基于核心点虚拟标签传播的密度聚类算法*
2022-07-04刘雷甘腾
刘雷 甘腾
(桂林航天工业学院 计算机科学与工程学院,广西 桂林 541004)
聚类是一种无监督的数据分析过程,其目的是把相似性高的数据点划分到同一类簇中,把相似性低的数据点划分到不同类簇中。聚类算法在数据挖掘、网络安全、生物信息、图像分割等诸多领域有广泛应用[1-2]。最近几十年来,研究学者们对聚类问题进行了深入研究,提出了大量的聚类算法[3]。
密度聚类算法是聚类算法中的一个分支,此类算法大都具有可自动计算类簇数量、对噪声不明感、可识别噪声或异常点等优点。DBSCAN[4]是一种经典的密度聚类算法,使用前需要预先设置参数eps和minPts。对于某一个数据点,如果在其半径为eps的范围内具有至少minPts个数据点,就认为该点是核心点。DBSCAN算法可以很好地处理类簇形状不规则的情况,但是当不同类簇的密度差异较大时,聚类效果不理想。密度峰值算法DP[5]根据预先设置的密度阈值ρ和局部密度最大点之间的距离阈值δ计算出一组密度峰值点,然后在这些峰值点的基础上进行类簇划分。DP算法可以有效处理类簇间密度差异大的问题,提高聚类效果,但是当同一类簇中有多个密度峰值点时,该算法有可能会把一个类簇错误地划分为多个类簇[6]。
除了用特定半径内数据点的个数表征密度,k近邻和反向k近邻也被广泛应用于计算数据点的密度。反向k近邻的数量越多,表明该点的密度越大,重要性越大。HkNN[7]、RNN-DBSCAN[8]等算法就利用反向k近邻的数量表征数据点的密度。利用反向k近邻的数量表征数据点的密度只需要一个参数,简单高效,同时可以有效处理不同类簇间密度差异大的问题。近年有很多密度聚类算法[9-10]采用这种方法。
大部分真实数据集都具有类簇间密度差异大和类簇形状不规则等特点。这些特点会严重影响聚类效果。为提升此类情况下的聚类效果,本文提出了一种基于核心点虚拟标签传播的聚类算法(VLPC,virtual label propagation of core points)。该算法以反向k近邻的数量表征密度,并结合了图论中的相关方法和标签传播算法[11-13]。在人工合成数据集和实际数据集上的测试表明,VLPC算法有效提升了类簇形状不规则、类簇密度差异大等情况下的聚类效果。
1 相关定义
数据集表示为X={x1,…,xn},其中x表示一个m维的数据点。任意两个数据点xi和xj之间的距离用欧氏距离表示,记为sij。对于任意一个数据点xi,距离其最近的k个数据点定义为xi的k近邻,用Nk(xi)表示。对于任意两个数据点xi和xj,如果xi∈Nk(xj)和xj∈Nk(xi)同时满足,则称xi和xj为互近邻。数据点xi的所有互近邻用Mk(xi)表示。如果xi∈Nk(xj),则称xj是xi的反向k近邻。xi的所有反向k近邻记为Rk(xi)。可见,如果两个数据点是互近邻关系,那么它们也是互为反向k近邻。
在k值确定的情况下,每个数据点反向k近邻的数量是不一样的。一般来说,处于类簇中心高密度区的数据点可能是更多数据点的k近邻,从而具有更多的反向k近邻;反之,处于类簇边缘区域的数据点可能具有较少的反向k近邻。因此,以反向k近邻作为指标衡量一个数据点的密度和重要性是合理的。
如图1所示,带箭头的线段表示k近邻关系,箭头端的点是无箭头端点的k近邻,图中k的值取2。处于类簇中心高密度区域的点A、B、C各具有3个反向k近邻,而处于边缘低密度区域的点D、E、F没有反向k近邻。

图1 k近邻示意图
2 算法描述
2.1 构建核心区域
构建核心区域分两步进行,首先需要找出核心点,然后合并关联紧密的核心点形成核心区域。
每个数据点都具有k个近邻,则平均每个点同样具有k个反向k近邻。但由于每个数据点的位置不同,周围数据点的密集程度不同,导致不同数据点的反向k近邻有差异。以平均值k作为阈值,对于数据点xi,如果|Rk(xi)|≥k,则xi是核心点,否则xi是边界点。核心点是对聚类效果有重要影响的数据点,是构建核心区域的基础。如图1所示,点A、B、C的反向k近邻的个数大于等于k值,因此这3个点是核心点。而点D、E、F的反向k近邻的个数小于k值,因此这3个点是边界点。
数据点之间的紧密程度可通过近邻关系表示。互近邻关系要强于单向近邻关系,而单向近邻关系要强于非近邻关系。为了确保两个核心点之间的关系足够紧密,同时满足以下条件的两个核心点xi和xj可以进行合并:
1)xi和xj是互近邻关系,即xj∈Mk(xi)或xi∈Mk(xj);
2)存在点xp,xi和xj都是xp的k近邻,即∃xp∈X,xi∈Nk(xp)且xj∈Nk(xp)。
满足条件1表示两个核心点联系紧密;条件2进一步增强了联系程度,同时也表示点xi和xj处于中心区域。将所有核心点按照上述条件合并之后,即构建出了核心区域。每个核心点只属于一个核心区域,而一个核心区域包含一个或多个核心点。只包含一个核心点的核心区域可能是虚假核心区域。因此,最后需要遍历所有的核心区域,去除掉那些只包含一个核心点的核心区域。
构建核心区域的具体实现步骤如下:
Step 1:计算数据点两两之间的距离,得到距离矩阵S,其中元素sij表示点xi和xj之间的欧氏距离;
Step 2:根据距离矩阵S,得到每个数据点的k近邻和反向k近邻;
Step 3:根据每个数据点反向k近邻的数量,判断其是否为核心点;
Step 4:合并满足要求的核心点,得到核心区域;
Step 5:筛选Step 4中的核心区域,去除掉只包含一个核心点的核心区域,剩下的即为最终的核心区域。
2.2 虚拟标签传播
相同核心区域中的核心点被划分到相同的类簇中,不同核心区域中的核心点被划分到不同的类簇中。每个边界点需要根据其与核心点之间的联系进行类簇的划分。为了确定每个边界点所归属的类簇,本文给每个核心点设置一个虚拟标签,然后通过标签传播的方法将这些标签发散到边界点上,从而得到边界点的类簇划分结果。
虚拟标签采用one-hot编码的形式,相同核心区的核心点具有相同的标签,不同核心区的核心点具有不同的标签。假设共有c个核心区域,核心点xi属于第j个核心区域Cj,则xi的标签可表示为c维列向量yi,其中yi的第j个元素为1,其余元素为0。
数据点之间的联系与距离有关,距离越远联系越小,距离越近联系越大。 本文用W表示关系矩阵,其中的元素wij表示点xi和xj之间的联系:
(1)
其中:
(2)
关系紧密的数据点更可能属于相同的类簇,即标签应该相同或者相近。带有虚拟标签的核心点以k近邻关系为基础向边界点进行标签传播,边界点的标签可以通过求解以下目标函数的最优解获得:
(3)
其中:y1…yl表示l个核心点的虚拟标签,yl+1…yn表示待确定的m=n-l个边界点的虚拟标签。
式(3)可以写成矩阵的形式:
(4)
Y是虚拟标签矩阵Y=[y1…yn]T。为了方便计算,令Yc=[y1…yl]T,Yb=[yl+1…yn]T,则Y可表示为:
(5)

(6)
其中:Lcc和Lbb分别为l×l维和m×m维的方阵。将式(4)和式(5)带入式(3)可得:
(7)

(8)
式(7)对Yb求导,并令导数为0,可得:
(9)
利用式(9)可求得每个边界点的虚拟标签,但是这些边界点的虚拟标签并不是one-hot编码形式。为了转化为one-hot编码形式,对每一个边界的虚拟标签yi,取其中最大元素设置为1,其他元素都设置为0。
矩阵Lbb可能存在不可逆的情况,这是由于近邻个数k的取值过小所引起的,可以通过增大k的取值解决此问题。
遍历所有的数据点,把具有相同虚拟标签的划分为同一个类簇,具有不同虚拟标签的划分为不同类簇。
2.3 算法时间复杂度分析

3 实验与结果分析
为检验VLPC算法的聚类效果,本文选取了8个公开数据集进行测试,其中包括Compound、Jain、Pathbased 、Mouse 4个人工合成数据集和Iris 、Wine 、Appendicitis 、Banknote 4个由真实数据组成的数据集。每个数据集的详细描述如表1所示。

表1 数据集描述
选取DP、RNN-DBSCAN(简写为RDBS)和NPIR算法作为对比算法。DP算法是经典密度峰值聚类算法,RDBS算法与本文提出的VLPC算法都使用反向邻居计算数据点密度,NPIR是一种最近提出的基于k近邻的聚类算法。
聚类效果使用NMI指数和ARI指数进行评估。这是两种常用的评价聚类效果的指数,取值范围在0到1之间,且越接近1表示聚类效果越好。由于在多个数据集上进行测试,将每个算法在所有数据集上的平均排名作为该算法的最终排名。各算法在人工合成数据集上的聚类效果如表2和表3所示。由测试结果可看出,无论采用NMI或ARI指数评价,VLPC算法在除Mouse和Iris数据集上的聚类效果都优于其他3个对比算法。VLPC算法在Mouse和Iris数据集上的聚类效果排名第2。

表2 聚类效果的NMI指数

表3 聚类效果的ARI指数
图2-图5是VLPC算法在人工合成数据集上的聚类效果。从图中可看出,除了Compound数据集中右部存在对数据点较为明显的错误划分,VLPC算法在类簇形状不规则和类簇间密度差异大的情况下可以得到较好地聚类效果。
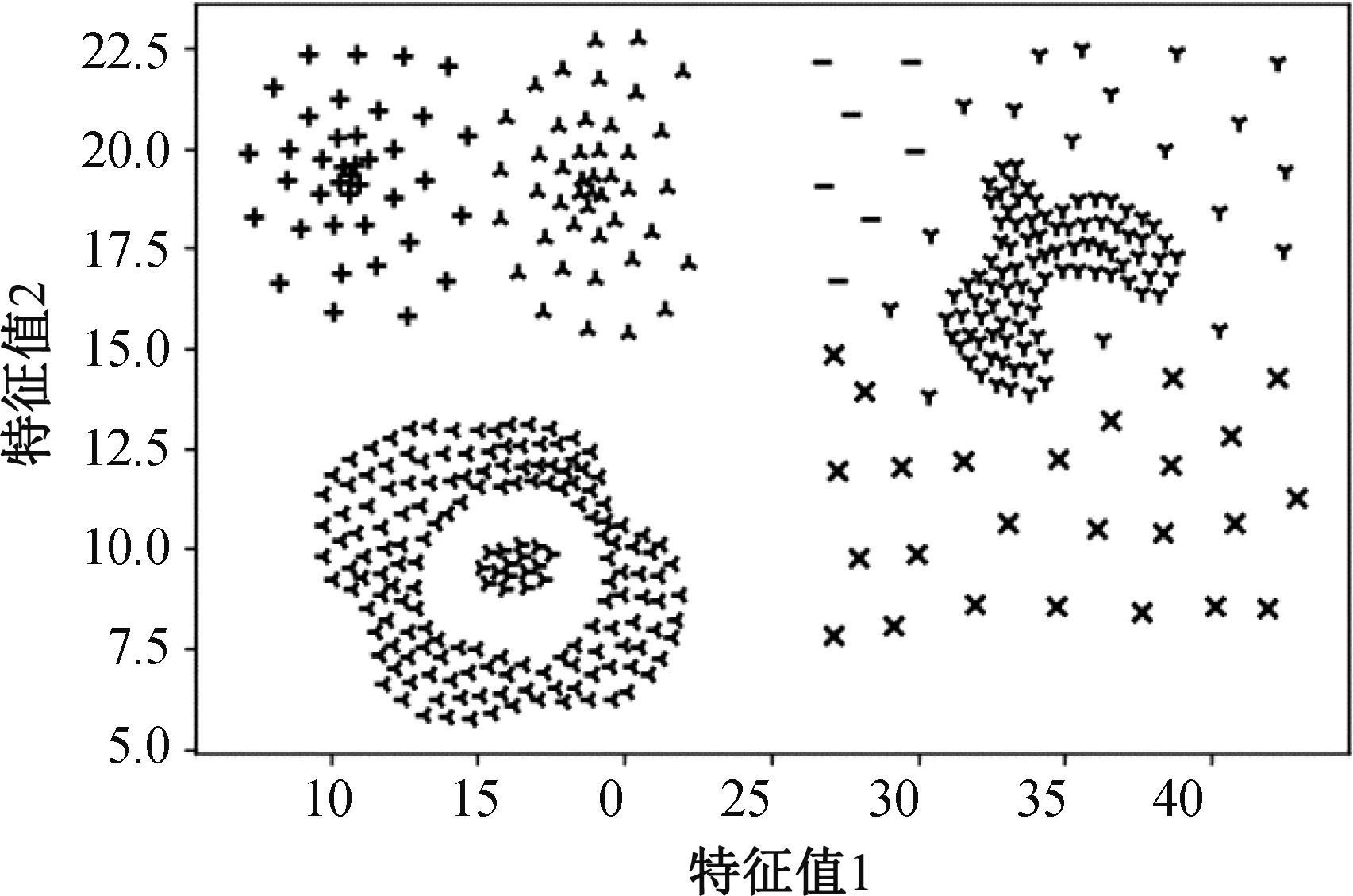
图2 Compound聚类效果

图3 Jain聚类效果

图4 Pathbased聚类效果
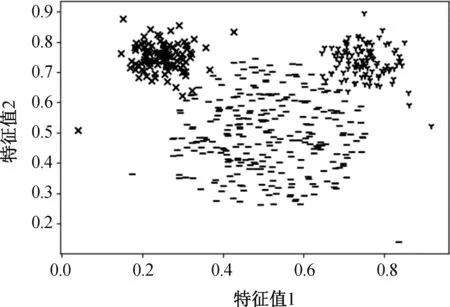
图5 Mouse聚类效果
VLPC算法的综合聚类效果最优,主要可归结于两点。第一,采用反向k近邻表征数据点的重要性可以有效避免不同类簇间密度差异过大给聚类效果带来的负面影响。反向k近邻对密度差异具有自动补偿的效果,无论局部密度大或小,处于中心位置的核心点始终都具有更多的反向k近邻。第二,在k近邻图上采用标签传播法可以有效处理类簇形状不规则问题。k近邻图表现了样本点之间的相似关系,与类簇形状无关。标签传播法的传播路径以k近邻图为基础,虚拟标签在样本点之间的传播强度与k近邻图中边的权重有关,因此可以有效处理类簇形状不规则问题。
4 结束语
本文采用反向k近邻表征数据点的密度和重要性,得到核心点和核心区域,并使用标签传播算法将核心点的虚拟标签扩散到各个边界点,从而完成类簇划分。通过在人工合成数据集和真实数据集上的测试,并与DP、RNN-DBSCAN和NPIR算法进行比较,表明VLPC算法的聚类效果整体上优于对比算法,能够很好地处理类簇形状不规则、密度差异大等问题。
