基于注意力机制的多任务汉语关键词识别
2022-07-06何振华胡恒博金鑫安达李静涛
何振华?胡恒博?金鑫?安达?李静涛


摘 要:为了提高语音关键词识别的性能,在无自动语音识别的端到端关键词识别模型的基础上,使用了软注意力机制并结合多任务训练的方式对其进行了改进。改进后的基于注意力机制的关键词识别模型由四部分构成,关键词嵌入模块和声学模块使用软注意力来得到特征向量,判别器模块和分类器模块输入特征向量来进行关键词识别。实验结果表明,改进后模型的准确率分别比基线模型和传统的关键词检索方法高出37.3%和3.1%。
关键词:关键词识别;注意力机制;多任务训练
中图分类号:TP183 文献标识码:A文章编号:2096-4706(2022)06-0082-05
Keyword Recognition of Multi-Task Chinese Based on Attention Mechanism
HE Zhenhua1, HU Hengbo1, JIN Xin2, AN Da2, LI Jingtao1
(1.Zhengzhou Xinda Institute of Advanced Technology, Zhengzhou 450000, China; 2.China Railway Beijing Group Co., Ltd., Beijing 100036, China)
Abstract: In order to improve the performance of speech sounds keyword recognition, this paper uses the method of soft-attention mechanism and combines multi-task training method to improve it based on the end-to-end keyword recognition model without automatic speech sounds recognition. The improved keyword recognition model based on attention mechanism consists of four parts. Keyword embedded modules and acoustic modules use soft attention to obtain the feature vectors, and the discriminator modules and classifier modules input the feature vectors for keyword recognition. Experimental results show that the accuracy of the improved model is 37.3% and 3.1% higher than the baseline model and the traditional keyword retrieval methods respectively.
Keywords: keyword recognition; attention mechanism; multi-task training
0 引 言
关键词识别(Keywordspotting)指在从连续的音频流中检查出是否有预定义的关键词[1]。根据是否使用了傳统的关键词识别方法,可分为两类:第一类为传统的关键词识别方法,即基于大词汇量连续语音识别的关键词检索[2],第二类方法为基于神经网络的关键词识别方法。传统的方法通常先将待检测的音频通过自动语音识别识别来生成一种特殊的词格,然后在词格上面进行关键词搜索以检测是否有预定义的关键词。基于神经网络的关键词识别方法则是直接使用由神经网络构成的关键词识别模型进行关键词识别,例如[3-6]。此外,文献[1]中使用了卷积循环神经网络(Convolutional Recurrent Neural Network, CRNN)模块加上连接时序分类(Connectionist Temporal Classification, CTC)[7]训练损失对不同组合方式的普通话输入进行了关键词识别,其中的四种CTC标签分别为:关键词标签、非关键词标签、句子中每个字的间隔标签、CTC的blank标签。关键词标签中使用了字和音调的组合以获得最好的结果,关键词以外的全部字则被设为非关键词标签。模型训练结束后,对模型输出的结果去重后即可进行关键词识别。另外,Audhkhasi等人[8]提出了一种使用较少监督进行关键词识别的方法,模型中分别用声学模型和字符级语言模型得到输入音频和关键词的嵌入向量表示,然后送入前馈网络中预测关键词是否出现在输入音频中,模型中的声学模块和字符级语言模型模块都采用无监督的方式进行训练,模型的标签也只有1/0分别表示所需检测关键词是否出现在需要检测的句子中,整个模型的训练用到较少的监督标签,并没有对音频进行标注。本文以此模型对应的方法作为基线系统并对其进行进一步的改进。
在文献[8]中,其声学模块是由声学自动编码器组成。声学自动编码器[9]中的编码器将输入的音频特征进行信息压缩得到代表整个输入音频的嵌入向量表示,然后再将此嵌入向量送入声学自动编码器中的解码器中,以输出重建的输入音频,声学模块使用最小均方误差损失来进行训练。由于在对输入音频特征进行信息压缩的过程中会有信息损失,而且对于关键词识别,并不需要输入音频中所有的信息,而只需要包含有关键词信息的那部分信息。故只需要关注整个输入中对关键词识别有用的信息,而不再需要对整个输入音频特征进行信息压缩。注意力机制是一种聚焦于局部信息的机制,可以被用来从众多信息中选择出对当前任务目标更关键的信息,受此启发,可以使用注意力机制对输入音频进行处理以得到关键词识别中所需的信息。B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
本文改进了一种基于注意力机制的关键词识别方法。使用注意力机制得到融合了关键词和输入音频特征的嵌入向量,然后再将嵌入向量送入前馈神经网络进行关键词识别。
1 无自动语音识别的端到端关键词识别
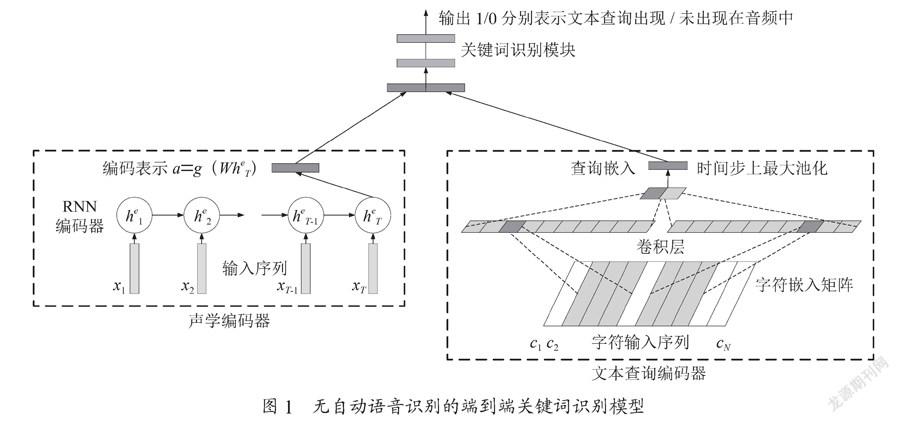
该模型的输入为待检测的文本格式关键词和待检测音频的特征,输出为1/0表示关键词是否出现在音频中。模型结构如图1所示,该模型由三部分构成。声学编码器将音频特征进行压缩以得到代表输入音频的编码表示向量,文本查询编码其将输入的文本格式关键词进行嵌入、卷积和池化操作得到对应的查询嵌入,最后对这两个向量进行拼接并送入到前馈神经网络中输出识别结果。
声学编码器是训练过后的声学自动编码器的编码器部分。声学自动编码器输入音频特征,然后输出重建后的输入音频特征。其实由两个循环神经网络(Recurrent Neural Network, RNN)组成:一个编码器、一个解码器。RNN编码器逐步输入音频特征(x1,x2,…,xT)并更新对应的RNN内部单元状态,直接输入xT更新对应的状态后将隐含层状态作为整个输入特征的表示,然后对进行非线性转换以使得声学向量表示和文本向量表示在相同的嵌入空间中,并将此向量作为输入特征。最后,将送入RNN解码器的每个时间步上,并依次输出对应时间步上的重建特征。声学自动编码器在使用最小均方误差损失进行训练之后去除解码器之后便得到了声学编码器[10]。
文本查询编码器是由字符级语言模型[11]经过训练后得到的。字符级语言模型输入字符序列,然后输出下一个预测的字符。其由三部分构成:嵌入向量矩阵,一维卷积神经网络,RNN语言模型。给定n个字符c=(c1,c2,…,cn),每个字符经过d×N的嵌入向量矩阵的嵌入后得到n个嵌入向量d=(d1,d2,…,dn),然后使用M个d×w的卷积核对向量d进行一维卷积得到M个对应的一维卷积向量,对这M个向量进行最大池化后得到一个维度为M的嵌入向量q,最后将q送入到RNN语言模型中以输出待预测的下一个字符。由于RNN语言模型只输入向量q来预测下一个字符,因此可以用向量q作为文本输入序列的表示。字符级语言模型使用交叉熵损失进行训练,训练完之后去除掉RNN语言模型便得到了文本查询编码器。
前馈神经网络是由两层神经网络构成的。在得到了输入音频特征表示a和文本向量表示q之后,首先对这两个向量进行拼接,然后再将拼接后的向量送入到前馈神经网络中进行预测,结果输出1/0分别表示关键词是否出现在音频中。
软注意力机制是一种根据某些额外的query信息中从向量表达集合values中提取特定的向量进行加权组合的方法。软注意力值可以分为两步得到,先根据query信息在所有的向量表达集合values上计算注意力分布,然后根据注意力分布来计算向量表达集合values的加权平均。
具体来说,对于第一步,给定query向量q和values向量X=(x1,x2,…,xn),可以使用两个向量之间的点积运算结果来得到注意力打分分数:s =(s1,…,si,…,sn),其中,然后使用softmax函数来得到注意力分布:a=(a1,…,ai,…,an),其中ai表示向量q和xi的相关联程度:
(1)
对于第二步,则是将第一步得到的注意力分布a中的每个注意力得分ai分别乘上对应的xi,然后将相乘加权后的向量全部相加得到注意力值:
(2)
在无自动语音识别的端到端关键词识别模型中,为了更有效地得到输入音频中与关键词识别相关的信息,我们可以使用软注意力机制将文本向量表示q作为query向量,将输入音频的特征作为values向量,经过运算操作后得到注意力值然后送入到前馈神经网络中进行关键词识别。
2 基于注意力机制的多任务关键词识别模型
该模型有两个输入X1,X2和两个输出Y1,Y2,X1为文本格式的关键词,X2为音频话语,Y1输出1/0表示关键词输入是否出现在输入的音频话语中,Y2输出被检测关键词的分类概率。模型在推理时则只需输出Y1来得到最终的识别结果。
模型由四部分组成:(1)关键词嵌入模块,用来得到关键词嵌入向量。(2)声学模块,使用注意力机制融合关键词嵌入向量和音频特征序列来得到特征向量。(3)判别器模块,输入特征向量进行关键词识别。(4)分类器模块,输入特征向量进行关键词分类。模型结构如图2所示。
2.1 关键词嵌入模块
为了更有效地得到注意力机制中的关键词query向量,与文本查询编码器不同的是,没有训练字符级语言模型的环节,我们直接将每个关键词进行嵌入操作得到关键词query向量。关键词嵌入模块中的关键词输入经过两个步骤得到嵌入向量:首先,N个关键词k1,k2,…,kN-1,kN经过嵌入矩阵E后得到对应的嵌入向量e1,e2,…,eN-1,eN,为了使关键词的嵌入向量和音频特征序列向量在同一模态空间中以更好的进行后续的注意力运算,关键词嵌入模块使用线性变化q=g(We)来得到处理后的关键词嵌入向量,其中g为LeakyRelu(LeakyRectifiedLinearUnit)函数,W为线性层。
2.2 声学模块
声学模块由CRNN模块和注意力模块两部分构成。CRNN模块从输入音频特征中提取出输入音频的高层特征,Attention模块则使用注意力机制将关键词嵌入向量和音频输入高层特征进行融合。
2.2.1 CRNN模块
CRNN模块由m个卷积神经网络(ConvolutionalNeural Network, CNN)层和n个循环神经网络(RecurrentNeural Network, RNN)层组成。CNN层中的CNN有权重共享和局部感受野的特点,可以用来捕获局部相关性,且在最后一层使用了最大池化(MaxPooling)用来减少后续的计算量,使得所需提取的特征更加突出明显。RNN层只包含用来获得上下文相关性的双向RNN网络。CRNN模块使用了批归一化(BatchNormalization)層用来加速训练,激活函数则使用了LeakyRelu。模块的最后使用线性层来对双向RNN网络的隐含层输出做变换,以使得CRNN模块输出的音频高层特征和关键词嵌入向量在同一嵌入空间中。B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
2.2.2 注意力模块
注意力模块使用注意力机制从高层声学特征中提取与关键词相关的信息。注意力模块的计算过程如下:关键词嵌入向量为qi,i∈(1,2,…,N-1,N),音频输入特征X=x1,x2,…,xT进入CRNN模块后得到的高层特征为V=v1,v2,…,,用qi对V中的每一个特征向量做内积得到权重向量d=(d1,d2…),其中:
(3)
d中的每个常数表示关键词嵌入向量qi与每个高层特征v的关联性大小。d经过softmax处理得到对应的权重向量s=s1,s2…:
(4)
然后将s中的每一个权重乘上对应的高层特征v得到加权后的C其中,最后将C中每列的特征向量进行相加得到融合了关键词嵌入向量和高层特征向量的向量a,即:
(5)
2.3 判别器模块
因向量a融合了关键词嵌入向量信息和音频特征信息,判别器模块直接将向量a作为输入以进行关键词识别,输出范围为0-1的置信度得分以表示关键词是否出现在音频句子中。判别器模块是由两个线性层后接LeakyRelu激活函数后再加上了sigmoid激活函数组成。
2.4 分类器模块
为了更好地利用模型输入的关键词信息以辅助进行关键词识别,我们可以将融合了关键词嵌入向量信息和音频特征信息的a送入分类器模块中输出关键词分类结果。分类器模块是由两个线性层后接LeakyRelu激活函数后再加上softmax激活函数组成。基于注意力机制的多任务关键词识别模型如图2所示。
3 实验
3.1 实验设置
3.1.1 数据准备
实验使用了AISHELL数据集,AISHELL包含各种类型的共计178个小时的干净普通话话语,采样频率为16 kHz。我们按照词频递减的方法在数据集中选出了至少出现5次的共计15个关键词。训练集和评估集中的每个句子至少包含有一个关键词,测试集中一半的句子不止包含有一个关键词,另外一半句子完全不包含有关键词。
为了使模型不会受数据标签比例偏向性的影响,需要对判别器模块和分类器模块的标签数据进行处理。对于判别器的标签,需使数据中的正样本和负样本保持1:1的比例。具体来说,对于训练集和评估集,假设句子si中含有n个关键词k1,k2…kn,则句子si分别与k1,k2…kn共构成n对标签为1的实验数据集S1:(si,k1),(si,k2)…(si,kn),对应标签全为1。S1作为正面样本,表示关键词k1,k2…kn出现在句子si中。未出现在句子si中的剩余(15-n)个关键词被随机地选出相同数量的n个关键词,同样的,句子si分别与共构成n对标签为0的实验数据集S0:,对应标签全为0。S0作为负面样本,表示关键词未出现在句子si中。测试集中正样本的选取方式和训练与评估集相同,负面样本则采取类似的方式由任意的关键词与任意的完全不包含有关键词的句子组成。对于分类器的标签,当判别器的标签为0时,分类器的标签也为0,当判别器的标签为1时,分类器的标签为对应的关键词分类标签。
3.1.2 参数设置
关键词嵌入模块中嵌入矩阵E的维度为256,线性层W含有256个单元。对于声学模型模块,给定音频后先对其进行帧长为25 ms,帧移为10 ms的分帧,然后对每帧取40维梅尔滤波器组特征(filterbank,fbank)并进行一阶和二阶差分后得到每帧120维的fbank特征。CRNN模块中的m/n分别为2/2,CNN层中的卷积核大小都为3×4且步长都为1,而输出通道数依次为16和32,最大池化层的池化大小都为2×2且步长都为2,RNN层中的双向LSTM中的隐含层大小都为256,紧跟其后的线性层含有256个单元。判别器模块中隐含层单元个数依次为256,128,1。分类器模块中隐含层单元个数依次为256,128,16。
模型使用了Adam优化算法,采用了多任务训练的方式对其进行了训练:记判别器输出和对应标签yk的二分类损失为,分类器输出和对应标签yc的交叉熵损失为,则总损失为。Batchsize为512,初始学习速率为0.000 1,实验每5个epoch进行一次评估,当评估集损失无明显下降时,便将学习速率下降至原来的0.9,当评估集的损失不再下降时,模型被停止训练以防止过拟合。该模型使用Pytorch进行实现。
我们用Kaldi工具完成了传统方法的关键词识别实验作为对比。在实验中,我们使用了TDNN-HMM模型,共有5层DNN,每层含有850个隐含层,其含有2 984个发射状态。
3.2 评估准则
在本文的关键词识别任务中,准确率和召回率被用来衡量关键词识别任务的好坏。首先定义如下统计量:
Nfa:虚警(FalseAlarm, FA)数,即将非关键词样本检测为关键词的个数。
Nfr:拒识(FalseReject, FR)数,即将关键词样本检测为非关键词的个数。
Ntt:关键词样本被检测为关键词的个数。
Nff:非关键词样本被检测为非关键词的个数。
召回率(Recall)是指识别结果中关键词样本中被正确地检测为关键词结果所占所有关键词样本的比例,其定义为:
(6)
准确率(Accuracy)是指识别结果中被正确检测的关键词样本占所有检测样本的比例,其定义为:
(7)
3.3 实验结果及分析
我们分别探究了α、β取不同值时其对结果的影响,实验结果如表1所示。
表中的Attention-KWS表示本文所改进的方法,ASR-free-KWS表示本文中第2章所提到的基线系统,ASR-KWS则表示传统的关键词识别方法。从表中可以看出,当α和β分别取0.7和0.3时,准确率最高,效果最好。相比较于未使用注意力机制的ASR-free-KWS,Attention-KWS與其相比提升了37.3%,这说明了注意力机制在关键词识别中提取所需信息的重要性,而且Attention-KWS相比较于传统方法ASR-KWS也提升了3.1%。B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
4 结 论
本文针对ASR-free-KWS声学模块中存在的信息利用问题,使用了软注意力机制并利用多任务训练的方式,使得关键词嵌入向量高效地使用了输入音频特征的信息,使系统的性能得到了较大的提升。在下一步的工作中,为了能够识别任意的汉语关键词,我们将试着探究汉语中的开集关键词识别。
参考文献:
[1] YANH K,HEQ H,XIEW.Crnn-CtcBased Mandarin Keywords Spotting [C]//ICASSP2020-2020IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Barcelona:IEEE,2020:7489-7493.
[2] MANDAL A,KUMAR K R P,MITRA P. Recentdevelopmentsinspokentermdetection:asurvey [J].InternationalJournalofSpeechTechnology,2014,17:183-198.
[3] CHENGG,PARADAC,HEIGOLDG.Small-footprintkeywordspottingusingdeepneuralnetworks [C]//2014IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Florence:IEEE,2014:4087-4091.
[4] DEANDRADEDC,LEOS,VIANAMLDS,et al.Aneuralattentionmodelforspeechcommandrecognition [J/OL].arXiv:1808.08929 [eess.AS].[2021-12-24].https://arxiv.org/abs/1808.08929.
[5] SAINATHT N,PARADAC. Convolutionalneuralnetworksforsmall-footprintkeywordspotting [EB/OL].[2021-12-24].https://download.csdn.net/download/weixin_42601421/10691683?utm_source=iteye_new.
[6] ARIKS?,KLIEGL M,CHILD R,etal. ConvolutionalRecurrentNeuralNetworksforSmall-FootprintKeywordSpotting [EB/OL].[2021-12-24].https://www.isca-speech.org/archive/interspeech_2017/ark17_interspeech.html.
[7] GRAVES A,FERN?NDEZ S,GOMEZ F,etal. ConnectionistTemporalClassification:LabellingUnsegmentedSequenceDataWithRecurrentNeuralNetworks [C]//Proceedingsofthe23rdinternationalconferenceonMachinelearning. Pittsburgh:[s.n.],2006:369-376.
[8] AUDHKHASI K,ROSENBERG A,SETHY A,etal. End-to-End ASR-Free Keyword Search From Speech [J/OL].IEEEJournalofSelectedTopicsinSignalProcessing,2017,11(8):1351-1359.
[9] BALDIP. Autoencoders,unsupervisedlearning,anddeeparchitectures [C].Proceedings of the 2011 International Conference on Unsupervised and Transfer Learning workshop.Washington:JMLR.org,2011,27:37-50.
[10] CHUNGY A,WUCC,SHENC H,et al.AudioWord2Vec:UnsupervisedLearningofAudioSegmentRepresentationsusingSequence-to-sequenceAutoencoder [J/OL].arXiv:1603.00982[cs.SD].[2021-12-24].https://doi.org/10.48550/arXiv.1603.00982.
[11] KIMY,JERNITEY,SONTAGD,et al. Character-AwareNeuralLanguageModels [J/OL].arXiv:1508.06615 [cs.CL].[2021-12-24].https://arxiv.org/abs/1508.06615.
作者簡介:何振华(1983—),男,汉族,河南郑州人,中级工程师,本科,研究方向:语音识别、机器翻译;胡恒博(1994—),男,汉族,河南郑州人,硕士研究生在读,研究方向:语音识别、语音关键词识别。
收稿日期:2022-02-09
课题项目:中国铁路北京局集团有限公司科技研究开发计划课题(2021AY02)B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
