以智能审核应对DRG高靠分组问题
2022-07-09周吴平简伟研
周吴平 简伟研
(北京大学公共卫生学院 北京 100191)
1 问题:高靠分组对DRG付费的破坏性
高靠分组(又称“高编码 upcoding”)可能是DRG 支付制度设立后最具破坏性的提供方策略行为(gaming behavior)。 高 靠 分 组的行为是医疗服务提供方利用DRG分组过程高度依赖疾病诊断和手术操作编码的特点,有目的地调整结算清单中的诊断和(或)手术编码(包括改变患者诊断信息、增加与本次疾病不相关的并发症和合并症、虚报不存在的合并症与并发症等)[1],误导DRG 分组器把病例错分到高权重的DRG 中,从而达到获得高额补偿的目的[2,3]。
尽管目前我国DRG 试点城市对高靠分组的报道不多,但从国际经验看,应该引起决策者足够的重视。 美 国Medicare 保 险1985 年随机审核发现DRG 出院病例的高靠分组占比高达12.83%,采取综合监管与大力惩罚措施后,1988 年高靠分组占比降至7.45%。澳大利亚在实施DRG 后的第七年(1995年)仍然有5.2%的出院病例存在高靠分组[4];德国因高靠分组每年为新生儿病例额外支付了40%的费用[5]。
高靠分组带来的系统性偏倚,单靠DRG 付费制度本身是无法克服的,不得不依赖于配套的稽查手段。国家医保局办公室2021 年发布的《按疾病诊断相关分组(DRG)付费医疗保障经办管理规程(试行)》(医保办发〔2021〕23 号),把高靠分组作为稽核重点,强调“设计并执行监控体系,有效实施稽核程序,循迹追踪实现对DRG 付费的全流程把控”。
本文以“疾病诊断相关分组”“高编码”“高靠分组”“监管”“智能审核”为中文关键词,"Diagnosis-Related Groups" "up-coding""upgrading""audit""supervision""artificial intelligence"为英文关键词,在各中英文数据库中检索相关文献,系统梳理发达国家应对DRG 高靠分组的方法与发展历程,并结合我国DRG 试点进展现状,提出我国发展智能审核的手段,高效应对DRG 高靠分组的路径与建议。
2 现状:应对高靠分组的方法
2.1 事前监管
事前监管指采用多种手段规范医生和编码员的行为,防止高靠分组的发生[6]。事前监管的手段主要包括:对医生和编码员进行职业教育,提高编码能力,防止因为能力不足导致的高编码或者向下编码[7,8];创建编码员和医生应该遵守的伦理准则,违背伦理准则将会受到职业道德的谴责,这一方法能在一定程度上降低高编码的发生[4,9]。不过伦理准则是道德准则,而非法律规定,违背伦理准则并不一定意味着违法[4]。
2.2 判断高靠分组的金标准
由于医疗服务本身具有非常高的技术壁垒,即便是有经验的专科医生,在不核对原始病历的情况下,仅仅依靠医院上报的病案首页数据和费用数据,很难判断信息是否真实有效[10]。判断高靠分组的“金标准”是由临床专家根据原始病历给出正确信息,而后由编码专家给出正确编码,再由DRG 分组器重新分组给出正确的权重,与原始权重对比后判断权重是否增加[1,7,11]。整个过程成本很高,美国联邦与州政府每年花费2.59 亿美元以识别Medicaid 保险出院病例存在的欺诈行为[12]。
2.3 事后监管
识别实际发生的高靠分组并加以惩罚,追回费用的同时达到震慑效果,被称为事后监管,事后监管是应对高靠分组的主要手段。DRG 付费初期的事后监管主要以随机抽样的方式从所有病例中抽取样本,由专家细致审核后给出正确编码[13,14]。具体做法是培养一批审核经验丰富的专家,将经过审核的原始数据进行正确编码,再进行深度的数据挖掘,形成能够反映DRG 高编码的常见变量,发现高编码容易发生的DRG组,并形成初步的监管规则[15]。例如,美国医疗保险和医疗补助服务中心曾经提出17 个最容易发生高编 码 的MS-DRG 组(Medicare’s adaptation of the DRG system),包括089 单纯性肺炎和胸膜炎、320肾脏和尿路感染等[16]。
2.4 智能审核与综合监管
尽管专家经验以及基于经验的监管规则提高了审核效率,但专家抽样审核的病例数量相对于海量的医保结算数据十分有限。随着信息技术发展,人们自然想到借助计算机建立更加智能高效的审核体系。事实上,历史审核数据的积累为引入智能算法打下良好基础,新的审核规则由计算机自动从数据中学习,并据此判断病例是否为高编码,事后监管从人工抽样审核变为全样本智能审核。
DRG 支付方式相对成熟国家的综合监管模式见图1。首先,由政府组织临床专家与编码专家形成团队,将专家经验不断地显性化和数字化,并形成计算机智能审核的规则。计算机依据这些规则便可以完成全部结算数据的筛查(而不是抽样),并对证据确切的案例给出判定意见,同时将存疑案例提报给专家复审。在此过程中,计算机不断通过机器学习提升智能审核的精准度和敏感度。其次,专家团队每年随机抽样一部分结算数据进行人工审核,将发现的新审核规则补充或修正到原有的审核规则库。
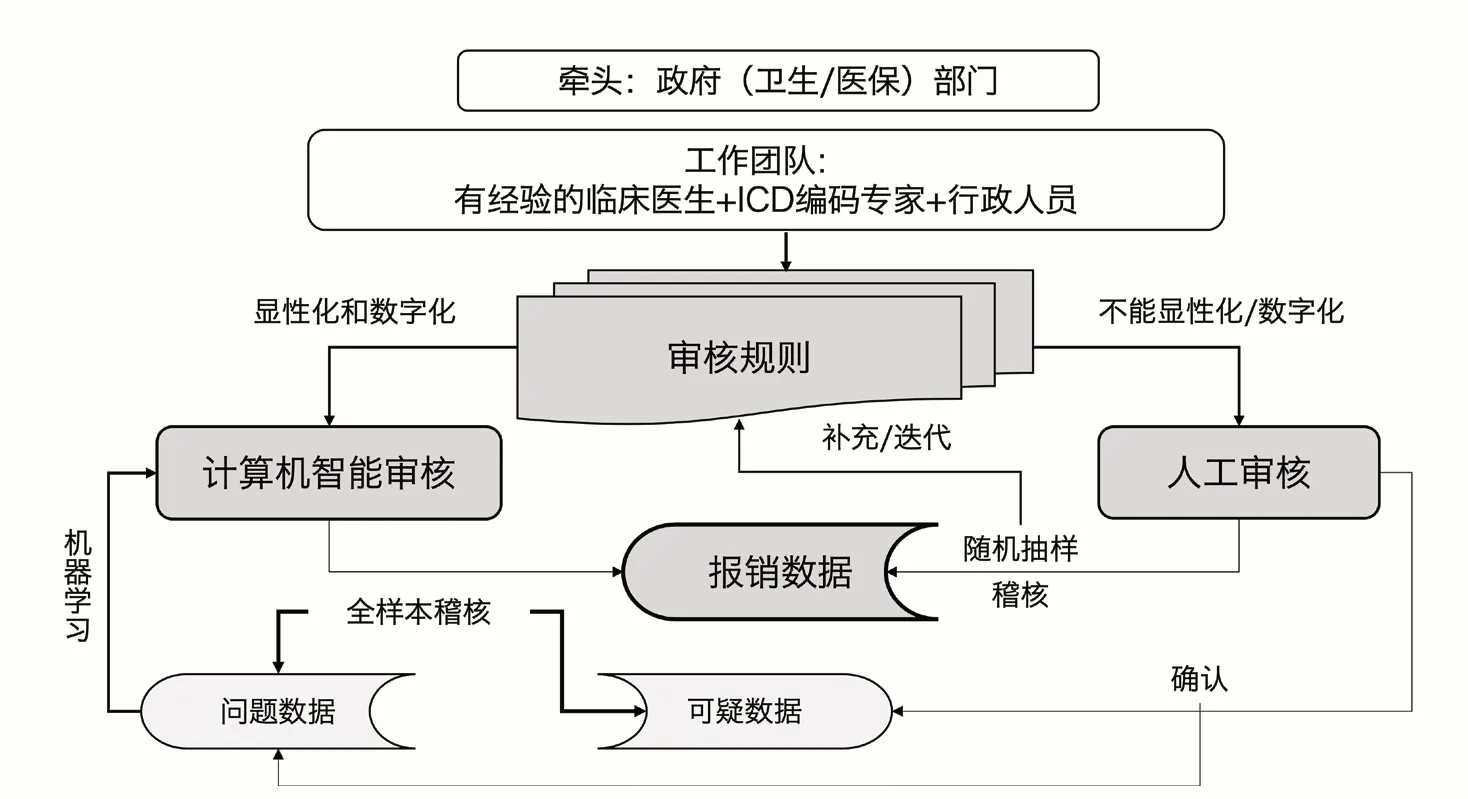
图1 DRG支付方式相对成熟国家的综合监管模式
3 完善路径:开发智能化审核规则
3.1 专家经验的显性化
DRG 实施初期审核数据相对较少,智能审核规则由专家经验显性化形成。政府部门牵头组织有审核经验的临床专家和编码专家,通过头脑风暴提出常见的高靠分组形式。进一步由专家团队逐条回顾被判定为高靠分组的病例,列出判断为高编码的原因,排除偶发原因后将具有规律性的判断条件扩充形成初步的审核规则。这些规则需要经过数据验证有效性:筛选历史审核数据库中符合某条规则的所有病例,计算其中被专家判定为高编码的占比,占比越高提示该规则识别高编码的能力越强。占比低于事先设定阈值的规则由专家团队二次研讨,重新评估规则的合理性与普适性,舍弃不存在临床逻辑或编码逻辑的规则,进一步细化普适性与针对性较差的规则。最后再次组织专家团队,研讨每条审核规则的临床逻辑或编码逻辑并加以推广,扩充完善规则库。
3.2 机器学习
引入机器学习算法需要大量的历史数据作为支撑,常用的机器学习算法包括神经网络、贝叶斯分类器、聚类分析和离群点监测等[17-22]。例如,Bayerstadler 等使用贝叶斯缩减技术的马尔科夫链蒙特卡洛(MCMC)算法构建监测医疗滥用和欺诈的模型,测量医疗索赔数据中对通常模式的系统性偏离来检查 欺 诈 行 为[23]。Rosenberg 等 人用贝叶斯分级模型,在原来方法的基础上额外识别88%的高编码病例并收回98%的多付款项[24]。Massi等人使用kmeans 算法和人工决策支持系统,从183 家医院中识别3 家可疑的医院并进行审核[25]。Hillerman 等 人 使 用ksmeans 聚类算法对病例可能存在欺诈的风险概率进行赋值,并给出排名[21]。Feng 等人使用一个包含2.3 万样本量的数据库,借助随机森林模型和支持向量机构建模型识别可能存在错误的病例,并由监管方进行人工审核,同时提供方法来解决数据不平衡的问题[26]。
4 建议
DRG 支付制度的建立客观上促进了医保结算(以及医院内部管理)的数字化。与之伴随的,便是利用信息化手段升级监管模式。有效应对高靠分组,既是DRG 支付取得实效的保障,也是医保监管成功转型升级的标志。为了做好高靠分组的监管工作,国家层面的专家团队有必要集中研究如何显性化医保数据稽核的专家经验,并开发机器学习的基础模型,然后把这些成果提供给各统筹地区作为本土化的基础。各地则有必要先建立由ICD编码专家和临床专家共同组成的稽核专家队伍,不断积累数据审核的经验。同时,建立智能化审核技术团队,将国家提供的经验和机器学习模型软件化,而后结合本地专家的共识,利用本地真实世界数据开展分析,形成智能化审核的具体规则。当这些准备工作完成后,智能化监管便可以启动。在智能化监管过程中,不断吸取专家经验,通过机器学习持续优化审核规则,让智能化监管的效能不断提升。
