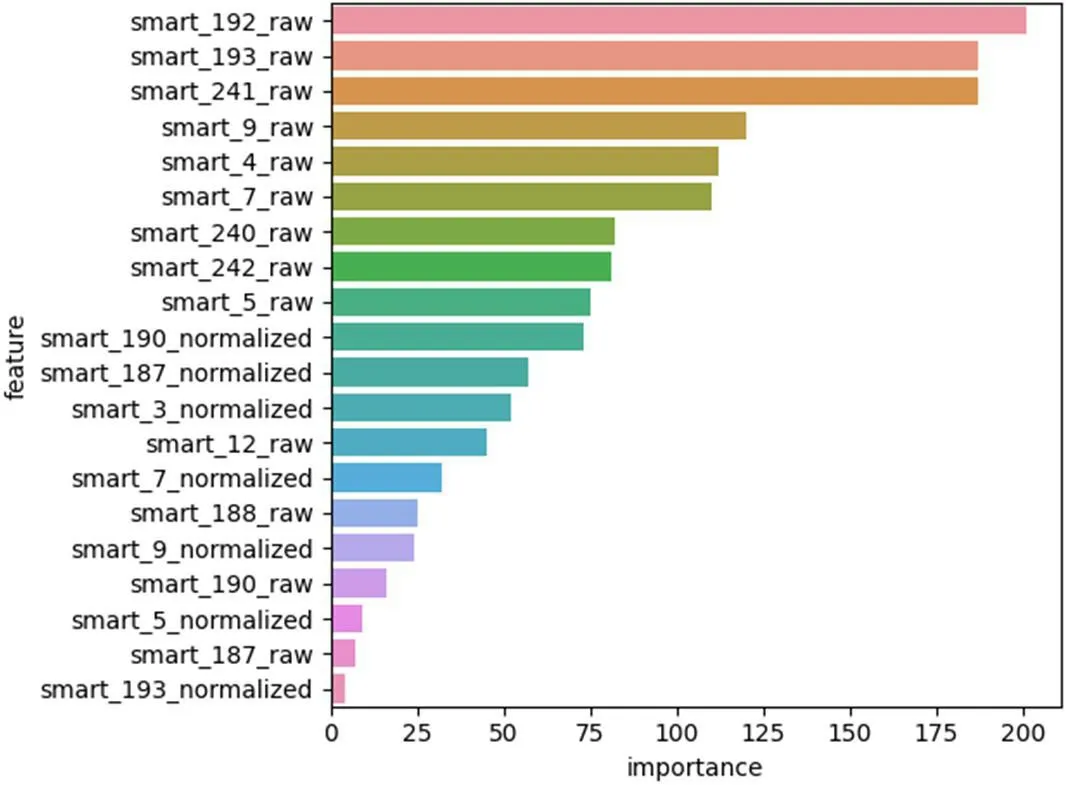
图3:importance_type='split'时权值系数前二十的特征
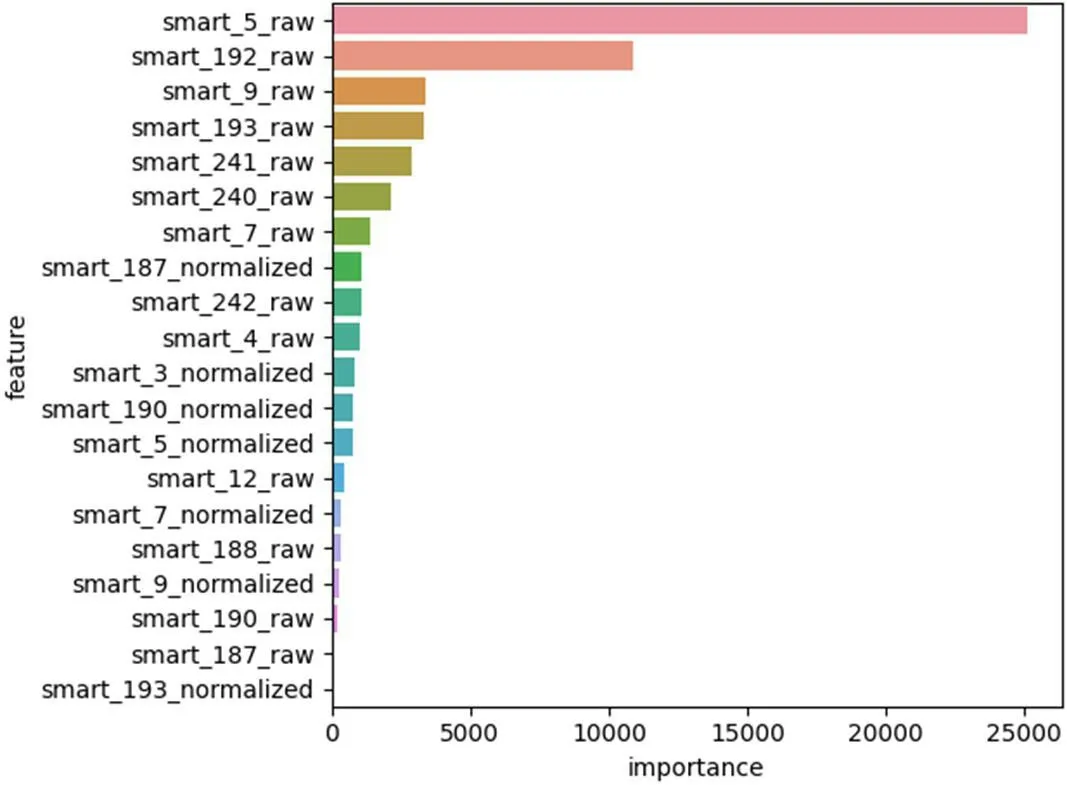
图4:importance_type='gain'时权值系数前二十的特征

表2:选取的12 个特征
4 在线模型的构建
实现在线磁盘故障预测模型需要在离线模型的基础上进行增量学习,本文先通过已标注的历史数据集构建出基础模型,然后再对实时产生的数据样本进行在线标注,最后利用新数据样本增量更新基础模型,实现磁盘故障的在线预测。
4.1 基础模型构建
4.1.1 数据选择
本文选择2020 年1 月-2020 年12 月四个季度的数据进行离线模型训练,得到基础模型。该训练数据集包含从正常运行的健康磁盘数据中随机抽取的连续七天的数据样本(总共有258412 条数据样本),和从故障盘数据的最后一天向前取的七天数据样本(总共有2304 条数据样本,其中两条数据因异常而去除)。将故障盘的数据样本的failure 值全部改为1,作为负样本。
4.1.2 样本不平衡处理
由于出现故障磁盘是一个小概率事件,因此故障磁盘数据与正常磁盘数据的训练样本数量差距很大,如果不处理就进行训练会严重影响模型精度,对故障磁盘的预测性能非常差。
处理样本不平衡问题,可以采用保留比例小的样本数据和减少比例大的样本数据来平衡两者的比例,但这种方法可能会丢失一些重要信息而导致欠采样。因此本文采用改变权重的方法来处理样本不平衡问题,把正样本权重设置为:正样本权重=负样本数量/正样本数量,从改变模型的目标函数出发,增大正样本权重,从而间接降低负样本权重,让分类器更多的关注正样本。通过该方法减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型。
4.1.3 参数优化
训练模型过程中,除了应用LightGBM 的重要参数外,本文还选取了LightGBM 中的colsample_bytree:特征的随机取样(来加速训练及处理过拟合);subsample:LightGBM将会在每次迭代中在不进行重采样的情况下随机选择部分数据(来加速训练及处理过拟合);min_split_gain:执行节点分裂的最小增益(防止树过深,处理过拟合);min_child_samples:叶节点样本的最小数据量(使叶子节点的数据分布相对稳定,提高模型的泛化能力)。通过网格搜素和交叉验证的方法进行参数调优,参数的设置如表3 所示。
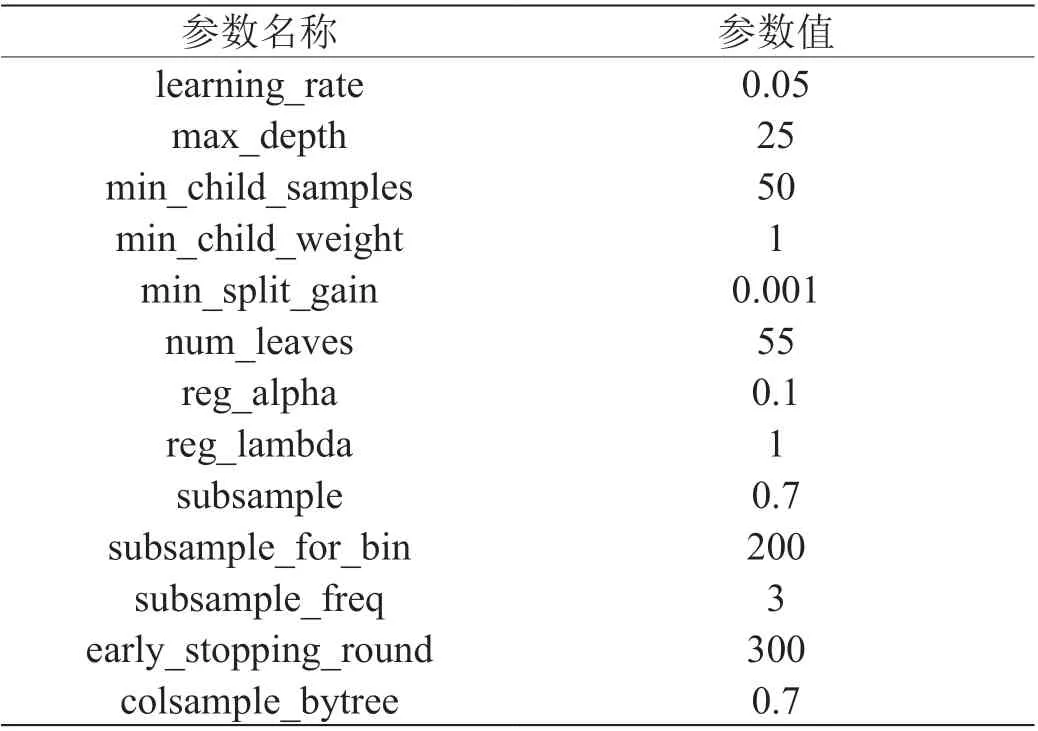
表3:LightGBM 主要参数设置
4.2 训练样本的在线标注
4.2.1 数据选择
在线模型的训练数据我们选择的是2021 年上半年的数据,为了模拟真实的在线过程,本文选择七天为一个周期,将七天的数据聚合成为一个训练样本,示例如图5 所示。

图5:训练样本示例
4.2.2 在线样本标记
对于离线模型的样本数据,其磁盘状态已经确定,很容易进行样本标记。而对于在线样本数据,由于其磁盘的状态不确定,如果直接将样本数据标记为正常磁盘,那么若是磁盘在近期发生故障,这些标记就会成为标记噪音,同时也不能直接标记为故障磁盘,因为只有当故障真实发生之后,其之前的样本才能标记为故障磁盘。因此,本文提出了一种新的在线样本标记方法,具体步骤如下:
(1)样本数据A 到来,暂存;
(2)检查A 中是否有故障磁盘,如果有则将相同序列号的故障磁盘的failure 值全部改为1;
(3)新的样本数据B 到来,检查其中是否有故障磁盘,如果有则将磁盘序列号传给A;
(4)修改A 中对应序列号的磁盘数据,将其failure 值改为1;
(5)将样本数据A 移除暂存队列,用于模型更新,将样本数据B 暂存并重复以上步骤。
4.2.3 更新模型
实现在线磁盘故障模型,即在离线模型的基础上使用新的样本来更新模型,以避免模型老化,实现在线故障预测。具体来说,就是在当前迭代树的基础上增加新的决策树,而原来的决策树保持不变。通过对LightGBM 算法的分析研究,我们发现LightGBM 存在对外的Python API 接口,通过设置其参数init_model,可以继续训练LightGBM 模型或Booster。本文在完成离线模型的训练后,将其存储为gbm,更新模型时加载gbm,同时设置init_model=gbm,从而实现在线模型。
4.2.4 评价结果
磁盘故障预测实际是一个二分类问题,磁盘样本的预测结果有两种,正样本(P)和负样本(N),坏盘的样本为P,好盘的样本为N,对其预测结果可能是正确(T),也可能是错误(F)。因此,磁盘故障预测结果有四种:TP、FP、FN、TN。其中TP 是正确的正样本预测,即把坏盘的样本预测为坏盘。FP 是错误的正样本,即把坏盘样本预测为好盘。FN 是错误的负样本,即把好盘样本预测为坏盘。TN 是正确的负样本,即把好盘样本预测为好盘。磁盘故障预测的评价指标是经过以上四种结果计算出来的。
FDR 定义为故障检出率,表示所有测试磁盘中坏盘被预测为坏盘的比例,公式如下:
FDR=TP/(TP+FN)
FAR 定义为故障误报率,表示所有测试磁盘中好盘被预测为坏盘的比例,公式如下:
FAR=FP/(TN+FP)
经计算离线模型的FDR 为85.59%,FAR 为1.33%。随着样本数据的增加在线模型的预测性能发生波动,如图6 所示。总体的FDR 维持在75%以上,且FAR 不超过5%,符合预测系统对性能测试的需求。
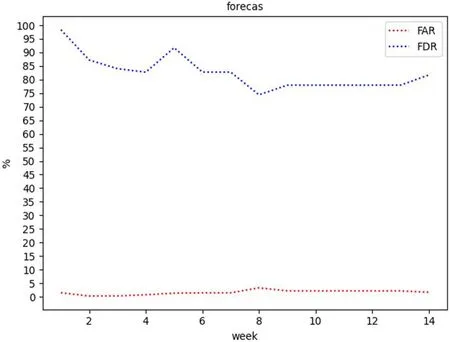
图6:实验结果
5 结语
在如今信息化时代,社会的方方面面越来越依赖数据,而磁盘作为数据的存储器,提高其可靠性对于保障数据安全具有重大意义。本文提出的基于LightGBM 的在线磁盘故障预测模型,在保障误报率较低的情况下,实现较高的故障检出率,同时该模型可以根据新来的样本数据进行实时更新,适应SMART 属性随时间的动态变化,摆脱模型老化问题。
在未来研究中,本文将考虑增大样本的数量,同时选用不同磁盘生厂商的数据集,以提升模型的鲁棒性。另一方面,由于时间限制,在模型参数调优方面,本文选取的参数粒度较大,同时LightGBM 的参数众多,本文只选取了其中一部分,未来可以选取更多参数,使用更小的调参力度,以得到预测性能更好的模型。同时,还可以考虑使用其他模型进行在线学习,进一步提升预测模型性能和稳定性。
