基于机器学习的表层土壤成矿元素空间预测:以稀有金属铷元素为例
2022-07-09戴亮亮聂小力吴欢欢汤媛媛彭志刚
戴亮亮,聂小力,郭 军,巩 浩,吴欢欢,张 涛,汤媛媛,毛 聪,彭志刚,贺 灿
(1.中国地质调查局 长沙自然资源综合调查中心,湖南 长沙 410600;
2.中国地质调查局 西安矿产资源调查中心,陕西 西安 710000)
0 引 言
随着计算机技术和人工智能算法的进步,大数据在传统行业获得了巨大成功,并形成了“互联网+”的经济社会发展新形态[1]。相比于其他传统领域,大数据在地学领域特别是地球化学领域研究相对滞后,相关研究成果缺乏[2]。在中国知网检索“地球化学”关键词(2021年5月18日)可以得到将近17万条文献记录,而以“大数据+地球化学”为关键词检索,仅能得到约160条文献记录,相比于2018年4月20日增加了120篇文献[3],文献增量相对较少,在国际主要数据库进行类似检索结果也相差无几,这表明拥有海量定量数据的地球化学领域对大数据的研究屈指可数,急需加强大数据的相关研究。
大数据是基于数据的科学[4],从数据本身出发,通过对这些含有意义的数据进行专业化处理,挖掘数据间的规律和相关关系,进而发现传统科学方法难以发现的新认识和新规律[5]。近两年,随着地质信息化建设和大数据智能地球科学的快速发展[6],大数据正在成为地球科学领域新的爆发点,取得了一系列新的成果与认识[7-8],如基于大数据分析的大地构造环境的判别[9-15],基于大数据和机器学习地球化学异常信息的提取和对比研究[16-17],基于机器学习的微量元素定量预测[3,18],大数据在矿产资源预测与评价领域中的应用[19-23],由此可见大数据对于地球科学的核心价值就在于分类和预测。我国自1999年开始实施土地质量地球化学调查工作以来[24-25],在岩石、土壤、农作物和灌溉水方面积累了大量的定性定量数据[26],但受限于调查的尺度,土壤样品分析测试的指标有很大的差异,1∶250 000土地质量地球化学调查要求分析表层土壤样品54项指标,主要服务于农业种植、生态环境和矿产资源等方面[27],但调查的精度无法精细化指导矿产勘查工作,1∶50 000土地质量地球化学调查在1∶250 000的基础上开展工作,但测试的指标以服务农业种植和生态环境为主[28],由于经费的限制,很少涉及金属矿产元素,进而导致了大比例尺的表层土壤调查出现了一定的矿产元素数据缺失。同一区域的1∶250 000表层土壤样品和1∶50 000表层土壤样品具有相同的采样介质、成土母质背景和表生地球化学过程,因此我们希望以同一区域1∶250 000测试指标建立一个预测模型,对1∶50 000大比例尺表层土壤未测元素指标含量进行空间预测,来补全1∶50 000土地质量地球化学调查数据库中缺少的矿产元素含量,服务于矿产资源勘查。
本文将以罗山地区表层土壤地球化学元素指标为研究对象,运用机器学习随机森林方法,立足对表层土壤地球化学元素间相关关系的挖掘,重点探讨由表层土壤的已知元素含量预测Rb元素含量的过程和结果,为机器学习算法在地球化学元素空间预测和进一步拓展土地质量地球化学数据的服务应用维度提供借鉴。
1 材料与方法
1.1 数据集
本文研究的罗山地区1∶250 000表层土壤数据(2 548组数据)来源于全国地质资料馆,具有54项指标含量值,该样品基本采样密度为1个点/km2,采样深度为0~20 cm,4 km2内的4个子样组合成1个分析样,样品元素含量的测定均由具有相关测试资质的实验室完成,严格按照《DZ/T 0258—2014多目标区域地球化学调查规范(1∶250 000)》[27]进行质量控制。罗山地区1∶5万表层土壤数据为2020年实测(1 761组数据),具有17项指标含量值,采样深度为0~20 cm,样品空间分布相对均匀,平均采样密度为9个点/km2,样品采集充分考虑地块代表性,在每个样点的20~50 m范围内采集4~6个子样,充分混匀后采用四分法获取约1.5 kg土壤装入样品袋中,待样品自然风干后过2 mm(10目)尼龙筛,均匀获取500 g送实验室分析测试,样品野外处理及加工严格执行《DZ/T 0296—2016土地质量地球化学评价规范》[28]。
1.2 变量遴选和研究方法
1∶5万表层土壤具有17种元素指标(Se、B、As、Hg、V、Cr、Mn、Co、Ni、Cu、Zn、Mo、Cd、Pb、pH、K、P)的数据,由于预测变量较多,为了提高预测的精度,防止过拟合,需要根据每个预测变量对预测结果的重要程度来对预测变量进行优选,确定最佳的预测变量集。变量的漏选会导致关键信息丢失,降低模型的准确度,使模型无法准确描述变量间的复杂关系,而多余的预测变量又会增加模型的复杂度和学习难度,同时也会将噪声引入建模过程中,进而导致模型过拟合,降低泛化能力[29-31]。因此需通过变量的重要性度量对变量进行优选,留下对预测结果影响最大的变量集,随机森林中常用的变量重要性度量计算方式主要有基于基尼指数(GI)和袋外数据错误率(OOB)[32-33],本文选择基尼指数来计算出所有变量的重要性评分,因为其在评价地球化学元素含量这种连续性变量时具有更好的稳定性[34]。本文变量遴选的方法主要分为两步,第一步对所有变量进行变量重要性度量并进行排序,第二步采用机器学习中常用的学习曲线来确定最优的预测变量数量,其原理是根据预测变量的重要性度量从高至低累计选取预测变量进行建模,对模型的拟合优度和均方根误差进行对比,进而确定最优的预测变量数量。
随机森林算法是一种用随机方式建立的,以决策树为基学习器构建的集成学习算法[35],且每个决策树之间都是相互独立的,其输出的结果是由每个决策树输出结果的众数(分类)或整体平均(回归)而定[36-37],使得整体模型的结果具有较高的精确度和泛化性能。近些年,随机森林算法由于其强大的性能,已经成功地应用到各领域的多种预测模型之中,被誉为“代表集成学习技术水平的方法”[38-39]。相比于其他机器学习建模算法,随机森林算法具有一些明显的优势[40-41],主要体现在:①实现简单,训练可以高度并行化,特别是对于大样本的地球化学海量数据具有明显的速度优势;②能处理高维数据(多个元素指标),具有较强的抗过拟合能力;③通过训练,可以准确获取元素间的相互关系,给出各个特征对于输出的重要性度量;④随机采样的过程,使训练出的模型的方差小,泛化能力强;⑤对数据集的适应能力强,既能处理离散型数据,也能处理连续型数据,数据集无需规范化[42]。因此,把随机森林算法应用于地球化学元素空间预测研究具有很好的契合性。如前面所述,随机森林模型是由一棵棵决策树组成,一般来说决策树的数量越多,建模的结果往往越好,但当决策树数量达到一定值后,随机森林模型的精确性往往不再上升而是开始上下波动,并且决策树越多,模型会越复杂,训练时间也会越长。为了平衡建模效果和模型复杂度,本文通过构建学习曲线来拟合决策树数量和建模效果的关系(图1)。如图1所示,当决策树数量为150棵时,模型具有较低的复杂度,同时也具有较好的建模效果。

图1 随机森林决策树的数量对模型拟合优度和均方根误差的影响Fig.1 The influence of the number of random forest decision trees on the model’s goodness of fit and root mean square error
2 结果与讨论
2.1 变量选择结果
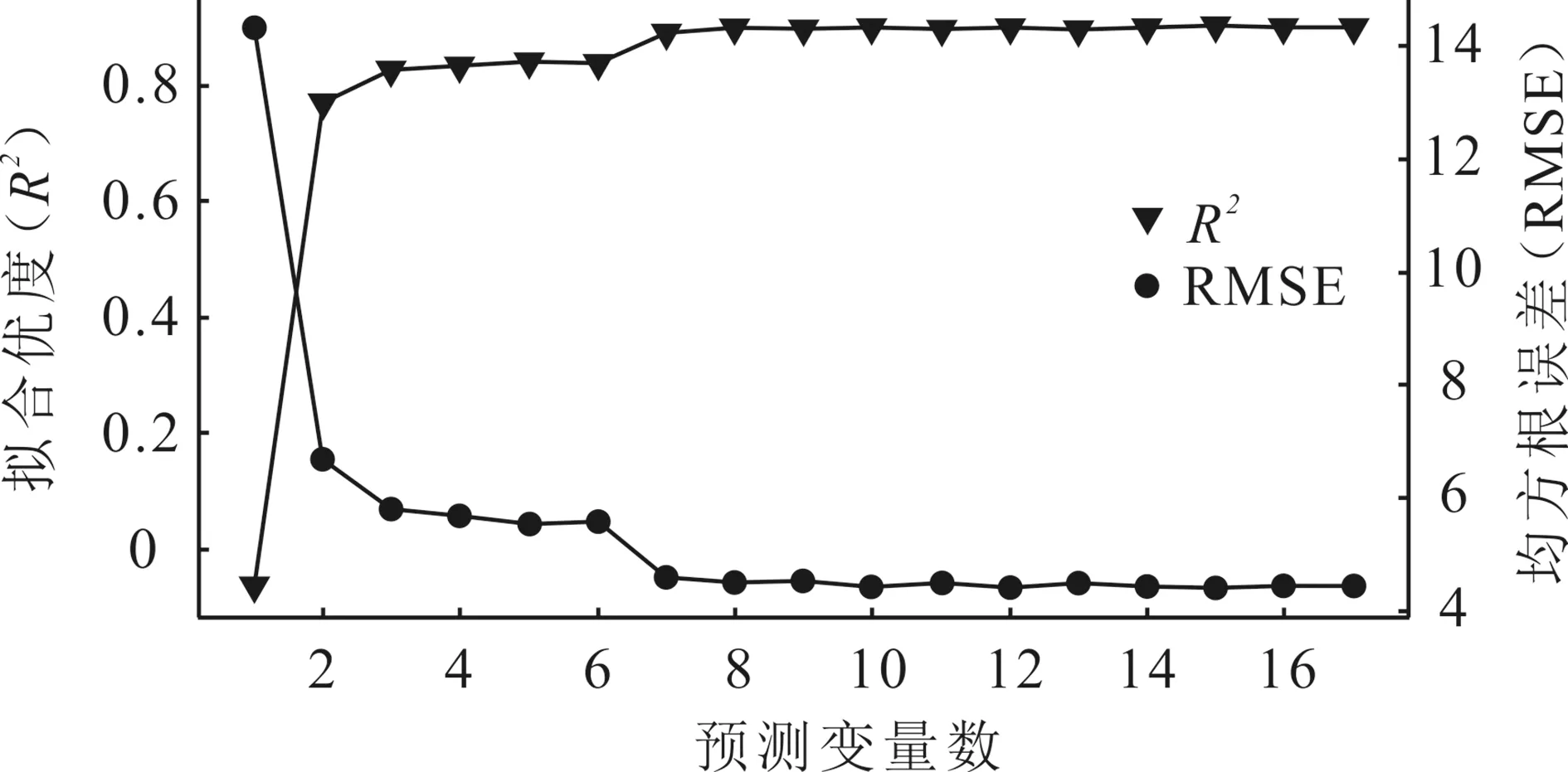
图2 预测变量数量对模型拟合优度和均方根误差的影响Fig.2 The influence of the number of predictors of the model on the goodness of fit and the root mean square error
本文用于变量遴选的学习曲线是一条预测变量数作为横坐标、预测模型的拟合优度和均方根误差作为纵坐标的曲线(图2),其中对全部数据(2 548组)进行变量重要性度量是利用Python随机森林模块的内置函数实现。由图2可知,当预测变量在4个以下时,模型的效果随着预测变量的增加有着巨大提升,说明此时模型处于欠拟合状态,当选取重要性度量最高的8个预测变量时,模型既可以具有较好的拟合优度和较低的均方根误差,又具有较低的模型复杂度,具有较高的计算效率,因此本文选取变量重要性最高的K、B、Ni、V、Zn、As、Co和Cu作为预测因子(图3)。

图3 基于随机森林算法的预测变量重要性度量Fig.3 The importance of predictor variables based on the random forest algorithm

图4 随机森林模型对训练数据(a)和测试数据(b)的回归结果Fig.4 The regression results of the random forest model on training data and test data
在自然界中Rb没有自己的独立矿物,由于离子半径等地球化学性质与K相近,Rb常以类质同象的形式赋存于钾长石和云母等含钾矿物晶格中,因此Rb的含量与K具有密切的正相关关系[43]。 B为不相容元素,离子半径小,在内生作用过程中,常在岩浆作用的晚期富集,同Rb一样,从超基性岩、基性岩到中性岩和酸性岩B含量逐渐增加,大部分 B分散在造岩矿物中,主要以进入钾长石等长石类矿物为主,岩石风化成土过程中,B和Rb均容易被黏土矿物吸附,较为相似的内生和表生作用可能使Rb和B具有一定的相关性[44]。Rb与Ni、V、Zn、As和Co等元素的关系可能与有机质和黏土矿物的选择性吸附有关[45]。
2.2 预测结果分析
本文随机森林建模是通过Python语言中的sklearn库实现,采用研究区1∶250 000表层土壤数据的80%(2 038组)作为训练数据集,用来建立随机森林预测模型,20%数据(510组)用来对建立的模型进行验证。首先通过K、B、Ni、V、Zn、As、Co、Cu和Rb的含量,建立随机森林模型,如图4(a)所示,纵坐标表示预测值,横坐标表示实际值,中分线表示实际值与预测值相等,模型对训练数据的拟合优度高达0.983 2,说明随机森林模型对该训练数据的训练效果较好。再用划分的20%表层土壤的K、B、Ni、V、Zn、As、Co和Cu的含量数据作为预测变量输入到建立的随机森林模型中得到预测的Rb元素含量,并将预测值与实际值进行对比,随机森林模型对测试数据的预测结果如图4(b)所示,图中的点密度基本上分布在中分线附近,预测结果的拟合优度为0.895 6,说明该模型很好地预测了Rb元素的含量,也进一步表明根据本文方法筛选出的预测变量是有效的。
为了更直观地对比测试数据的实际值和预测值,本文利用GeoIPAS软件分别制作了实际值和预测值的地球化学图(图5)。从图5中可知,预测图能够准确地反映Rb元素的空间含量特征,预测图的高、低值区域与实际图具有很好的套合关系,仅有一些微小的差异,这说明建模的过程是可靠的,预测的结果也是可信的。
2.3 模型应用

图5 测试数据Rb地球化学图:实际图(a)和预测图(b)Fig.5 Rb geochemical map of test data: actual map (a) and predicted map (b)
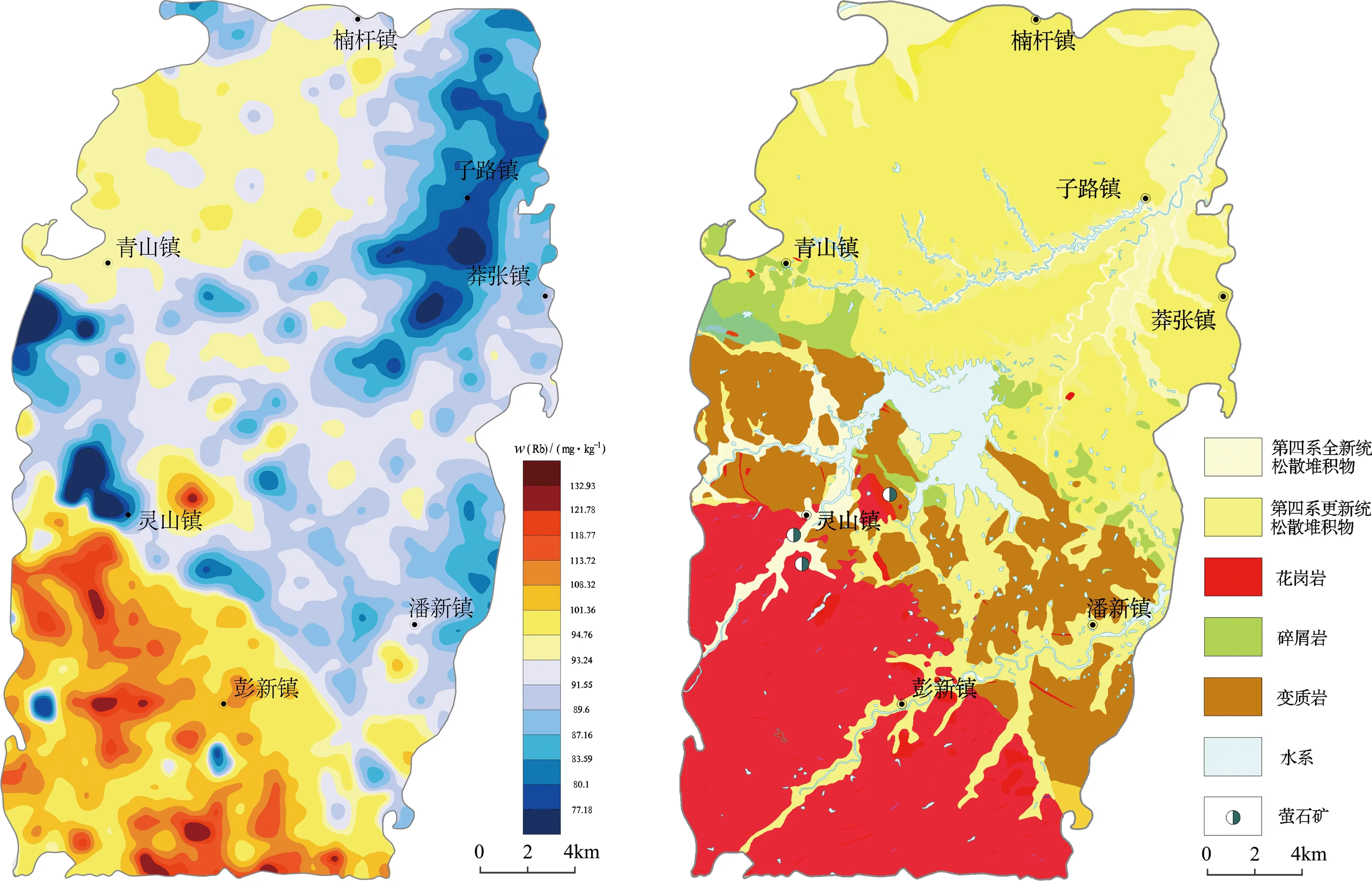
图6 预测表层土壤Rb元素地球化学图(a)和成土母质图(b)Fig.6 Predicted surface soil Rb element geochemical map (a) and soil parent material map (b)
通过上述1∶250 000表层土壤数据建立的模型,将1∶50 000表层土壤的K、B、Ni、V、Zn、As、Co和Cu的含量数据作为输入变量导入模型中,得到预测的Rb元素含量,并利用GeoIPAS软件绘制了Rb元素地球化学图(图6(a)),通过与研究区的成土母质背景(图6(b))对比可知,预测结果比较符合实际特征:①Rb元素含量的高值区与花岗岩出露区高度套合,这是因为自然界Rb通常以伴生状态赋存于花岗岩或花岗伟晶岩中[43];②Rb元素含量的低值区与第四系全新统冲积物分布密切相关,其原因为Rb离子半径较大,水化能(离子被水分子包围的牢固程度)小,阳离子易被带负电的胶体黏土矿物吸附在原地,不易随水流迁移[46],因此在第四系冲积物中含量相对较低,出现低值区;③已发现萤石矿的周围往往都有Rb元素含量高值区,因为萤石矿常常有锂铷云母伴生[47]。
3 结论与展望
本研究立足土地质量地球化学调查出现的小比例尺调查元素多而大比例尺调查元素少的现状,旨在对大比例尺缺失的矿产元素进行空间预测,通过大量数据的训练和学习,以稀有金属Rb元素为例,定量探索土地质量地球化学数据之间的关系。以同一地区1∶250 000表层土壤元素含量数据建立随机森林模型,在1∶50 000尺度Rb元素的空间预测取得了良好的效果,Rb元素预测值与地质背景和表生地球化学过程保持较高的一致性,可视化结果较好地展现了表层土壤Rb元素的空间分布主要受地质背景和表生地球化学作用控制。主要结论如下:①在构建随机森林模型时,采用变量重要性度量排序和构建学习曲线的组合方法进行预测变量的优选,模型对训练数据和测试数据的拟合优度分别达到0.983 2和0.895 6,说明预测变量的优选方法是有效的;②由变量重要性度量结果可知,表层土壤中Rb元素含量与K、B含量具有很强的相关性;③通过对大比例尺Rb元素空间预测结果的佐证,表明将大数据机器学习算法引入表层土壤地球化学元素含量的空间定量预测具有可行性。
土地质量地球化学调查近些年积累了海量数据,立足数据的特点,本文仅以Rb元素为例,介绍了小比例尺建模、大比例尺预测的方法,展示了该算法变量优选的过程和预测的能力。首次尝试把大数据机器学习算法运用到土地质量地球化学数据定量预测中来,并在大比例尺的矿产元素空间定量预测中取得了较好的效果,对预测的结果进行了相关的佐证,具有广阔的应用推广前景,进一步拓展了土地质量地球化学数据的服务应用维度。随着新时代地质调查事业“三大转变”的大力推进,每一名地质调查人员都应当积极向科技创新和信息化建设转变,运用新技术新方法充分挖掘数据潜力,提升数据服务水平,全面提高地质调查成果的服务能力。
